深度学习是 2018-22 年度最热门的话题之一。近几年该行业取得了非常大的进步,可以说机器或计算机程序真正取代人类的时代已经到来。
在本文章,将使用 Python 进行深度学习的的实战,希望能帮助您了解深度学习到底是什么,以及它是如何实现的。
我将在本文中介绍以下主题:
- 理论篇
- 深度学习的作用
- 什么是深度学习?
- 感知器和人工神经网络
- 深度学习的应用
- 为什么用 Python 进行深度学习?
- 实战篇
- 使用 Python 进行深度学习:感知器示例
- 使用 Python 进行深度学习:创建深度神经网络
理论篇
深度学习的作用
提起深度学习,首先需要了解机器学习。机器学习是迈向人工智能的第一步。它基于这样一种理论概念:即应该让机器自己学习和探索,逐步提升自己。从技术上讲,机器学习应该能够处理大型的数据集,并从大型数据集中提取模型。
机器学习的缺点:
- 机器学习算法无法处理高维数据——高维数据会有大量的输入和输出:大约有数千个维度。处理此类数据会非常复杂并且耗费资源。我们称之为维数诅咒。
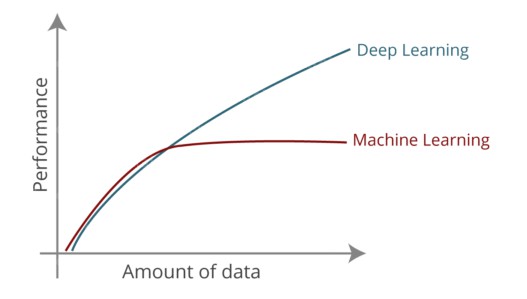
- 机器学习需要提取特征。这在预测结果以及提高准确性方面起着重要作用。因此,如果不进行特征提取,程序员就会面临巨大的挑战。另外特征的有效性在很大程度上取决于程序员的洞察力。
深度学习解决了机器学习的缺点。深度学习能够处理高维数据,并且能够自动提取正确、有效的特征。
什么是深度学习?
深度学习是机器学习的一个子集,它使用类似的机器学习的算法来训练深度神经网络,能够比机器学习达成更好的准确性。深度学习模仿了我们大脑的运作方式,即从经验中学习。
如你所知,我们的大脑由数十亿个神经元组成,使我们能够做出惊人的事情。即使是小孩的大脑也能解决即使使用超级计算机也很难解决的复杂问题。那么,我们如何才能在程序中实现相同的功能呢?现在,这就需要我们了解人工神经元(感知器)和人工神经网络。
感知器和人工神经网络
深度学习主要研究被称为脑细胞或神经元的大脑基本单位。
首先,让我们了解生物神经元的功能,然后让我们了解如何通过感知机和人工神经网络模仿这种功能。
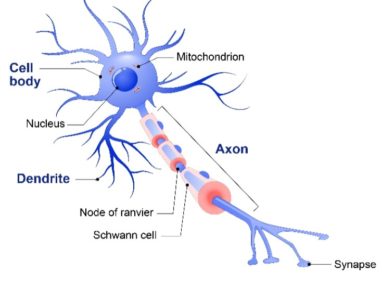
如上图所示,生物神经元包含以下几个部分:
- 树突: 接收来自其他神经元的信号
- 单元体:对所有输入进行求和
- 轴突:用于向其他细胞传递信号
人工神经元或感知器是用于二元分类的线性模型。它对具有一组输入的神经元建模,每个输入都被赋予特定的权重。神经元根据这些加权输入计算一些函数并给出输出。
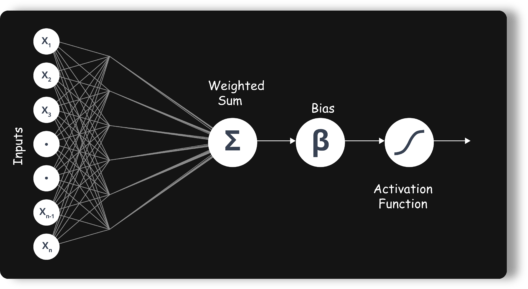
它接收 n 个输入(对应于每个特征)。然后它将这些输入相加,应用转换并产生输出。它有两个功能:
- 求和
- 转化(激活)
权重显示特定输入的有效性。输入的权重越大,对神经网络的影响就越大。另一方面,偏差是感知器中的一个附加参数,用于调整输出以及神经元输入的加权和,从而以最适合给定数据的方式帮助模型。
激活函数将输入转化为输出。它使用阈值来产生输出。有许多函数用作激活函数,例如:
- 线性或恒等式
- 单位或二进制步骤
- 乙状结肠或逻辑
- 坦赫
- ReLU
- 软最大
如果你认为 Perceptron 解决了问题,那你就错了。有两个主要问题:
- 单层感知器无法对非线性可分数据点进行分类。
- 单层感知器无法解决涉及大量参数的复杂问题。
考虑此处的示例以及营销团队做出决策所涉及的参数的复杂性。
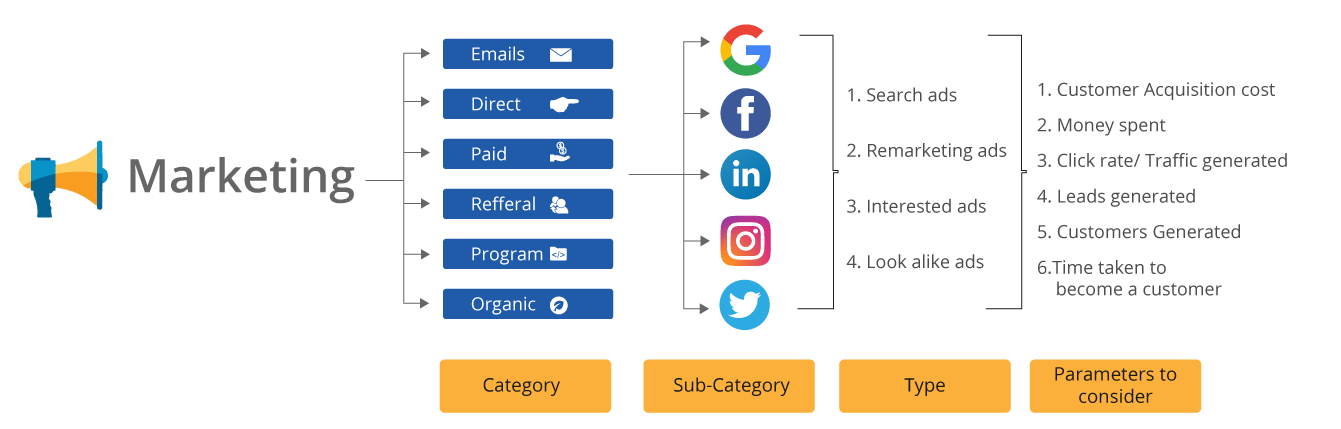
一个神经元,不能接受这么多输入,这就是为什么要使用多个神经元来解决这个问题。神经网络实际上只是感知器的组合,以不同的方式连接并在不同的激活函数上运行。
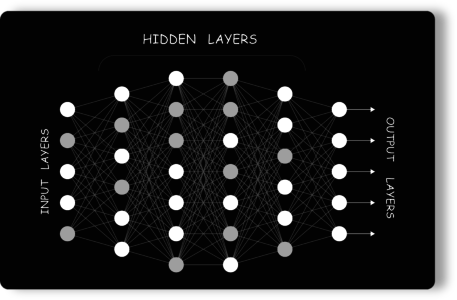
- 输入节点 向网络提供来自外部世界的信息,统称为“输入层”。
- 隐藏节点 执行计算并将信息从输入节点传输到输出节点。隐藏节点的集合形成一个“隐藏层”。
- 输出节点统称为“输出层”,负责计算和将信息从网络传输到外界。
现在您已经了解了感知器的行为方式、所涉及的不同参数以及神经网络的不同层,让我们继续这篇用 Python 进行深度学习的博客,看看深度学习的一些很酷的应用。
深度学习的应用
深度学习在行业中有多种应用,以下是我们日常任务中的一些重要应用。
- 语音识别
- 机器翻译
- 面部识别和自动标记
- 虚拟个人助理
- 自动驾驶汽车
- 聊天机器人
为什么用 Python 进行深度学习?
- Python就是这样一种具有独特属性的工具,它是一种通用编程语言,在分析和定量计算方面易于使用。
- 这很容易理解
- Python 是动态类型的
- 巨大的社区支持
- 用于不同目的的大量库,例如Numpy、Seaborn、Matplotlib、Pandas 和 Scikit-learn
现在理论已经足够了,让我们看看如何通过一个小而令人兴奋的例子开始使用 Python 进行深度学习。
使用 Python 进行深度学习:感知器示例
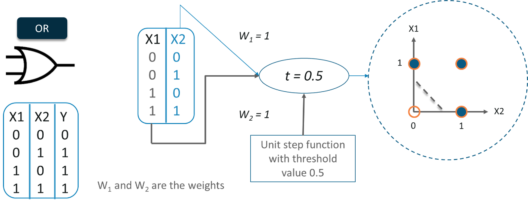
现在我相信你们一定熟悉“或”门的工作原理。如果任何输入也 为 1,则输出为1 。
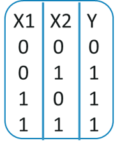
因此,感知器可以用作分隔符或决策线,将或门的输入集分为两类:
- 第 1 类:输入的输出为 0,位于决策线下方。
- 第 2 类:输入的输出为 1,位于决策线或分隔符上方。
到目前为止,我们了解到线性感知器可用于将输入数据集分为两类。但是,它实际上是如何对数据进行分类的呢?
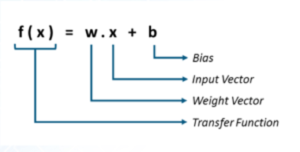
在数学上,感知器可以被认为是权重、输入和偏差的方程式。
第 1 步:导入所有需要的库
在这里,我们只需要导入一个库,即 tensorflow 。
import tensorflow as tf第 2 步:为输入和输出定义向量变量
接下来,我们需要创建变量来存储感知器的输入、输出和偏差。
train_in = [
[0,0,1],
[0,1,1],
[1,0,1],
[1,1,1]]
train_out = [
[0],
[1],
[1],
[1]]第 3 步:定义权重变量
在这里,我们将为我们的权重定义形状为 3×1 的张量变量,并为其初始分配一些随机值。
w = tf.Variable(tf.random_normal([3, 1], seed=15))第 4 步:定义输入和输出的占位符
我们需要定义占位符,以便它们可以在运行时接受外部输入。
x = tf.placeholder(tf.float32,[None,3])
y = tf.placeholder(tf.float32,[None,1])第 5 步:计算输出和激活函数
如前所述,感知器接收到的输入首先乘以各自的权重,然后将所有这些加权输入相加。然后将该求和值馈送到激活以获得最终结果。
output = tf.nn.relu(tf.matmul(x, w))注意:在本例中,我使用了 relu 作为我的激活函数。您可以根据需要自由使用任何激活功能。
第 6 步:计算成本或误差
我们需要计算 Cost = Mean Squared Error,它只是感知器输出与期望输出之差的平方。
loss = tf.reduce_sum(tf.square(output - y))第 7 步:最小化错误
感知器的目标是最小化损失或成本或错误。所以在这里我们将使用梯度下降优化器。
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = optimizer.minimize(loss)第 8 步:初始化所有变量
变量仅使用tf.Variable 定义。所以,我们需要对定义的变量进行初始化。
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)第 9 步:迭代训练感知器
我们需要训练我们的感知器,即在连续迭代中更新权重和偏差值,以最小化错误或损失。在这里,我将在 100 个时期内训练我们的感知器。
for i in range(100):
sess.run(train, {x:train_in,y:train_out})
cost = sess.run(loss,feed_dict={x:train_in,y:train_out})
print('Epoch--',i,'--loss--',cost)第 10 步:输出

如您所见,损失从2.07开始,到0.27结束。
使用 Python 进行深度学习:创建深度神经网络
现在我们已经成功地创建了一个感知器并将其训练为一个或门。让我们继续这篇文章,看看如何从头开始创建我们自己的神经网络,我们将在其中创建输入层、隐藏层和输出层。
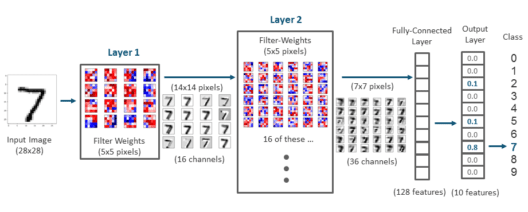
我们将使用 MNIST 数据集。MNIST 数据集由60,000 个训练样本和10,000 个手写数字图像测试样本组成。图像大小为28×28 像素,输出可以介于0-9之间。
这里的任务是训练一个可以准确识别图像上数字的模型。
首先,我们将使用下面的导入将打印函数从 Python 3 引入到 Python 2.6+。future 语句需要靠近文件的顶部,因为它们改变了语言的基本内容,因此编译器需要从一开始就知道它们。
from __future__ import print_function以下是每一步都带有注释的代码:
# Import MNIST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
import tensorflow as tf
import matplotlib.pyplot as plt
# Parameters
learning_rate = 0.001
training_epochs = 15
batch_size = 100
display_step = 1
# Network Parameters
n_hidden_1 = 256 # 1st layer number of features
n_hidden_2 = 256 # 2nd layer number of features
n_input = 784 # MNIST data input (img shape: 28*28)
n_classes = 10 # MNIST total classes (0-9 digits)
# tf Graph input
x = tf.placeholder("float", [None, n_input])
y = tf.placeholder("float", [None, n_classes])
# Create model
def multilayer_perceptron(x, weights, biases):
# Hidden layer with RELU activation
layer_1 = tf.add(tf.matmul(x, weights['h1']), biases['b1'])
layer_1 = tf.nn.relu(layer_1)
# Hidden layer with RELU activation
layer_2 = tf.add(tf.matmul(layer_1, weights['h2']), biases['b2'])
layer_2 = tf.nn.relu(layer_2)
# Output layer with linear activation
out_layer = tf.matmul(layer_2, weights['out']) + biases['out']
return out_layer
# Store layers weight & bias
weights = {
'h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'out': tf.Variable(tf.random_normal([n_hidden_2, n_classes]))
}
biases = {
'b1': tf.Variable(tf.random_normal([n_hidden_1])),
'b2': tf.Variable(tf.random_normal([n_hidden_2])),
'out': tf.Variable(tf.random_normal([n_classes]))
}
# Construct model
pred = multilayer_perceptron(x, weights, biases)
# Define loss and optimizer
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
# Initializing the variables
init = tf.global_variables_initializer()
#create an empty list to store the cost history and accuracy history
cost_history = []
accuracy_history = []
# Launch the graph
with tf.Session() as sess:
sess.run(init)
# Training cycle
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(mnist.train.num_examples/batch_size)
# Loop over all batches
for i in range(total_batch):
batch_x, batch_y = mnist.train.next_batch(batch_size)
# Run optimization op (backprop) and cost op (to get loss value)
_, c = sess.run([optimizer, cost], feed_dict={x: batch_x,y: batch_y})
# Compute average loss
avg_cost += c / total_batch
# Display logs per epoch step
if epoch % display_step == 0:
correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
# Calculate accuracy
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
acu_temp = accuracy.eval({x: mnist.test.images, y: mnist.test.labels})
#append the accuracy to the list
accuracy_history.append(acu_temp)
#append the cost history
cost_history.append(avg_cost)
print("Epoch:", '%04d' % (epoch + 1), "- cost=", "{:.9f}".format(avg_cost), "- Accuracy=",acu_temp)
print("Optimization Finished!")
#plot the cost history
plt.plot(cost_history)
plt.show()
#plot the accuracy history
plt.plot(accuracy_history)
plt.show()
# Test model
correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
# Calculate accuracy
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print("Accuracy:", accuracy.eval({x: mnist.test.images, y: mnist.test.labels}))输出:
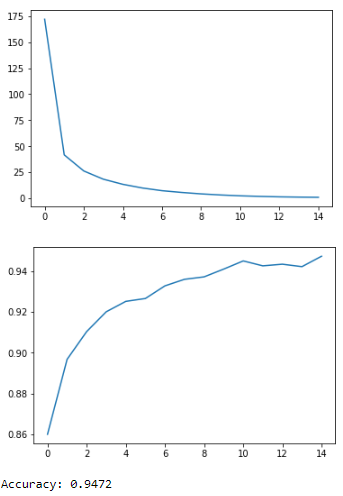
现在,我们结束了这篇用 Python 进行深度学习的文章。我希望您了解深度学习的各个组成部分,它是如何开始的以及我们如何使用 Python 创建一个简单的感知器和深度神经网络。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:深度学习Python实战:用Python实现第一个深度学习程序! - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
