
1、BERT简介
首先需要介绍什么是自监督学习。我们知道监督学习是有明确的样本和对应的标签,将样本丢进去模型训练并且将训练结果将标签进行比较来修正模型,如下图: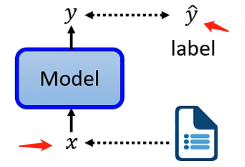
而自监督学习就是没有标签也要自己创建监督学习的条件,即当前只有样本x但是没有标签\(\hat{y}\),那具体的做法就是将样本x分成两部分\(x\prime\)和\(x\prime \prime\),其中一部分作为输入模型的样本,另一部分来作为标签:
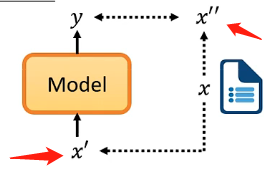
如果觉得很抽象也没关系,请继续往下阅读将会逐渐清晰这个定义。
1.1、BERT的masking
BERT的架构可以简单地看成跟Transformer中的Encoder的架构是相同的(可以参考我这篇文章[点此]([机器学习]李宏毅——Transformer - 掘金 (juejin.cn))),其实现的功能都是接受一排向量,并输出一排向量。而BERT特别的地方在于它对于接受的一排输入的向量(通常是文字或者语音等)会随机选择某些向量进行“遮挡”(mask),而进行遮挡的方式又分为两种:
- 第一种是将该文字用一个特殊的字符来进行替代
- 第二种是将该文字用一个随机的文字来进行替代
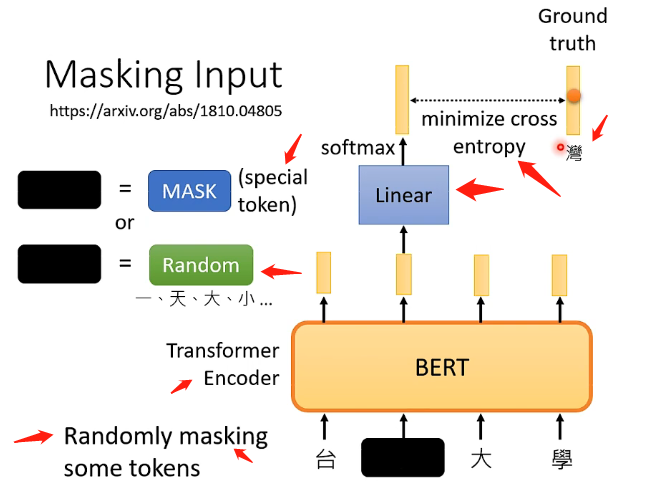
而这两种方法的选择也是随机的,因此就是随机选择一些文字再随机选择mask的方案来进行遮挡。然后就让BERT来读入这一排向量并输出一排向量,那么训练过程就是将刚才遮挡的向量其对应的输出向量,经过一个线性变换模型(乘以一个矩阵)再经过softmax模块得到一个result,包含该向量取到所有文字的所有概率,虽然BERT不知道被遮挡的向量代表什么文字但我们是知道的,因此我们就拿答案的文字对应的one-hat-vector来与向量result最小化交叉熵,从而来训练BERT和这个线性变换模块,总体可以看下图:
1.2、Next Sentence Prediction
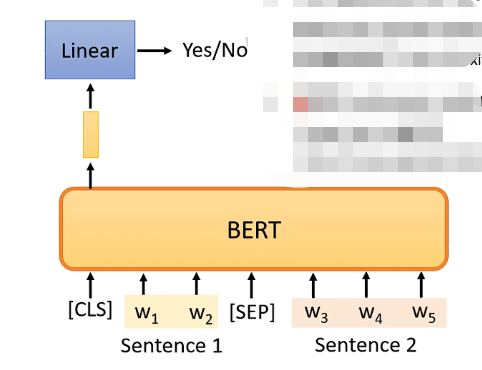
这个任务是判别两个句子它们是不是应该连接在一起,例如判断“我爱”和“中国”是不是应该连在一起,那么在BERT中具体的做法为:
- 先对两个句子进行处理,在第一个句子的前面加上一个特殊的成为CLS的向量,再在两个句子的中间加上一个特殊的SEP的向量作为分隔,因此就拼成了一个较长的向量集
- 将该长向量集输入到BERT之中,那么就会输出相同数目的向量
- 但我们只关注CLS对应的输出向量,因此我们将该向量同样经过一个线性变换模块,并让这个线性变换模块的输出可以用来做一个二分类问题,就是yes或者no,代表这两个句子是不是应该拼在一起
具体如下图:
而前面我们介绍了两种BERT的应用场景,看起来似乎都是填空题或者判断题,那么是否BERT只能够用于这种场景之下呢?当然不是!BERT具有强大的能力,它不仅可以用来解决我们感兴趣的下游任务,更有趣的是,它只需要将刚才训练(Pre-train)完成的可以处理填空题任务的简单BERT进行微调(Fine-tune)就可以用来高效地解决一些下游、复杂的任务。也就是说BERT只需要先用简单的任务来进行Pre-train,然后再进行微调就可以用于我们感兴趣的下游复杂任务!
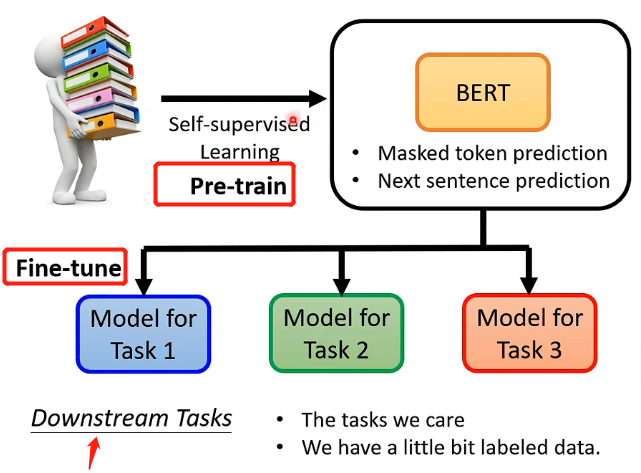
这里补充一个知识点,因为BERT这类模型可以进行微调来解决各种下游任务,因此有一个任务集为GLUE,里面包好了9种自然语言处理的任务,一般评判BERT这种模型就是将BERT分为微调来处理这9个任务然后对正确率等进行平均。9个任务如下:

1.3、How to ues BERT
Case 1
Case 1 是接受一个向量,输出一个分类,例如做句子的情感分析,对一个句子判断它是积极的还是消极的。那么如何用BERT来解决这个问题呢,具体的流程如下:
- 在句子对应的一排向量之前再加上CLS这个特殊字符所对应的向量,然后将这一整排向量放入BERT之中
- 我们只关注CLS对应的输出向量,将该向量经过一个线性变换(乘上一个矩阵)后再经过一个softmax,输出一个向量来表示分类的结果,表示是积极的还是消极的
而重要的地方在于线性变换模块的参数是随机初始化的,而BERT中的参数是之前就pre-train的参数,这样会比随机初始化的BERT更加高效。而这也代表我们需要很多句子情感分析的样本和标签来让我们可以通过梯度下降来训练线性变换模块和BERT的参数。如下图:
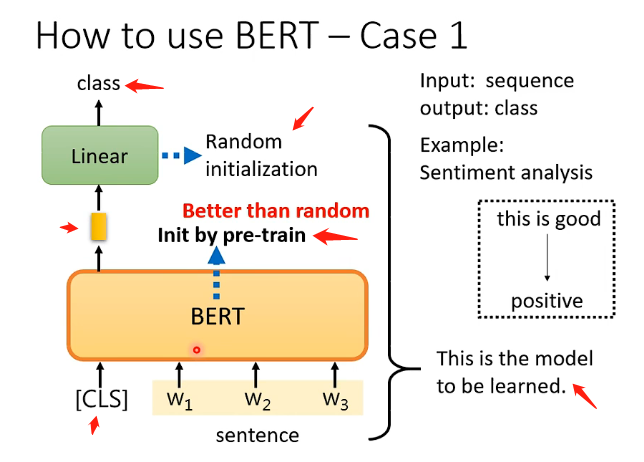
一般我们是将BERT和线型变换模块一起称为Sentiment analysis。
Case 2
这个任务是输入一排向量,输出是和输入相同数目的向量,例如词性标注问题。那么具体的方法也是很类似的,BERT的参数也是经过pre-train得到的,而线性变化的参数是随机初始化的,然后就通过一些有标注的样本进行学习,如下图:
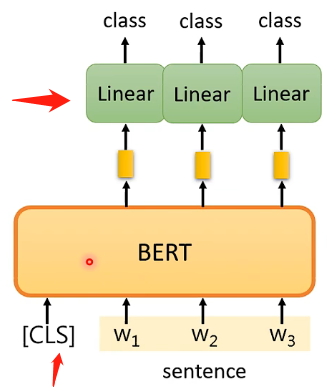
Case 3
在该任务中,输入是两个句子,输出是一个分类,例如自然语言推断问题,输入是一个假设和一个推论,而输出就是这个假设和推论之间是否是冲突的,或者是相关的,或者是没有关系的:
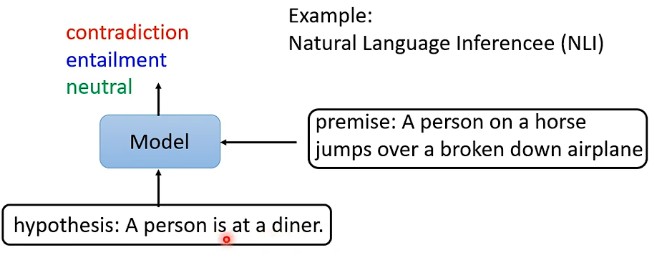
那么BERT对这类任务的做法也是类似的,因为要输出两个句子,因此在两个句子之间应该有一个SEP的特殊字符对应的向量,然后在开头也有CLS特殊字符对应的向量,并且由于输出是单纯一个分类,那关注的也是CLS对应的输出向量,将其放入线性变换模块再经过softmax就得到分类结果了。参数的设置跟之前都是一样的。如下图:
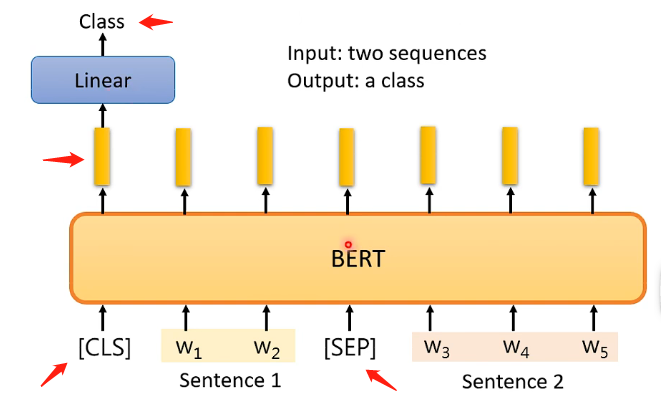
Case 4
BERT还可以用来做问答模型!但是对这个问答模型具有一定的限制,即需要提供给它一篇文章和一系列问题,并且要保证这些问题的答案都在文章之间出现过,那么经过BERT处理之后将会对一个问题输出两个正整数,这两个正整数就代表问题的答案在文章中的第几个单词到第几个单词这样截出来的句子,即下图的s和e就能够截取出正确答案。
那么BERT具体在做这件事时,也是将文章和问题看成两个向量集,那么同样在它们中间要加上SEP,在开头要加上CLS,然后经过BERT之后会产生相同数目的向量。那么关键地方在于会初始化两个向量称为A和B,它们的长度和BERT输出的向量的长度相同,那首先拿A和文章对应的所有输出向量逐个进行点乘,每一个都得到一个数字,再全部经过softmax,然后看看哪一个最终的结果最大,最大的就是对应s的取值;B也是同理经过相同的处理最后取最大的作为e的取值,那么得到s和e之后就可以去文章中取答案了!如下图: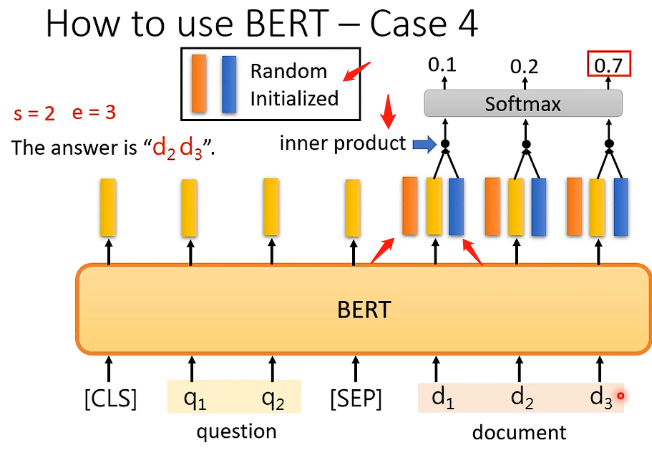
那么我们要训练的就是随机初始化的两个向量和已经pre-train的BERT。
1.4、Pre-train seq2seq model
前面介绍的BERT的各种应用场景都没有用在seq2seq的场景,那么如果要将BERT用于这个场景呢还需要再加上一个Dncoder,即:
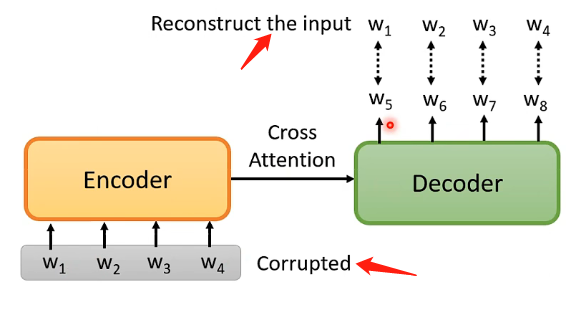
先将原始的输入加入一定的干扰,然后经过Encoder和Decoder之后呢输出的向量是和原来的输入具有相同的数目,那么目的就是希望输出向量能够和未加干扰之前的向量集足够接近。
具体的干扰方法也是多种多样:
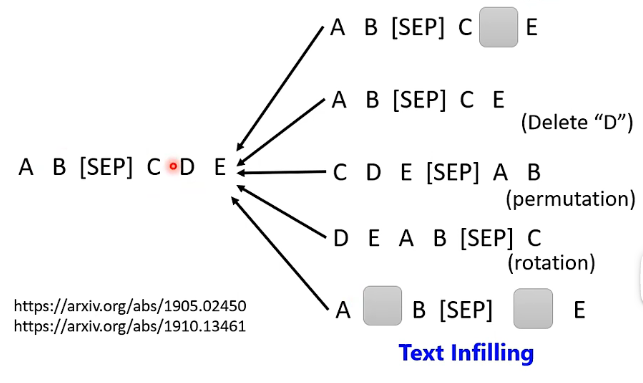
2、BERT的奇闻轶事
2.1 Why does BERT work?
先从一个事实来说明为什么BERT能够在文字处理中如此有效。
在BERT中,如果我们给它一个句子,也就是一排向量,那么它对应输出的向量可以认为里面包含了对应输入向量文字的含义,怎么理解呢?看下面的例子,例如我们给输入”台湾大学“,那么BERT的对应”大“的输出其实可以认为它是知道其含义的。这么说明可能有点抽象,我们需要通过下一个例子来解释。
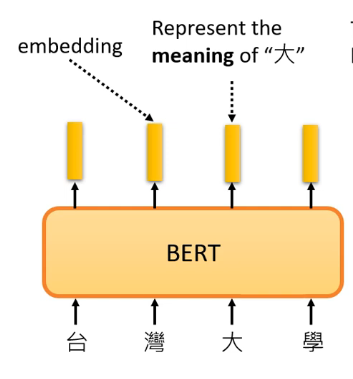
由于中文中常常存在一词多意,那么现在假设苹果的苹的两个含义,收集关于苹果的各种句子和关于苹果手机的各种句子让BERT先进行训练, 然后再输入关于苹果的五条句子和关于苹果手机的五条句子,如下图:
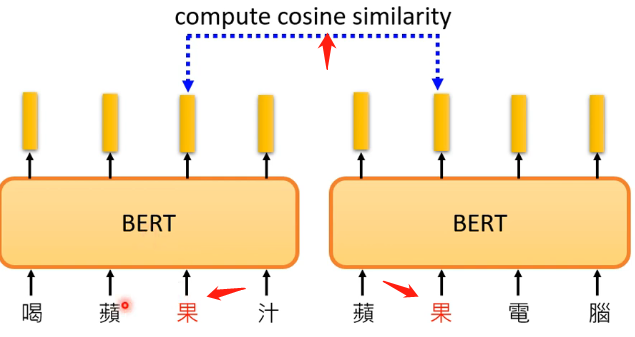
然后我们就来检查,两个意义中的“苹”字对应的输出向量之间的相似性,结果如下图:
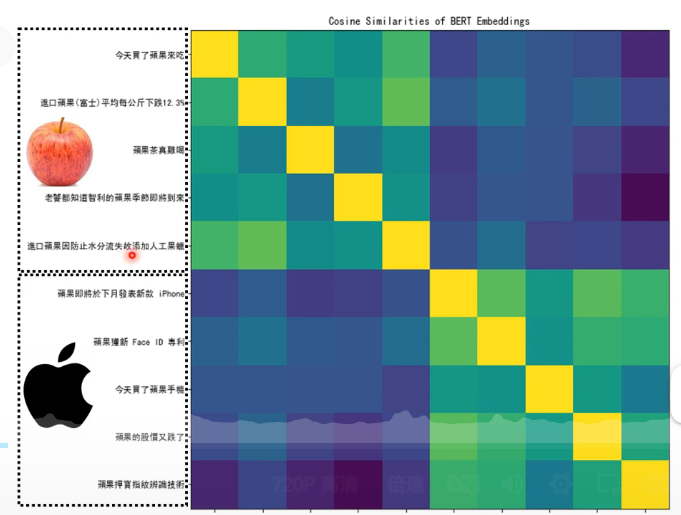
可以看到,关于吃的苹果的句子之中“苹”的对应输出向量,它们彼此之间相似性较高;关于苹果手机的也是;但是如果是不同的“苹“那么相似性则较低。
为什么会有这种神奇的现象呢?难道是BERT学会了这个文字的多个含义吗?
实际上是因为在训练的时候我们将”苹“遮住的话,BERT要从上下文来分析做出预测,它会发现这两种不同的”苹“所对应的上下文经常是不一样的,因此它做出预测的输出向量也就会存在差异!在许多论文上都是这个说法的。或者也可以认为由于上下文给这个遮掉的单词赋予了一定的意义,那么有可能,具有类似含义的单词在上下文就会比较接近(例如食物的话上下文可能都跟餐具有关),那么在做出预测的时候就向量比较接近。
2.2、Multi-lingual BERT
这个模型也就是用很多种语言来训练一个模型:
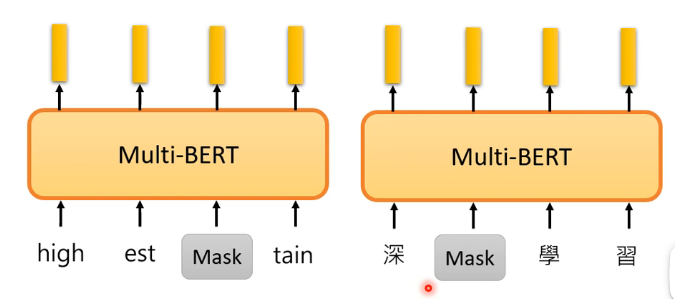
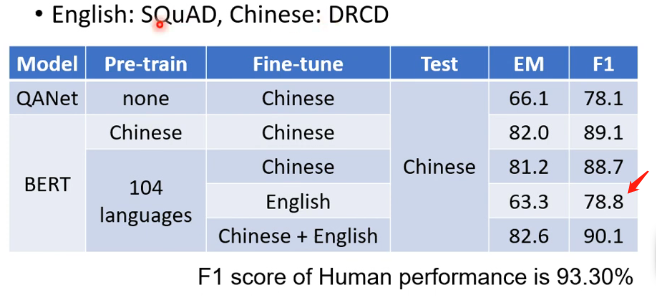
那么有一个实验室表现了BERT的神奇之处,也就是用了104种语言Pre-trainBERT,也就是教BERT做填空题,然后再用英文的问答资料来教BERT做英文的问答题,再在测试集中用中文的问答题来测试BERT,它的结果如下,可以达到这个正确率真的很令人吃惊!因为在BERT之前最好的是QANet,它的正确率比这样的BERT还低!
2.3、语言的资讯
经过上述中英文的训练,现在思考的问题是:为什么你给的是英文的训练集,在测试集的中文中,它不会给你在预测的地方预测出英文呢?那么这是否可以说明在BERT中实际上它是能够区分不同语言之间的差别,而不是单纯的将其看做一个向量呢?那么来做下面这个实验:如果把所有中文都放进去BERT得到输出然后平均得到一个向量,英文也是相同做法得到一个向量,然后将这两个向量进行相减得到一个差值的向量;再将英文一句话丢进去BERT,得到输出后加上这个差值的向量,会出现这个神奇的现象:
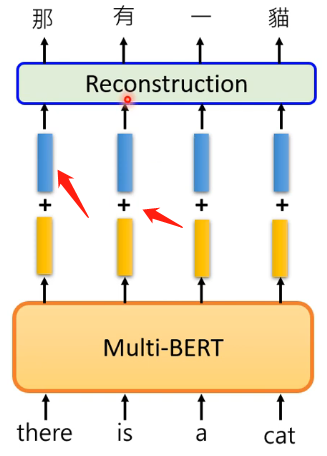
可以发现居然可以直接实现了翻译的功能!再来看更复杂的例子:

可以看到虽然BERT不能够完全地将中文转为英文,但是在某些单词上还是能够正确的转换的!这也表达了BERT的强大之处。
3、GPT的野望
GPT做的事情和BERT所做的填空题是不一样的,GPT具体做的是根据当前的输入预测下一个时刻可能的token,例如下图:
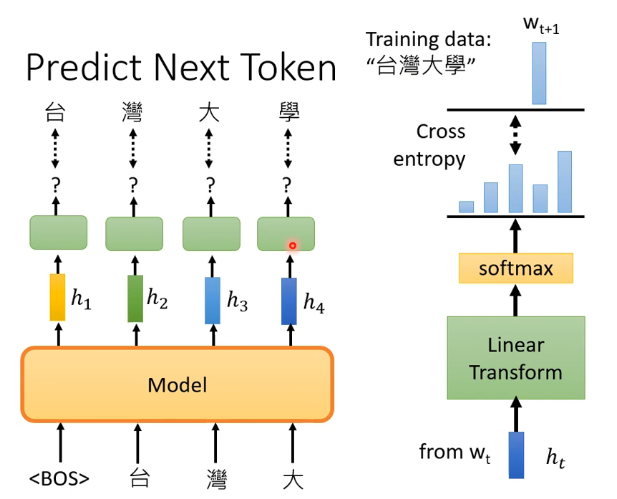
即给出Begin of Sequence,就预测出台,然后给出BOS和台就预测出湾,以此类推。对输出向量的处理就是右边那部分,先经过一个线性变化后再经过softmax得到结果向量,再跟理想结果来计算交叉熵,然后是最小化交叉熵来训练的。
那么要注意的地方是它预测的时候看到的只有上文而已,即不知道后面的句子是什么。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:【机器学习】李宏毅——自监督式学习 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
