一、问题背景
前情提要(第5.8章节):
【Python可视化大屏】全流程揭秘实现可视化数据大屏的背后原理!
在用Page函数拖拽组合完大屏时,点击页面左上角的Save Config,会生成一个文件:chart_config.json
这个文件是什么?有什么作用?怎么高效利用它?
二、揭开json文件神秘面纱
打开json文件后,如下: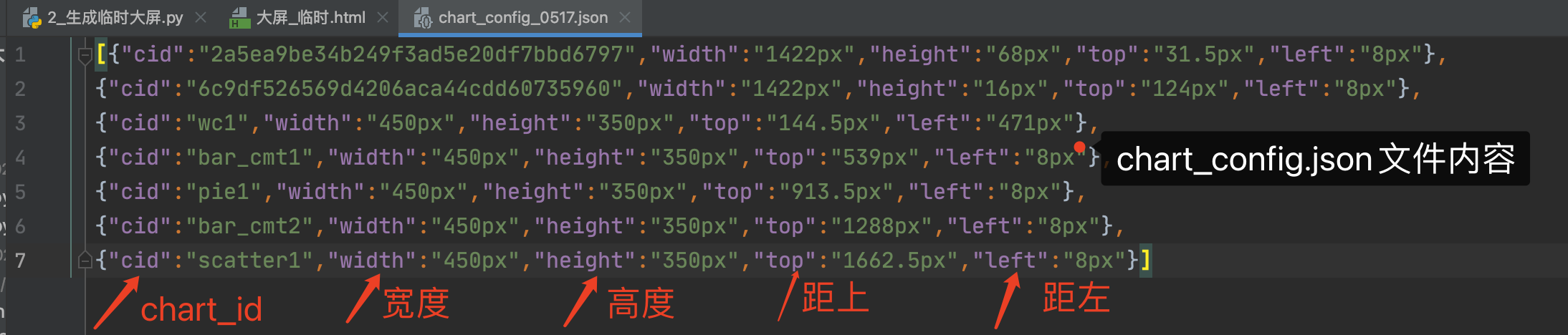

json是一个由dict组成的列表,每个dict的key分别是:
- cid:chart_id,图表的唯一标识
- width:图表的宽度
- height:图表的高度
- top:距离顶部的大小,多少px像素
- left:距离左侧的大小,多少px像素
也就是说,json文件以chart_id为标识,记录了每个图表的所在大屏的属性(大小、位置等)
有了这个json配置文件,下一步生成最终大屏html文件的时候,pyecharts就知道每个图表摆放在什么位置,大小是多少了:
Page.save_resize_html(
source="大屏_临时.html",
cfg_file="chart_config.json",
dest="大屏_最终.html"
)
是不是很好理解了。
三、巧用json文件
既然我们理解了json文件的内容和作用,什么时候需要用到它呢?
如果你跑完数据,拖拽组合大屏完成,生成了json文件和最终大屏,发现效果图表有问题,数据不对,但是大屏的图表没问题,都很美观,此时,只需要重新跑一遍数据,不需要重新组合拖拽大屏,就可以巧妙利用这个json文件。
所以,关键点来了(敲黑板!期末要考!!)
在开发各个子图表时,一定要在每个图表的初始化配置项opts.InitOpts里面,设置上chart_id,就像这样:
词云图:
WordCloud(init_opts=opts.InitOpts(width="450px", height="350px", theme=theme_config, chart_id='wc1'))
涟漪散点图:
EffectScatter(init_opts=opts.InitOpts(width="450px", height="350px", theme=theme_config, chart_id='scatter1'))
柱形图:
Bar(init_opts=opts.InitOpts(theme=theme_config, width="450px", height="350px", chart_id='bar_cmt1'))
每个图表都设置了chart_id(重点!)
不然保存json文件时,pyecharts会给图表生成随机的chart_id,后面巧用json文件时就会很麻烦,需要手动替换chart_id了!
当把最新的数据重新跑完,生成好大屏_临时.html后,直接执行3_生成最终大屏.py就行,
不需要重新拖拽了!
不需要重新拖拽了!
不需要重新拖拽了!
重要的事情说三遍。
非常快速高效的生成最终大屏!(因为chart_config.json里面已经记录了上次拖拽的结果)
非常优雅对不对?
好了,关于chart_config.json的剖析就到这里!
四、关于Table图表
关于pyecharts里的Table组件,这里需要特殊说明。
由于Table不是Echarts框架的标准图表类型,属于HTML的原生表格,所以它不支持设置chart_id。(关于此事,我特意咨询了pyecharts框架的原作者 ,在此感谢大佬解答!)
所以,只能从临时大屏的html文件里,找出table的chart_id,把它粘贴到json文件中,才可以继续巧用josn文件。
五、同步讲解视频
5.1 讲解json的视频
https://www.zhihu.com/zvideo/1509818909490876416
5.2 讲解全流程大屏的视频
https://www.zhihu.com/zvideo/1503013679826690048
5.3 讲解全流程大屏的文章
https://zhuanlan.zhihu.com/p/505408710
by: 马哥python说
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:详细剖析pyecharts大屏的Page函数配置文件:chart_config.json - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 