1.字段加密--django-mirage-field
一个django模型字段,在保存到数据库时对数据进行加密,在从数据库获取数据时进行解密。它使数据库中的数据始终加密。
A Django model fields collection that encrypt your data when save to and decrypt when get from database. It keeps data always encrypted in database. Base on AES, it supports query method like get() and filter() in Django.
Mirage can also migrate data from origin column to encrypted column in database with a good performance.
需要导入的模块为;
from mirage.crypto import Crypto
案例:
from mirage.crypto import Crypto c = Crypto() # key is optional, default will use settings.SECRET_KEY ###密钥是可选的,默认情况下将使用settings.secret处的key c.encrypt('some_address') # -bYijegsEDrmS1s7ilnspA== c.decrypt('-bYijegsEDrmS1s7ilnspA==') # some_address
https://github.com/luojilab/django-mirage-field
https://www.cnpython.com/pypi/django-mirage-field
2.SQL Server 语句不能完整执行的问题
变动的文件为/sql/engines/mssql.py,修改的方法是 execute_check 和 execute 。
在split_sql = [f"""use [{db_name}]"""] 代码行后面,添加以下语句:
split_sql = split_sql + ['SET NOCOUNT ON;'] #### 解决SQL Server 语句出现更新失败的情况,失败指执行不报错,但是SQL语句完全没有执行或只执行了部分语句。
参考网址 ; https://www.cnpython.com/qa/402147
3. 其中Redis 的安装
Redis安装包下载路径 如下:
https://redis.io/download
如果下载的版本是 redis-5.0.14.tar.gz

redis 的启动命令:
./redis-server /XXXXX/redis-5.0.14/redis.conf
密码设置可参照
https://www.cnblogs.com/xincha/p/16165760.html
4. 异步调用 async_task
很多地方 是异步调用的,使用的是django_q中的async_task。
from django_q.tasks import async_task
关于async_task的运行环境,其设置来自于settings.py. 在.../archery/settings.py中设置.

Welcome to Django Q 【官方文档】
https://django-q.readthedocs.io/en/latest/index.html
5.get_object_or_404
get_object_or_404 是Django的django.shortcuts的方法,用来查询数据,或者抛出一个DoesNotExist的异常。
用的是ORM中的get方法。
Def get_object_or_404(klass,*args,**kwargs):
需要三个参数:
klass 是一个model对象或者是一个mange.query 对象
*args和**kwargs 是查询使用到的参数(在klass中查询)。
6.GoInception兼容域名 可能遇到的问题
我们知道GoInception是支持IP,例如在备份服务器上,备份库的命名格式为:IP_PORT_库名,例如127_0_0_1_3306_test。
如果需要支持兼容域名,则下面的三个问题需要留意:
(1)数据库的命名规则时不能超过64位,如果是域名_端口_库名,很容易超过64位。如果依照这域名_端口_库名 去找这个数据库,则这个数据库可能不存在不存在。
(2)大家想下,goinception在执行的时候, 它产生了一个备份库,那个这个备份库的名字是什么呢? 原来它是做了一个截取,是 保留 域名_端口_库名 命名的后面的64位。
(3)字符串特殊转换,当域名(其实IP也是这个规则) 中含有. 或 – 字符时,自动转换为_,然后再拼凑备份库。
7.判断对象是否有指定的属性
hasattr() 函数用于判断对象是否包含对应的属性。
hasattr(object, name)
- object -- 对象。
- name -- 字符串,属性名。
如果对象有该属性返回 True,否则返回 False。
8.多线程并发执行的解决思路
目前 Archery是不支持分片的,即不支持并发。这与应用场景不符,限制了使用场景,迫切需要二开。
我们首先先看下分库分表的类型。
(1)多实例多库。即根据业务需要和资源限制,分片规则是部署在多个实例上,并且一个实例上部署了多个数据库,当然数据库的名字是不能一样的。
例如,订单库,根据设计和部署要求,订单分了64个分库,每个集群上部署了4个库;即orderdb1,orderdb2,orderdb3,orderdb4 这四个库部署在了MHA集群1上,4个分库共用一个DB实例,类似 orderdb5,orderdb6,orderdb7,orderdb8这四个库部署在了MHA集群2上,这四个库共用另一个DB实例 。。。。。。依次类推
(2)多实例单库。即根据业务和资源需要,分片规则是部署在多个实例上,并且一个实例上只部署一个DB,此时数据库的名字可以一样的。
例如,物流信息库,物理库分了32库,部署了32套mha集群,每套集群上只有一个数据库。在所有的集群上的db名字可以一样(不强求)。
(3)单实例多库。即分库了,但是所有的数据库都在一个实例上(一个mha集群上),当然此时数据库的名字是不能一样的。
(4)单实例单库多表。即分表未分库。这种情况,我们是不建议的,应该舍弃,多线程并发执行的解决方案不考虑这种情况。因为这种不容易扩展,当性能有压力时,还是不能横向扩展的,即不能很快的部署到多个集群上。扩展,需要研发、测试、SRE 配合。
分库分表工单执行与多并非解决思路:
只要表相同(表名相同、表结构相同),在提交时判断生成多任务工单。按照DB实例(集群)个数生成一级子任务,按照DB数据库生成二级子任务。一级子任务并发执行,属于统一个一级子任务的二级任务串行执行。这也符合我们收到操作的习惯,还可以避免单个实例上多个库同时执行而遇到资源不够的情况。判断多任务还是单任务,是依据提交的工单需要在单个实例上执行还是要多个实例上执行(即实在一个mha集群上执行还是在单个mha集群上执行),多个实例上执行,就是多任务,需要并发;单个实例上执行就是单任务,无需并发。
但是需要注意,各个子任务对应的SQL语句,即要执行的语句是一样的。
9.多并发--ThreadPoolExecutor
导入主要模块
from concurrent.futures import ThreadPoolExecutor
结构伪代码:
def 执行工单的方法: thread_counter = workflow_detail.task1_counter ##创建的最大线程数有工单的一级子任务数据决定 task_pool = [] executor = ThreadPoolExecutor(max_workers=thread_counter) ##设置最大线程池 ###根据一级子任务进行拆解工单 for i in range(1,thread_counter+1)###注意range(),默认是从0开始;另外,计数到stop结束,单步包括stop,所有结束值设置为thread_counter+1 task_name = workflow_detail.task1_counter(i) ###伪代码,即子任务对应的工单具体内容 task_pool.append(task_name) for result in executor.map(execute_multtask_fun,task_pool) execute_result = result def execute_multtask_fun(task_name); """供多线程调用的单个方法""" 处理一个一级子任务的代码
注意的是:按照我们多线程并发执行的解决思路,各个子任务对应的SQL语句,即要执行的语句是一样的。
多线程的知识,可以参照:
《线程池ThreadPoolExecutor类的使用》
https://blog.51cto.com/u_12004792/3138599
10.LDAP登陆设置(AD账户登录)
在 archery/settings.py中设置,
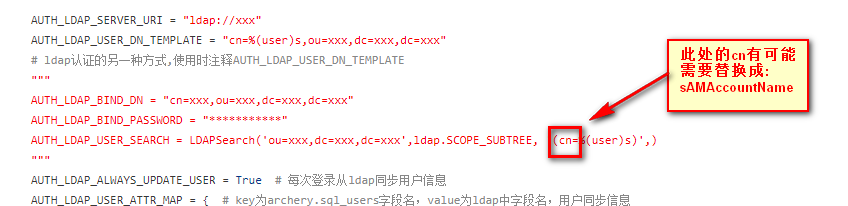
# LDAP ENABLE_LDAP = False if ENABLE_LDAP: import ldap from django_auth_ldap.config import LDAPSearch AUTHENTICATION_BACKENDS = ( 'django_auth_ldap.backend.LDAPBackend', # 配置为先使用LDAP认证,如通过认证则不再使用后面的认证方式 'django.contrib.auth.backends.ModelBackend', # django系统中手动创建的用户也可使用,优先级靠后。注意这2行的顺序 ) AUTH_LDAP_SERVER_URI = "ldap://xxx" AUTH_LDAP_USER_DN_TEMPLATE = "cn=%(user)s,ou=xxx,dc=xxx,dc=xxx" # ldap认证的另一种方式,使用时注释AUTH_LDAP_USER_DN_TEMPLATE """ AUTH_LDAP_BIND_DN = "cn=xxx,ou=xxx,dc=xxx,dc=xxx" AUTH_LDAP_BIND_PASSWORD = "***********" AUTH_LDAP_USER_SEARCH = LDAPSearch('ou=xxx,dc=xxx,dc=xxx',ldap.SCOPE_SUBTREE, '(cn=%(user)s)',) """ AUTH_LDAP_ALWAYS_UPDATE_USER = True # 每次登录从ldap同步用户信息 AUTH_LDAP_USER_ATTR_MAP = { # key为archery.sql_users字段名,value为ldap中字段名,用户同步信息 "username": "cn", "display": "displayname", "email": "mail" }
需要特别指出的是:
11.DEBUG=False静态文件无法访问
静态文件不能加载导致的问题:
(1)页面排版不正常,css文件不能正常加载;
(2)通过url不能访问静态文件,如图片等。
解决方案
在urls.py文件中,添加以下代码:
from django.views import static ##新增 from django.conf import settings ##新增 from django.conf.urls import url ##新增 urlpatterns = [ ...... ## 以下是新增 url(r'^static/(?P<path>.*)$', static.serve,{'document_root': settings.STATIC_ROOT}, name='static'), ]
特别注意
此时 login 登录访问时,调用的static可能还会有302 异常,需要进一步设置。
在.../common/middleware/check_login_middleware.py文件中,修改 url例外 规则
.... ##调整前 ##IGNORE_URL_RE = r'/admin/w*' ##调整后 IGNORE_URL_RE = r'(/admin/w*|/static/w*)' .....
参考
https://archerydms.com/modules/auth/
https://blog.csdn.net/oscar999/article/details/121216835
https://zhuanlan.zhihu.com/p/151855280
检验是改进的基础,持续验证,持续改进。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:SQL Archery 代码说明及优化(一) - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 