突发奇想,爬取p站图片做个壁纸图库(bukemiaoshu),当然这里有许多的门槛,但是为了实现理想,暂时没想那么多了,直接开干
(不是专业做测试和自动化的,如有大佬请评论指教!!!)
1.进入登录页
由于p站是需要登录的,听说p站反爬,requests应该不是那么好使,于是使用selenium模拟人工登录
观察p站起始页,首先是有个登录的a标签在这里的,可以使用类选择器来确定这个元素,再click一下即可
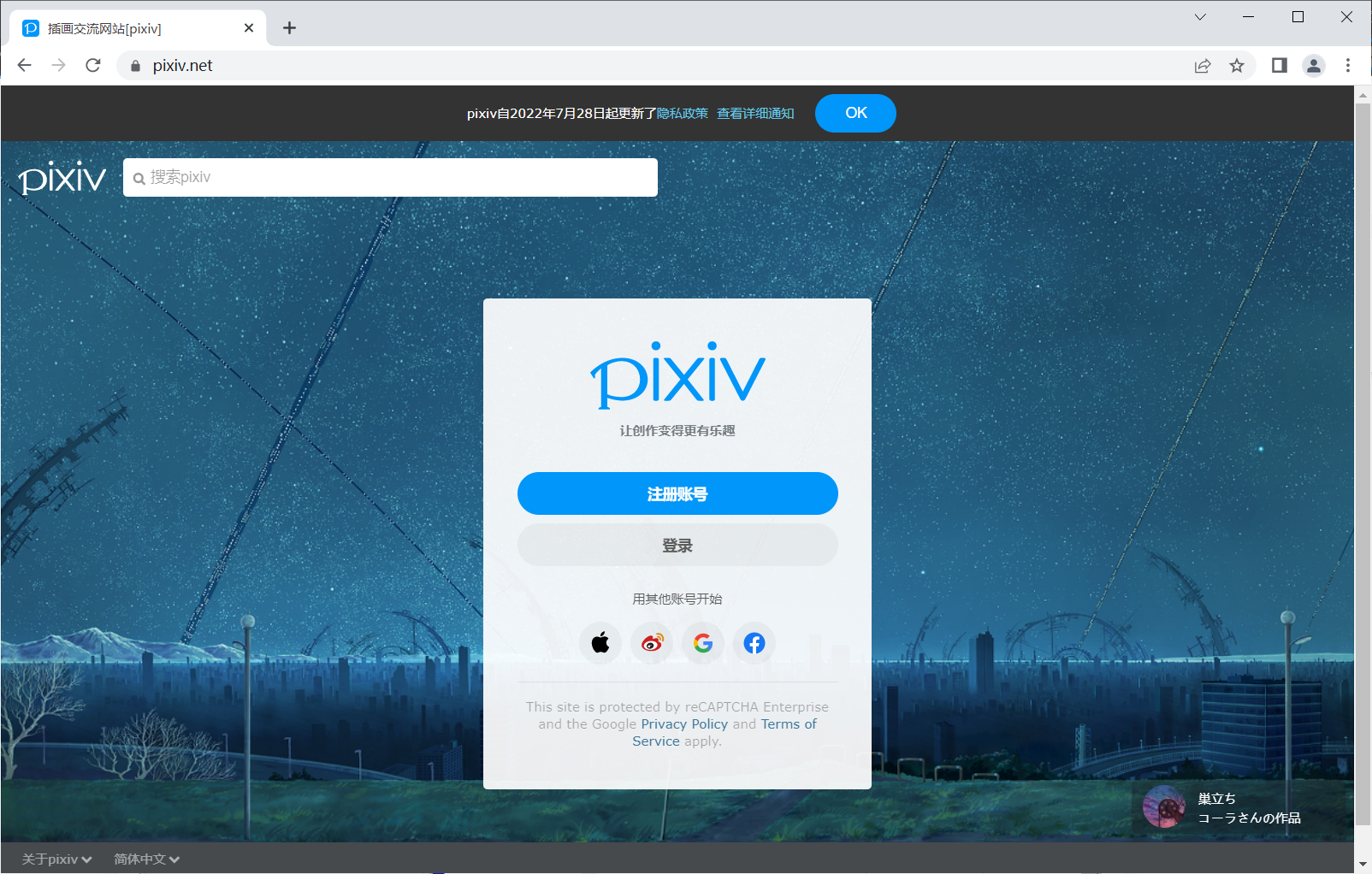


# 模拟登录
purl = "https://www.pixiv.net/"
browser = webdriver.Chrome()
browser.get(purl)
login1 = browser.find_element_by_class_name("signup-form__submit--login")
login1.click()2.输入账户密码
观察页面
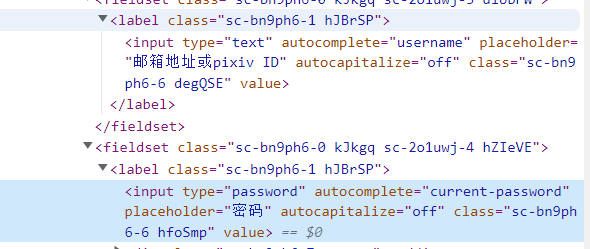
同样可以使用类选择器确定两个元素
确定后使用send_keys(key)方法可以将key填入input标签,填入后再单击一下登录即可
user = 'xxxxxx'
passwd = 'xxxxxx'
user_class = browser.find_element_by_class_name("degQSE")
passwd_class = browser.find_element_by_class_name("hfoSmp")
login2 = browser.find_element_by_class_name("jvCTkj")
user_class.send_keys(user)
passwd_class.send_keys(passwd)
login2.click()3.搜索
进入主页后,观察页面搜索框,可以直接使用标签选择器搜索input标签,整个页面有3个input标签,而选择器会选择第一个标签,恰好搜索框就是第一个标签
再定义一个key用来在终端中输入爬取关键字,输入后同样可以用send_keys(key)方法填充,再模拟一下键盘,模拟键盘需要导入Keys
from selenium.webdriver.common.keys import Keys导入Keys之后,可以使用sned_keys(Keys.ENTER)模拟键盘的回车,来确认搜索


# 模拟搜索
time.sleep(10)
search = browser.find_element_by_tag_name("input")
# browser.find_element_by_partial_link_text("搜索作品")
key = "归终"
key = input('请输入爬取关键字:')
search.send_keys(key)
search.send_keys(Keys.ENTER)4.模拟下载
这里就是我遇到的门槛了...
因为selenium不方便下载,就想利用requests和with open下载
结果发现p站的链接只有通过鼠标访问才可以被接受,而直接在浏览器敲图片地址的方式是403被拒绝的
(这是什么鬼反爬,这样requests也get不到图片了)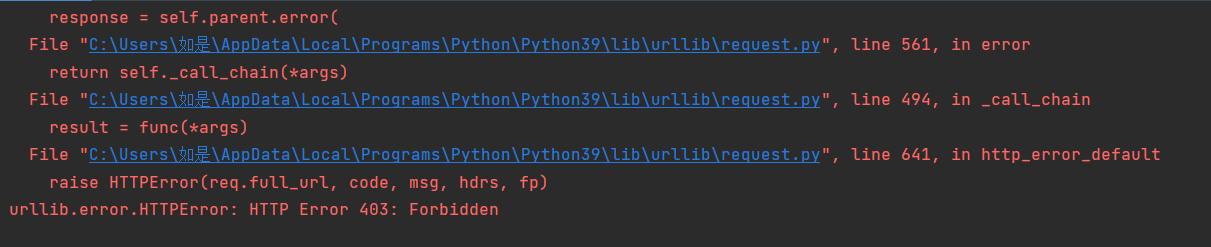
time.sleep(10)
photo_class_li = browser.find_elements_by_class_name("gpVAva")
print("搜索到li,开始逐个进入")
for picture in photo_class_li:
print(picture)
picture.click()
time.sleep(4)
true_picture_class = browser.find_element_by_class_name("beQeCv").find_element_by_tag_name("a")
true_picture_class.click()
true_picture = browser.find_element_by_class_name("cKLKGN").find_element_by_tag_name("img")
url = true_picture.get_attribute('src')
urllib.request.urlretrieve(url, f'./pictures/{url.split("/")[-1]}')
browser.back()新的思路是:
在搜索框搜索完之后会有一个ul列表,里面每个li都是图片,可以使用复数类选择器find_elements_by_class_name
利用循环对选择器找到的类进行点击,点击之后进入图片介绍页,再次点击图片则会进入图片大图,模拟鼠标右键,再进行另存为即可
但是同样的十分麻烦
因为p站图片不能用快捷键保存,只能用鼠标,而鼠标模拟右键又需要其他的库
就算用了模拟鼠标的库,也要进行坐标级的调整,比如鼠标右键后要移动到什么位置单击等等
十分的麻烦
这里我就放弃了,希望哪次再心血来潮的时候(并且技术力足够)继续完善它(好家伙,被p站教做人了)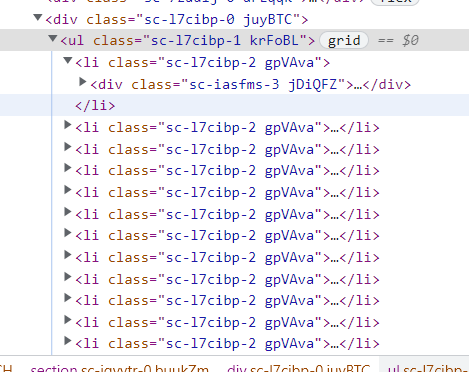
然而就这样摆烂过了几天,我痛定思痛,决定还是要实现理想,不过在实现理想前,我首先去锻炼了下(google,Stack Overflow...)
在那些也爬取pixiv同样返回403的我等同胞那里,我找到了同胞们解决问题的方法
如同requests提交请求需要加入请求头一样,p站的图片链接如果没有一个referer请求头的话,它也会拒绝你的访问
解决方法:https://blog.csdn.net/ycarry2017/article/details/79599539/
加入了referer就成功了可以访问了,但是还有一些小小细节什么的,单图多图之类的,注释应该解释全了(实际上还有一个动图,不过我好像没有需求,有需要的可以自行更改)
总的代码是这样的:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from six.moves import urllib
import time
purl = "https://www.pixiv.net/"
# 模拟登录
browser = webdriver.Chrome()
browser.get(purl)
login1 = browser.find_element_by_class_name("signup-form__submit--login")
login1.click()
user = 'xxxxxx'
passwd = 'xxxxxx'
user_class = browser.find_element_by_class_name("degQSE")
passwd_class = browser.find_element_by_class_name("hfoSmp")
login2 = browser.find_element_by_class_name("jvCTkj")
user_class.send_keys(user)
passwd_class.send_keys(passwd)
login2.click()
# 模拟搜索
time.sleep(10)
search = browser.find_element_by_tag_name("input")
# browser.find_element_by_partial_link_text("搜索作品")
key = "归终"
key = input('请输入爬取关键字:')
search.send_keys(key)
search.send_keys(Keys.ENTER)
# 模拟下载
time.sleep(10)
photo_class_li = browser.find_element_by_class_name("krFoBL").find_elements_by_tag_name("a")
hrefs=[]
res_href=[]
num=1
print("正在获取链接......")
#获取所有a标签中的链接
for href in photo_class_li:
hrefs.append(href.get_attribute("href"))
#过滤其中重复的与作者的链接
for href in hrefs:
if num>60:
break
res_href.append(hrefs[num])
num+=4
print(photo_class_li)
print("搜索到li,开始逐个进入")
for href in res_href:
time.sleep(3)
# print("当前进入到:",end="")
print("当前爬取的图片地址是:"+href)
browser.get(href)
# picture.click()
time.sleep(4)
#多图页面的标志是存在"查看全部"这个标签,点击它就可以展开了
try:
browser.find_element_by_class_name("wEKy")
browser.find_element_by_class_name("wEKy").click()
print("采取多图")
print("加载多图中...请稍等")
time.sleep(10)
pictures = browser.find_element_by_class_name("beQeCv").find_elements_by_tag_name("a")
for p in pictures:
pnum=1
p.click()
ture_temp = browser.find_element_by_class_name("cKLKGN").find_element_by_tag_name("img")
url_temp=ture_temp.get_attribute("src")
# 添加请求头
opener = urllib.request.build_opener()
opener.addheaders = [('Referer', "https://www.pixiv.net/member_illust.php?mode=medium&illust_id=60541651")]
urllib.request.install_opener(opener)
# 请求下载
urllib.request.urlretrieve(url_temp, f'./pictures/{pnum}+{url_temp.split("/")[-1]}')
pnum=pnum+1
ture_temp.click()
except:
print("采取单图")
#单图
true_picture_class = browser.find_element_by_class_name("beQeCv").find_element_by_tag_name("a")
true_picture_class.click()
true_picture = browser.find_element_by_class_name("cKLKGN").find_element_by_tag_name("img")
#查询src地址
url = true_picture.get_attribute("src")
#添加请求头
opener = urllib.request.build_opener()
opener.addheaders = [('Referer', "https://www.pixiv.net/member_illust.php?mode=medium&illust_id=60541651")]
urllib.request.install_opener(opener)
#请求下载
urllib.request.urlretrieve(url, f'./pictures/{url.split("/")[-1]}')
browser.back()项目结构很简单,就一个pictures和一个.py
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:记一次selenium爬取p站图片的经历(成功啦) - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 