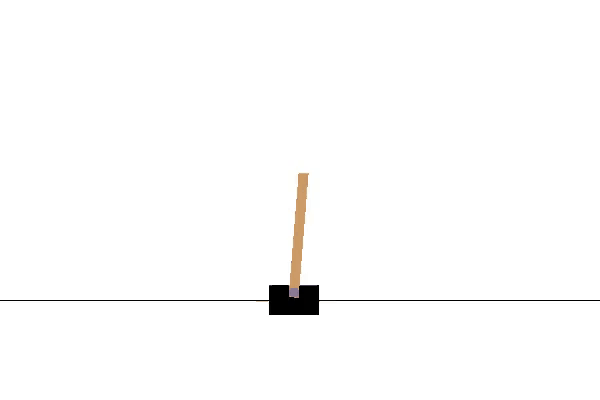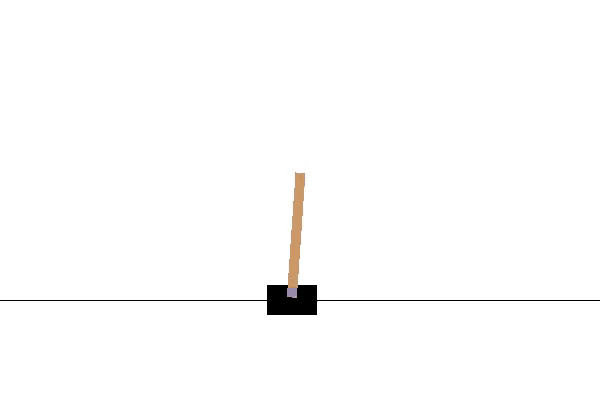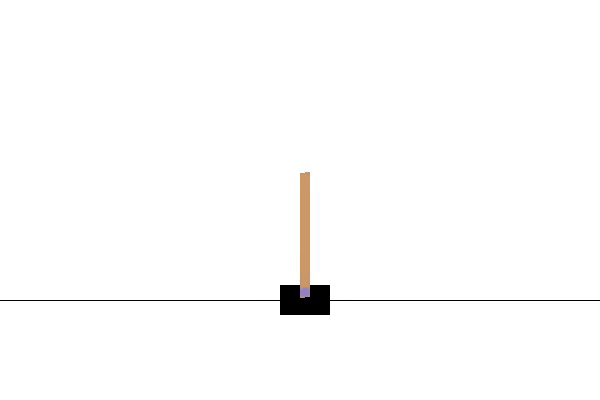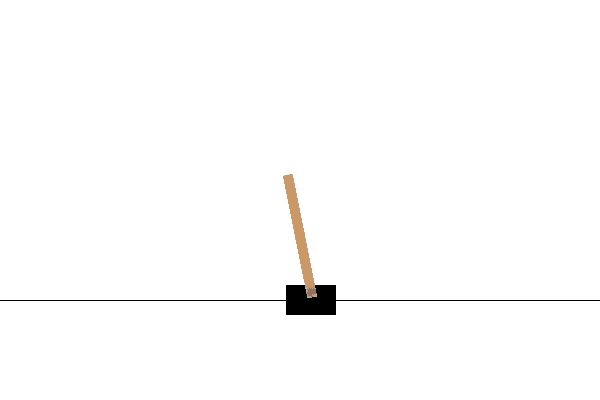

摘要:OpenAI Gym是一款用于研发和比较强化学习算法的工具包,本文主要介绍Gym仿真环境的功能和工具包的使用方法,并详细介绍其中的经典控制问题中的倒立摆(CartPole-v0/1)问题。最后针对倒立摆问题如何建立控制模型并采用爬山算法优化进行了介绍,并给出了相应的完整python代码示例和解释。要点如下:
1. 前言
自从AlphaGo的横空出世之后,整个工业界都为之振奋,也确定了强化学习在人工智能领域的重要地位,越来越多的人加入到强化学习的研究和学习中。强化学习(Reinforcement learning, RL)是机器学习的一个子领域,在智能控制机器人及分析预测等领域有许多应用。强化学习通过与环境进行交互获得的奖赏指导行为,目标是使智能体获得最大的奖赏,最终开发出智能体(Agent)做出决策和控制。
OpenAI Gym是一个研究和比较强化学习相关算法的开源工具包,包含了许多经典的仿真环境和各种数据。目前强化学习的研究面临着使用的环境缺乏标准化的问题,这个问题使得很难复制已发表的研究结果以及比较不同论文的结果,个人认为Gym正好为这一问题提供了很好的解决方案。因此非常有必要学习一下Gym这一快捷工具包,经过一段时间对深度强化学习的研究和学习,我这里将前期所学做一个整理和总结。
2. OpenAI Gym仿真环境介绍
Gym是一个研究和开发强化学习相关算法的仿真平台,无需智能体先验知识,并兼容常见的数值运算库如 TensorFlow、Theano等。OpenAI Gym由以下两部分组成:
- Gym开源库:测试问题的集合。当你测试强化学习的时候,测试问题就是环境,比如机器人玩游戏,环境的集合就是游戏的画面。这些环境有一个公共的接口,允许用户设计通用的算法。
- OpenAI Gym服务:提供一个站点和API(比如经典控制问题:CartPole-v0),允许用户对他们的测试结果进行比较。
简单来说OpenAI Gym提供了许多问题和环境(或游戏)的接口,而用户无需过多了解游戏的内部实现,通过简单地调用就可以用来测试和仿真。接下来以经典控制问题CartPole-v0为例,简单了解一下Gym的特点,以下代码来自OpenAI Gym官方文档
import gym
env = gym.make('CartPole-v0')
env.reset()
for _ in range(1000):
env.render()
env.step(env.action_space.sample()) # take a random action
env.close()
运行效果如下:

以上代码中可以看出,gym的核心接口是Env。作为统一的环境接口,Env包含下面几个核心方法:
- reset(self):重置环境的状态,返回观察。
- step(self, action):推进一个时间步长,返回observation, reward, done, info。
- render(self, mode='human', close=False):重绘环境的一帧。默认模式一般比较友好,如弹出一个窗口。
- close(self):关闭环境,并清除内存。
以上代码首先导入gym库,第2行创建CartPole-v0环境,并在第3行重置环境状态。在for循环中进行1000个时间步长(timestep)的控制,第5行刷新每个时间步长环境画面,第6行对当前环境状态采取一个随机动作(0或1),最后第7行循环结束后关闭仿真环境。
2.1 观测(Observations)
在上面代码中使用了env.step()函数来对每一步进行仿真,在Gym中,env.step()会返回 4 个参数:
- 观测 Observation (Object):当前step执行后,环境的观测(类型为对象)。例如,从相机获取的像素点,机器人各个关节的角度或棋盘游戏当前的状态等;
- 奖励 Reward (Float): 执行上一步动作(action)后,智能体( agent)获得的奖励(浮点类型),不同的环境中奖励值变化范围也不相同,但是强化学习的目标就是使得总奖励值最大;
- 完成 Done (Boolen): 表示是否需要将环境重置 env.reset。大多数情况下,当 Done 为True 时,就表明当前回合(episode)或者试验(tial)结束。例如当机器人摔倒或者掉出台面,就应当终止当前回合进行重置(reset);
- 信息 Info (Dict): 针对调试过程的诊断信息。在标准的智体仿真评估当中不会使用到这个info,具体用到的时候再说。
总结来说,这就是一个强化学习的基本流程,即"agent-environment loop",在每个时间点上,智能体(可以认为是你写的算法)选择一个动作(action),环境返回上一次action的观测(Observation)和奖励(Reward),用图表示为
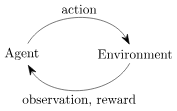
在 Gym 仿真中,每一次回合开始,需要先执行 reset() 函数,返回初始观测信息,然后根据标志位 done 的状态,来决定是否进行下一次回合。所以更恰当的方法是遵守done的标志,同样我们可以参考OpenAI Gym官方文档中的代码如下
import gym
env = gym.make('CartPole-v0')
for i_episode in range(20):
observation = env.reset()
for t in range(100):
env.render()
print(observation)
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
if done:
print("Episode finished after {} timesteps".format(t+1))
break
env.close()
当done 为真时,控制失败,此阶段episode 结束。可以计算每 episode 的回报就是其坚持的t+1时间,坚持的越久回报越大,在上面算法中,agent 的行为选择是随机的,平均回报为20左右。
2.2 空间(Spaces)
在前面的两个小例子中,每次执行的动作(action)都是从环境动作空间中随机进行选取的,但是这些动作 (action) 是什么?在 Gym 的仿真环境中,有运动空间 action_space 和观测空间observation_space 两个指标,程序中被定义为 Space类型,用于描述有效的运动和观测的格式和范围。下面是一个代码示例:
import gym
env = gym.make('CartPole-v0')
print(env.action_space)
#> Discrete(2)
print(env.observation_space)
#> Box(4,)
从程序运行结果可以看出:
- action_space 是一个离散Discrete类型,从discrete.py源码可知,范围是一个{0,1,...,n-1} 长度为 n 的非负整数集合,在CartPole-v0例子中,动作空间表示为{0,1}。
- observation_space 是一个Box类型,从box.py源码可知,表示一个 n 维的盒子,所以在上一节打印出来的observation是一个长度为 4 的数组。数组中的每个元素都具有上下界。
print(env.observation_space.high)
print(env.observation_space.low)
[4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38]
[-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38]
利用运动空间和观测空间的定义和范围,可以将代码写得更加通用。在许多仿真环境中,Box和Discrete是最常见的空间描述,在智体每次执行动作时,都属于这些空间范围内,代码示例为:
from gym import spaces
space = spaces.Discrete(8)
# Set with 8 elements {0, 1, 2, ..., 7}
x = space.sample()
print(space.contains(x))
print(space.n == 8)
True
True
在CartPole-v0栗子中,运动只能选择左和右,分别用{0,1}表示。
2.3 OpenAI Gym中可用的环境
Gym中从简单到复杂,包含了许多经典的仿真环境和各种数据,其中包括:
-
经典控制和文字游戏:经典的强化学习示例,方便入门;
-
算法:从例子中学习强化学习的相关算法,在Gym的仿真算法中,由易到难方便新手入坑;
-
雅达利游戏:利用强化学习来玩雅达利的游戏。Gym中集成了对强化学习有着重要影响的Arcade Learning Environment,并且方便用户安装;
-
2D和3D的机器人:这个是我一直很感兴趣的一部分,在Gym中控制机器人进行仿真。需要利用第三方的物理引擎如 MuJoCo。
2.4 注册表
Gym是一个包含各种各样强化学习仿真环境的大集合,并且封装成通用的接口暴露给用户,查看所有环境的代码如下
from gym import envs
print(envs.registry.all())
#> [EnvSpec(DoubleDunk-v0), EnvSpec(InvertedDoublePendulum-v0), EnvSpec(BeamRider-v0), EnvSpec(Phoenix-ram-v0), EnvSpec(Asterix-v0), EnvSpec(TimePilot-v0), EnvSpec(Alien-v0), EnvSpec(Robotank-ram-v0), EnvSpec(CartPole-v0), EnvSpec(Berzerk-v0), EnvSpec(Berzerk-ram-v0), EnvSpec(Gopher-ram-v0), ...
Gym支持将用户制作的环境写入到注册表中,需要执行 gym.make()和在启动时注册register,具体可参考这篇博客:gym介绍。同时我们可以通过写入新的注册表实现对环境中的某些参数设置进行修改,例如
form gym.envs.registration import register
register(
id='CartPole-v2',
entry_point='gym.envs.classic_control:CartPoleEnv',
max_episode_steps=200*4,
reward_threshold=195.0*4,
)
env = gym.make('CartPole-v2')
2.5 OpenAI Gym评估平台
用户可以记录和上传算法在环境中的表现或者上传自己模型的Gist,生成评估报告,还能录制模型玩游戏的小视频。在每个环境下都有一个排行榜,用来比较大家的模型表现。详细介绍可以参考这篇博文:OpenAI Gym评估平台、OpenAI教程,当然更加准确的表述还是应该参考OpenAI Gym官方文档。
3. CartPole-v0/1原理与功能
在CartPole-v0的环境中,实际参考了论文:AG Barto, RS Sutton and CW Anderson, "Neuronlike Adaptive Elements That Can Solve Difficult Learning Control Problem", IEEE Transactions on Systems, Man, and Cybernetics, 1983.中的倒立摆控制问题。
Cart Pole即车杆游戏,游戏模型如下图所示。游戏里面有一个小车,上有竖着一根杆子,每次重置后的初始状态会有所不同。小车需要左右移动来保持杆子竖直,为了保证游戏继续进行需要满足以下两个条件:
- 杆子倾斜的角度(theta)不能大于15°
- 小车移动的位置(x)需保持在一定范围(中间到两边各2.4个单位长度)
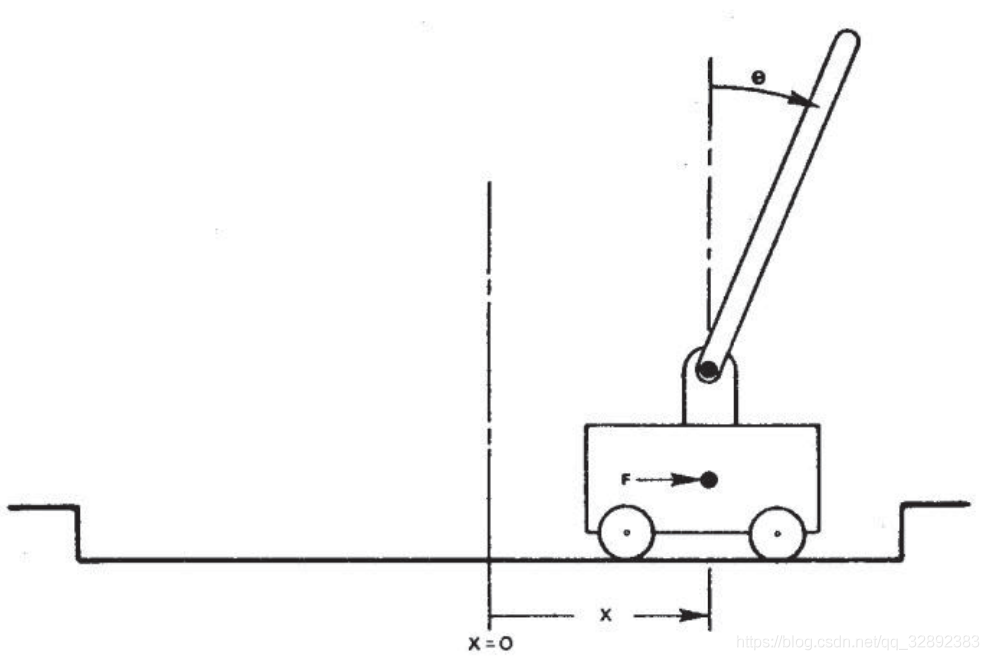
动作(action):
- 左移(0)
- 右移(1)
状态变量(state variables):
- (x):小车在轨道上的位置(position of the cart on the track)
- (theta):杆子与竖直方向的夹角(angle of the pole with the vertical)
- (dot{x}):小车速度(cart velocity)
- (dot{theta }):角度变化率(rate of change of the angle)
import gym
env = gym.make('CartPole-v0')
observation = env.reset()
print(observation)
#> [-0.00478028 -0.02917182 0.00313288 0.03160127]
以上代码显示了初始状态下的取值,每次调用env.reset( )将重新产生一个初始状态。打印出的observation的四个元素分别表示了小车位置、小车速度、杆子夹角及角变化率。
游戏奖励(reward):
在gym的Cart Pole环境(env)里面,左移或者右移小车的action之后,env会返回一个+1的reward。其中CartPole-v0中到达200个reward之后,游戏也会结束,而CartPole-v1中则为500。最大奖励(reward)阈值可通过前面介绍的注册表进行修改。
4. 爬山算法解决倒立摆问题
为了能够有效控制倒立摆首先应建立一个控制模型。明显的,这个控制模型的输入应该是当前倒立摆的状态(observation)而输出为对当前状态做出的决策动作(action)。从前面的知识我们了解到决定倒立摆状态的observation是一个四维向量,包含小车位置((x))、杆子夹角((theta))、小车速度((dot{x}))及角变化率((dot{theta })),如果对这个向量求它的加权和,那么就可以根据加权和值的符号来决定采取的动作(action),用sigmoid函数将这个问题转化为二分类问题,从而可以建立一个简单的控制模型。其模型如下图所示:
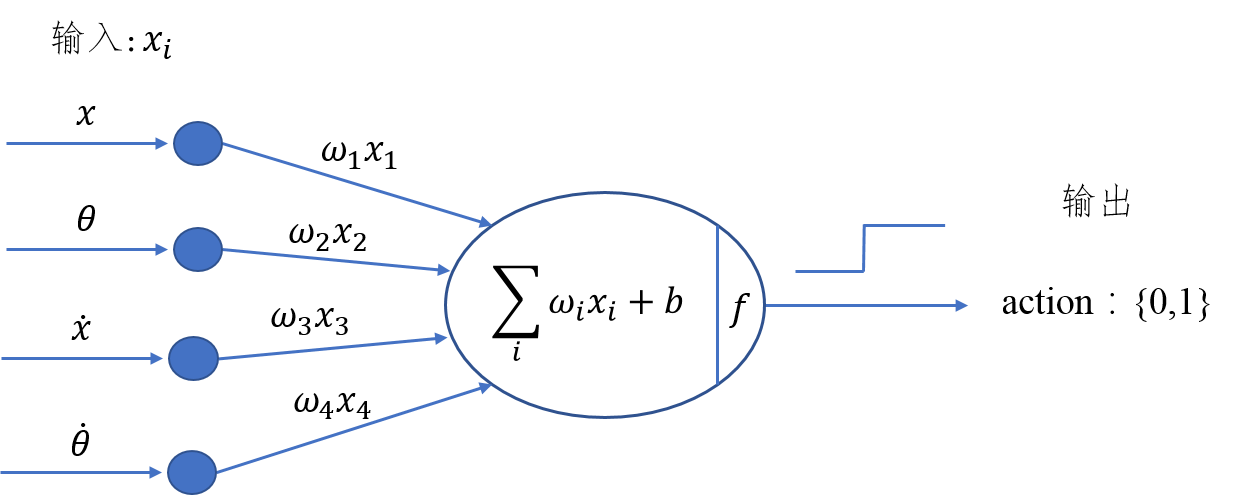
上图的实际功能与神经网络有几分相似,但比神经网络要简单得多。通过加入四个权值,我们可以通过改变权重值来改变决策(policy),即有加权和(H_{sum}=omega _{1}x+omega _{2}theta +omega _{3}dot{x}+omega _{4}dot{theta}+b),若(H_{sum})的符号为正判定输出为1,否则为0。为了得到一组较好的权值从而有效控制倒立摆,我们可以采用爬山算法(hill climbing algorithm)进行学习优化。爬山算法是一种启发式方法,是对深度优先搜索的一种改进,它利用反馈信息帮助生成解的决策。
爬山算法的基本思路是每次迭代时给当前取得的最优权重加上一组随机值,如果加上这组值使得有效控制倒立摆的持续时间变长了那么就更新它为最优权重,如果没有得到改善就保持原来的值不变,直到迭代结束。在迭代过程中,模型的参数不断得到优化,最终得到一组最优的权值作为控制模型的解。其代码如下:
# coding: utf8
import numpy as np
import gym
import time
def get_action(weights, observation):# 根据权值对当前状态做出决策
wxb = np.dot(weights[:4], observation) + weights[4] # 计算加权和
if wxb >= 0:# 加权和大于0时选取动作1,否则选取0
return 1
else:
return 0
def get_sum_reward_by_weights(env, weights):
# 测试不同权值的控制模型有效控制的持续时间(或奖励)
observation = env.reset() # 重置初始状态
sum_reward = 0 # 记录总的奖励
for t in range(1000):
# time.sleep(0.01)
# env.render()
action = get_action(weights, observation) # 获取当前权值下的决策动作
observation, reward, done, info = env.step(action)# 执行动作并获取这一动作下的下一时间步长状态
sum_reward += reward
# print(sum_reward, action, observation, reward, done, info)
if done:# 如若游戏结束,返回
break
return sum_reward
def get_weights_by_random_guess():
# 选取随机猜测的5个随机权值
return np.random.rand(5)
def get_weights_by_hill_climbing(best_weights):
# 通过爬山算法选取权值(在当前最好权值上加入随机值)
return best_weights + np.random.normal(0, 0.1, 5)
def get_best_result(algo="random_guess"):
env = gym.make("CartPole-v0")
np.random.seed(10)
best_reward = 0 # 初始最佳奖励
best_weights = np.random.rand(5) # 初始权值为随机取值
for iter in range(10000):# 迭代10000次
cur_weights = None
if algo == "hill_climbing": # 选取动作决策的算法
# print(best_weights)
cur_weights = get_weights_by_hill_climbing(best_weights)
else: # 若为随机猜测算法,则选取随机权值
cur_weights = get_weights_by_random_guess()
# 获取当前权值的模型控制的奖励和
cur_sum_reward = get_sum_reward_by_weights(env, cur_weights)
# print(cur_sum_reward, cur_weights)
# 更新当前最优权值
if cur_sum_reward > best_reward:
best_reward = cur_sum_reward
best_weights = cur_weights
# 达到最佳奖励阈值后结束
if best_reward >= 200:
break
print(iter, best_reward, best_weights)
return best_reward, best_weights
# 程序从这里开始执行
print(get_best_result("hill_climbing")) # 调用爬山算法寻优并输出结果
# env = gym.make("CartPole-v0")
# get_sum_reward_by_weights(env, [0.22479665, 0.19806286, 0.76053071, 0.16911084, 0.08833981])
爬山算法本质是一种局部择优的方法,效率高但因为不是全局搜索,所以结果可能不是最优。在这里采用的模型较为简单,如若想要获得更好的学习效果可以考虑更加复杂的模型,如深度神经网络。
5. 结束语
可以看到网上有很多通过深度Q学习算法解决倒立摆问题的文章,DQN确实不失为一种较好的解决方法,不过作为强化学习的基础部分这里就总结这么多了,关于DQN后面也会具体总结介绍。
由于博主能力有限,博文中提及的方法与代码即使经过测试,也难免会有疏漏之处。希望您能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。同时如果有更好的实现方法也请您不吝赐教。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:OpenAI Gym 经典控制环境介绍——CartPole(倒立摆) - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 