机器学习方法简介
机器学习、人工智能、深度学习是什么关系?
机器学习研究和构建的是一种特殊算法(而非某一个特定的算法),能够让计算机自己在数据中学习从而进行预测。
Arthur Samuel给出的定义指出,机器学习是这样的领域,它赋予计算机学习的能力(这种学习能力)不是通过显著式编程获得的。
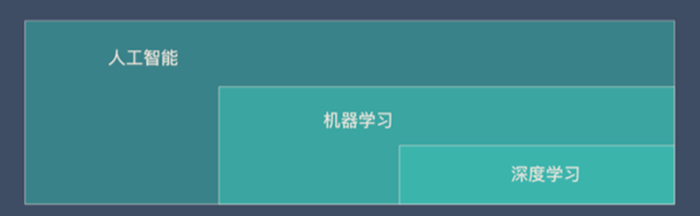
不管是机器学习还是深度学习,都属于人工智能(AI)的范畴。所以人工智能、机器学习、深度学习可以用下面的图来表示:

机器学习的基本思路
1.把现实生活中的问题抽象成数学模型,并且很清楚模型中不同参数的作用
2.利用数学方法对这个数学模型进行求解,从而解决现实生活中的问题
3.评估这个数学模型,是否真正的解决了现实生活中的问题,解决的如何?
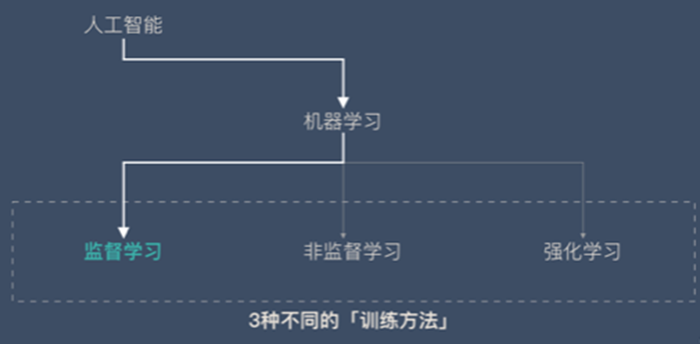
机器学习分类
监督学习
监督学习:指我们给算法一个数据集,并且给定正确答案。机器通过数据来学习正确答案的计算方法。
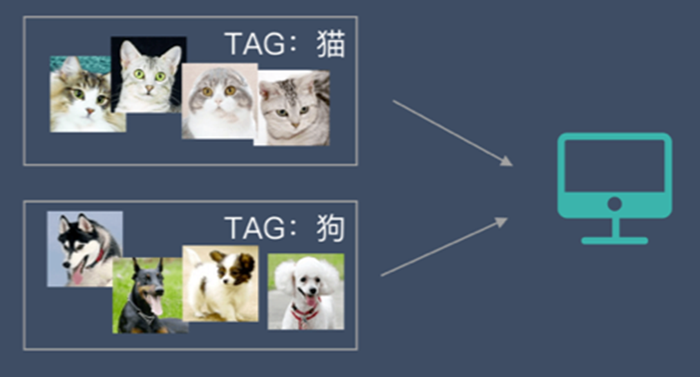
这种通过大量人工打标签来帮助机器学习的方式就是监督学习。这种学习方式效果非常好,但是成本也非常高。

监督学习的2个任务:
1.回归:预测连续的、具体的数值。比如:支付宝里的芝麻信用分数
2.分类:对各种事物分门别类,用于离散型预测

“回归”案例:个人信用评估方法——FICO
FICO 评分系统得出的信用分数范围在300~850分之间,分数越高,说明信用风险越小。

非监督学习
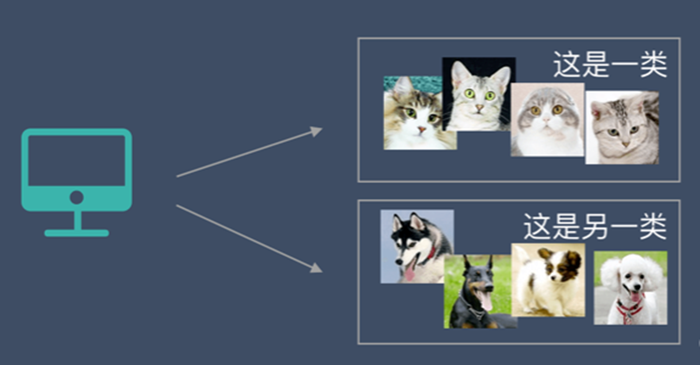
非监督学习中,给定的数据集没有“正确答案”,所有的数据都是一样的。无监督学习的任务是从给定的数据集中,挖掘出潜在的结构。

通过学习,机器会把这些照片分为2类,一类都是猫的照片,一类都是狗的照片。虽然跟上面的监督学习看上去结果差不多,但是有着本质的差别:
强化学习
在一个有特定规则的场景下,尤其是游戏。
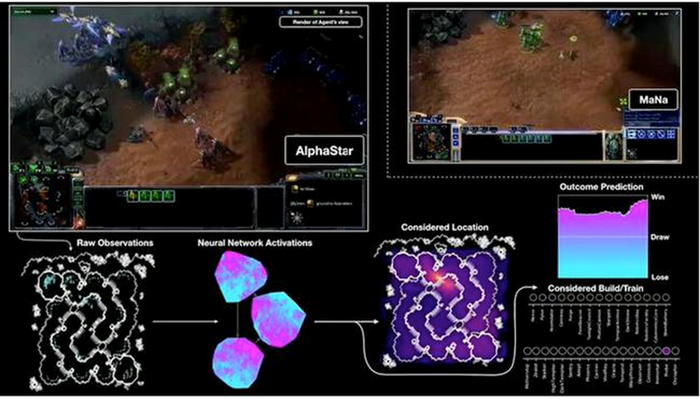
机器学习实操的步骤
机器学习在实际操作层面一共分为7步:
- 收集数据
- 数据准备
- 选择一个模型
- 训练
- 评估
- 参数调整
- 预测(开始使用)

15种经典机器学习算法
| 算法 | 训练方式 |
|---|---|
| 线性回归 | 监督学习 |
| 逻辑回归 | 监督学习 |
| 线性判别分析 | 监督学习 |
| 决策树 | 监督学习 |
| 朴素贝叶斯 | 监督学习 |
| K邻近 | 监督学习 |
| 学习向量量化 | 监督学习 |
| 支持向量机 | 监督学习 |
| 随机森林 | 监督学习 |
| AdaBoost | 监督学习 |
| 高斯混合模型 | 非监督学习 |
| 限制波尔兹曼机 | 非监督学习 |
| K-means 聚类 | 非监督学习 |
| 最大期望算法 | 非监督学习 |
主流的监督学习算法
| 算法 | 类型 | 简介 |
|---|---|---|
| 朴素贝叶斯 | 分类 | 贝叶斯分类法是基于贝叶斯定定理的统计学分类方法。它通过预测一个给定的元组属于一个特定类的概率,来进行分类。朴素贝叶斯分类法假定一个属性值在给定类的影响独立于其他属性的 —— 类条件独立性。 |
| 决策树 | 分类 | 决策树是一种简单但广泛使用的分类器,它通过训练数据构建决策树,对未知的数据进行分类。 |
| SVM | 分类 | 支持向量机把分类问题转化为寻找分类平面的问题,并通过最大化分类边界点距离分类平面的距离来实现分类。 |
| 逻辑回归 | 分类 | 逻辑回归是用于处理因变量为分类变量的回归问题,常见的是二分类或二项分布问题,也可以处理多分类问题,它实际上是属于一种分类方法。 |
| 线性回归 | 回归 | 线性回归是处理回归任务最常用的算法之一。该算法的形式十分简单,它期望使用一个超平面拟合数据集(只有两个变量的时候就是一条直线)。 |
| 回归树 | 回归 | 回归树(决策树的一种)通过将数据集重复分割为不同的分支而实现分层学习,分割的标准是最大化每一次分离的信息增益。这种分支结构让回归树很自然地学习到非线性关系。 |
| K邻近 | 分类+回归 | 通过搜索K个最相似的实例(邻居)的整个训练集并总结那些K个实例的输出变量,对新数据点进行预测。 |
| Adaboosting | 分类+回归 | Adaboost目的就是从训练数据中学习一系列的弱分类器或基本分类器,然后将这些弱分类器组合成一个强分类器。 |
| 神经网络 | 分类+回归 | 它从信息处理角度对人脑神经元网络进行抽象, 建立某种简单模型,按不同的连接方式组成不同的网络。 |
模型评估与参数优化——SVM
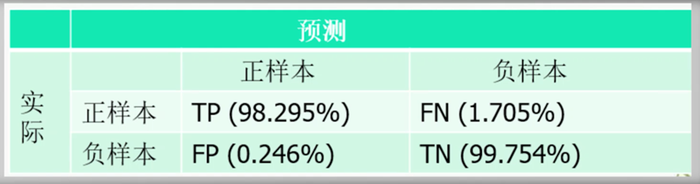
混淆矩阵

TP+FN=所有正样本的数量
FP+TN=所有负样本的数量
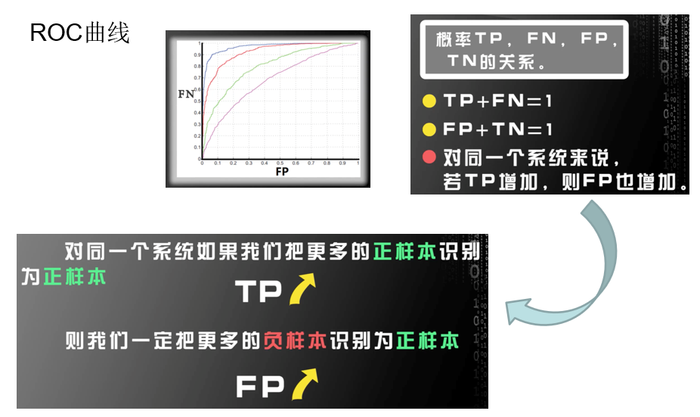
ROC曲线
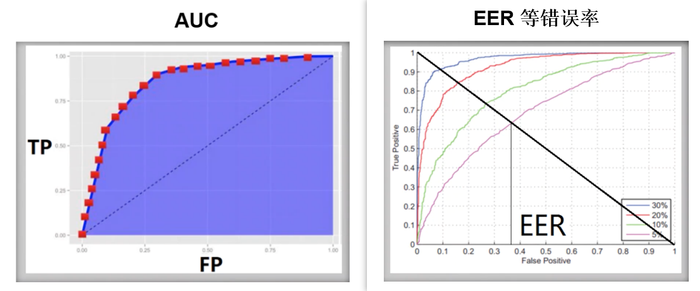
AUC Score
SVM参数调优
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split,cross_val_score,GridSearchCv
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
#pandas处理数据集
#sklearn.model selection实现数据集分割,自动调参
#sklearn,svm线性支持向量分类
#读取数据
data = pd.read csv('krkopt.data',header=None)
data.dropna(inplace=True)#不创建新的对象,直接对原始对象进行修改
数据预处理忽略,详见ppt
SVM参数
SVC(*, C=1.0, kernel='rbf', degree=3, gamma='scale', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape='ovr', break_ties=False, random_state=None)
SVC参数解释
- C: 目标函数的惩罚系数C,用来平衡分类间隔margin和错分样本的,default C = 1.0;
- kernel:参数选择有RBF, Linear, Poly, Sigmoid, 默认的是"RBF";
- degree:degree决定了多项式的最高次幂;
- gamma:核函数的系数('Poly', 'RBF' and 'Sigmoid'), 默认是gamma = 1 / n_features;
- coef0:核函数中的独立项,'RBF' and 'Poly'有效;
- probablity: 可能性估计是否使用(true or false);
- shrinking:是否进行启发式;
- tol(default = 1e - 3): svm结束标准的精度;
- cache_size: 制定训练所需要的内存(以MB为单位);
- class_weight: 每个类所占据的权重,不同的类设置不同的惩罚参数C, 缺省的话自适应;
- verbose: 跟多线程有关;
- max_iter: 最大迭代次数,default = 1, if max_iter = -1, no limited;
- decision_function_shape : ‘ovo’ 一对一, ‘ovr’ 多对多 or None 无, default=None
- random_state :用于概率估计的数据重排时的伪随机数生成器的种子。
ps:7,8,9一般不考虑。
def svm_c(x train,x test,y_train,y_test):
#xbf核函数,设置数据权重
svc = SVC(kernel='rbf',class weight='balanced',)
c_range = np.logspace(-5,15,11,base=2)
gamma range = np.logspace(-9,3,13,base=2)
#网格搜索交叉验证的参数范围,cV=3,3折交叉
param_grid =[{'kernel':['rbf']'C':c_range,'gamma':gamma_range}]
grid = GridSearchCV(svc,param_grid,cv=3,n jobs=-1)
产训练模型
clf = grid.fit(x train,y_train)
#计算测试集精度
score = grid.score(x test,y test)
print('精度为8s' % score)
网格搜索(GridSearchCV)
GridSearchCV的名字其实可以拆分为两部分,GridSearch和CV,即网格搜索和交叉验证。
网格搜索,搜索的是参数,即在指定的参数范围内,按步长依次调整参数,利用调整的参数训练学习器,从所有的参数中找到在验证集上精度最高的参数,这其实是一个训练和比较的过程。
交叉验证分为三种:简单交叉验证、S折交叉验证、留一交叉验证
GridSearchCV可以保证在指定的参数范围内找到精度最高的参数,但是这也是网格搜索的缺陷所在,他要求遍历所有可能参数的组合,在面对大数据集和多参数的情况下,非常耗时。
grid = GridSearchCV(svc, param_grid, cv=3, n_jobs=-1)
#n_jobs=-1,表示使用该计算机的全部cpu
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:大数据关键技术:常规机器学习方法 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 