
毋庸讳言,和传统架构(BS开发/CS开发)相比,人工智能技术确实有一定的基础门槛,它注定不是大众化,普适化的东西。但也不能否认,人工智能技术也具备像传统架构一样“套路化”的流程,也就是说,我们大可不必自己手动构建基于神经网络的机器学习系统,直接使用深度学习框架反而更加简单,深度学习可以帮助我们自动地从原始数据中提取特征,不需要手动选择和提取特征。
之前我们手动构建了一个小型的神经网络,解决了机器学习的分类问题,本次我们利用深度学习框架Tensorflow2.11构建一套基于神经网络协同过滤模型(NCF)的视频推荐系统,解决预测问题,完成一个真正可以落地的项目。
推荐系统发展历程
“小伙子,要光盘吗?新的到货了,内容相当精彩!”
大约20年前,在北京中关村的街头,一位抱着婴儿的中年大妈兴奋地拽着笔者的胳臂,手舞足蹈地推荐着她的“产品”,大概这就是最原始的推荐系统雏形了。
事实上,时至今日,依然有类似产品使用这样的套路,不管三七二十一,弄个首页大Banner,直接怼用户脸上,且不论用户感不感兴趣,有没有用户点击和转化,这种强买强卖式的推荐,着实不怎么令人愉快。
所以推荐系统解决的痛点应该是用户的兴趣需求,给用户推荐喜欢的内容,才是推荐系统的核心。
于是乎,启发式推荐算法(Memory-based algorithms)就应运而生了。
启发式推荐算法易于实现,并且推荐结果的可解释性强。启发式推荐算法又可以分为两类:
基于用户的协同过滤(User-based collaborative filtering):主要考虑的是用户和用户之间的相似度,只要找出相似用户喜欢的物品,并预测目标用户对对应物品的评分,就可以找到评分最高的若干个物品推荐给用户。举个例子,李老师和闫老师拥有相似的电影喜好,当新电影上映后,李老师对其表示喜欢,那么就能将这部电影推荐给闫老师。
基于物品的协同过滤(Item-based collaborative filtering):主要考虑的是物品和物品之间的相似度,只有找到了目标用户对某些物品的评分,那么就可以对相似度高的类似物品进行预测,将评分最高的若干个相似物品推荐给用户。举个例子,如果用户A、B、C给书籍X,Y的评分都是5分,当用户D想要买Y书籍的时候,系统会为他推荐X书籍,因为基于用户A、B、C的评分,系统会认为喜欢Y书籍的人在很大程度上会喜欢X书籍。
启发式协同过滤算法是一种结合了基于用户的协同过滤和基于项目的协同过滤的算法,它通过启发式规则来预测用户对物品的评分。
然而,启发式协同过滤算法也存在一些缺陷:
难以处理冷启动问题:当一个用户或一个物品没有足够的评分数据时,启发式协同过滤算法无法对其进行有效的预测,因为它需要依赖于已有的评分数据。
对数据稀疏性敏感:如果数据集中存在大量的缺失值,启发式协同过滤算法的预测准确率会受到影响,因为它需要依赖于完整的评分数据来进行预测。
算法的可解释性较差:启发式协同过滤算法的预测结果是通过启发式规则得出的,这些规则可能很难被解释和理解。
受限于启发式规则的质量:启发式协同过滤算法的预测准确率受到启发式规则的质量影响,如果启发式规则得不到有效的优化和更新,算法的性能可能会受到影响。
说白了,这种基于启发式的协同过滤算法,很容易陷入一个小范围的困境,就是如果某个用户特别喜欢体育的视频,那么这种系统就会玩命地推荐体育视频,实际上这个人很有可能也喜欢艺术类的视频,但是囿于冷启动问题,无法进行推荐。
为了解决上面的问题,基于神经网络的协同过滤算法诞生了,神经网络的协同过滤算法可以通过将用户和物品的特征向量作为输入,来预测用户对新物品的评分,从而解决冷启动问题。
对数据稀疏性的鲁棒性:神经网络的协同过滤算法可以自动学习用户和物品的特征向量,并能够通过这些向量来预测评分,因此对于数据稀疏的情况也能进行有效的预测。
更好的预测准确率:神经网络的协同过滤算法可以通过多层非线性变换来学习用户和物品之间的复杂关系,从而能够提高预测准确率。
可解释性和灵活性:神经网络的协同过滤算法可以通过调整网络结构和参数来优化预测准确率,并且可以通过可视化方法来解释预测结果。
所以基于神经网络协同过滤模型是目前推荐系统的主流形态。
基于稀疏矩阵的视频完播数据
首先构造我们的数据矩阵test.csv文件:
User,Video 1,Video 2,Video 3,Video 4,Video 5,Video 6
User1,10,3,,,,
User2,,10,,10,5,1
User3,,,9,,,
User4,6,1,,8,,9
User5,1,,1,,10,4
User6,1,4,1,,10,1
User7,,2,1,2,,8
User8,,,,1,,
User9,1,,10,,3,1
这里横轴是视频数据,纵轴是用户,对应的数据是用户对于视频的完播程度,10代表看完了,1则代表只看了百分之十,留空的代表没有看。
编写ncf.py脚本,将数据读入内存并输出:
import pandas as pd
# set pandas to show all columns without truncation and line breaks
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 1000)
# data = np.loadtxt('data/test-data.csv', delimiter=',', dtype=int, skiprows=1,)
data = pd.read_csv('data/test-data.csv')
print(data)
程序返回:
User Video 1 Video 2 Video 3 Video 4 Video 5 Video 6
0 User1 10.0 3.0 NaN NaN NaN NaN
1 User2 NaN 10.0 NaN 10.0 5.0 1.0
2 User3 NaN NaN 9.0 NaN NaN NaN
3 User4 6.0 1.0 NaN 8.0 NaN 9.0
4 User5 1.0 NaN 1.0 NaN 10.0 4.0
5 User6 1.0 4.0 1.0 NaN 10.0 1.0
6 User7 NaN 2.0 1.0 2.0 NaN 8.0
7 User8 NaN NaN NaN 1.0 NaN NaN
8 User9 1.0 NaN 10.0 NaN 3.0 1.0
一目了然。
有数据的列代表用户看过,1-10代表看了之后的完播程度,如果没看过就是NAN,现在我们的目的就是“猜”出来这些没看过的视频的完播数据是多少?从而根据完播数据完成视频推荐系统。
矩阵拆解算法
有一种推荐算法是基于矩阵拆解,通过假设的因素去“猜”稀疏矩阵的空缺数据,猜出来之后,再通过反向传播的逆运算来反推稀疏矩阵已存在的数据是否正确,从而判断“猜”出来的数据是否正确:
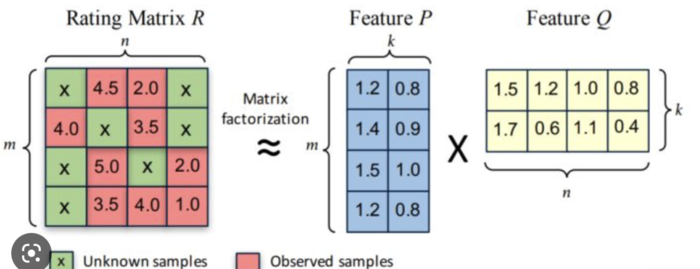

通俗地讲,跟算命差不多,但是基于数学原理,如果通过反推证明针对一个人的算命策略都是对的,那么就把这套流程应用到其他人身上。
但是这套逻辑过于线性,也就是因素过于单一,比如我喜欢黑色的汽车,那么就会给我推所有黑色的东西,其实可能黑色的因素仅局限于汽车,是多重因素叠加导致的,所以矩阵拆解并不是一个非常好的解决方案。
基于神经网络
使用神经网络计算,必须将数据进行向量化操作:
# reset the column.index to be numeric
user_index = data[data.columns[0]]
book_index = data.columns
data = data.reset_index(drop=True)
data[data.columns[0]] = data.index.astype('int')
# print(data)
# print(data)
scaler = 10
# data = pd.DataFrame(data.to_numpy(), index=range(0,len(user_index)), columns=range(0,len(book_index)))
df_long = pd.melt(data, id_vars=[data.columns[0]],
ignore_index=True,
var_name='video_id',
value_name='rate').dropna()
df_long.columns = ['user_id', 'video_id', 'rating']
df_long['rating'] = df_long['rating'] / scaler
# replace the user_id to user by match user_index
df_long['user_id'] = df_long['user_id'].apply(lambda x: user_index[x])
# data = df_long.to_numpy()
print(df_long)
程序返回:
user_id video_id rating
0 User1 Video 1 1.0
3 User4 Video 1 0.6
4 User5 Video 1 0.1
5 User6 Video 1 0.1
8 User9 Video 1 0.1
9 User1 Video 2 0.3
10 User2 Video 2 1.0
12 User4 Video 2 0.1
14 User6 Video 2 0.4
15 User7 Video 2 0.2
20 User3 Video 3 0.9
22 User5 Video 3 0.1
23 User6 Video 3 0.1
24 User7 Video 3 0.1
26 User9 Video 3 1.0
28 User2 Video 4 1.0
30 User4 Video 4 0.8
33 User7 Video 4 0.2
34 User8 Video 4 0.1
37 User2 Video 5 0.5
40 User5 Video 5 1.0
41 User6 Video 5 1.0
44 User9 Video 5 0.3
46 User2 Video 6 0.1
48 User4 Video 6 0.9
49 User5 Video 6 0.4
50 User6 Video 6 0.1
51 User7 Video 6 0.8
53 User9 Video 6 0.1
这里scaler=10作为数据范围的阈值,让计算机将完播数据散列成0-1之间的浮点数,便于神经网络进行计算。
随后安装Tensorflow框架:
pip3 install tensorflow
如果是Mac用户,请安装mac版本:
pip3 install tensorflow-macos
接着针对数据进行打标签操作:
import numpy as np
import pandas as pd
import tensorflow as tf
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
# dataset = pd.read_csv(url, compression='zip', usecols=['userId', 'movieId', 'rating'])
dataset = df_long
# Encode the user and video IDs
user_encoder = LabelEncoder()
video_encoder = LabelEncoder()
dataset['user_id'] = user_encoder.fit_transform(dataset['user_id'])
dataset['video_id'] = video_encoder.fit_transform(dataset['video_id'])
# Split the dataset into train and test sets
# train, test = train_test_split(dataset, test_size=0.2, random_state=42)
train = dataset
# Model hyperparameters
num_users = len(dataset['user_id'].unique())
num_countries = len(dataset['video_id'].unique())
随后定义64个维度针对向量进行处理:
embedding_dim = 64
# Create the NCF model
inputs_user = tf.keras.layers.Input(shape=(1,))
inputs_video = tf.keras.layers.Input(shape=(1,))
embedding_user = tf.keras.layers.Embedding(num_users, embedding_dim)(inputs_user)
embedding_video = tf.keras.layers.Embedding(num_countries, embedding_dim)(inputs_video)
# Merge the embeddings using concatenation, you can also try other merging methods like dot product or multiplication
merged = tf.keras.layers.Concatenate()([embedding_user, embedding_video])
merged = tf.keras.layers.Flatten()(merged)
# Add fully connected layers
dense = tf.keras.layers.Dense(64, activation='relu')(merged)
dense = tf.keras.layers.Dense(32, activation='relu')(dense)
output = tf.keras.layers.Dense(1, activation='sigmoid')(dense)
# Compile the model
model = tf.keras.Model(inputs=[inputs_user, inputs_video], outputs=output)
model.compile(optimizer='adam', loss='mse', metrics=['mae'])
这里定义了一个64维度的 embedding 类用来对向量进行处理。相当于就是把属于数据当中的所有特征都设定成一个可以用一个64维向量标识的东西,然后通过降维处理之后使得机器能以一个低维的数据流形来“理解”高维的原始数据的方式来“理解”数据的“含义”,
从而实现机器学习的目的。而为了检验机器学习的成果(即机器是否有真正理解特征的含义),则使用mask(遮罩)的方式,将原始数据当中的一部分无关核心的内容“遮掉”,然后再尝试进行输入输出操作,如果输入输出操作的结果与没有遮罩的结果进行比较后足够相近,或者完全相同,则判定机器有成功学习理解到向量的含义。
这里需要注意的是,因为embedding 这个词其实是有一定程度的误用的关系,所以不要尝试用原来的语义去理解这个词,通俗地讲,可以把它理解为“特征(feature)”,即从原始数据中提取出来的一系列的特征属性,至于具体是什么特征,不重要。
这里有64个维度,那就可以认为是从输入的原始数据当中提取64个“特征”,然后用这个特征模型去套用所有的输入的原始数据,然后再将这些数据通过降维转换,最终把每一个输入的向量转换成一个1维的特殊字符串,然后让机器实现“理解复杂的输入”的目的,而那个所谓的训练过程,其实也就是不断地用遮罩mask去遮掉非核心的数据,然后对比输出结果,来看机器是否成功实现了学习的目的。
说白了,和矩阵拆解差不多,只不过矩阵拆解是线性单维度,而神经网络是非线性多维度。
最后进行训练和输出:
model.fit(
[train['user_id'].values, train['video_id'].values],
train['rating'].values,
batch_size=64,
epochs=100,
verbose=0,
# validation_split=0.1,
)
result_df = {}
for user_i in range(1, 10):
user = f'User{user_i}'
result_df[user] = {}
for video_i in range(1, 7):
video = f'Video {video_i}'
pred_user_id = user_encoder.transform([user])
pred_video_id = video_encoder.transform()
result = model.predict(x=[pred_user_id, pred_video_id], verbose=0)
result_df[user] = result[0][0]
result_df = pd.DataFrame(result_df).T
result_df *= scaler
print(result_df)
程序返回:
Video 1 Video 2 Video 3 Video 4 Video 5 Video 6
User1 9.143433 3.122697 5.831852 8.930688 9.223139 9.148163
User2 2.379406 9.317654 9.280337 9.586231 5.115635 0.710877
User3 6.046935 8.950342 9.335093 9.546472 8.487216 5.069511
User4 6.202362 1.341177 2.609368 7.755390 9.160558 8.974072
User5 1.134012 1.772043 0.634183 3.741076 9.297663 3.924277
User6 0.488006 4.060344 1.116192 4.625140 9.264144 1.199519
User7 2.820735 0.898690 0.560579 2.215827 8.604731 7.889819
User8 0.244587 1.062029 0.360087 1.069786 7.698551 1.286932
User9 1.337930 8.537857 9.329366 9.123328 3.074733 0.774436
我们可以看到,机器通过神经网络的“学习”,直接“猜出来”所有用户未播放视频的完播程度。那么,我们只需要给这些用户推荐他未看的,但是机器“猜”他完播高的视频即可。
总结
我们可以看到,整个流程简单的令人发指,深度学习框架Tensorflow帮我们做了大部分的工作,我们其实只是简单的提供了基础数据而已。
首先定义一个embedding (多维空间) 用来理解需要学习的原始数据 :
一个用户对象(含一个属性userId)
一个视频对象(含三个属性:videoId, userId, rating (完播向量))
这里需要进行学习的具体就是让机器理解那个“完播向量:rating”的含义)这里定义的embedding 维度为64, 本质就是让机器把完播向量rating 的值当作成一个64维度的空间来进行理解(其实就是从这个rating值当中提取出64个特征来重新定义这个rating)
随后对embedding 进行降维处理:
具体的操作与使用的降维函数曲线有关,这里采用的是先降为32维再降为1维的两道操作方式,原来的代表rating 的embedding 空间从64维降低到了1维。而此时的输出output 对象就是机器对rating完播向量所做出来的“自己的理解”。
最后通过对学习完的输出项output 进行mask(遮罩)测试,通过变换不同的mask(遮罩)来测试结果是否与原始数据相近,或一致,从而来证实机器学习的效果,也就是上文提到的反向传播方式的逆运算。
结语
可能依然有朋友对这套系统的底层不太了解,那么,如果我们用“白话文”的形式进行解释:比如有一幅油画,油画相比完播量,肯定是多维度的,因为画里面有颜色、风格、解析度、对比度、饱和度等等特征参数,此时我们让机器先看完整的这幅画,然后用机器学习的方式让它学习(即embedding方式),接着把这幅画遮掉一部分与主题无关的部分,然后再测试机器让它用学习到的数据(即embedding完成降维处理之后的数据)去尝试复原整幅画,随后对比复原的整幅画和原始油画有多大差别,如果差别没有或者很小,则证明机器学习成功了,机器确实学会了这副画,然后就让机器按照这套逻辑去画类似的画,最后把这一“类”的画推荐给没有鉴赏过的用户,从而完成推荐系统,就这么简单。
最后,奉上视频推荐系统项目代码,与众乡亲同飨:github.com/zcxey2911/NeuralCollaborativeFiltering_NCF_Tensorflow
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:构建基于深度学习神经网络协同过滤模型(NCF)的视频推荐系统(Python3.10/Tensorflow2.11) - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 