
在本文中,您将学习如何使用 Keras 从头开发一个深度学习模型,自动从德语翻译成英语。
机器翻译是一项具有挑战性的任务,传统上涉及使用高度复杂的语言知识开发的大型统计模型。
在本教程中,您将了解如何开发用于将德语短语翻译成英语的神经机器翻译系统。
完成本教程后,您将了解:
- 如何清理和准备数据以训练神经机器翻译系统。
- 如何为机器翻译开发编码器-解码器模型。
- 如何使用经过训练的模型对新的输入短语进行推理并评估模型技能。
本教程分为 4 个部分;它们是:
- 获取德语到英语翻译训练数据集
- 准备文本数据
- 训练神经翻译模型
- 评估神经翻译模型
准备Python环境
在开始之前,您需要安装好对应的Python环境,要求如下:
- 您必须将 Keras(2.0 或更高版本)与 TensorFlow 一起安装。
- 还需要安装了 NumPy 和 Matplotlib
获取德语到英语的翻译数据集
在本教程中,我们将使用德语到英语术语的数据集作为语言学习的基础。
该数据集可从ManyThings.org网站上获得,其中的示例来自Tatoeba项目。该数据集由德语短语及其英语对应词组成,旨在与Anki软件一起使用。
该页面提供了许多语言对的列表,我鼓励您探索其他语言:
请注意,原始数据集已更改,如果直接使用,将破坏本教程并导致错误:
ValueError: too many values to unpack (expected 2)
如果出现错误,您可以直接从此处下载正确格式的原始数据集:
将数据集文件下载到当前工作目录。
您将有一个名为deu.txt的文件,其中包含 152,820 对英语到德语阶段,每行一对,带有分隔语言的制表符。
例如,文件的前 5 行如下所示:
Hi. Hallo!
Hi. Grüß Gott!
Run! Lauf!
Wow! Potzdonner!
Wow! Donnerwetter!我们将预测问题框定为给定德语单词序列作为输入,翻译或预测英语单词序列。
我们将开发的模型将适用于一些初学者德语短语。
准备文本数据
下一步是准备文本数据以进行建模。
如果您不熟悉清理文本数据,请参阅这篇文章:
查看原始数据,并注意您在数据清理操作中可能需要处理的内容。
例如,以下是我在查看原始数据时注意到的一些观察结果:
- 有标点符号。
- 文本包含大写和小写。
- 德语中有特殊字符。
- 英语中有重复的短语,德语有不同的翻译。
- 文件按句子长度排序,文件末尾的句子很长。
一个好的文本清理过程可以处理部分或全部这些观察结果。
数据准备分为两个子部分:
- 干净的文本
- 拆分文本
干净的文本
首先,我们必须以保留 Unicode 德语字符的方式加载数据。下面称为load_doc() 的函数会将文件加载为文本块。
# load doc into memory
def load_doc(filename):
# open the file as read only
file = open(filename, mode='rt', encoding='utf-8')
# read all text
text = file.read()
# close the file
file.close()
return text每行包含一对短语,首先是英语,然后是德语,由制表符分隔。
我们必须按行拆分加载的文本,然后按短语拆分。下面的函数to_pairs() 将拆分加载的文本。
# split a loaded document into sentences
def to_pairs(doc):
lines = doc.strip().split('\n')
pairs = [line.split('\t') for line in lines]
return pairs我们现在已准备好清理每个句子。我们将执行的具体清洁操作如下:
- 删除所有不可打印的字符。
- 删除所有标点字符。
- 将所有 Unicode 字符规范化为 ASCII(例如拉丁字符)。
- 将大小写规范化为小写。
- 删除任何未按字母顺序排列的剩余标记。
- 我们将对加载数据集中每对的每个短语执行这些操作。
下面的clean_pairs() 函数实现了这些操作。
# clean a list of lines
def clean_pairs(lines):
cleaned = list()
# prepare regex for char filtering
re_print = re.compile('[^%s]' % re.escape(string.printable))
# prepare translation table for removing punctuation
table = str.maketrans('', '', string.punctuation)
for pair in lines:
clean_pair = list()
for line in pair:
# normalize unicode characters
line = normalize('NFD', line).encode('ascii', 'ignore')
line = line.decode('UTF-8')
# tokenize on white space
line = line.split()
# convert to lowercase
line = [word.lower() for word in line]
# remove punctuation from each token
line = [word.translate(table) for word in line]
# remove non-printable chars form each token
line = [re_print.sub('', w) for w in line]
# remove tokens with numbers in them
line = [word for word in line if word.isalpha()]
# store as string
clean_pair.append(' '.join(line))
cleaned.append(clean_pair)
return array(cleaned)最后,现在数据已被清理,我们可以将短语对列表保存到一个可供使用的文件中。
函数save_clean_data() 使用 pickle API 将干净文本列表保存到文件中。
将所有这些放在一起,下面列出了完整的示例。
import string
import re
from pickle import dump
from unicodedata import normalize
from numpy import array
# load doc into memory
def load_doc(filename):
# open the file as read only
file = open(filename, mode='rt', encoding='utf-8')
# read all text
text = file.read()
# close the file
file.close()
return text
# split a loaded document into sentences
def to_pairs(doc):
lines = doc.strip().split('\n')
pairs = [line.split('\t') for line in lines]
return pairs
# clean a list of lines
def clean_pairs(lines):
cleaned = list()
# prepare regex for char filtering
re_print = re.compile('[^%s]' % re.escape(string.printable))
# prepare translation table for removing punctuation
table = str.maketrans('', '', string.punctuation)
for pair in lines:
clean_pair = list()
for line in pair:
# normalize unicode characters
line = normalize('NFD', line).encode('ascii', 'ignore')
line = line.decode('UTF-8')
# tokenize on white space
line = line.split()
# convert to lowercase
line = [word.lower() for word in line]
# remove punctuation from each token
line = [word.translate(table) for word in line]
# remove non-printable chars form each token
line = [re_print.sub('', w) for w in line]
# remove tokens with numbers in them
line = [word for word in line if word.isalpha()]
# store as string
clean_pair.append(' '.join(line))
cleaned.append(clean_pair)
return array(cleaned)
# save a list of clean sentences to file
def save_clean_data(sentences, filename):
dump(sentences, open(filename, 'wb'))
print('Saved: %s' % filename)
# load dataset
filename = 'deu.txt'
doc = load_doc(filename)
# split into english-german pairs
pairs = to_pairs(doc)
# clean sentences
clean_pairs = clean_pairs(pairs)
# save clean pairs to file
save_clean_data(clean_pairs, 'english-german.pkl')
# spot check
for i in range(100):
print('[%s] => [%s]' % (clean_pairs[i,0], clean_pairs[i,1]))运行该示例会在当前工作目录中创建一个新文件,其中包含名为english-german.pkl 的清理文本。
打印了一些干净文本的示例,供我们在运行结束时进行评估,以确认清理操作是否按预期执行。
[hi] => [hallo]
[hi] => [gru gott]
[run] => [lauf]
[wow] => [potzdonner]
[wow] => [donnerwetter]
[fire] => [feuer]
[help] => [hilfe]
[help] => [zu hulf]
[stop] => [stopp]
[wait] => [warte]
...拆分文本
干净的数据包含略多于 150,000 个短语对,文件末尾的一些短语对很长。
这是开发小型翻译模型的大量示例。模型的复杂性随着示例数量、短语长度和词汇量的大小而增加。
虽然我们有一个很好的建模转换数据集,但我们会稍微简化问题,以显着减少所需模型的大小,进而减少拟合模型所需的训练时间。
您可以探索在更完整的数据集上开发模型作为扩展;我很想听听你是怎么做的。
我们将通过将数据集减少到文件中的前 10,000 个示例来简化问题;这些将是数据集中最短的短语。
此外,我们将其中的前 9,000 个作为示例进行训练,其余 1,000 个示例用于测试拟合模型。
下面是加载干净数据、拆分数据并将拆分部分数据保存到新文件的完整示例。
from pickle import load
from pickle import dump
from numpy.random import rand
from numpy.random import shuffle
# load a clean dataset
def load_clean_sentences(filename):
return load(open(filename, 'rb'))
# save a list of clean sentences to file
def save_clean_data(sentences, filename):
dump(sentences, open(filename, 'wb'))
print('Saved: %s' % filename)
# load dataset
raw_dataset = load_clean_sentences('english-german.pkl')
# reduce dataset size
n_sentences = 10000
dataset = raw_dataset[:n_sentences, :]
# random shuffle
shuffle(dataset)
# split into train/test
train, test = dataset[:9000], dataset[9000:]
# save
save_clean_data(dataset, 'english-german-both.pkl')
save_clean_data(train, 'english-german-train.pkl')
save_clean_data(test, 'english-german-test.pkl')运行该示例会创建三个新文件:英语-德语-both.pkl,其中包含我们可以用来定义问题参数的所有训练和测试示例,例如最大短语长度和词汇表,以及用于训练和测试数据集的英语-德语-train.pkl和英语-德语-测试.pkl文件。
现在,我们已准备好开始开发我们的翻译模型。
训练神经翻译模型
在本节中,我们将开发神经翻译模型。
这涉及加载和准备干净的文本数据,以便对准备好的数据进行建模以及定义和训练模型。
让我们从加载数据集开始,以便准备数据。下面名为load_clean_sentences() 的函数可用于依次加载训练、测试和两个数据集。
# load a clean dataset
def load_clean_sentences(filename):
return load(open(filename, 'rb'))
# load datasets
dataset = load_clean_sentences('english-german-both.pkl')
train = load_clean_sentences('english-german-train.pkl')
test = load_clean_sentences('english-german-test.pkl')我们将使用训练数据集和测试数据集的“两者”或组合来定义问题的最大长度和词汇表。
这是为了简单起见。或者,我们可以仅从训练数据集定义这些属性,并截断测试集中太长或单词超出词汇表的示例。
我们可以使用 KerasTokenize类将单词映射到整数,以满足建模的需要。我们将对英语序列和德语序列使用单独的分词器。下面名为create_tokenizer() 的函数将在短语列表上训练分词器。
# fit a tokenizer
def create_tokenizer(lines):
tokenizer = Tokenizer()
tokenizer.fit_on_texts(lines)
return tokenizer类似地,下面名为max_length() 的函数将在短语列表中查找最长序列的长度。
# max sentence length
def max_length(lines):
return max(len(line.split()) for line in lines)我们可以用组合数据集调用这些函数,为英语和德语短语准备分词器、词汇大小和最大长度。
# prepare english tokenizer
eng_tokenizer = create_tokenizer(dataset[:, 0])
eng_vocab_size = len(eng_tokenizer.word_index) + 1
eng_length = max_length(dataset[:, 0])
print('English Vocabulary Size: %d' % eng_vocab_size)
print('English Max Length: %d' % (eng_length))
# prepare german tokenizer
ger_tokenizer = create_tokenizer(dataset[:, 1])
ger_vocab_size = len(ger_tokenizer.word_index) + 1
ger_length = max_length(dataset[:, 1])
print('German Vocabulary Size: %d' % ger_vocab_size)
print('German Max Length: %d' % (ger_length))现在,我们已准备好准备训练数据集。
每个输入和输出序列必须编码为整数,并填充到最大短语长度。这是因为我们将对输入序列使用一个词嵌入,并对输出序列使用一个热编码下面名为encode_sequences() 的函数将执行这些操作并返回结果。
# encode and pad sequences
def encode_sequences(tokenizer, length, lines):
# integer encode sequences
X = tokenizer.texts_to_sequences(lines)
# pad sequences with 0 values
X = pad_sequences(X, maxlen=length, padding='post')
return X输出序列需要采用独热编码。这是因为该模型将预测词汇表中每个单词的概率作为输出。
下面的函数encode_output() 将对英语输出序列进行独热编码。
# one hot encode target sequence
def encode_output(sequences, vocab_size):
ylist = list()
for sequence in sequences:
encoded = to_categorical(sequence, num_classes=vocab_size)
ylist.append(encoded)
y = array(ylist)
y = y.reshape(sequences.shape[0], sequences.shape[1], vocab_size)
return y
我们可以利用这两个函数,准备训练数据集和测试数据集,为训练模型做好准备。
# prepare training data
trainX = encode_sequences(ger_tokenizer, ger_length, train[:, 1])
trainY = encode_sequences(eng_tokenizer, eng_length, train[:, 0])
trainY = encode_output(trainY, eng_vocab_size)
# prepare validation data
testX = encode_sequences(ger_tokenizer, ger_length, test[:, 1])
testY = encode_sequences(eng_tokenizer, eng_length, test[:, 0])
testY = encode_output(testY, eng_vocab_size)现在,我们已准备好定义模型。
我们将使用编码器-解码器 LSTM 模型来解决这个问题。在此体系结构中,输入序列由称为编码器的前端模型编码,然后由称为解码器的后端模型逐字解码。
下面的函数define_model() 定义了模型,并采用许多用于配置模型的参数,例如输入和输出词汇表的大小、输入和输出短语的最大长度以及用于配置模型的内存单元数。
该模型使用有效的Adam方法进行随机梯度下降训练,并最小化分类损失函数,因为我们已将预测问题构建为多类分类。
模型配置没有针对此问题进行优化,这意味着您有很多机会对其进行调整并提高翻译技能。我很想看看你能想出什么。
# define NMT model
def define_model(src_vocab, tar_vocab, src_timesteps, tar_timesteps, n_units):
model = Sequential()
model.add(Embedding(src_vocab, n_units, input_length=src_timesteps, mask_zero=True))
model.add(LSTM(n_units))
model.add(RepeatVector(tar_timesteps))
model.add(LSTM(n_units, return_sequences=True))
model.add(TimeDistributed(Dense(tar_vocab, activation='softmax')))
return model
# define model
model = define_model(ger_vocab_size, eng_vocab_size, ger_length, eng_length, 256)
model.compile(optimizer='adam', loss='categorical_crossentropy')
# summarize defined model
print(model.summary())
plot_model(model, to_file='model.png', show_shapes=True)最后,我们可以训练模型。
我们训练了 30 个 epoch 和 64 个示例的批量大小的模型。
我们使用检查点来确保每次测试集上的模型技能提高时,模型都会保存到文件中。
# fit model
filename = 'model.h5'
checkpoint = ModelCheckpoint(filename, monitor='val_loss', verbose=1, save_best_only=True, mode='min')
model.fit(trainX, trainY, epochs=30, batch_size=64, validation_data=(testX, testY), callbacks=[checkpoint], verbose=2)我们可以将所有这些联系在一起,并拟合神经翻译模型。
下面列出了完整的工作示例。
from pickle import load
from numpy import array
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
from keras.utils.vis_utils import plot_model
from keras.models import Sequential
from keras.layers import LSTM
from keras.layers import Dense
from keras.layers import Embedding
from keras.layers import RepeatVector
from keras.layers import TimeDistributed
from keras.callbacks import ModelCheckpoint
# load a clean dataset
def load_clean_sentences(filename):
return load(open(filename, 'rb'))
# fit a tokenizer
def create_tokenizer(lines):
tokenizer = Tokenizer()
tokenizer.fit_on_texts(lines)
return tokenizer
# max sentence length
def max_length(lines):
return max(len(line.split()) for line in lines)
# encode and pad sequences
def encode_sequences(tokenizer, length, lines):
# integer encode sequences
X = tokenizer.texts_to_sequences(lines)
# pad sequences with 0 values
X = pad_sequences(X, maxlen=length, padding='post')
return X
# one hot encode target sequence
def encode_output(sequences, vocab_size):
ylist = list()
for sequence in sequences:
encoded = to_categorical(sequence, num_classes=vocab_size)
ylist.append(encoded)
y = array(ylist)
y = y.reshape(sequences.shape[0], sequences.shape[1], vocab_size)
return y
# define NMT model
def define_model(src_vocab, tar_vocab, src_timesteps, tar_timesteps, n_units):
model = Sequential()
model.add(Embedding(src_vocab, n_units, input_length=src_timesteps, mask_zero=True))
model.add(LSTM(n_units))
model.add(RepeatVector(tar_timesteps))
model.add(LSTM(n_units, return_sequences=True))
model.add(TimeDistributed(Dense(tar_vocab, activation='softmax')))
return model
# load datasets
dataset = load_clean_sentences('english-german-both.pkl')
train = load_clean_sentences('english-german-train.pkl')
test = load_clean_sentences('english-german-test.pkl')
# prepare english tokenizer
eng_tokenizer = create_tokenizer(dataset[:, 0])
eng_vocab_size = len(eng_tokenizer.word_index) + 1
eng_length = max_length(dataset[:, 0])
print('English Vocabulary Size: %d' % eng_vocab_size)
print('English Max Length: %d' % (eng_length))
# prepare german tokenizer
ger_tokenizer = create_tokenizer(dataset[:, 1])
ger_vocab_size = len(ger_tokenizer.word_index) + 1
ger_length = max_length(dataset[:, 1])
print('German Vocabulary Size: %d' % ger_vocab_size)
print('German Max Length: %d' % (ger_length))
# prepare training data
trainX = encode_sequences(ger_tokenizer, ger_length, train[:, 1])
trainY = encode_sequences(eng_tokenizer, eng_length, train[:, 0])
trainY = encode_output(trainY, eng_vocab_size)
# prepare validation data
testX = encode_sequences(ger_tokenizer, ger_length, test[:, 1])
testY = encode_sequences(eng_tokenizer, eng_length, test[:, 0])
testY = encode_output(testY, eng_vocab_size)
# define model
model = define_model(ger_vocab_size, eng_vocab_size, ger_length, eng_length, 256)
model.compile(optimizer='adam', loss='categorical_crossentropy')
# summarize defined model
print(model.summary())
plot_model(model, to_file='model.png', show_shapes=True)
# fit model
filename = 'model.h5'
checkpoint = ModelCheckpoint(filename, monitor='val_loss', verbose=1, save_best_only=True, mode='min')
model.fit(trainX, trainY, epochs=30, batch_size=64, validation_data=(testX, testY), callbacks=[checkpoint], verbose=2)运行示例首先打印数据集参数的摘要,例如词汇大小和最大短语长度。
English Vocabulary Size: 2404
English Max Length: 5
German Vocabulary Size: 3856
German Max Length: 10接下来,打印已定义模型的摘要,使我们能够确认模型配置。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 10, 256) 987136
_________________________________________________________________
lstm_1 (LSTM) (None, 256) 525312
_________________________________________________________________
repeat_vector_1 (RepeatVecto (None, 5, 256) 0
_________________________________________________________________
lstm_2 (LSTM) (None, 5, 256) 525312
_________________________________________________________________
time_distributed_1 (TimeDist (None, 5, 2404) 617828
=================================================================
Total params: 2,655,588
Trainable params: 2,655,588
Non-trainable params: 0
_________________________________________________________________还会创建模型图,为模型配置提供另一个视角。
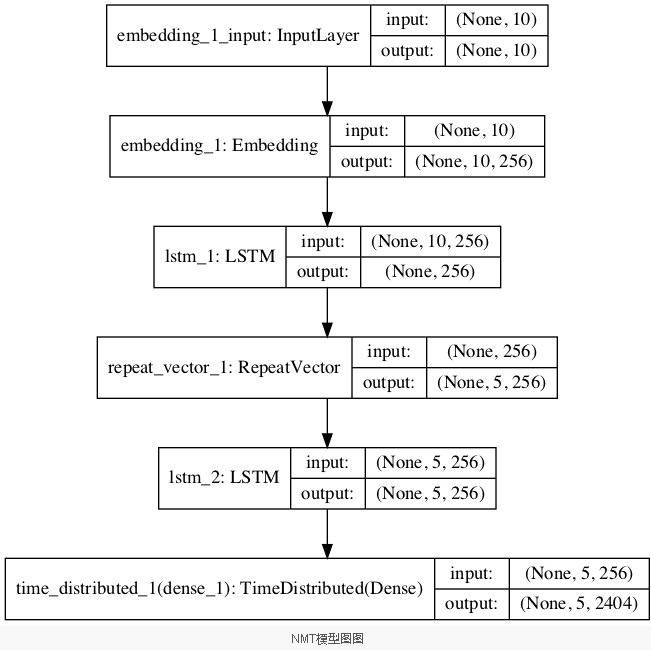
接下来,训练模型。
在现代 CPU 硬件上,每个纪元大约需要 30 秒;不需要图形处理器。
注意:根据算法或评估过程的随机性质或数值精度的差异,您的结果可能会有所不同。请考虑运行几次示例并比较平均结果。
在运行期间,模型将保存到文件model.h5,以便在下一步中进行推理。
...
Epoch 26/30
Epoch 00025: val_loss improved from 2.20048 to 2.19976, saving model to model.h5
17s - loss: 0.7114 - val_loss: 2.1998
Epoch 27/30
Epoch 00026: val_loss improved from 2.19976 to 2.18255, saving model to model.h5
17s - loss: 0.6532 - val_loss: 2.1826
Epoch 28/30
Epoch 00027: val_loss did not improve
17s - loss: 0.5970 - val_loss: 2.1970
Epoch 29/30
Epoch 00028: val_loss improved from 2.18255 to 2.17872, saving model to model.h5
17s - loss: 0.5474 - val_loss: 2.1787
Epoch 30/30
Epoch 00029: val_loss did not improve
17s - loss: 0.5023 - val_loss: 2.1823评估神经翻译模型
我们将在训练和测试数据集上评估模型。
模型应在训练数据集上表现良好,理想情况下已泛化以在测试数据集上表现良好。
理想情况下,我们将使用单独的验证数据集来帮助在训练期间选择模型,而不是测试集。您可以尝试将其作为扩展。
必须像以前一样加载和准备干净的数据集。
...
# load datasets
dataset = load_clean_sentences('english-german-both.pkl')
train = load_clean_sentences('english-german-train.pkl')
test = load_clean_sentences('english-german-test.pkl')
# prepare english tokenizer
eng_tokenizer = create_tokenizer(dataset[:, 0])
eng_vocab_size = len(eng_tokenizer.word_index) + 1
eng_length = max_length(dataset[:, 0])
# prepare german tokenizer
ger_tokenizer = create_tokenizer(dataset[:, 1])
ger_vocab_size = len(ger_tokenizer.word_index) + 1
ger_length = max_length(dataset[:, 1])
# prepare data
trainX = encode_sequences(ger_tokenizer, ger_length, train[:, 1])
testX = encode_sequences(ger_tokenizer, ger_length, test[:, 1])接下来,必须加载训练期间保存的最佳模型。
# load model
model = load_model('model.h5')评估涉及两个步骤:首先生成翻译后的输出序列,然后对许多输入示例重复此过程,并在多个案例中总结模型的技能。
从推理开始,模型可以一次性预测整个输出序列。
translation = model.predict(source, verbose=0)这将是一个整数序列,我们可以在分词器中枚举和查找这些整数以映射回单词。
下面名为word_for_id() 的函数将执行此反向映射。
# map an integer to a word
def word_for_id(integer, tokenizer):
for word, index in tokenizer.word_index.items():
if index == integer:
return word
return None我们可以对翻译中的每个整数执行此映射,并将结果作为单词字符串返回。
下面的函数predict_sequence() 对单个编码的源短语执行此操作。
# generate target given source sequence
def predict_sequence(model, tokenizer, source):
prediction = model.predict(source, verbose=0)[0]
integers = [argmax(vector) for vector in prediction]
target = list()
for i in integers:
word = word_for_id(i, tokenizer)
if word is None:
break
target.append(word)
return ' '.join(target)接下来,我们可以对数据集中的每个源短语重复此操作,并将预测结果与英语中的预期目标短语进行比较。
我们可以将其中一些比较打印到屏幕上,以了解模型在实践中的表现。
我们还将计算BLEU分数,以定量了解模型的性能。
下面的evaluate_model() 函数实现了这一点,为提供的数据集中的每个短语调用上述predict_sequence() 函数。
# evaluate the skill of the model
def evaluate_model(model, tokenizer, sources, raw_dataset):
actual, predicted = list(), list()
for i, source in enumerate(sources):
# translate encoded source text
source = source.reshape((1, source.shape[0]))
translation = predict_sequence(model, eng_tokenizer, source)
raw_target, raw_src = raw_dataset[i]
if i < 10:
print('src=[%s], target=[%s], predicted=[%s]' % (raw_src, raw_target, translation))
actual.append([raw_target.split()])
predicted.append(translation.split())
# calculate BLEU score
print('BLEU-1: %f' % corpus_bleu(actual, predicted, weights=(1.0, 0, 0, 0)))
print('BLEU-2: %f' % corpus_bleu(actual, predicted, weights=(0.5, 0.5, 0, 0)))
print('BLEU-3: %f' % corpus_bleu(actual, predicted, weights=(0.3, 0.3, 0.3, 0)))
print('BLEU-4: %f' % corpus_bleu(actual, predicted, weights=(0.25, 0.25, 0.25, 0.25)))我们可以将所有这些联系在一起,并在训练和测试数据集上评估加载的模型。
下面提供了完整的代码清单。
from pickle import load
from numpy import array
from numpy import argmax
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import load_model
from nltk.translate.bleu_score import corpus_bleu
# load a clean dataset
def load_clean_sentences(filename):
return load(open(filename, 'rb'))
# fit a tokenizer
def create_tokenizer(lines):
tokenizer = Tokenizer()
tokenizer.fit_on_texts(lines)
return tokenizer
# max sentence length
def max_length(lines):
return max(len(line.split()) for line in lines)
# encode and pad sequences
def encode_sequences(tokenizer, length, lines):
# integer encode sequences
X = tokenizer.texts_to_sequences(lines)
# pad sequences with 0 values
X = pad_sequences(X, maxlen=length, padding='post')
return X
# map an integer to a word
def word_for_id(integer, tokenizer):
for word, index in tokenizer.word_index.items():
if index == integer:
return word
return None
# generate target given source sequence
def predict_sequence(model, tokenizer, source):
prediction = model.predict(source, verbose=0)[0]
integers = [argmax(vector) for vector in prediction]
target = list()
for i in integers:
word = word_for_id(i, tokenizer)
if word is None:
break
target.append(word)
return ' '.join(target)
# evaluate the skill of the model
def evaluate_model(model, tokenizer, sources, raw_dataset):
actual, predicted = list(), list()
for i, source in enumerate(sources):
# translate encoded source text
source = source.reshape((1, source.shape[0]))
translation = predict_sequence(model, eng_tokenizer, source)
raw_target, raw_src = raw_dataset[i]
if i < 10:
print('src=[%s], target=[%s], predicted=[%s]' % (raw_src, raw_target, translation))
actual.append([raw_target.split()])
predicted.append(translation.split())
# calculate BLEU score
print('BLEU-1: %f' % corpus_bleu(actual, predicted, weights=(1.0, 0, 0, 0)))
print('BLEU-2: %f' % corpus_bleu(actual, predicted, weights=(0.5, 0.5, 0, 0)))
print('BLEU-3: %f' % corpus_bleu(actual, predicted, weights=(0.3, 0.3, 0.3, 0)))
print('BLEU-4: %f' % corpus_bleu(actual, predicted, weights=(0.25, 0.25, 0.25, 0.25)))
# load datasets
dataset = load_clean_sentences('english-german-both.pkl')
train = load_clean_sentences('english-german-train.pkl')
test = load_clean_sentences('english-german-test.pkl')
# prepare english tokenizer
eng_tokenizer = create_tokenizer(dataset[:, 0])
eng_vocab_size = len(eng_tokenizer.word_index) + 1
eng_length = max_length(dataset[:, 0])
# prepare german tokenizer
ger_tokenizer = create_tokenizer(dataset[:, 1])
ger_vocab_size = len(ger_tokenizer.word_index) + 1
ger_length = max_length(dataset[:, 1])
# prepare data
trainX = encode_sequences(ger_tokenizer, ger_length, train[:, 1])
testX = encode_sequences(ger_tokenizer, ger_length, test[:, 1])
# load model
model = load_model('model.h5')
# test on some training sequences
print('train')
evaluate_model(model, eng_tokenizer, trainX, train)
# test on some test sequences
print('test')
evaluate_model(model, eng_tokenizer, testX, test)运行该示例首先打印源文本、预期和预测翻译的示例,以及训练数据集的分数,然后打印测试数据集。
注意:根据算法或评估过程的随机性质或数值精度的差异,您的结果可能会有所不同。请考虑运行几次示例并比较平均结果。
首先查看测试数据集的结果,我们可以看到翻译是可读的,并且大部分是正确的。
例如:“ich bin brillentrager”被正确翻译为“我戴眼镜”。
我们还可以看到翻译并不完美,“hab ich nicht recht”被翻译成“我胖了吗”而不是预期的“我错了吗”。
我们还可以看到 BLEU-4 的分数约为 0.45,这为我们对这个模型的期望提供了一个上限。
src=[er ist ein blodmann], target=[hes a jerk], predicted=[hes a jerk]
src=[ich bin brillentrager], target=[i wear glasses], predicted=[i wear glasses]
src=[tom hat mich aufgezogen], target=[tom raised me], predicted=[tom tricked me]
src=[ich zahle auf tom], target=[i count on tom], predicted=[ill call tom tom]
src=[ich kann rauch sehen], target=[i can see smoke], predicted=[i can help you]
src=[tom fuhlte sich einsam], target=[tom felt lonely], predicted=[tom felt uneasy]
src=[hab ich nicht recht], target=[am i wrong], predicted=[am i fat]
src=[gestatten sie mir zu gehen], target=[allow me to go], predicted=[do me to go]
src=[du hast mir gefehlt], target=[i missed you], predicted=[i missed you]
src=[es ist zu spat], target=[it is too late], predicted=[its too late]
BLEU-1: 0.844852
BLEU-2: 0.779819
BLEU-3: 0.699516
BLEU-4: 0.452614查看测试集上的结果,确实可以看到可读的翻译,这不是一件容易的事。
例如,我们看到“tom erblasste”正确翻译为“tom turn pale”。
我们还看到一些糟糕的翻译,以及模型可能会遭受进一步调整的好案例,例如“ich brauche erste hilfe”翻译为“我需要他们你”而不是预期的“我需要急救”。
获得了大约 0.153 的 BLEU-4 分数,为通过进一步改进模型提供了改进的基线技能。
src=[mein hund hat es gefressen], target=[my dog ate it], predicted=[my dog is tom]
src=[ich hore das telefon], target=[i hear the phone], predicted=[i want this this]
src=[ich fuhlte mich hintergangen], target=[i felt betrayed], predicted=[i didnt]
src=[wer scherzt], target=[whos joking], predicted=[whos is]
src=[wir furchten uns], target=[were afraid], predicted=[we are]
src=[reden sie weiter], target=[keep talking], predicted=[keep them]
src=[was fur ein spa], target=[what fun], predicted=[what an fun]
src=[ich bin auch siebzehn], target=[im too], predicted=[im so expert]
src=[ich bin dein vater], target=[im your father], predicted=[im your your]
src=[ich brauche erste hilfe], target=[i need first aid], predicted=[i need them you]
BLEU-1: 0.499623
BLEU-2: 0.365875
BLEU-3: 0.295824
BLEU-4: 0.153535扩展
本节列出了一些您可能希望探索的扩展教程的想法。
- 数据清理。可以对数据执行不同的数据清理操作,例如不删除标点符号或规范化大小写,或者删除重复的英语短语。
- 词汇。词汇可以改进,也许可以删除数据集中使用少于5或10次的单词,并替换为“unk”。
- 更多数据。用于拟合模型的数据集可以扩展到 50,000、100,000 个短语或更多。
- 输入顺序。输入短语的顺序可以颠倒,据报道这可以提升技能,或者可以使用双向输入层。
- 层。编码器和/或解码器模型可以用额外的层进行扩展,并针对更多时期进行训练,从而为模型提供更多的表示能力。
- 单位。编码器和解码器中的存储单元数量可以增加,为模型提供更多的表示能力。
- 正则化。该模型可以使用正则化,例如权重或激活正则化,或者在 LSTM 层上使用 dropout。
- 预先训练的词向量。可以在模型中使用预先训练的词向量。
- 递归模型。可以使用模型的递归公式,其中输出序列中的下一个单词可以以输入序列和到目前为止生成的输出序列为条件。
总结
在本教程中,您了解了如何开发用于将德语短语翻译成英语的神经机器翻译系统。
具体而言,您了解到:
- 如何清理和准备数据以训练神经机器翻译系统。
- 如何为机器翻译开发编码器-解码器模型。
- 如何使用经过训练的模型对新的输入短语进行推理并评估模型技能。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:(实战篇)从头开发机器翻译系统! - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 