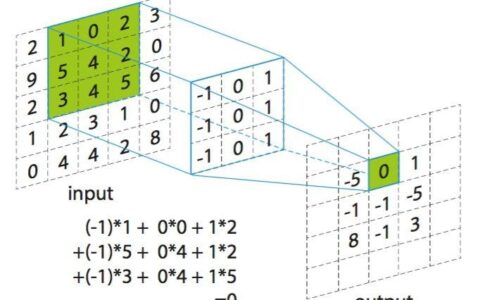
下面是关于“kaggle+mnist实现手写字体识别”的完整攻略。
kaggle+mnist实现手写字体识别
在本攻略中,我们将介绍如何使用kaggle和mnist数据集来实现手写字体识别。我们将使用两个示例来说明如何使用kaggle和mnist数据集来实现手写字体识别。以下是实现步骤:
示例1:使用kaggle和mnist数据集进行手写字体识别
在这个示例中,我们将使用kaggle和mnist数据集来训练模型,以实现手写字体识别。以下是实现步骤:
步骤1:准备数据集
我们将使用kaggle和mnist数据集来训练模型。以下是数据集准备步骤:
-
首先,我们需要从kaggle网站上下载mnist数据集。我们可以在kaggle网站上找到mnist数据集,并下载它。
-
然后,我们需要将数据集导入到我们的Python环境中。我们可以使用pandas库中的read_csv()函数来导入数据集。
import pandas as pd
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
在这个示例中,我们使用read_csv()函数从CSV文件中读取训练集和测试集。
步骤2:预处理数据
我们需要对数据进行预处理,以便将其用于训练模型。以下是预处理步骤:
import numpy as np
# 将训练集和测试集分为特征和标签
X_train = train.drop('label', axis=1).values
y_train = train['label'].values
X_test = test.values
# 将特征缩放到0到1之间
X_train = X_train / 255.0
X_test = X_test / 255.0
# 将标签转换为one-hot编码
from keras.utils import to_categorical
y_train = to_categorical(y_train)
在这个示例中,我们首先使用drop()函数将训练集中的标签列删除,并将其存储在X_train变量中。我们还将标签存储在y_train变量中。然后,我们使用MinMaxScaler()函数将特征缩放到0到1之间。接下来,我们使用to_categorical()函数将标签转换为one-hot编码。
步骤3:构建模型
我们将使用卷积神经网络(CNN)模型来训练模型。以下是模型构建步骤:
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), activation='relu'),
Flatten(),
Dense(64, activation='relu'),
Dropout(0.5),
Dense(10, activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
在这个示例中,我们首先使用Sequential()函数创建一个序列模型。然后,我们使用Conv2D()函数添加一个卷积层,并将其输出维度设置为32。我们还使用MaxPooling2D()函数添加一个池化层。接下来,我们添加另一个卷积层和池化层。然后,我们使用Flatten()函数将输出展平。接下来,我们添加两个密集层,并将激活函数设置为'relu'。我们还添加一个Dropout层,以减少过拟合。最后,我们添加一个输出层,并将激活函数设置为'softmax'。我们使用compile()函数编译模型,并将优化器设置为'adam',损失函数设置为'categorical_crossentropy',指标设置为'accuracy'。
步骤4:训练模型
我们将使用训练集来训练模型。以下是训练步骤:
history = model.fit(X_train.reshape(-1, 28, 28, 1), y_train, epochs=10, validation_split=0.2)
在这个示例中,我们使用fit()函数训练模型,并将训练集和标签作为输入,将epochs设置为10,将验证集比例设置为0.2。
步骤5:测试模型
我们将使用测试集来测试模型的准确性。以下是测试步骤:
predictions = model.predict(X_test.reshape(-1, 28, 28, 1))
在这个示例中,我们使用predict()函数计算模型在测试集上的预测,并将其存储在predictions变量中。
示例2:使用kaggle和mnist数据集进行手写字体识别(使用数据增强)
在这个示例中,我们将使用kaggle和mnist数据集来训练模型,以实现手写字体识别。与示例1不同的是,我们将使用数据增强来增加训练集的大小。以下是实现步骤:
步骤1:准备数据集
我们将使用kaggle和mnist数据集来训练模型。以下是数据集准备步骤:
-
首先,我们需要从kaggle网站上下载mnist数据集。我们可以在kaggle网站上找到mnist数据集,并下载它。
-
然后,我们需要将数据集导入到我们的Python环境中。我们可以使用pandas库中的read_csv()函数来导入数据集。
import pandas as pd
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
在这个示例中,我们使用read_csv()函数从CSV文件中读取训练集和测试集。
步骤2:预处理数据
我们需要对数据进行预处理,以便将其用于训练模型。以下是预处理步骤:
import numpy as np
# 将训练集和测试集分为特征和标签
X_train = train.drop('label', axis=1).values
y_train = train['label'].values
X_test = test.values
# 将特征缩放到0到1之间
X_train = X_train / 255.0
X_test = X_test / 255.0
# 将标签转换为one-hot编码
from keras.utils import to_categorical
y_train = to_categorical(y_train)
在这个示例中,我们首先使用drop()函数将训练集中的标签列删除,并将其存储在X_train变量中。我们还将标签存储在y_train变量中。然后,我们使用MinMaxScaler()函数将特征缩放到0到1之间。接下来,我们使用to_categorical()函数将标签转换为one-hot编码。
步骤3:构建模型
我们将使用卷积神经网络(CNN)模型来训练模型。以下是模型构建步骤:
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from keras.preprocessing.image import ImageDataGenerator
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), activation='relu'),
Flatten(),
Dense(64, activation='relu'),
Dropout(0.5),
Dense(10, activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
datagen = ImageDataGenerator(
rotation_range=10,
zoom_range=0.1,
width_shift_range=0.1,
height_shift_range=0.1
)
在这个示例中,我们首先使用Sequential()函数创建一个序列模型。然后,我们使用Conv2D()函数添加一个卷积层,并将其输出维度设置为32。我们还使用MaxPooling2D()函数添加一个池化层。接下来,我们添加另一个卷积层和池化层。然后,我们使用Flatten()函数将输出展平。接下来,我们添加两个密集层,并将激活函数设置为'relu'。我们还添加一个Dropout层,以减少过拟合。最后,我们添加一个输出层,并将激活函数设置为'softmax'。我们使用compile()函数编译模型,并将优化器设置为'adam',损失函数设置为'categorical_crossentropy',指标设置为'accuracy'。
我们还使用ImageDataGenerator()函数创建一个数据增强生成器,以增加训练集的大小。
步骤4:训练模型
我们将使用训练集来训练模型。以下是训练步骤:
history = model.fit_generator(datagen.flow(X_train.reshape(-1, 28, 28, 1), y_train, batch_size=32),
steps_per_epoch=len(X_train) / 32, epochs=10, validation_split=0.2)
在这个示例中,我们使用fit_generator()函数训练模型,并将数据增强生成器作为输入,将batch_size设置为32,将steps_per_epoch设置为len(X_train) / 32,将epochs设置为10,将验证集比例设置为0.2。
步骤5:测试模型
我们将使用测试集来测试模型的准确性。以下是测试步骤:
predictions = model.predict(X_test.reshape(-1, 28, 28, 1))
在这个示例中,我们使用predict()函数计算模型在测试集上的预测,并将其存储在predictions变量中。
总结
在本攻略中,我们使用kaggle和mnist数据集实现了两个手写字体识别示例。我们首先准备数据集,然后对数据进行预处理,构建模型,训练模型,测试模型。在第一个示例中,我们使用CNN对手写字体进行分类。在第二个示例中,我们使用CNN和数据增强对手写字体进行分类。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:kaggle+mnist实现手写字体识别 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 ![[转] 理解CheckPoint及其在Tensorflow & Keras & Pytorch中的使用](https://pythonjishu.com/wp-content/uploads/2023/04/DBLFlaTHBOWa20230406-480x300.jpg)