作者:蒋天园
来源:公众号@3D视觉工坊
链接:3D目标检测深度学习方法中voxel-represetnation内容综述(三)
前言
前两篇文章:3D目标检测深度学习方法中voxel-represetnation内容综述(一)、3D目标检测深度学习方法中voxel-represetnation内容综述(二)分别介绍了当前voxel-representation方法的backbone和主流的研究进展。即目前主要可以分为如下的几个方向做出研究内容的改进:
(1)refine(2)loss(3)fusion(4)backboe -structure(5)others。
前面的文章中已经介绍到了基于refine和loss研究工作,这一篇主要介绍剩下的在3D目标检测中做研究的思路。
1. Fusion
1.1多模态融合和单模态多特征融合
就研究中的Fusion工作,也可以分为多模态信息融合和单模态多特征的融合。可以按照如下图来理解这里二者的差异,下图表示的是如果采用多传感器信息融合则是多模态,这一部分研就目前受到一些限制,比如因为view角度的不同,多传感器的信息精准融合是需要准确的信息;其次,在多传感器信息融合时需要考虑到时间帧问题,如果具有时差的数据融合也是很具有难度的。值得一提的是,目前很多研究工作都热衷于基于lidar的单模态做研究,做融合的工作还有着很大的发展空间的。
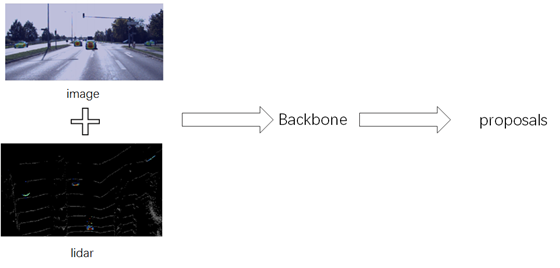

单模态多特征信息融合可以用如下的特征框表示。即可以采取多特征提取的方式对lidar数据做不同的特征提取,然后通过特征融合模块得到融合后的特征,再通过RPN网络学习到bounding-box的七个维度信息。

1.2 多模态特征融合
这里分享比较近的两篇文章。第一篇是来自浙大和阿里的合作工作,发表在AAAI20上的PI-RCNN。文章地址是:https://arxiv.org/pdf/1911.06084.
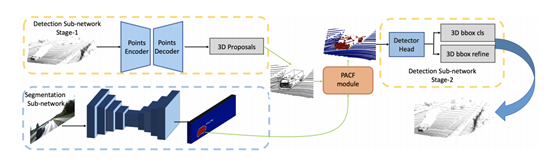
具体的网络结构如下。可以理解为一个两阶段的方法,其中stage-1是利用了在综述(一)中的backbbone提取高质量的3D候选框;而stage-2则是一个信息融合和候选框优化的过程。该阶段会利用通过对二维图像进行语义分割得到的分割后的图像信息。
具体的融合模块如下图所示。
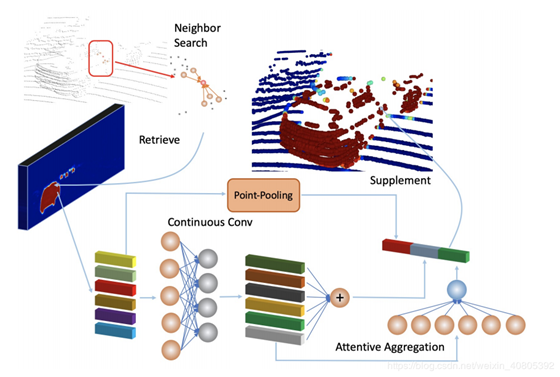
1.首选第一步是根据image和lidar的映射关系<下面括号是补充知识>(该映射关系根据图像到点云的投影矩阵计算得到,可以表示为下图所示的意思,每一个点实际上是可以和部分像素存在空间上的映射关系的,但是值得提到的是,由于KITTI数据中的相机存在多个,并且不同相机之间的数据是存在重叠的,也就是点云中一个点的数据可能是对应着不同相机在同一时刻拍摄到的图像中的某一块像素,所以选择哪个view拍摄到的图像也是需要做研究的,此外,这种通过映射关系的融合(目前也只有这种融合)存在image和point的尺度不对等问题,也就是说point的远近在图像中所对应的pix的数量也是不一致的,但是也都符合两种传感器的特性,即越远对应的细节信息越少)。

2.根据上面的索引关系可以得到每一个点对应到二维分割的特征信息,然后作者再采用了一个注意力模块将特征维度降维提取,最后做multi-feature的concat在一起做三维点云上的refine。本文的大概思路也就是如此,但是是第一个在将二维特征信息通过检索到三维点上的研究工作,之前的多模态融合的特征融合都是在feature上做融合,而本文的融合则是在refine模块做的融合,进一步的提高了检测的performance.第二篇分享的文章来自CVPR20的研究工作,pointpainting。文章地址:https://arxiv.org/pdf/1911.10150.pdf
也是一个将二维分割特征融合进三维点云的多模态信息融合工作,如下。作者给出的问题是在image中可以对小物体,例如杆子和行人清晰的辨认出,但是在Lidar模态中,看上去却很相似,因此作者想把这部分在image中可以清晰被辨认出的信息融合到在点云信息中,以提升目标检测的精度。
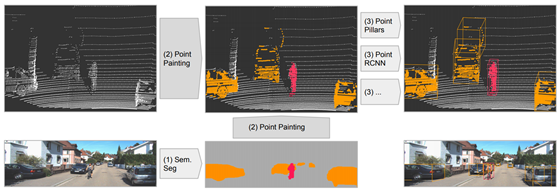
融合的方式和上文的PI-RCNN的又不一样,本文则是将分割得到的特征直接附加给点云,再送入到目标检测的框架中,而不是在refine阶段再做特征信息融合。可以简单的理解为“early-fusion”的概念,不做过多的处理直接把分割信息和点云最原始的特征叠加在一起。作者在多个baseline上做了实验对比,均显示这种多模态分割信息是有助于做3D目标检测任务的。
1.3 单模态多特征融合
由于这个系列都在介绍lidar的研究工作,那么仅仅依靠lidar特征,做特征信息融合应该怎么做;这里把之前稍微有介绍到的文章再做另外的角度的理解。
第一篇文章是来这CVPR20的HV-Net,文章地址为:https://arxiv.org/pdf/2003.00186
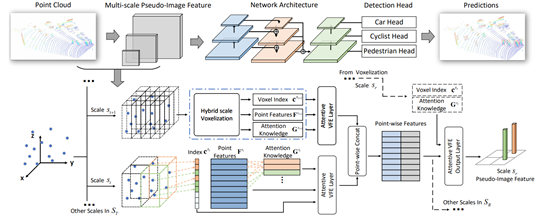
如下图所示,本文的核心思想是改变多组voxel划分的参数大小,对不同尺度的信息做提取,然后再多Multi-scale的特征融合。也就是说在对每一组不同的voxel参数做特征提取时,会采用一个同样的方法做多尺度的信息提取。最后也就会对应着一组特征,再利用类似二维图像中FPN的结构对multi-scale的特征进行融合即可。
第二篇在单模态上做特征融合的工作可以是CVPR20上表现最为出色的工作PV-RCNN。之前也有很多笔者写了很多的解读。文章地址是:https://arxiv.org/pdf/1912.13192.pdf。
同时最近笔者也看了原作者在B站上关于3D目标检测的一些内容讲解,地址分享:https://www.bilibili.com/video/BV1E741177wr/
强烈推荐做相关研究的同学去看一下。
回到正文,如下图所示,PV-RCNN是一个两阶段的方法,其中stage-1也是用在综述(一)中所介绍的稀疏backbone,通过该backbone提出高质量的候选框,然后通过二阶段的优化进一步得到最终的回归框,但是在文章的refine阶段是多特征voxel特征在点上的融合,如下图所示的内容,multi-scale的voxel的特征经过索引回到point-representation,最后通过作者提出的ROI-Pooling模块得到经过融合后的key-points在grid-points上的特征表示。最后通过grid-poits做进一步候选框的优化。
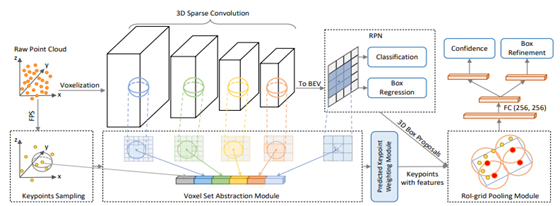
可以说,本文的研究工作不仅仅是一个multi-scale的voxel的特征信息融合,同时也是point和voxel的融合。point的方法具有可变多尺度感受野的特征,而voxel的方法的高效性在本文中也得到了很好的体现。
2.Backbone-Structure
在网络结构上做出创新的工作目前都需要在representation上做出创新,比如今年CVPR20上的PointGCN通过对point-cloud做建图然后设计图卷积网络作为backbone,在笔者之前的博客中有细致的讲到过这一篇文章,按分类也不能再分为voxel-represntation的表示形式。
这里笔者也介绍两篇在voxel领域中的新的backbone-structure。
2.1 cube voxels和sphere voxels
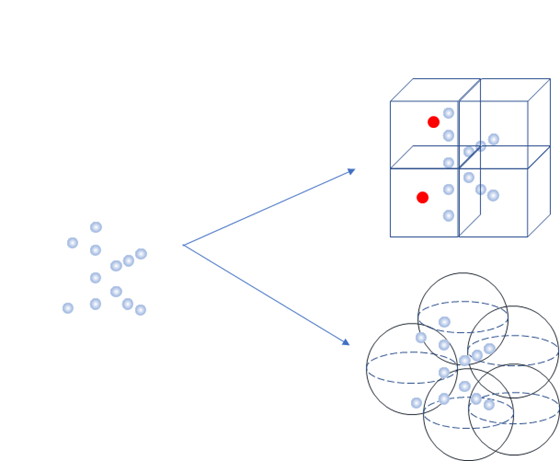
如下图所示,为两种不同的voxel表达形式,笔者之前综述中也介绍到了cube-voxels的表达形式,但是实际上在ICCV19上的一篇文章提出了通过划分sphere来做为voxel对局部的点做特征提取。对比cube形式,sphere最大的好处在于没有朝向问题,我们知道假如目标检测的一个car在一个cube的anchor中,那么需要对该朝向首先设置一个标准值(目前是90度和180度,也有更多的,比如在文章fast-point-rcnn中设置的是45,90,135和180四个角度),但是在sphere的anchor中则不需要这样的设置,这样可以减少倍数的anchor占用。
2.2 对应研究工作
作为介绍性文章,只对文章做主要内容介绍,不做过多的探究。要想获得深刻的认识需要阅读原文和对应的代码。
第一篇文章是上面提到的ICCV19的STD,文章地址为:https://arxiv.org/pdf/1907.10471
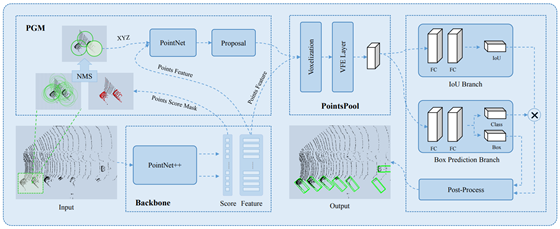
来自腾讯优图和港科大的研究工作,是一年前的工作了。为一个两阶段的方法,如下图所示。
(1)第一个阶段PGM是通过一个man-made的球形anchor生成一个proposal(这就和voxelnet系列不一样了,voxelnet系列都是预先定义一个anchor每个anchor一个proposals,而不是要生成一个proposal,最大的区别是:voxelnet系列的特征是以小size的anchor为单位的,而这一篇文章则是以一个“proposal”提取的),作者是先通过语义信息对每一个点生成一个球形anchor,再通过nms得到最终的分类proposals,接下来是pointpool层得到每一个proposals的特征,采用的是VFE。
(2)第二阶段则是作者的IOU Branch和Box Prediction Branch的结合。(感觉这才是巨大的创新)
STD在KITTI上的表现在当时是很好的,下面这一篇是最近才放在arxiv上的研究工作,可以说是STD的后续研究,来自电子科技大学,目前就其在论文中展示的精度,超过了PV-RCNN,获得了新的冠军,按照投稿的单栏形式,应该是NIPS20。
文章地址:https://arxiv.org/pdf/2006.04043
主要网络结构如下图所示,如果说它是一个fusion的研究工作也是可以的,作者提出了新的voxel-graph的表示形式来进一步优化在voxel表示中存在的问题。voxel-based的方法对Local-pointnets的局部之间不能建立联系。所以本文从这个点出发建立了Voxel-GraphAttention Network。该网络首先在球型体素内构造局部graph,然后再通过voxels构造全局global KNN。这里的局部的graph和全局的graph用于注意力机制去强化提取到的特征。可以看出在sphere-voxel-graph的模式下特征通过图得到了更好的提取和融合。
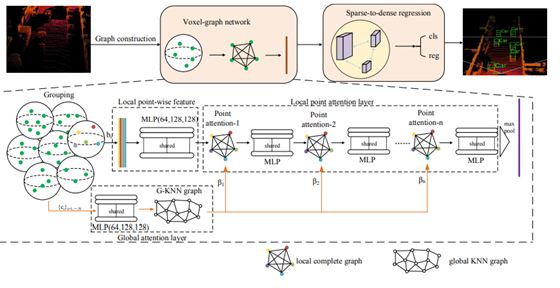
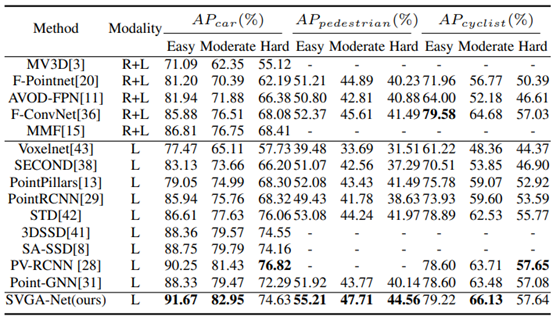
最后看一下该文章在KITTI-test数据集上的表现,如下。可以看出比高居榜首长达半年的PV-RCNN还要推进了1个点。非常好的工作,开源后一定要研读一番。
3. 补充知识
3.1 3D-Bbox可视化
也是因为笔者最近参加了一个训练营,其中有一个赛题是和该项目相关,所以在对场景可视化方面做了一下工作。
如下图,可以看出128线的数据具有以下的几个特点:
-
点云场景稠密
-
场景中的object比较多,相对KITTI而言多很多,场均有50+,而kitti一帧能有10个已经是很多的了
-
全场景的数据标注(对于KITTI而言仅仅在FOV视角下的点才得以保留,原因是KITTI的标注只有FOV内)
-
点云数据Z轴朝上(对于KITTI是Y轴朝上,因此旋转轴是Y轴)
-
以右手系建立,其中z轴指向上方(在KITTI中y轴指向上方),读取的文件信息(****.bin)包含了(x,y,z,intensity),也是分别和三轴位置对应。

bbox可视化
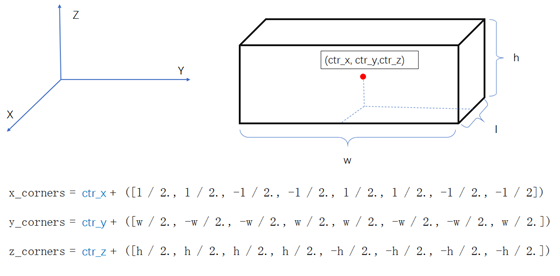
读取到的信息是Bbox的中心(x,y,z)和对应的长宽高(l,w,h分别对应着坐标轴的x,y,z三个轴),以及对应的z轴顺时针旋转角(yaw)
所以可视化的想法就是从上面的label信息得到bbox的八个角点,然后通过把对应的角点连线画出bbox即可。解决思路可以分解为两步:1.在不考虑旋转角度情形下计算八个角点的x,y,z的坐标。
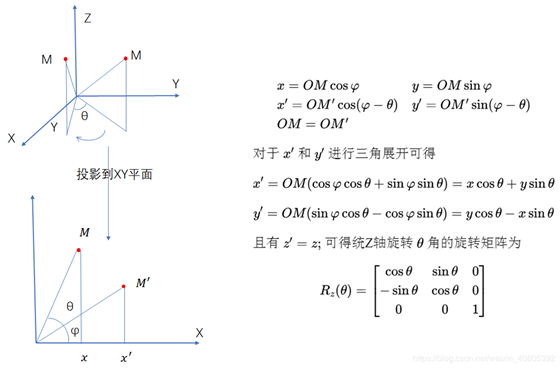
2.在得到的每一个角点的基础上加入旋转角度,这里的数据考虑的是沿着z轴的顺时针旋转。笔者以一个点为例展示三维旋转矩阵的求取。
所以最终坐标转换代码为:
defboxes3d_to_corners3d_camera(boxes3d, bottom_center=False): boxes_num = boxes3d.shape[0] l,w,h=boxes3d[:, 3], boxes3d[:, 4],boxes3d[:, 5] x_corners = np.array([l / 2., l / 2., -l /2., -l / 2., l / 2., l / 2., -l / 2., -l / 2], dtype=np.float32).T y_corners = np.array([w / 2., -w / 2., -w /2., w / 2., w / 2., -w / 2., -w / 2., w / 2.], dtype=np.float32).T z_corners = np.array([h / 2., h / 2., h /2., h / 2., -h / 2., -h / 2., -h / 2., -h / 2.], dtype=np.float32).T ry = boxes3d[:, 6] zeros, ones = np.zeros(ry.size,dtype=np.float32), np.ones(ry.size, dtype=np.float32) rot_list = np.array([[np.cos(ry), np.sin(ry),zeros ], [-np.sin(ry), np.cos(ry), zeros], [zeros, zeros, ones]]) # (3, 3, N) temp_corners =np.concatenate((x_corners.reshape(-1, 8, 1), y_corners.reshape(-1, 8, 1), z_corners.reshape(-1, 8, 1)), axis=2) # (N, 8, 3) rotated_corners = np.matmul(temp_corners,R_list) # (N, 8, 3) x_corners, y_corners, z_corners =rotated_corners[:, :, 0], rotated_corners[:, :, 1], rotated_corners[:, :, 2] x_loc, y_loc, z_loc = boxes3d[:, 0],boxes3d[:, 1], boxes3d[:, 2] x = x_loc.reshape(-1, 1) +x_corners.reshape(-1, 8) y = y_loc.reshape(-1, 1) +y_corners.reshape(-1, 8) z = z_loc.reshape(-1, 1) + z_corners.reshape(-1,8) corners = np.concatenate((x.reshape(-1, 8,1), y.reshape(-1, 8, 1), z.reshape(-1, 8, 1)), axis=2) return corners.astype(np.float32)通过mayavi可视化如下:

推荐阅读
[1] PI-RCNN: An EfficientMulti-sensor 3D Object Detector with Point-based Attentive Cont-conv FusionModule
[2] Multi-view 3d object detection network for autonomous driving
[3] PointPainting: Sequential Fusion for 3D Object Detection
[4] HVNet: Hybrid Voxel Network for LiDAR Based 3D Object Detection
[5] STD: Sparse-to-Dense 3D Object Detector for Point Cloud本文仅做学术分享,如有侵权,请联系删文。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:3D目标检测深度学习方法中voxel-represetnation内容综述(三) - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 