
1、What
在自编码器中,有两个神经网络,分别为Encoder和Decoder,其任务分别是:
- Encoder:将读入的原始数据(图像、文字等)转换为一个向量
- Decoder:将上述的向量还原成原始数据的形式
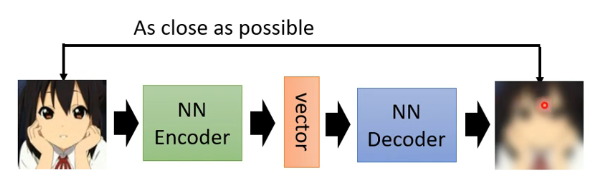
而目标是希望还原出来的结果能够与原始数据尽可能的接近。其中的向量可称为Embedaing、Representation、Code。而它的主要用处就是将原始数据(高维、复杂)经过Encoder后得到的向量(经过处理,低纬度)作为下游任务的输入。
2、Why
因为例如图像这种原始数据它的变化是有限的(不可能每一个像素点都是完全随机的,这不是我们可能看到的图片),因此如果AutoEncoder能够找到它们之间的变化规律(通常是比原始数据更简单的)那么就可以用更加简便的表达形式来表示数据,那么在下游任务训练的时候就可能可以用更简单的数据、更少的数据来学习到原来想要让机器学习到的东西了。
3、De-noising Auto-encoder
这个和普通的Auto-encoder的区别在于,Encoder的输入并不是原始的图像,而是将图像加上一定的噪声之后再作为Encoder的输入,而在输出的时候是要求Decoder输出能够与未加噪声之前的图像越接近越好,即:
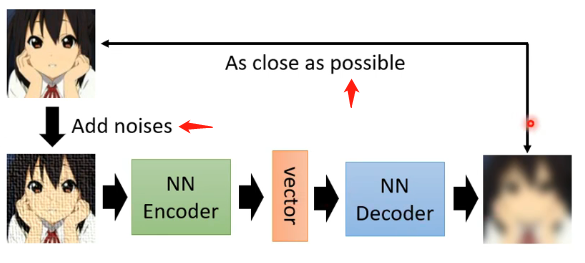
而如果我们回顾一下之前学习过的BERT,可以发现BERT实际上就是De-noising Auto-encoder,可以看下图:
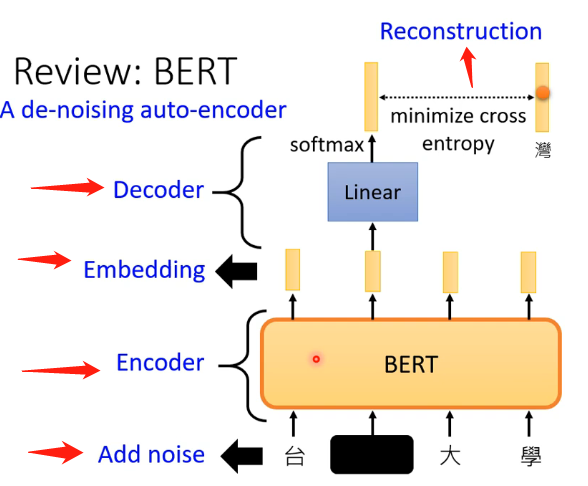
4、Feature Disentangle
特征区分技术可以用于上文介绍的Auto-encoder,具体上可以这么理解:在Auto-encoder中我们将图片、文字、语音等放入Encoder得到的输出向量Embedaing中就包含了这些输入的特征信息,但是一个输入可能存在不同的特征信息,例如一段语音就包含语音的内容、说话者的特征等等,那么有没有可能在Embedaing中将这些特征分别提取出来呢?这就是Feature Disentangle想要实现的事情。
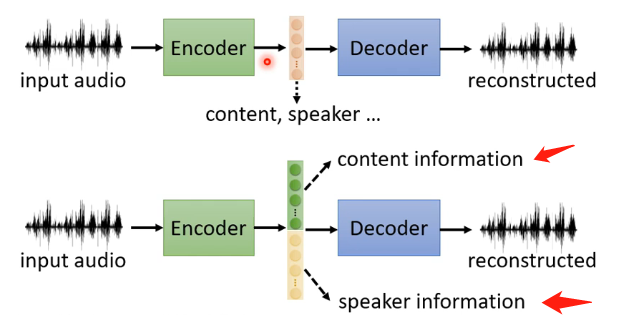
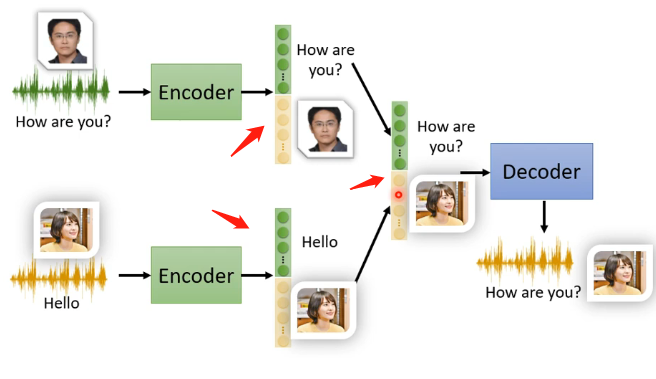
5、Voice Conversion
语者转换这个例子就是学习完模型之后,将A说话的内容用B的声音复述出来作为输出,就好像柯南的领带变声器一般神奇。那么Auto-encoder如何来实现这个任务呢?
实际上这就需要借助Feature Disentangle。首先如果将该任务作为一个监督学习的任务,那我们就需要A和B两个人分别来说同样的句子同样的内容,产生大量的样本从而来进行训练,但是这显然是不可能的!因此如果我们利用Auto-encoder和Feature Disentangle,可以有这样的思路:
- 训练完Auto-encoder后,将A说话的语音和B说话的语音都输出Encoder得到对应的Embedaing输出
- 运用特征提取技术,将A和B对应的Embedaing分别提取出说话的内容和语者的特征两部分
- 再将A说话的特征和B的特征互换,让B的特征和A的内容拼接在一起,这样就实现了用B语者来说出A的内容。
6、Discrete Representation
上述我们说到的Embedaing是一个向量,其中每一个维度都是可以连续变化的数值。那么有没有可能我们强迫这个Embedaing是用离散的数值来表示呢?例如表示为二进制,只有0和1,每个维度表示是否含有某个特征;或者表示为One-hat-vector,来表示对物品的分类(这样就不需要标签)了,因为在学习的过程中就会自动将类似的物品归于同一类,就类似于聚类算法了。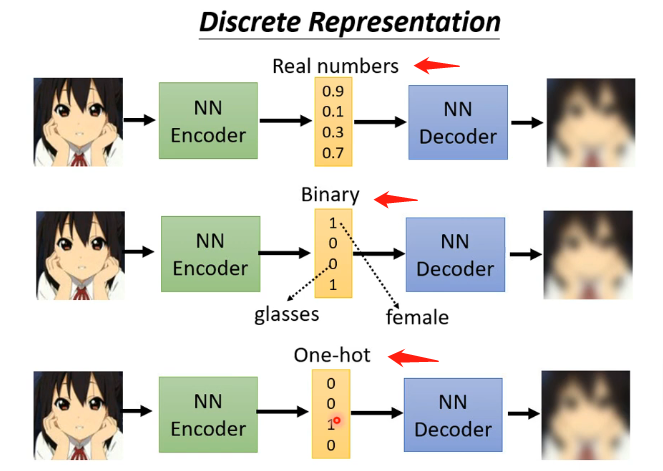
那么这种想法比较有代表性的技术为VQVAE,其具体的流程为:
- 将输入经过Encoder之后得到Embedaing,然后现在有一排向量Codebook(里面向量的个数也是你指定的)
- 将Embedaing逐一与Codebook中的向量进行计算相似度,并取其中相似度最高的来作为Decoder的输入
- 训练的时候我们会要求Decoder的输出要与Encoder的输入越接近越好,从而来不断地改进Codebook中的各个向量
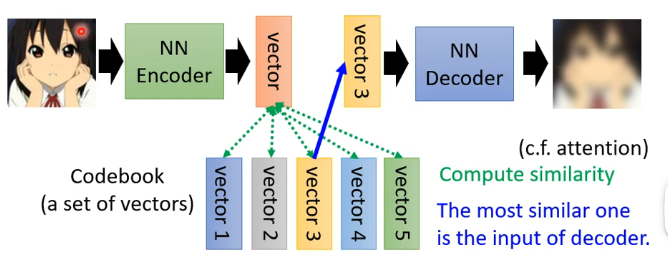
这样最终的结果就是让你Decoder的输入是离散的,只能在Codebook中进行选取,而且例如应用在语音的例子中,有可能最终学习得到的Codebook中的各个向量的不同维度可能会代表不同音标等等。
但这里我有一个问题就是如上图应用在图像上,那么训练完成后如果放入Encoder的是之前训练从未见过的图像,那么输出还能够与输入相接近吗?
7、令Embedaing是一段文字
如果天马行空一点,能否让Embedaing是一段文字呢?例如我们给Encoder一篇文章,然后希望它输出一段文字,而Decoder再由这段文字来还原回原来的文章。那么此时这个Embedaing是否可以认为是文章的摘要呢?
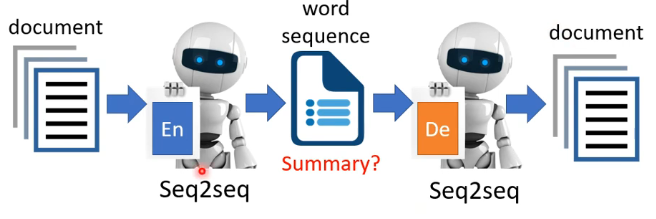
如果真的将这个想法进行实现会发现:Embedaing虽然确实是一段文字,但是它经常是我们人类看不懂的文字,即在我们看来是毫无逻辑的文字无法作为摘要,但这可以认为是En和De之间发明的暗号,它们用这些文字就可以实现输入和输出的文章都极其相似。那么如果希望中间的Embedaing是我们能够看得懂的文字,我们可以加上GAN的思想,即加上一个辨别器,该辨别器是学习了很多人类写文章的句子,它能够分辨一段文字是否是人类能够理解的逻辑,那么这就会使得En不断地调整自己的输出,希望能够欺骗过辨别器,让它认为是人类写出来的句子,因此Embedaing也就越来越接近于摘要的功能了!
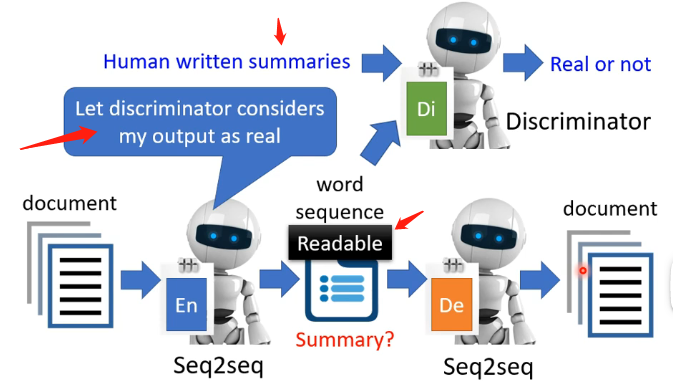
8、其他应用
8.1、生成器
训练完Auto-encoder后,由于Decoder是接受一个向量,生成一个输出(例如图像),那么就可以认为这个Decoder就是一个生成器,因此可以单独拿出来作为一个生成器使用: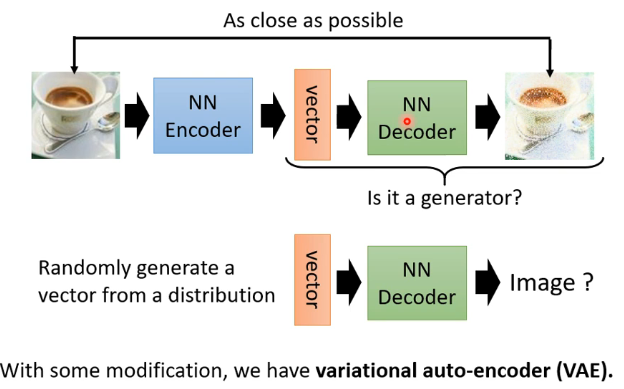
8.2、压缩
将Encoder训练完成后它相当于接受一个输入(例如图片)然后得到向量,那么这个向量通常是低维度的,那么我们可以认为是进行了压缩,而Decoder就是进行了解压缩。但需要注意的是由于De输出的结果无法与原始的输入一模一样,因此这样的压缩是有损的。
8.3、异常检测
我们如果想要做一个异常检测系统,那我们需要很多的资料来进行训练,而在某些应用场景中很可能我们只有非常多的正常的数据而只有非常少的异常数据,甚至于说有些异常的数据混杂在正常的数据中都分辨不出来,那么这时候Auto-encoder就可以派上用场了!如下图,我们先用正常的数据来训练我们的Auto-encoder,例如正常的数据是人脸:
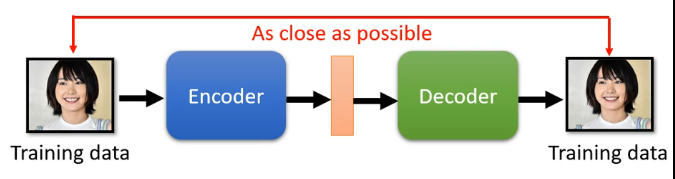
那么训练完成之后,如果你进行检测时输入的也是相似的人脸,那么Auto-encoder就有较大的可能,使得输入与输出之间较为接近,即计算相似度就会较大;但是如果输入不是人脸,例如动漫人物,那么因为Auto-encoder没有看过这样的图片因此很难正确的将其还原,那么再计算输入与输出之间的相似度时就会较小,即:
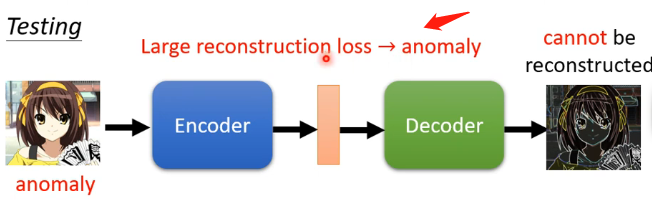
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:【机器学习】李宏毅——AE自编码器(Auto-encoder) - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
