

1 导引
在知识图谱领域,最重要的任务之一就是实体对齐 [1](entity alignment, EA)。实体对齐旨在从不同的知识图谱中识别出表示同一个现实对象的实体。如下图所示,知识图谱\(\mathcal{G}_1\)和\(\mathcal{G}_2\)(都被虚线框起来)是采自两个大型知识图谱Wikida和DBpedia的小子集。圆角矩形框表示实体,方角矩形表示属性值。圆角矩形之间的箭头代表一个关系谓词(relation predicate),而这就进一步形成了关系元组,如\((\text{dbp}: \text{Victoria}, \text{country}, \text{dbp}:\text{Australia})\),一个圆角矩形和方角矩阵之间的箭头表示一个属性谓词,而这形成一个属性元组,比如\((\text{dbp}:\text{Victoria}, \text{total\_area}, \text{237659 km}^2)\)。
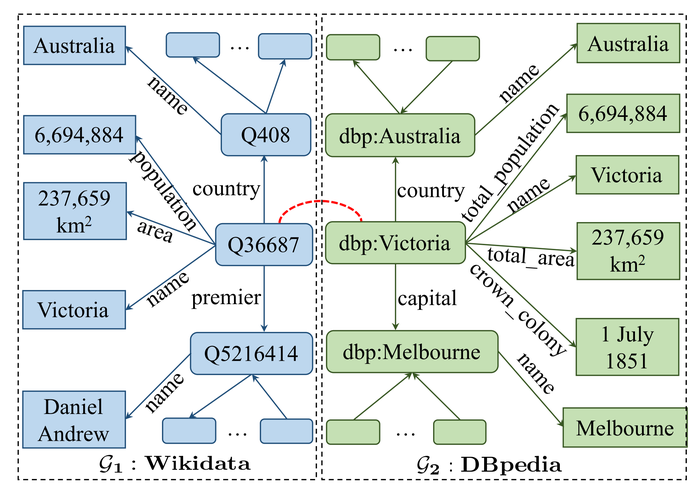

我们可以看到同一个现实实体可能会在两个不同知识图谱中都有其表示(比如\(\text{Q36687}\)和\(\text{dbp:Victoria}\))。这两个知识图谱拥有关于这个现实对象互补的信息,\(\mathcal{G}_1\)知识图谱拥有关于其总理的信息,\(\mathcal{G}_2\)拥有其首都的信息。
如果我们能够确定\(\mathcal{G}_1\)中的\(\text{Q36687}\)和\(\mathcal{G}_2\)中的\(\text{dbp:Victoria}\)指的是同一个现实世界的实体(也即\(\text{Q36687}\)和\(\text{dbp:Victoria}\)是对齐的实体),那么我们所获取的关于该实体的信息就可以大大增加。所谓\(\mathcal{G}_1\)和\(\mathcal{G}_2\) 之间的实体对齐任务即寻找这两个知识图谱中的所有对齐实体。在这个例子里,这里有两个对齐的实体\(\langle \text{Q36687, dbp:Victoria}\rangle\)和$ \langle Q408, dbp:Australia \rangle$。
形式化的说,我们将知识图谱表示为\(\mathcal{G}=(\mathcal{E}, \mathcal{R}, \mathcal{T} )\)(为了简单起见,本文暂不考虑属性谓词)。给定两个知识图谱\(\mathcal{G}_1=(\mathcal{E}_1,\mathcal{R}_1,\mathcal{T}_1)\)和\(\mathcal{G}_2=(\mathcal{E}_2,\mathcal{R}_2,\mathcal{T}_2)\),知识图谱对齐任务的目标为识别出所有的对齐实体对\((e_1,e_2), e_1\in \mathcal{E}_1, e_2\in\mathcal{E_2}\),这里\(e_1\)和\(e_2\)表示的是同一个真实世界的实体(即\(e_1\)和\(e_2\)是对齐的实体)。
一些过于传统的知识图谱实体对齐方法(如基于相似度的方法)我们就不再叙述了,目前主流的都是基于embedding的知识图谱实体对齐方法。基于embedding的知识图谱实体对齐框架如下:
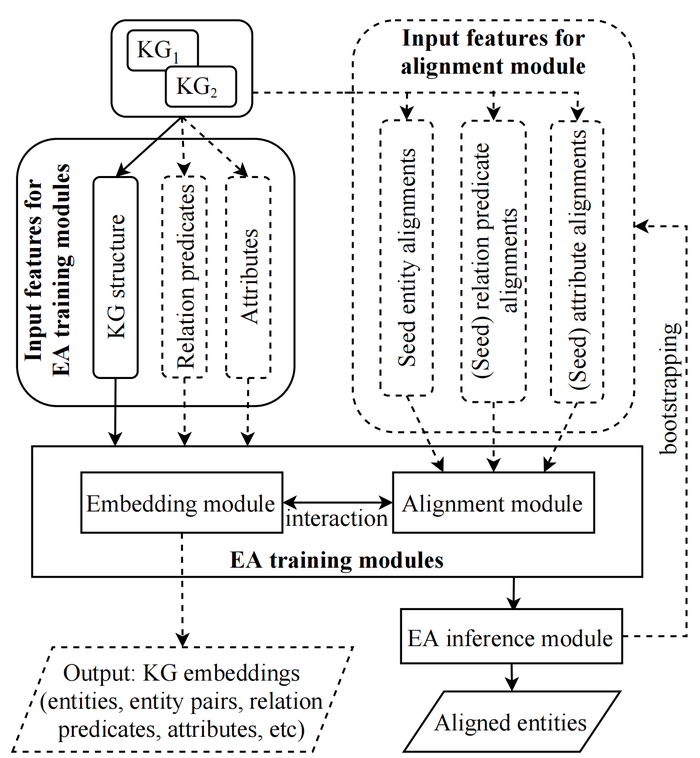
可见基于embedding的知识图谱实体对齐框架由三个部分组成:embedding模块,alignment模块,inference模块。embedding模块和对齐模块可能会交替或共同训练,这两个模块一起构成了知识图谱实体对齐中的training模块。
知识图谱embedding模块负责学习实体和关系的表征(常常是低维的),也即它们的embeddings,常常会利用到一下四种信息:知识图谱的结构(即原始知识图谱数据中的关系元组),关系谓词,属性谓词和数性值(属性谓词和属性值本文暂不讨论)。而其嵌入方法包括基于平移的(translation-based)和基于GNN的(GNN-based),这块大家可以去阅读知识图谱嵌入的入门资料,此处不再赘述。
下面我们来看alignment模块。由于embedding模块独立地学习知识图谱的emebddings,这使得\(\mathcal{G}_1\)和\(\mathcal{G}_2\)的embeddings落入到不同的向量空间中。而alignment模块旨在将两个知识图谱的embeddings统一(unify)到同样的向量空间中,这样就能够识别出对齐的实体了,而这个统一操作也是知识图谱对齐最大的挑战。
这类似于NLP中对跨语言词向量的对齐操作,即使用一个线性变换\(W\)将不同embedding空间中的向量投影到一个统一的embedding空间中[2]。
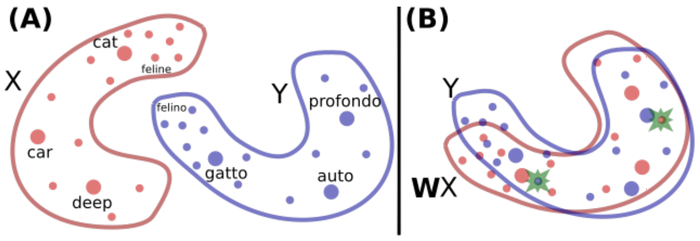
如上图所示,(A)为两个不同的词向量分布,红色的英语单词由\(X\)表示,蓝色的意大利单词由\(Y\)表示,我们想要进行翻译/对齐(在意大利语里面,gatto意为“cat”,profondo意为“deep”,felino意为“feline”,“auto”意为“car”)。每一个点代表词向量空间中的一个单词,点的大小和单词在训练语料中出现的频率成正比。(B)意为学习一个旋转矩阵\(W\)将两个分布大致地对齐。
在知识图谱对齐的过程中经常会使用一个手工对齐好的实体或关系谓词集合做为引子,我们把这个叫做种子对齐集合(seed alignments)。种子对齐集合将会被做为输入特征来训练alignment模块,最常用的方法就是使用一个对齐好的实体集合来做种子\(
\mathcal{S}=\left\{\left(e_1, e_2\right) \mid e_1 \in \mathcal{E}_1, e_2 \in \mathcal{E}_2, e_1 \equiv e_2\right\}
\)。这个种子集合由实体对\((e_1, e_2)\)组成,这里\(e_1\)是\(\mathcal{E}_1\)中的实体,\(e_2\)是\(\mathcal{E}_2\)中的实体。种子集合被用来计算alignment模块的损失函数以学习一个统一的向量空间,然后我们就能够识别出更多潜在的对齐实体。一个典型的损失函数可以被定义如下的Hinge loss形式:
\]
这里\(\gamma\)是间隔超参数。上面的损失函数被设计来最小化种子对齐集合\(\mathcal{S}\)中实体间的距离,最大化负例集合\(\mathcal{S}'\)中实体对\((e_1', e_2,')\)的距离,这里的负样本生成的手段为将种子实体对中的一个实体替换为随机实体。这里,实体对间的距离由\(f_{\text{align}}\)计算,这个函数被称为alignment score function。
若按照所要对齐的知识图谱的类型划分,则可包括跨语言知识图谱[3][4][5][6]、多视角实体相关信息知识图谱[7][8],和相似领域且存在信息重叠的知识图谱[9][10]。
若按照对齐策略来划分,则我们能够将基于embedding的对齐方法进一步细分为基于平移(translation)的和基于GNN的两类。这篇文章我们只介绍基于平移的,基于GNN的我们留在下一篇文章介绍。
2 基于平移(translation)的方法
2.1 MTransE
论文[3]是第一个被提出的基于平移的实体对齐模型。它的embedding模块使用TransE将各个知识图谱的实体与关系谓词嵌入不同的embedding空间后。为了使这些embeddings都落入到一个统一的(unfied)空间,它的对齐模块会最小化下列的alignment score function(对所有的种子元组集合)来进行实体与关系的对齐:
\]
这里\(\mathcal{S}_t\)是来自\(\mathcal{G}_1\)和\(\mathcal{G}_2\)的种子元组集合(注意不同于之前的种子实体集合,除了实体之外还包括关系谓词),\(f_{\text{align}}(tr_1,tr_2)\)是alignment score function。注意,不同于我们在前面的第一部分的知识图谱对齐框架只计算实体的相似程度, 我们前面提到的alignment score function计算两个元组\(tr_1(h_1, r_1, t_1)\in \mathcal{G}_1\) 和\(tr_2(h_1,r_1,t_1)\in \mathcal{G}_2\)的相似程度。为了计算align score,MTranseE有三种策略来进行跨知识图谱转换(cross-KG transition),包括基于距离的轴校准(distance-based axis calibration)和线性变换等。根据作者的实验,基于线性变换的策略具有最佳的表现,该策略学习了一个从\(\mathcal{G}_1\)到\(\mathcal{G}_2\)的emebdding空间的线性变换,使用下列的score function:
f_{\operatorname{align}}\left(t r_1, t r_2\right)=&\left\|\boldsymbol{M}_{i j}^e \boldsymbol{h}_1-\boldsymbol{h}_2\right\|+\\
&\left\|\boldsymbol{M}_{i j}^r \boldsymbol{r}_1-\boldsymbol{r}_2\right\|+\left\|\boldsymbol{M}_{i j}^e \boldsymbol{t}_1-\boldsymbol{t}_2\right\|
\end{aligned}
\]
这里\(\boldsymbol{M}_{i j}^e\)和\(\boldsymbol{M}_{i j}^r\)分别为作用于实体和关系embeddings的线性变换。最小化\(f_{\text{align}}\)会最小化变换之后的\(\mathcal{G}_1\)的实体/关系谓词和\(\mathcal{G}_2\)的实体/关系谓词之间的距离,使这两个知识图谱的embeddings落入到同一个向量空间。
2.2 IPTransE
在embedding模块,IPTransE[10]首先用TransE的扩展PtransE独立学习了\(\mathcal{G}_1\)和\(\mathcal{G}_2\)的embeddings。PTransE不同于TransE,它能够考虑实体之间的路径,从而对间接连接的实体建模(这里的路径由在它们之间形成平移的关系谓词决定)。
在alignment模块, IPTranseE也使用了多种策略完成在\(\mathcal{G}_1\)到\(\mathcal{G}_2\)的转换,包括基于平移的,基于线性变换的和基于参数共享的。
基于平移的策略将平移的思想引入跨知识图谱对齐领域,它将对齐视为一个来自\(\mathcal{G}_1\)的种子实体集合\(\mathcal{E}_1\)和来自\(\mathcal{G}_2\)的种子实体集合\(\mathcal{E}_2\)之间的特殊的关系谓词\(r^{(\varepsilon_1\rightarrow \epsilon_2 )}\)。关于种子实体的alignment score function定义如下:
\]
这里\(\bm{e}_1\)和\(\bm{e}_2\)是实体\(e_1\in\mathcal{E}_1\)和\(\mathcal{e}_2\in\mathcal{E}_2\)的emebddings。目标函数则是嵌入模块PTransE的损失函数和对齐模块的损失函数\(f_{\text{align}}\)的加权和。
而基于线性变换的策略则学习一个变换矩阵\(M^{\left(\mathcal{E}_1 \rightarrow \mathcal{E}_2\right)}\),该矩阵使两个对齐实体互相接近,其采用的alignment score function如下所示:
\]
而参数共享策略会迫使\(\bm{e}_1 = \bm{e}_2\),这表示对齐的实体共享相同的embeddings,因此在两个种子实体上计算\(f_{\text{align}}\)总是得到0,此时目标函数可以规约到PTranE的损失函数。共享策略展示了在三种策略中最佳的emebdding联合学习效果。
在训练过程中,IPTransE采用了bootstraping策略并有一软一硬两种策略来将新对齐的实体添加到种子对齐集合。在硬策略中(也是通常所使用的),将最新对齐的实体被直接加入到种子对齐集合中,而这可能导致错误的传播;在软策略中,新对齐的实体会被分配一个置信分数来缓解错误传播。这里的置信分数对应对齐实体之间的embedding距离,它将会做为损失项添加到目标函数中。
2.3 BootEA
BootEA[9]方法将实体对齐建模为一对一的分类问题,实体所关联到的另一个实体被视为其标签。它会从有标签数据(seed entity alignments)和无标签数据(predicated aligned entities)进行bootstrapping采样迭代地学习分类器。它的embedding模块采用TransE中的score function,此处不再赘述。不过不同于传统的知识图谱对齐方法,它的alignment模块是一个一对一的分类器。该模块使用在\(\mathcal{G}_1\)的实体分布和\(\mathcal{G}_2\)的预测类分布(即对齐实体)之间的交叉熵损失函数。所有在种子实体集合\(S\)中的实体对\(e_1\)、\(e_2\)会被代入到下列等式中计算交叉熵损失:
\]
合理\(\phi_{e_1}(\cdot)\)是一个计算\(e_1\)标签分布的函数。如果\(e_1\)被标注为\(e_2\),标签分布\(\phi_{e_1}(\cdot)\)会将其所有概率质量聚集到\(e_2\),即\(\phi_{e_1}{(e_2)}=1\)。如果\(e_1\)没有被标注,则\(\phi_{e_1}(\cdot)\) 是均匀分布。\(\pi(\cdot)\) 是一个给定\(e_1\in \mathcal{E}_1\),从\(\mathcal{E}_2\)中预测对齐实体的分类器。BootEA的整体损失函数\(\mathcal{E} = \mathcal{L}_e + \beta_2\mathcal{L}_a\),这里\(\beta_2\)是一个平衡超参数,\(\mathcal{L}_e\)是embedding模块的损失。
2.4 NAEA
NAEA[5]也将实体对齐形式化为了一个一对一分类问题,但是将基于平移的范式和基于GAT(Graph Attention Network, 图注意力网络)的范式进行了结合。具体来说,NAEA除了关系层次的信息之外还嵌入了邻居层次的信息。其邻居信息的嵌入是通过attention机制对其邻居的emebddings进行聚合来完成的。这里将其实体\(w\)在邻居层次的表征和在关系层面的表征分别记为\(\text{Ne}(e)\)和\(\text{Nr}(r)\)。其alignment模块和NAEA类似,也使用了\(\mathcal{G}_1\)实体分布和\(\mathcal{G}_2\)实体分布之间的交叉熵损失,如下图所示:
\]
这里\(\phi_{e_1}(e_2)\)和BootEA相似,不同之处在于其分类器\(\pi(e_j \vert e_i)\)定义如下:
\pi\left(e_j \mid e_i\right)=& \beta_3 \sigma\left(\operatorname{sim}\left(\operatorname{Ne}\left(e_i\right), \operatorname{Ne}\left(e_j\right)\right)\right) \\
&+\left(1-\beta_3\right) \sigma\left(\operatorname{sim}\left(\mathbf{e}_i, \mathbf{e}_j\right)\right)
\end{aligned}
\]
这里\(\text{sim}(\cdot)\)是余弦相似度,\(\beta_3\)是一个平衡超参数。
2.5 TransEdge
TransEdge[11]为了解决TransE的缺点,在embedding模块中提出了考虑了关系环境(关系的头节点和尾节点)的平移嵌入模型。举个例子,
\(\text{director}\)在\((\text{Steve Jobs}, \text{director}, \text{Apple})\)和\((\text{James Cameron}, \text{director}, \text{Avator})\) 这两个不同的关系元组中就拥有不同的含义,因此考虑关系的环境信息是值得的。这个模型将关系谓词的环境embebddings(文章中称之为edge embeddings)视为头实体到尾实体的平移。
它的alignment模块使用参数共享策略来统一两个不同的知识图谱,也即迫使在种子实体集合中的实体对拥有同样的embedding。TransEdge使用bootstrapping策略迭代地选择可能对齐的新实体加入(表示为\(
\mathcal{D}=\left\{\left(e_1, e_2\right) \in \mathcal{E}_1 \times \mathcal{E}_2 \mid \cos \left(\mathbf{e}_1, \mathbf{e}_2\right)>s\right\}
\), \(s\)为相似度阈值),但由于可能产生错误,故在每轮迭代中新加入的对齐实体并没有使用参数共享处理。为了使新对齐的实体在emebdding空间中更接近,论文添加了一个基于新对齐实体集合\(\mathcal{D}\)中的emebdding距离的损失项:
\]
参考
[1] Zhang R, Trisedya B D, Li M, et al. A benchmark and comprehensive survey on knowledge graph entity alignment via representation learning[J]. The VLDB Journal, 2022: 1-26.
[2] Alexis Conneau, Guillaume Lample, Marc’Aurelio Ranzato, Ludovic Denoyer, and Hervé Jégou. 2018. Word Translation Without Parallel Data. Proceedings of ICLR.
[3] Muhao Chen, Yingtao Tian, Mohan Yang, and Carlo Zaniolo. 2017. Multilingual Knowledge Graph Embeddings for Cross-lingual Knowledge Alignment. In Proceedings of IJCAI. 1511–1517.
[4] Wu Y, Liu X, Feng Y, Wang Z, Yan R, Zhao D (2019a) Relation-aware entity alignment for heterogeneous knowledge graphs. In: IJCAI 2019
[5] Zhu Q, Zhou X, Wu J, et al. Neighborhood-Aware Attentional Representation for Multilingual Knowledge Graphs[C]//IJCAI 2019: 1943-1949.
[6] Pei S, Yu L, Yu G, et al. Rea: Robust cross-lingual entity alignment between knowledge graphs[C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020: 2175-2184.
[7] Cao Y, Liu Z, Li C, Liu Z, Li J, Chua TS (2019) Multi-channel graph neural network for entity alignment. In: ACL 2019
[8] Qingheng Zhang, Zequn Sun, Wei Hu, Muhao Chen, Lingbing Guo, and Yuzhong Qu. 2019. Multi-view knowledge graph embedding for entity alignment. In Proceedings of IJCAI. AAAI Press, 5429–5435.
[9] (2018) Bootstrapping entity alignment with knowledge graph embedding. In: IJCAI 2018
[10] Zhu H, Xie R, Liu Z, et al. Iterative entity alignment via knowledge embeddings[C]//Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI). 2017.
[11] Sun Z, Huang J, Hu W, et al. Transedge: Translating relation-contextualized embeddings for knowledge graphs[C]//International Semantic Web Conference. Springer, Cham, 2019: 612-629.
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:知识图谱实体对齐1:基于平移(translation)的方法 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 