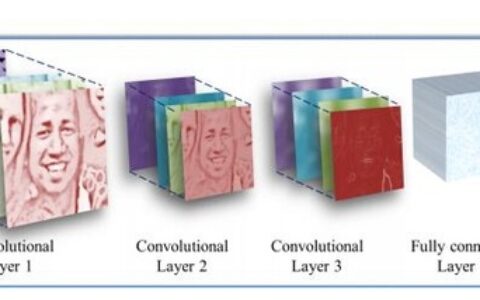
prototxt文件是caffe的配置文件,用于保存CNN的网络结构和配置信息。prototxt文件有三种,分别是deploy.prototxt,train_val.prototxt和solver.prototxt。
solver.prototxt是caffe的配置文件。里面定义了网络训练时候的各种参数,比如学习率、权重衰减、迭代次数等等。
solver.prototxt文件只在网络进行训练的时候需要载入。是网络训练的一个整体的参数配置文件。
下面详细说明每一个参数所代表的意义:
1 #网络模型描述文件 2 #也可以用train_net和test_net来对训练模型和测试模型分别设定 3 #train_net: "xxxxxxxxxx" 4 #test_net: "xxxxxxxxxx" 5 net: "E:/Caffe-windows/caffe-windows/examples/mnist/lenet_train_test.prototxt" 6 #这个参数要跟test_layer结合起来考虑,在test_layer中一个batch是100,而总共的测试图片是10000张 7 #所以这个参数就是10000/100=100 8 test_iter: 100 9 #每迭代500次进行一次测试 10 test_interval: 500 11 #学习率 12 base_lr: 0.01 13 #动力 14 momentum: 0.9 15 #type:SGD #优化算法的选择。这一行可以省略,因为默认值就是SGD,Caffe中一共有6中优化算法可以选择 16 #Stochastic Gradient Descent (type: "SGD"), 在Caffe中SGD其实应该是Momentum 17 #AdaDelta (type: "AdaDelta"), 18 #Adaptive Gradient (type: "AdaGrad"), 19 #Adam (type: "Adam"), 20 #Nesterov’s Accelerated Gradient (type: "Nesterov") 21 #RMSprop (type: "RMSProp") 22 #权重衰减项,其实也就是正则化项。作用是防止过拟合 23 weight_decay: 0.0005 24 #学习率调整策略 25 #如果设置为inv,还需要设置一个power, 返回base_lr * (1 + gamma * iter) ^ (- power),其中iter表示当前的迭代次数 26 lr_policy: "inv" 27 gamma: 0.0001 28 power: 0.75 29 #每训练100次屏幕上显示一次,如果设置为0则不显示 30 display: 100 31 #最大迭代次数 32 max_iter: 2000 33 #快照。可以把训练的model和solver的状态进行保存。每迭代5000次保存一次,如果设置为0则不保存 34 snapshot: 5000 35 snapshot_prefix: "E:/Caffe-windows/caffe-windows/examples/mnist/models" 36 #选择运行模式 37 solver_mode: GPU
2. deploy.prototxt和train_val.prototx
- 在train_val.prototx中网络结构的data层有两种,分别为TRAIN和TEST。顾名思义,TRAIN是网络训练时后的数据结构,TEST是网络做验证时候的数据结构。一般来说TRAIN中的batchSize比TEST中的要大一些。
- 在train_val.prototx中的卷积层(Convolution)中存在学习率和权重衰减的参数,而deploy.prototxt文件中则没有这些参数(有些deploy.prototxt中仍然有这些参数,但是对测试不起任何作用)。
1 data层
1 layer { 2 name: "train-data" 3 type: "Data" 4 top: "data" 5 top: "label" 6 include { 7 phase: TRAIN 8 } 9 transform_param { 10 mirror: true 11 crop_size: 227 12 mean_file: "./mean.binaryproto" 13 } 14 data_param { 15 source: "./train_db" 16 batch_size: 128 17 backend: LMDB 18 } 19 }
2. Convolution层
1 layer { 2 name: "conv1" 3 type: "Convolution" 4 bottom: "data" 5 top: "conv1" 6 param { 7 lr_mult: 1.0 8 decay_mult: 1.0 9 } 10 param { 11 lr_mult: 2.0 12 decay_mult: 0.0 13 } 14 convolution_param { 15 num_output: 96 16 kernel_size: 11 17 stride: 4 18 weight_filler { 19 type: "gaussian" 20 std: 0.01 21 } 22 bias_filler { 23 type: "constant" 24 value: 0.0 25 } 26 } 27 }
lr_mult: 学习率。这里有两个学习率,分别是filter和bias的学习率。
decay_mult::衰减系数。同样有两个,与学习率对应。
num_output::这一层输出的特征图个数。即改成用多少个卷积核去对输入做卷积操作。
kernel_size:卷积核的尺寸。
stride:卷积的步长。
weight_filler {
type: "gaussian"
std: 0.01
}
整个参数是表示使用高斯方法初始化滤波器参数。这里是使用均值为0,方差为0.01的高斯核。
bias_filler {
type: "constant"
value: 0.0
}
整个参数表示使用constant方法初始化偏置。即初始偏置设置为0。
补充
mnist对图片进行预处理转换使用的是 caffe-windows\Build\x64\Debug\convert_mnist_data.exe
分类测试使用的是 E:\caffe\caffe-windows\Build\x64\Debug\classification.exe
计算均值使用的是 caffe-windows\Build\x64\Debug\compute_image_mean.exe ,输入是lmdb,输出均值文件xxxx.binaryproto
caffemodel和solverstate
在caffe训练完网络之后,会生成两个文件一个caffemodel和solberstate,caffemodel是各层的参数,也就是训练之后的网络模型最重要的文件,而 solverstate则是快照,就是可以通过该文件继续进行迭代(类似于断点续传)。
这两个文件的位置请看你训练网络的 solver.prototxt文件,这里面的 snapshot_prefix字段里写了文件生成的位置。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:caffe(1) 网络结构层参数详解 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫