前言
在爬爬爬的时候,有些网页的数据并不存在于html中,它们常出现在scrip标签或js文件里面,所有这时候使用xpath就有些不尽人意了。但是,我们可以直接使用re对script的内容进行提取,然后再转json格式,再通过字典索引的方法对数据逐个提取。但是,面对近百万字符的文本,正则的运行速度堪忧。
使用re提取js文件的内容:
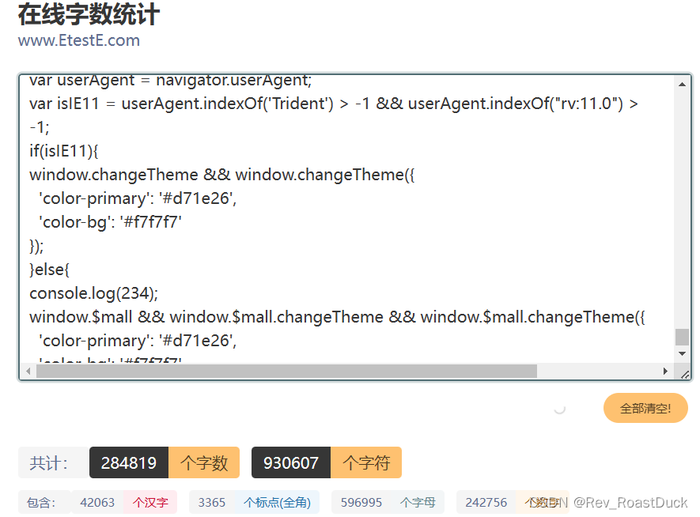

耗时:
主要思路
- 把获取到的文本,存到txt文件(txt文件作为中间处理管道)
- 获取特定行的内容
- 正则解析
下面提供两种思路:
linecache获取特定行
这里,我们以知道数据所在的位置为前提,直接定位到数据,减少正则的查找操作。
下面使用linecache.getline(filename, lineno, module_globals=None)
# 导包
import linecache
# 获取html内容
url = ""
resp=requests.get(url)
t1=time.time()
# 储存到txt文件
file="m.txt"
with open(file,"w",encoding="utf8") as f:
f.write(resp.text)
# linecache获取特定行
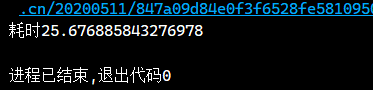
text=linecache.getline(file, 32)
# 正则解析
re_Info_obj = re.compile(
r'window.pageConfigData\["product"] = (.*);', re.S)
reInfo = re_Info_obj.findall(text)[0]
print(reInfo)
t2=time.time()
print(f"耗时{t2-t1}")
耗时:
file.readlines()获取特定行的内容
"""接上文获取html内容、储存到txt文件的操作"""
# 起始行数,结束行数
start=31
end=32
# 储存结果
text=""
# 获取特定行
with open(file,encoding='utf-8',) as f:
# 一行一行地读取
line=f.readlines()
# 枚举
for i,rows in enumerate(line):
if i in range(start,end):
#拼接文本
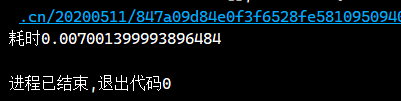
text+=rows
耗时:

for循环读取获取特定行的内容
"""接上文获取html内容、储存到txt文件的操作""
# 储存数据
text=""
# 数据所在的位置
row=31
with open(file,encoding='utf-8',) as f:
n=0
for content in f:
if start==n:
#拼接
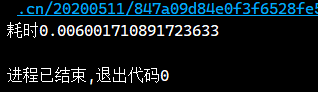
text+=content
n+=1
耗时:
此外
对于json检索,我们还可以通过减少对原文本的次数来提高程序效率。这里简单说一下,比如有一个多层嵌套的字典,
dict={
"salesInfo": {
"id": "462767448039731200",
"shop": {
"name": "汕头市丽德美针织制衣有限公司",
"id": "462530681697091584"
}
}
}
想要提高运行效率,一般不使用以下方法检索,
name=dict["salesInfo"]["shop"]["name"]
id=dict["salesInfo"]["shop"]["id"]
我们可以先缩小检索范围,避免重复搜索["salesInfo"]["shop"],可以这样做,
shop = dict["salesInfo"]["shop"]
name=shop["name"]
id=shop["id"]
完事!!!溜~
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:正则解析提速方案_爬虫 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 