Python爬虫:原来微博上的视频下载链接在这啊
最近看了一下网页版的微博,觉得那上面的视频不错,想获取它上面的下载链接,于是就写了这篇博文。
1. 几个视频播放平台的下载链接的实现
1. 西瓜视频
西瓜视频这个平台上面的视频下载链接一开始就存在于视频播放界面,电脑键盘F12键查看源码,按Ctrl+F搜索script标签,依次点击,可以发现其中一个script标签下有一段json数据,而当前播放的视频的下载链接就在这个json数据中,只不过下载视频进行了加密,根本看不懂,需要找到相应的解密函数即可。(感兴趣的读者可以去看看小编的这篇文章:Python爬虫:从js逆向了解西瓜视频的下载链接的生成)
2.斗鱼视频
斗鱼视频这个平台上的视频下载,使用了ajax技术,在当前播放界面可以找到一个ajax请求,在这个请求里面可以找到当前视频的m3u8文件下载链接(但是这个ajax请求是一个post请求,且请求参数进行了加密,需要模拟加密才能进行访问),之后根绝这个m3u8文件可以下载当前视频的一些ts文件,最后把ts文件合并称mp4文件即可.(感兴趣的读者可以去看看小编的这篇文章:Python爬虫:通过js逆向我发现了斗鱼视频请求参数的加密原理)
3.快手视频
快手视频这个平台上的视频下载和斗鱼类似,但比斗鱼简单很多.(感兴趣的读者可以去看看小编的这篇文章:Python爬虫:给我一个链接,快手视频随便下载)
2. 实现原理
实现原理和斗鱼视频、快手视频的原理一样,找到相应的ajax请求链接即可(这又是一个post请求)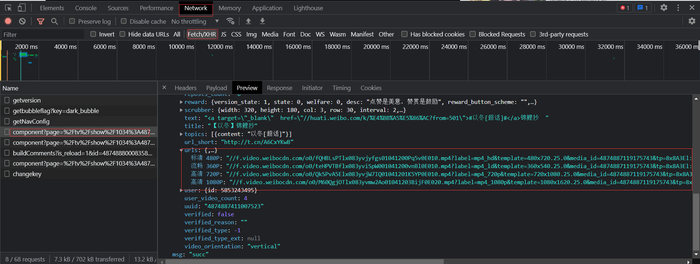

但是如果要使用Python爬虫来得到这个数据,请求头需要添加一些字段,比如cookie、user-agent等字段。

但是不知道小编这个post请求data这个参数是不是写错了(requests模块),还是这个链接存在一定问题,反正试了很多方法,总是获取不到完整数据,最后把post请求改成get请求才最终成功获取。
3. 运行结果
[video(video-fHqZMMbf-1677750262052)(type-bilibili)(url-https://player.bilibili.com/player.html?aid=865253588)(image-https://img-blog.csdnimg.cn/img_convert/ab51fed4277a57c7dca4fa877db89738.jpeg)(title-Python爬虫:抓取微博上的视频下载链接)]参考代码如下:
import requests
import json
import re
# https://weibo.com/tv/show/1034:4857185377910909?mid=4857186621067064
video_url = input('输入:')
id = re.findall('https://weibo.com/tv/show/(\d*:\d*)?.*',video_url)[0]
url = 'https://weibo.com/tv/api/component?page=/tv/show/{0}&data={1}'
data_str = '{%22Component_Play_Playinfo%22:{%22oid%22:%22' + id + '%22}}'
url = url.format(id, data_str)
headers = {
"cookie": "SINAGLOBAL=1642093035151.6916.1590980167697; UOR=news.huse.edu.cn,widget.weibo.com,www.baidu.com; SCF=AoITVZf4HS3L4qWC3iYin9ewmWRQdnQsEsKnkUAKVrhUGsrSuJsFtN6Puc1jeCHZyLFnsESBUt7YCk5DWM4I86o.; SUBP=0033WrSXqPxfM72wWs9jqgMF55529P9D9W5yXxXxcVnl70-8qPgRKnCg5JpVF02ReK-E1hMReKep; SUB=_2AkMU3QDBdcPxrAVSmvsVxGnqbYtH-jynCGk3An7uJhMyAxh87n0PqSVutBF-XEV4WnRTgvv_qqEol-0DEUdZBTB_; UPSTREAM-V-WEIBO-COM=b09171a17b2b5a470c42e2f713edace0; _s_tentry=-; Apache=2882565213456.4116.1677573461765; ULV=1677573461958:47:1:1:2882565213456.4116.1677573461765:1669435390809; XSRF-TOKEN=KLbhVzQdbXXP_F7laqGMs0xt; WBPSESS=Dt2hbAUaXfkVprjyrAZT_FgOH_8DbGpQMRQSA1lwg1qH-m_kdZLq1PmsYPFYeK6IewUd4GmxAOEZC3rK48r1iqi82kid-HnqOCAwipsM3hrg5LtskejSkGEhijD2kFHQ8CBnf3q1vzJpVpquSnhK5Q==",
"origin": "https://weibo.com",
"page-referer": "/tv/show/1034:4857185377910909",
"referer": "https://weibo.com/tv/show/1034:4857185377910909?mid=4857186621067064",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3877.400 QQBrowser/10.8.4507.400",
}
rsp = requests.get(url=url, headers=headers)
dict2 = json.loads(rsp.text)
urls_dict = dict2['data']['Component_Play_Playinfo']['urls']
for key in urls_dict:
print(key,f'https:{urls_dict.get(key)}')
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:Python爬虫:原来微博上的视频下载链接在这啊 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 