线程理论
什么是线程
# 将操作系统比喻成一个工厂,那么进程就相当于工厂里面的车间,线程就相当于车间里面的流水线 # 进程:资源单位(起一个进程仅仅只是在内存空间中开辟一块独立的空间) # 线程:执行单位(真正被cpu执行的其实是进程里面的线程,线程指的就是代码的执行过程,执行代码中所需要的资源都找所在的进程索要) # 每一个进程肯定自带一个线程 # 进程和线程都是虚拟单位,只是为了我们更加方便的描述问题
为什么要有线程
""" 开设进程 1、申请内存空间 耗资源 2、“拷贝代码” 耗资源 开设线程 一个进程内可以开设多个线程,在一个进程内开设多个线程无需再申请内存空间 总结: 开设线程的开销要远远的小于进程的开销 同一个进程下的多个线程数据是共享的!!! """ 我们要开发一款文本编辑器 获取用户输入的功能 实时展示到屏幕的功能 自动保存到硬盘的功能 针对上面这三个功能,开设进程还是线程合适??? 开三个线程处理上面的三个功能更加的合理
在python程序中进行线程操作
开启线程的两种方式
# 第一种:使用threading模块中Thread类的构造器创建线程
from threading import Thread
import time
def dask(name):
print('%s is running' % name)
time.sleep(1)
print('%s is over' % name)
# 创建线程不需要在main下面执行,直接书写就可以,但是我们还是习惯性的将启动命令写在main下面
t = Thread(target=dask, args=('jiang',))
t.start() # 创建线程的开销非常小,几乎代码一执行线程就已经创建了
print('主线程')
# 第二种:通过类的继承来创建线程 from threading import Thread import time class MyThread(Thread): # 重写了别人的方法,又不知道别人方法里有啥,就调用父类的方法 def __init__(self, name): '''针对双下划线开头双下划线结尾(__init__)的方法,统一读成 双下init''' super().__init__() self.name = name def run(self): print('%s is running' % self.name) time.sleep(1) print('%s is over' % self.name) if __name__ == '__main__': t = MyThread('jiang') t.start() print('主线程')
TCP服务端实现并发的效果
import socket from threading import Thread from multiprocessing import Process """ 服务端 1.要有固定的IP和PORT 2.24小时不间断提供服务 3.能够支持并发 """ server =socket.socket() # 括号内不加参数默认就是TCP协议 server.bind(('127.0.0.1',8080)) server.listen(5) # 将服务的代码单独封装成一个函数 def talk(conn): # 通信循环 while True: try: data = conn.recv(1024) # 针对mac linux 客户端断开链接后 if len(data) == 0: break print(data.decode('utf-8')) conn.send(data.upper()) except ConnectionResetError as e: print(e) break conn.close() # 链接循环 while True: conn, addr = server.accept() # 接客 # 叫其他人来服务客户 # t = Thread(target=talk,args=(conn,)) t = Process(target=talk,args=(conn,)) t.start()
# 客户端
import socket
client = socket.socket()
client.connect(('127.0.0.1',8080))
while True:
client.send(b'hello world')
data = client.recv(1024)
print(data.decode('utf-8'))
线程对象的join方法
from threading import Thread import time def task(name): print('%s is running'%name) time.sleep(3) print('%s is over'%name) if __name__ == '__main__': t = Thread(target=task,args=('egon',)) t.start() t.join() # 主线程等待子线程运行结束再执行 print('主')
同一个进程下多个线程数据共享
from threading import Thread n = 111 def task(): global n n = 666 print('子线程:',n) if __name__ == '__main__': t = Thread(target=task) t.start() print('主线程:',n)
# 子线程: 666
# 主线程: 666
线程对象属性及其他方法
''' Thread实例对象的方法 isAlive(): 返回线程是否活动的。 getName(): 返回线程名。 setName(): 设置线程名。 threading模块提供的一些方法: threading.currentThread(): 返回当前的线程变量。 threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。 threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。 ''' from threading import Thread, active_count, current_thread import os,time def task(n): # print('hello world',os.getpid()) print('hello world',current_thread().name) time.sleep(n) if __name__ == '__main__': t = Thread(target=task,args=(1,)) t1 = Thread(target=task,args=(2,)) t.start() t1.start() t.join() print('主',active_count()) # 统计当前正在活跃的线程数 # print('主',os.getpid()) # print('主',current_thread().name) # 获取线程名字
守护线程
''' 主线程运行结束之后不会立即结束,会等待其它非守护进程结束后才结束 因为主线程的结束意味着所有进程的结束 ''' from threading import Thread import time def task(name): print('%s is running' % name) time.sleep(1) print('%s is over' % name) if __name__ == '__main__': t = Thread(target=task,args=('jiang',)) t.daemon = True t.start() print('主.....')
线程互斥锁
from threading import Thread,Lock import time money = 100 mutex = Lock() def task(): global money mutex.acquire() tmp = money time.sleep(0.1) money = tmp-1 mutex.release() if __name__ == '__main__': t_list = [] for i in range(100): t = Thread(target=task) t.start() t_list.append(t) for t in t_list: t.join() print(money)
GIL全局解释器锁
GIL全局解释器锁的介绍
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple
(在CPython中,全局解释器锁(GIL)是一个互斥锁,可以防止多个互斥)
native threads from executing Python bytecodes at once. This lock is necessary mainly
(本机线程从执行Python字节码一次。这把锁主要是必需的)
because CPython’s memory management is not thread-safe. (However, since the GIL)
(因为CPython的内存管理不是线程安全的。(然而,自从GIL之后))
exists, other features have grown to depend on the guarantees that it enforces.
(存在,其他功能已经发展到依赖于它强制执行的保证。)
python解释器的版本
CPython
JPython
PyPython
普遍使用的都是CPython
在CPython解释器中GIL是一把互斥锁,用来阻止同一个进程下的多个线程的同时执行
同一个进程下的多个线程无法利用多核优势!!!
因为CPython中的内存管理不是线程安全的
1、引用计数
2、标记清除
3、分代回收
重点:
1、GIL不是python的特点而是CPython解释器的特点
2、GIL是保证解释器级别的数据的安全
3、GIL会导致同一个进程下的多个线程的无法同时执行即无法利用多核优势(******)
4、针对不同的数据还是需要加不同的锁处理
5、解释型语言的通病:同一个进程下多个线程无法利用多核优势
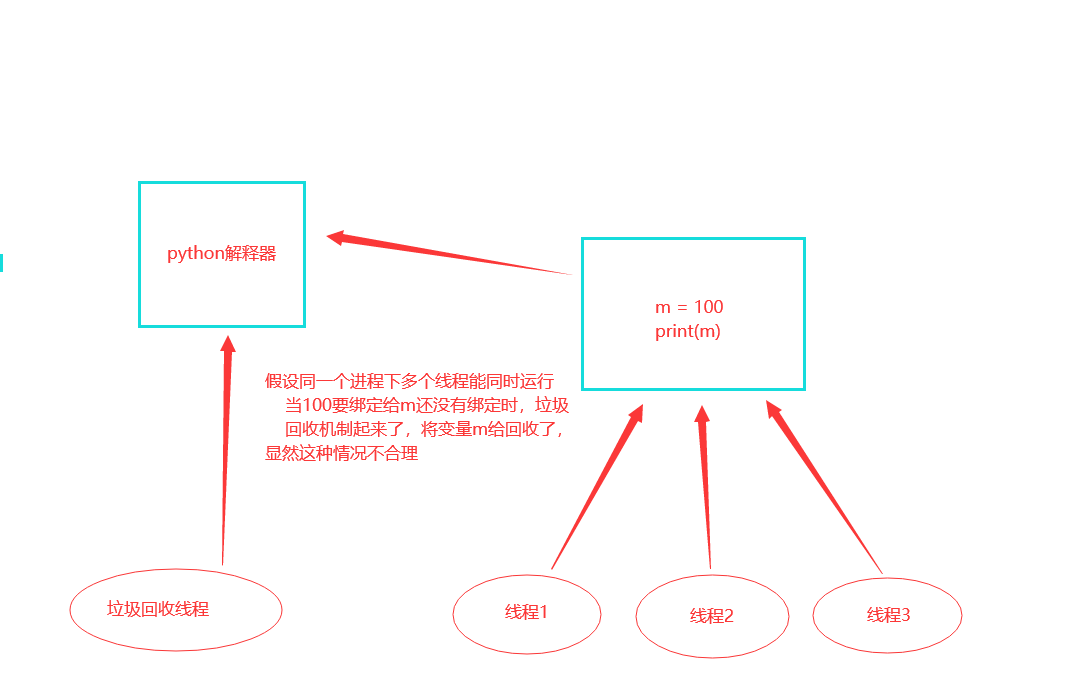

GIL与普通互斥锁的区别
from threading import Thread, Lock import time mutex = Lock() money = 100 def task(): global money # with mutex: # 将需要上锁的代码缩进到 with+锁名 里面就相当于加锁处理 # tmp = money # time.sleep(0.1) # money = tmp - 1 mutex.acquire() tmp = money time.sleep(0.1) # 只要你进入IO了,GIL会自动释放 money = tmp - 1 mutex.release() if __name__ == '__main__': t_list = [] for i in range(100): t = Thread(target=task) t.start() t_list.append(t) for t in t_list: t.join() print(money) """ 100个线程起来之后,先去抢GIL 首先抢到GIL的会继续抢自己的互斥锁 当遇见IO(阻塞态),GIL会自动释放,但此时手上还有一个自己的hucs 其他线程抢得到GIL但是抢不到互斥锁 最终GIL还是回到原来先抢到GIL的线程手里 """
多进程与多线程的比较
""" 多线程是否有用要看具体情况 单核:四个任务(IO密集型计算密集型) 多核:四个任务(IO密集型计算密集型) """ # 计算密集型 每个任务都需要10s 单核(不用考虑了) 多进程:额外的消耗资源 多线程:介绍开销 多核 多进程:总耗时 10+ 多线程:总耗时 40+ # IO密集型 多核 多进程:相对浪费资源 多线程:更加节省资源
# 计算密集型 # from multiprocessing import Process # from threading import Thread # import os,time # # # def work(): # res = 0 # for i in range(10000000): # res *= i # # if __name__ == '__main__': # l = [] # print(os.cpu_count()) # 获取当前计算机CPU个数 # start_time = time.time() # for i in range(12): # p = Process(target=work) # 1.4679949283599854 # t = Thread(target=work) # 5.698534250259399 # t.start() # # p.start() # # l.append(p) # l.append(t) # for p in l: # p.join() # print(time.time()-start_time) # IO密集型 from multiprocessing import Process from threading import Thread import os,time def work(): time.sleep(2) if __name__ == '__main__': l = [] print(os.cpu_count()) # 获取当前计算机CPU个数 start_time = time.time() for i in range(4000): # p = Process(target=work) # 21.149890184402466 t = Thread(target=work) # 3.007986068725586 t.start() # p.start() # l.append(p) l.append(t) for p in l: p.join() print(time.time()-start_time)
死锁与递归锁(了解)
# 死锁
# 当我们知道锁的使用抢锁必须要释放锁,其实你在操作所得时候也及其容易产生死锁现象(整个程序卡死 阻塞)
from threading import Thread,Lock import time mutexA = Lock() mutexB = Lock() # 多次实例化相同的类得到的是不同的对象,要想实例化多次相同的类得到相同的对象 “单例模式” class MyThread(Thread): def run(self): self.func1() self.func2() def func1(self): mutexA.acquire() print("%s 抢到A锁" % self.name) # 获取到线程的名字 mutexB.acquire() print("%s 抢到B锁" % self.name) mutexB.release() mutexA.release() def func2(self): mutexB.acquire() print("%s 抢到B锁" % self.name) time.sleep(2) mutexA.acquire() print("%s 抢到A锁" % self.name) mutexA.release() mutexB.release() if __name__ == '__main__': for x in range(10): t = MyThread() t.start()
# 递归锁
"""
递归锁的特点
可以被连续的acquire和release,但是只能被第一个抢到这把锁执行上述操作
它的内部有一个计数器 每acquire一次计数加一 每realse一次计数减一
只要计数不为0 那么其他人都无法抢到该锁
"""
# 将上述的 mutexA = Lock() mutexB = Lock() 换成 mutexA = mutexB = RLock()
信号量(了解)
信号量在不同阶段对应不同的技术点,在并发编程中信号量指的是锁
""" 如果我们将互斥锁比喻成一个厕所的话 那么信号量就相当于多个厕所 """ from threading import Thread, Semaphore import time import random sm = Semaphore(5) # 括号内写数字,写几就表示开设几个坑位 def task(name): sm.acquire() print('%s 正在蹲坑' % name) time.sleep(random.randint(1,5)) sm.release() if __name__ == '__main__': for i in range(20): t = Thread(target=task,args=('伞兵%s号' % i,)) t.start()
Event事件(了解)
一些进程/线程需要等待另外一些进程/线程运行完毕之后才能运行
from threading import Thread, Event import time event = Event() # 造了一个红绿灯 def light(): print('红灯亮着的') time.sleep(3) print('绿灯亮了') # 告诉等待红灯的人可以走了 event.set() def car(name): print('%s 车正在灯红灯'%name) event.wait() # 等待别人给你发信号 print('%s 车加油门飙车走了'%name) if __name__ == '__main__': t = Thread(target=light) t.start() for i in range(20): t = Thread(target=car, args=('%s'%i, )) t.start()
线程q(了解)
""" 同一个进程下多个线程数据是共享的 为什么先同一个进程下还会去使用队列呢 因为队列是 管道 + 锁 所以用队列还是为了保证数据的安全 """ import queue # 我们现在使用的队列都是只能在本地测试使用 # 1 队列q 先进先出 # q = queue.Queue(3) # q.put(1) # q.get() # q.get_nowait() # q.get(timeout=3) # q.full() # q.empty() # 后进先出q # q = queue.LifoQueue(3) # last in first out # q.put(1) # q.put(2) # q.put(3) # print(q.get()) # 3 # 优先级q 你可以给放入队列中的数据设置进出的优先级 q = queue.PriorityQueue(4) q.put((10, '111')) q.put((100, '222')) q.put((0, '333')) q.put((-5, '444')) print(q.get()) # (-5, '444') # put括号内放一个元祖 第一个放数字表示优先级 # 需要注意的是 数字越小优先级越高!!!
进程池与线程池
""" 无论是开设进程还是开设线程都要消耗资源 只不过开设线程的消耗比开设线程小 我们不可能无限的开设进程和线程(计算机硬件资源有限) 我们的宗旨应该是保证计算机硬件能够正常工作的情况下实现最大限度的利用 """ # 池的概念 用来保证计算机硬件安全的情况下最大限度的利用计算机 降低了程序的运行效率,但保证了计算机硬件的安全,从而程序正常的运行
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor import time import os # pool = ThreadPoolExecutor(5) # 池子里面固定只有五个线程 # 括号内可以传数字 不传的话默认会开设当前计算机cpu个数五倍的线程 pool = ProcessPoolExecutor(5) # 括号内可以传数字 不传的话默认会开设当前计算机cpu个数进程 """ 池子造出来之后 里面会固定存在五个线程 这个五个线程不会出现重复创建和销毁的过程 池子造出来之后 里面会固定的几个进程 这个几个进程不会出现重复创建和销毁的过程 池子的使用非常的简单 你只需要将需要做的任务往池子中提交即可 自动会有人来服务你 """ def task(n): print(n,os.getpid()) time.sleep(2) return n**n def call_back(n): print('call_back>>>:',n.result()) """ 任务的提交方式 同步:提交任务之后原地等待任务的返回结果 期间不做任何事 异步:提交任务之后不等待任务的返回结果 执行继续往下执行 返回结果如何获取??? 异步提交任务的返回结果 应该通过回调机制来获取 回调机制 就相当于给每个异步任务绑定了一个定时炸弹 一旦该任务有结果立刻触发爆炸 """ if __name__ == '__main__': # pool.submit(task, 1) # 朝池子中提交任务 异步提交 # print('主') t_list = [] for i in range(20): # 朝池子中提交20个任务 # res = pool.submit(task, i) # <Future at 0x100f97b38 state=running> res = pool.submit(task, i).add_done_callback(call_back) # print(res.result()) # result方法 同步提交 # t_list.append(res) # 等待线程池中所有的任务执行完毕之后再继续往下执行 # pool.shutdown() # 关闭线程池 等待线程池中所有的任务运行完毕 # for t in t_list: # print('>>>:',t.result()) # 肯定是有序的 """ 程序有并发变成了串行 任务的为什么打印的是None res.result() 拿到的就是异步提交的任务的返回结果 """
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:第二篇:线程 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 