主用python做项目有一段时间,这次简单总结学习下。为后面的项目编写,进行一次基础知识的查缺补漏、
1、变量名和数据类型
"""
变量名,只能由" 数字、大小写字母、_ " 组成,且不能以数字开头
"""
# 整数 int
# hashable,不可变对象
a = 5
# 浮点数 float
# hashable,不可变对象
a1 = 3.14
# 字符串 string
# hashable,不可变对象
a_1 = "哈哈哈"
str_num = '5'
_str_float = """3.14"""
_ = '''hello world''' # 常常用于接收我们不需要使用的值
# 列表 list
# 元素可修改,元素有顺序
# 列表是unhashable, 可变对象
tmp_list = [1, 3.14, "haha", [7, "qq"]]
# 元组 tuple
# 元素不可修改,元素有顺序
# 元组是hashable,不可变对象
tmp_tuple = (1, 3.14, "haha", [7, "qq"])
# 集合 set
# 元素不重复,即使重复,也会自动去重。元素没有顺序
# 元素必须是hashable,不可变对象
# 集合是unhashable, 可变对象
tmp_set = {1, 1, 3.14, "haha"}
# 字典 dict 键值对形式--key:value,key不能重复
# key必须为hashable,不可变对象
# 字典是unhashable,可变对象
tmp_dict = {1: "xy", "a": 123, (1, "a"): [1, "abc", 3]}
# 布尔值 bool
# 布尔值是hashable,不可变对象
x = True
y = False
# None 不是0,不是空字符串"",不是False,啥也不是
# None是hashable, 不可变对象
t = None
# 常量 变量名用大写字母
# 约定俗成,并不是不可变
PI = 3.1415926
INT_LIST = [1, 2, 3, 4, 5]
2、注释&格式化输出
# 注释:对代码的说明性文字,不参与代码运行、运算
# 单行注释
"""
多行注释
多行注释
多行注释
"""
'''
多行注释
多行注释
多行注释
'''
# 格式化输入
name = "alex"
age = 100
# 占位符(不推荐)
res = "姓名: %s,年龄: %d" % (name, age) # 字符串就是%s 整数就是%d 浮点数%f
print("占位符输出: %s" % res)
# format(推荐)
res = "姓名:{},年龄:{}".format(name, age)
res = "姓名:{name},年龄:{age}".format(age=age, name=name)
print("format函数输出:{}".format(res))
# f前缀(python3.6以上)
res = f"姓名:{name},年龄:{age}"
print(f"f前缀输出:{res}")
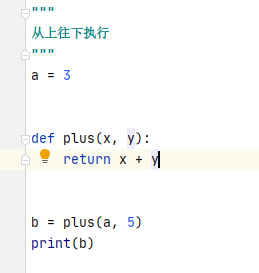
3、代码执行顺序
先调用会报错,放在后面即可运行。
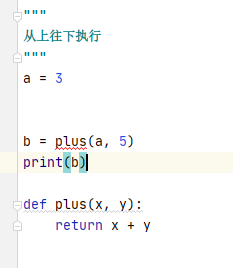

"""
从上往下执行
"""
a = 3
def plus(x, y):
return x + y
b = plus(a, 5)
print(b)
4、算数运算符&整浮互相转化&精度问题
"""
算术运算符: +、 -、 *、 /、 //、 **、%
"""
# 加
res = 2 + 3
print(f"2 + 3 = {res}")
# 减
res = 2 - 3
print(f"2 - 3 = {res}")
# 乘
res = 2 * 3
print(f"2 * 3 = {res}")
# 除
res = 2 / 3
print(f"2 / 3 = {res}")
# 整除
res = 5 // 2
print(f"5 // 2 = {res}")
# 取余
res = 5 % 2
print(f"5 % 2 = {res}")
# 次幂
res = 2 ** 3
print(f"2 ** 3 = {res}") # 2的三次方
"""
浮点数和整数的互相转换
以及常用函数abs
"""
# 整数转浮点数
a = 5
print("a = 5, a的类型为:{}".format(type(a)))
a = float(a)
print("float(a) = {}, a的类型为:{}".format(a, type(a)))
# 浮点数转整数,直接取整数位,没有四舍五入
b = 3.55
print("b = 3.55, b的类型为:{}".format(type(b)))
b = int(b)
print("int(b) = {}, b的类型为:{}".format(b, type(b)))
# abs 取绝对值
c = -3.14
print("c = -3.14, c的类型为:{}".format(type(c)))
c = abs(c)
print("abs(c) = {}, c的类型为:{}".format(c, type(c)))
# round,精度低,不推荐
b = 3.55
b = round(b, 1)
print("round(b) = {},b的类型为:{}".format(b, type(b))) # 3.5不是3.6
# 标准库decimal
from decimal import Decimal
b = 3.55
b = str(b)
b = Decimal(b).quantize(Decimal("0.1"),rounding="ROUND_HALF_UP") # 四舍五入 Decimal保留小数的位数
print("round(b) = {},b的类型为:{}".format(b, type(b)))
5、赋值运算符
"""
赋值运算符:
=, +=, -=, *=, /=, //=, %=, **=
"""
a = 2
a = a + 2 # a = 4
a += 2 # a = 6
a = a - 2 # a = 4
a -= 2 # a = 2
a = a * 2 # a = 4
a *= 2 # a = 8
6.1、编码
"""
在计算机中存储的是二进制数 10011011
在计算机最小存储单位,1位二进制数,即1个Bit(比特)
1 Byte(字节) = 8 Bits
1 KB = 1024 Bytes 2**10 = 1024
1 MB = 1024 KB
编码问题:
1、ASCII编码,只有大小写字母、数字、特色符号,
用1个Byte表示一个字符
例如:字母A 01000001
2、GB2312,Euc-kr,Shift_JIS ...
各国有各国的标准,必然会冲突,即乱码
3、Unicode编码(万国码),所有语言统一使用这一套编码
通常用2个Byte表示一个字符(生僻字符要4个Byte)
依然存在问题:
例如用户只用英文的话,采用这种编码,
占用的存储空间是ASCII编码的2倍。
例如:字母A 00000000 01000001
4、UTF-8编码
把Unicode字符集编码成1-6个Byte
(1)大小写英文字母、数字、特殊符号
维持ASCII编码,1个Byte
例如,字母A的ASCII码和UTF-8码是一样的
01000001
(2)中文通常是 3个Byte
(3)生僻的字符 4-6个Byte
5、Python3.X 源码.py文件默认使用UTF-8
Python3.X 默认使用ASCII,所以需要指明
# -*- coding:UTF-8 -*-
6、计算机内存中,使用的是Unicode编码
需要存储或传输时,会吧内存中的Unicode转为UTF-8
"""
6.2、字符串常用方法
"""
去除首尾指定字符,默认去除空格,返回值均为字符串
strip() # 左右都去除
lstrip() # 只去除左边
rstrip() # 只去除右边
"""
tmp = "----举个--栗子---"
tmp_lstrip = tmp.lstrip("-")
tmp_rstrip = tmp.rstrip("-")
tmp_strip = tmp.strip("-")
print("tmp_lstrip:{}".format(tmp_lstrip))
print("tmp_rstrip:{}".format(tmp_rstrip))
print("tmp_strip:{}".format(tmp_strip))
"""
startswith() 判断字符串是否以指定的字符串开头
endswith() 判断字符串是否以指定的字符串结尾
返回值均为布尔值,即True或False
"""
tmp = "这次继续举个栗子"
if tmp.startswith("这次"):
print("tmp是以'这次'开头的")
if tmp.endswith("子"):
print("tmp是以'子'结尾的")
"""
分割字符串
split(sep, maxsplit):
1、sep:指定分割符,默认为空格
2、maxsplit:分割次数,默认为-1即全部分割
3、返回值为一个列表list
"""
tmp = "Python,C,C++,Java,Vue"
res = tmp.split(",")
res_2 = tmp.split(",", 2)
print("res:{}".format(res))
print("res_2:{}".format(res_2))
"""
lower() 全转为小写
upper() 全转为大写
"""
tmp = "What's up! Man!"
tmp_l = tmp.lower()
tmp_u = tmp.upper()
print("大写:{}".format(tmp_u))
print("小写:{}".format(tmp_l))
"""
is系列方法,最常用的三个:
isalpha() 判断字符串是否仅含有字母
isdigit() 判断字符串是否仅含有数字
isalnum() 判断字符串是否仅含字母或数字
均返回布尔值,即True或False
"""
tmp_1 = "23"
tmp_2 = "python"
tmp_3 = "python666"
if tmp_1.isdigit():
print("tmp_1中仅含数字")
if tmp_2.isalpha():
print("tmp_2中仅含字母")
if tmp_3.isalnum():
print("tmp_3中仅含字母或数字")
"""
子字符串替换
replace(old, new, count)
1、old:被替换的子字符串
2、new:新的子字符串
3、count:替换次数,默认为-1全部替换
"""
tmp = "Python66666"
# 全部替换
tmp_1 = tmp.replace("6", "9")
# 从左往右,替换指定次数
tmp_2 = tmp.replace("6", "1", 4)
# 找不到指定的子字符串,则不替换
tmp_3 = tmp.replace("java", "go")
print(tmp_1)
print(tmp_2)
print(tmp_3)
"""
获取子字符的索引
1、index(sub,start,end) 从左往右
1)sub,子字符
2)start,查找的起始位置
3)end,查找的终止位置-1
2、rindex() 从右往左
3、只找一个,且若sub存在,则会报错
"""
# 012345678
tmp = "Python666"
# 正向查找
index_1 = tmp.index("6", 5, 7) # 实际是在第5个索引和第6个索引查找
# 反向查找
index_2 = tmp.rindex("6")
print("index_1:{}".format(index_1))
print("index_2:{}".format(index_2))
6.3、字符串转义
"""
字符串转义:
\n 换行符,将光标位置移到下一行开头。
\r 回车符,将光标位置移到本行开头。
\t 水平制表符,即Tab键
\a 蜂鸣器响铃。现在的电脑一般都没有蜂鸣器了
\b 退格(Backspace),将光标位置移到前一列。
\\ 反斜杠
\' 单引号
\" 双引号
"""
a = "这是换行,\n 这是\r回车符,这是\t制表符," \
"这里是退格\b\n" \
"这是反斜杠\\, 这是单引号\', 这是双引号\""
print(a)
7、比较运算符&if...else
"""
比较运算符: ==, !=, >, >=, <, <=
运算结果都是布尔值,即True或者False
"""
a = 1
b = 1
c = 2
# 单个if
if a == b:
res = a - b
print(f"a等于b,a-b={res}")
# if...else...
if a != b:
print("a不等于b")
else:
print("a等于b")
# if...elif...elif..............else...
if a > b:
print("a大于b")
elif a == b:
print("a等于b")
elif a < b:
print("c大于a")
else:
print()
# 嵌套
if a >= b:
print("a大于等于b")
if a == b:
print("a等于b")
else:
print("a不等于b")
8、身份运算符
"""
身份运算符:is,is not(尝用于判断是否为None)# 两个变量内存地址是否相同
运算结果为布尔值,即True或False
x is y 等效于 id(x) == id(y)
x is not y 等效于 id(x) != id(y)
"""
# 小整数池: -5~256
a = -5
b = -5
print("均为-5,a is b结果为{}".format(a is b))
print("id(a)={},id(b)={}\n".format(id(a), id(b)))
# 在pycharm运行会是true:pc会先保存257的内存地址,发现b也是257 b指向a的内存地址
a = 257
b = 257
print("均为257,a is b结果为{}".format(a is b))
print("id(a)={},id(b)={}\n".format(id(a), id(b)))
# 字符串池: 长度不超过20,且没有空格,内存地址相同
a = "test"
b = "test"
print("均为\"test\",a is b结果为{}".format(a is b))
print("id(a)={},id(b)={}\n".format(id(a), id(b)))
a = "te st"
b = "te st"
print("均为\"te st\",a is b结果为{}".format(a is b))
print("id(a)={},id(b)={}\n".format(id(a), id(b)))
# 代码在终端运行则会不一样
这种情况可能是因为Python的整数缓存机制导致的,具体表现为在某些情况下,Python会缓存一些整数对象以提高性能,这些对象的引用会被多个变量共享。根据官方文档,Python 3.7及更高版本中,整数对象的缓存机制默认会缓存从-5到256之间的整数对象。
在Python中,我们应该使用==运算符来比较两个对象的值是否相等,而不是使用is运算符来比较它们是否是同一个对象。
9、成员运算符
"""
成员运算符:in not in
运算结果为布尔值,即True或者False
"""
tmp_str = "Hello, World"
tmp_list = [1, 2, 3, "a", "b"]
tmp_tuple = (1, 2, 3, "a", "b")
tmp_set = {1, 2, 3, "a", "b"}
tmp_dict = {"a": 1, "b": 2}
if "lo" in tmp_str:
print(f"lo在字符串{tmp_str}中")
if 4 not in tmp_list:
print(f"4不在列表{tmp_list}中")
# 字典是判断存在"a"这个key
if "a" in tmp_dict:
print(f"a在字典{tmp_dict}中")
if 1 in tmp_dict:
print(f"1在字典{tmp_dict}中")
10、逻辑运算符
"""
逻辑运算符:and(与), or(或), not(非)
"""
a = 1
b = 2
c = 3
# x and y,要求x和y都为True, 运算结果才为True,
# 否则为False
if a < c and b < c:
print("a小于c,且b小于c")
else:
print("a不小于c或者b不小于c")
# x or y,只要x和y中有一个为True,运算结果就为True,
# 否则为False
if b > a or b > c:
print("b大于a或者b大于c")
else:
print("b不大于a且b不大于c")
# not x,取相反的值
if not (a < b): # 小括号运算优先级最高 不然就把a取反了
print("a不小于b")
else:
print("a小于b")
11、列表&元组
# 空列表
a = []
b = list()
c = [1, 2, 3]
# 空元组
d = ()
e = tuple()
# 定义只有一个元素的元组,一定要加一个逗号,
f = ("a",)
g = ("a") # 不然括号只能算是一个优先级的运算符,只会是一个字符串
print(f"f的数据类型为{type(f)}")
print(f"g的数据类型为{type(g)}")
"""
追加列表元素
list.append(item)
1、item,为任意元素
2、返回值为None
"""
tmp = ["a", 3, "c"]
tmp.append(["b", 1])
print(f"tmp.append([\"b\",1])追加到原始列表:{tmp}")
"""
将元素插入列表
list.insert(index,item)
1、index,插入位置的索引
2、item,要插入的元素
3、返回值为None
当index大于列表最大正向索引时,插入尾端
当index小于列表最小反向索引时,插入首端
"""
# 0 1 2
# -3 -2 -1
tmp = ["a", "c", "d"]
tmp.insert(1, "b")
print(tmp)
"""
列表的合并
list.extend(iterable)
1、iterable,可迭代对象
字符串、列表、元组、集合、字典。。。
2、返回值为None
"""
tmp = [1, 2, 3]
tmp_new = [4, 5, 6, 7]
tmp.extend(tmp_new)
print(f"tmp.extend(tmp_new)改变原始列表:{tmp}")
"""
删除指定索引的元素
list.pop(index)
1、index,要删除元素的索引
2、不传index,默认删除最后一个
3、有返回值,返回被删除的元素
4、若列表为空列表,或者,index超出列表范围都会报错
"""
tmp = ["Python", "Java", "Go", "C"]
a = tmp.pop()
print(f"先删掉了{a},{tmp}")
b = tmp.pop(1)
print(f"再删掉了{b},{tmp}")
"""
删除指定元素(从左往右找,只删除找到的第一个)
list.remove(item)
1、item,要删除的元素
2、返回值为None
3、若指定的删除元素不存在,则报错
"""
tmp = ["Python", "Java", "Go", "C"]
tmp.remove("Java")
print(f"tmp.remove(\"Java\")改变原始列表:{tmp}")
"""
清空&清除部分
1、list.clear()
2、del list[index]
3、del list[start:end]
返回值为None,均作用于原始列表
"""
tmp1 = ["Python", "Java", "Go"]
tmp1.clear()
print(f"tmp1.clear()结果:{tmp1}")
tmp2 = ["Python", "Java", "Go", "C"]
del tmp2[-1]
print(f"tmp2[-1]结果:{tmp2}")
del tmp2[1:] # 索引切片1到末尾全删
print(f"tmp2[1:]结果:{tmp2}")
del tmp2[:] # 整个列表全都清空
print(f"tmp2[:]结果:{tmp2}")
"""
列表翻转
1、list.reverse()
改变原列表,返回值为None
2、切片,list[::-1]
不改变原列表,会生成新的列表
"""
tmp = [1, 2, 3, 4, 5]
tmp.reverse()
print(f"tmp.reverse()翻转原始列表:{tmp}")
"""
列表排序
1、list.sort() 返回值为None,改变原始列表
2、 sorted(list) 有返回值,生成新列表,原始不变
"""
tmp = [4, 1, 3, 2, 5]
tmp.sort()
print(f"tmp.sort()改变原始列表:{tmp}")
tmp = [4, 1, 3, 2, 5]
tmp.sort(reverse=True) # 降序
print(f"tmp.sort(reverse = True)降序:{tmp}")
tmp = [4, 1, 3, 2, 5]
res = sorted(tmp) # 升序
print(f"sorted(tmp)新生成列表:{res}")
tmp = [4, 1, 3, 2, 5]
res = sorted(tmp, reverse=True)
print(f"sorted(tmp,reverse = True)降序:{res}")
"""
统计指定元素在列表中出现的次数
list.count(item)
1、item:要统计的元素
2、返回值为整数
"""
tmp = ["a", 2, 3, 2, "2", "2", "2"]
count_num_2 = tmp.count(2)
count_str_2 = tmp.count("2")
print(f"数字2出现了{count_num_2}次")
print(f"字符串\"2\"出现了{count_str_2}次")
12、集合常用方法
a = {} # 这是空字典
b = set() # 这才是空集合
print(f"a = {{}}的数据类型为{type(a)}")
print(f"b = set()的数据类型为{type(b)}")
c = {1, 2, 2, 2, 3, 4, 5}
"""
集合,添加元素
1、set.add(item) 添加单个元素
2、set.update(item) 添加多个元素
返回值均为None,改变原始集合
"""
tmp = {"a", "b", "c"}
tmp.add("c")
tmp.add("1")
tmp.update(["1", "c"]) # 列表、元组、集合均可
print(tmp)
"""
移除元素
1、set.remove(item) 返回值为None,改变原始集合
item不存在,会报错
2、set.discard(item) 返回值为None,改变原始集合
item不存在,不会报错
3、set.pop() 改变原始集合
随机删除一个元素,并返回被删除的元素
"""
tmp = {"a", "b", "c", "d", "e"}
tmp.remove("c")
tmp.discard("f")
x = tmp.pop()
print(f"tmp.pop()随机移除了{x}")
print(f"tmp={tmp}")
"""
求合集(集合的合并)
1、set_a.union(set_b,set_c,...)
2、set_a | set_b | set_c | ...
(竖杆,不是斜杠)
"""
set1 = {"Python", "Go"}
set2 = {"Python", "Rust"}
new_set1 = set1.union(set2)
print(f"set1 set2合集为{new_set1}")
"""
求差集
1、set_a.difference(set_b,set_c,...)
2、set_a - set_b - set_c - ...
均不改变原始集合,返回值是新的集合
"""
set1 = {"Python", "Go"}
set2 = {"Python", "Rust"}
new_set1 = set1.difference(set2)
# new_set1 = set1 - set2
new_set2 = set2.difference(set1)
# new_set2 = set2 - set1
print(f"set1 - set2 = {new_set1}")
print(f"set2 - set1 = {new_set2}")
"""
求交集(找共同的元素)
1、set_a.intersection(set_b,set_c,...)
2、set_a & set_b & set_c & ...
均不改变原始集合,返回值是新的集合
"""
set1 = {"Python", "Go"}
set2 = {"Python", "Rust"}
new_set1 = set1.intersection(set2)
print(f"set1,set2交集为{new_set1}")
"""
求不重合集
set_a.symmetric_difference(set_b,set_c,...)
不改变原始集合,返回值是新的集合
"""
set1 = {"Python","Go"}
set2 = {"Python","Rust"}
res = set1.symmetric_difference(set2)
print(f"set1,set2不重合集为{res}")
"""
判断是否为子集
set_b.issubset(set_a)
即表示判断set_b是否为set_a的子集
结果为布尔值,即True或False
"""
set1 = {"Python","Go"}
set2 = {"Python"}
# set2是否为set1的子集
res = set2.issubset(set1)
print(res)
13、字典常用方法
# 空字典
a = {}
a = dict()
# 若字典没有这个key,则会添加这对键值对
a["name"] = "Kwan"
a["age"] = 88
print(f"空字典添加两个值后{a}")
a["age"] = 99
print(f"修改\"age\"的value{a}")
b = {"name": "Kwan", "age": 99}
b = dict(name="Kwan", age=99)
# dict类中参数不能使用数字,会报错
# b = dict(name="Kwan",age=99,1="abc")
# 元组列表
tuple_list = [("name", "Kwan"), ("age", 99)]
c = dict(tuple_list)
print(f"元组列表生成的字典{c}")
# 所有key都赋予相同的值
key_list = ["name", "age"]
d = dict.fromkeys(key_list, "你猜")
print(f"所有key都赋予相同的值{d}")
"""
字典取值方法
1、dict.get(key,default_value)
1)若key不存在则返回default_value
2)default_value默认为None
2、dict[key]
若key不存在,则报错
"""
tmp_dict = {"name": "Kwan", "age": 88}
res1 = tmp_dict.get("name")
# res1 = tmp_dict["name"]
res2 = tmp_dict.get("sex", "未知性别")
# res2 = tmp_dict["sex"] 报错
print(res1)
print(res2)
"""
获取字典所有的key
dict.keys()
1、返回值不是列表,是dict_keys对象
2、一般与for搭配使用
"""
tmp_dict = {"name": "Kwan", "age": 88}
res = tmp_dict.keys()
print(type(res))
for key in res:
print(key)
"""
获取字典所有的value
dict.values()
1、返回值不是列表,是dict_values对象
2、一般与for搭配使用
"""
tmp_dict = {"name": "Kwan", "age": 88}
res = tmp_dict.values()
print(type(res))
for value in res:
print(value)
"""
获取字典所有的key和value
dict.items()
1、返回值不是列表,是dict_items对象
2、一般与for搭配使用
"""
tmp_dict = {"name": "Kwan", "age": 88}
res = tmp_dict.items()
print(type(res))
# [(key1,value1),(key2,value2)]
for key, value in res:
print(f"key:{key},value:{value}")
"""
字典的更新
dict_a.update(dict_b)
可以新增新的键值对,也可修改已存在的键值对
"""
tmp1 = {"name": "Kwan", "age": "88"}
tmp2 = {"sex": "male", "age": 99}
tmp1.update(tmp2)
print(tmp1)
14、索引和切片
# 索引,超过变量长度-1就会报错
# 1234567891011
a = "Hello, World"
a_len = len(a)
res = a[7]
print(f"a的长度为{a_len},a[7] = {res}")
# -6 -5 -4 -3 -2 -1 反向索引
# 0 1 2 3 4 5 正向索引
b = ["x", "y", "z", 1, 2, 3]
res = b[-1]
print(res)
# 切片,顾头不顾尾
# [头:尾:步长] 步长默认为1
# -6 -5 -4 -3 -2 -1 反向索引
# 0 1 2 3 4 5 正向索引
b = ["x", "y", "z", 1, 2, 3]
res1 = b[0:3] # 0到3之间的索引 不包括尾
# res1 = b[:3]
# res1 = b[-6:-3]
res2 = b[3:6]
res3 = b[::2] # 从头取到尾,步长为2
res4 = b[::-2] # 从头取到尾,步长为-2
res5 = b[::-1] # 从头取到尾,步长为-1,列表翻转
print(f"b[0:3] = {res1}")
print(f"b[3:6] = {res2}")
print(f"b[::2] = {res3}")
print(f"b[::-2] = {res4}")
print(f"b[::-1] = {res5}")
15、for循环
# for ... in 循环
weeks_list = ["周一", "周二", "周三"]
for week in weeks_list:
print(f"今天是{week}")
# 多个变量
date_list = [
["1月", "1号", "周一", "a"],
["2月", "2号", "周二", "a"],
["3月", "3号", "周三", "a"],
]
for month, date, _, _ in date_list:
print(f"今天是{month}---{date}")
# ["1月","1号","周一"],"a"
for *date_week, _ in date_list:
print(f"今天是{date_week}")
# "1月",["1号","周一"],"a"
for _, *date_week, _ in date_list:
print(f"今天是{date_week}")
# continue:立即结束本次循环,进入下一次循环
# break:终止循环
# for ... else ...
# 当for循环结束且不是因为break而终止时
# 才会执行else里的代码
num_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
for i in num_list:
if i % 2 == 0:
continue
print("这是偶数{i}")
elif i == 9:
print(f"遇到{i},结束循环")
break
else:
print(i)
else:
print("本次此处for循环正常执行完")
16、while循环
a = 0
while a < 5:
a += 1
print(a)
a = 0
while a < 5:
a += 1
if a == 2:
continue
elif a == 4:
break
else:
print(a)
else:
print("while循环正常执行结束")
while True:
print("无限循环")
17、if三元&推导式
"""
if的三元写法:
表达式1 if 条件 else 表达式2
条件为True则执行表达式1
条件为False则执行表达式2
"""
if len("test") > 5:
a = "长度大于5"
else:
a = "长度小于5"
a = "长度大于5" if len("test") > 5 else "长度小于5"
print(f"a = \"{a}\"")
"""
range(头,尾,步长)
1、顾头不顾尾,头默认为0,步长默认为1
2、python2.x 返回结果为列表
3、python3.x 返回结果为range对象,可使用for遍历
"""
num_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
num_range1 = range(10)
num_range2 = range(1, 11)
num_range3 = range(1, 11, 2)
num_range4 = range(2, 11, 2)
print(f"num_range1的数据类型{type(num_range1)}")
"""
列表、集合推导式
基本格式:
list = [表达式 for 变量名 in 序列 if 条件]
1) if条件,非必写项
2) 若写了if,只要满足if的条件参会执行表达式
3) 并且不能跟else
"""
a = []
for i in range(1, 11):
a.append(i)
print(f"正常for循环生成的整数列表\n{a}")
a = [i for i in range(1, 11)]
print(f"列表推导式生成的整数列表\n{a}")
o_list = [] # 求偶数列表
for i in range(1, 11):
if i % 2 == 0:
o_list.append(i)
print(f"正常for循环生成的偶数列表\n{o_list}")
o_list = [
i for i in range(1, 11) if i % 2 == 0
]
print(f"带if的推导式生成的偶数列表\n{o_list}")
o_list = [i for i in range(2, 11, 2)]
print(f"直接使用range步长和推导式生成的偶数列表\n{o_list}")
"""
字典推导式:
dict = {key: value for 变量名 in 序列 if 条件}
"""
tmp_list = [
("name", "a", "Kwan"),
("age", "b", 88)
]
tmp_dict = {}
for tmp_tuple in tmp_list:
tmp_dict[tmp_tuple[0]] = tmp_tuple[2]
print(f"正常for循环生成的字典:\n{tmp_dict}")
tmp_dict = {
tmp_tuple[0]: tmp_tuple[2] for tmp_tuple in tmp_tuple
}
print(f"字典推导式生成的字典:\n{tmp_dict}")
18、函数的作用&定义
"""
def 函数名(形式参数):
代码块
return 结果
1、形式参数:非必须
2、return:非必须,默认返回None
3、只要遇到return,函数调用就结束,立即返回结果
"""
# 空函数
def tmp1():
pass # 占行
def tmp2():
return # 返回值为None
def tmp3():
return None
def find_num(tmp_list):
res = []
for i in tmp_list:
if i.isdigit():
res.append(i)
return res
a = ["1", "2", "A", "3", "4", "f"]
res1 = find_num(a)
b = ["11", "21", "A1", "31", "41", "f1"]
res2 = find_num(b)
print(f"调用函数的执行结果\n{res1}")
print(f"调用函数的执行结果\n{res2}")
19、函数的参数
# 普通参数(必传参数)
def cal_num(num1, num2):
res = num1 ** 2 + num2
return res
# 按顺序传参
test1 = cal_num(3, 1) # 3的二次方加1
print(test1)
test2 = cal_num(1, 3) # 1的二次方加3
print(test2)
# 指定传参
test3 = cal_num(num2=1, num1=3)
# 默认参数必须放在普通参数后面
# def cal_num(num2=1,num1): 这样会报错
def cal_num_default(num1, num2=1):
res = num1 ** 2 + num2
return res
test4 = cal_num_default(3)
test5 = cal_num_default(3, 2)
test6 = cal_num_default(num2=2, num1=3)
# 不定长参数
def cal_sum(*rgs):
result = 0
for i in rgs:
result += i
return result
res1 = cal_sum(1, 2, 3)
res2 = cal_sum(1, 2, 3, 4, 5, 6, 7)
# 关键字参数
def cal_sum2(num, **kwargs):
result = num
for k, v in kwargs.items():
result += v
return result
# kwargs为字典{"num2":2,"num3":3}
res3 = cal_sum2(num2=2, num=1, num3=3)
# 命名关键字参数
def cal_sum3(num, *, num2, num3=3):
result = num + num2 + num3
return result
res4 = cal_sum3(num2=2, num=1)
res5 = cal_sum3(num2=2, num=1, num3=5)
"""
参数定义的顺序必须是:
普通参数、默认参数、不定长参数、命名关键字参数、关键字参数
def cal(num1,num2,*args,*,num3,num3,**kwargs):
"""
20、多个返回值
a = ["1", "2", "A", "3", "4", "f"]
def find_that1(tmp_list):
res1 = []
res2 = []
for i in tmp_list:
if i.isdigit():
res1.append(i)
elif i.isalpha():
res2.append(i)
return res1, res2
# return (res1, res2)
tmp_res = find_that1(a)
tmp_res1, tmp_res2 = find_that1(a)
# 返回值不一定是代码块的值,可以是其他的值
def find_that2(tmp_list):
res1 = []
res2 = []
for i in tmp_list:
if i.isdigit():
res1.append(i)
elif i.isalpha():
res2.append(i)
return res1, res2, 1, 2, 3
tmp_res1, tmp_res2, *tmp_res3 = find_that2(a)
print(f"{tmp_res1},{tmp_res2},{tmp_res3}")
# return 1 + 2 有确切结果返回值,没有就None
21、作用域
total = 0 # 全局变量
def plus(a, b):
# 这里的total局部变量
total = a + b
print(f"函数内部局部变量total={total}")
plus(1, 2)
print(f"函数外部全局变total={total}")
def plus2(a, b):
# 在函数内部使用函数外部的全局变量total
global total
total = a + b
print(f"函数内部局部变量total={total}")
plus2(1, 2)
print(f"函数外部全局变total={total}")
def plus3(a, b):
# 在函数内部使用函数外部的全局变量total
tmp_num = 10
res = a + b + tmp_num
print(f"函数内部局部变量total={res}")
# 不能在函数外部使用函数内部定义的变量
tmp_num = tmp_num + 10
22、匿名函数
"""
匿名函数:没有函数名
lambda 参数1,参数2...参数n : 表达式
"""
def plus1(num1, num2):
result = num1 + num2
return result
res1 = plus1(10, 11)
print("res1 = {}".format(res1))
plus2 = lambda x, y: x + y
res2 = plus2(10, 11)
print("res2 = {}".format(res2))
23、类的定义
"""
类(class):对具有相同属性(property)和方法(method)的对象(object)进行的抽象层
对象(object):通过类进行实例化得到
例:手机、平板、笔记本电脑...
都属于‘电子设备’这一类
都有的属性:尺寸、电量...
都有的方法:刷剧、打游戏...
"""
# 继承自object类
class Human(object):
# 初始化方法
def __init__(self, name, age=0):
self.name = name
self.age = age
self.ask = False
def run(self):
print("{}在跑步".format(self.name))
def sleep(self):
print("{}在睡觉".format(self.name))
# 实例化
human = Human(name="Kwan", age=88)
# 方法
human.run()
human.sleep()
# 属性
human_age = human.age
print(f"年龄是{human_age}")
24、魔术方法
class Human(object):
# 构造方法 返回结果为实例化的对象
def __new__(cls, *args, **kwargs):
print("触发构造方法 __new__")
return super().__new__(cls)
# 初始化方法 无返回值
def __init__(self, name, age=0):
print("触发初始化方法 __init__")
self.name = name
self.age = age
self.ask = False
# 删除方法(析构方法) 无返回值
# def 对象名 或 程序执行结束之后触发
def __del__(self):
print("触发删除方法 __def__")
# 调用方法 返回值自定
# 把对象当作函数调用时触发
def __call__(self, num):
print("触发调用方法 __call__")
print(f"传了一个{num}")
# 打印方法 返回值必须是一个字符串
# 使用print(对象)或者str(对象)的时候触发
def __str__(self):
print("触发打印方法 __str__")
return "打印了我"
def __len__(self):
print("触发长度方法 __len__")
return 100
# 实例化
human = Human(name="Kwan", age=88)
human(99)
print(human)
len_human = len(human)
print(len_human)
25、类的继承
"""
类的继承
1、子类会继承父类的所有属性和方法
2、一个类可以继承自多个类
3、子类可以重写父类中的方法和属性
4、当继承多个父类且父类中有相同方法,
就按照从左到右的先后顺序来决定使用哪个父类的方法
# 如A、B、C三个父类都有run(),那么class D(B,A,C)就会默认B中的run()
"""
class Human(object):
def __init__(self, name, age=0):
self.name = name
self.age = age
def run(self):
print("{}在跑步".format(self.name))
def work(self):
print("{}在搬砖".format(self.name))
def sleep(self):
print("{}在睡觉".format(self.name))
class Money(object):
def work(self):
print("钱钱在自己搬自己")
# class Worker(Human, Money):
# def sleep(self):
# print("{}岁的{}怎么睡的着啊".format(self.name, self.age))
class Worker(Money, Human):
def sleep(self):
print("{}岁的{}怎么睡的着啊".format(self.name, self.age))
worker = Worker(name="Kwan", age=88)
print(worker.name, worker.age)
worker.run()
worker.work()
worker.sleep()
26、静态方法和类方法
"""
静态方法:
1、在方法的上方使用装饰器 @staticmethod 即可
2、没有self参数,也没有cls参数
3、可以不经过实例化,直接使用
类方法:
1、在方法的上方使用装饰器 @classmethod 即可
2、有cls参数,代笔类本身
3、可以不经过实例化,直接使用
类方法:能访问类的属性,不能访问__init__中初始化的属性
静态方法:不能访问累的属性,不能访问__init__中初始化的属性
"""
class Human:
desc = "这是一个Human类"
def __init__(self, name="xxx", age="xxx"):
self.name = name
self.__age = age
@classmethod
def info(cls):
print(cls.desc)
@staticmethod
def eat():
print("吃饭")
Human.eat()
Human.info()
27、方法和函数
"""
1、函数和静态方法,都是函数类型(function)
2、实例方法和类方法,都是方法类型(method)
"""
def tmp():
pass
class Human:
desc = "这里一个Human类"
def __init__(self,name,age = 0):
self.name = name
self.__age = age
def run(self):
print("{}在跑步".format(self.name))
@classmethod
def info(cls):
print(cls.desc)
@staticmethod
def eat():
print("吃饭")
human = Human(name="Kwan",age=88)
print(f"实例方法run的类型为{type(human.run)}")
print(f"类方法info的类型为{type(human.info)}")
print(f"静态方法eat的类型为{type(human.eat)}")
print(f"函数tmp的类型为{type(tmp)}")
28、私有化
"""
私有属性和私有方法
1、以双下划线__开头
2、仅可在类的内部使用
"""
class Human:
desc = "这里一个Human类"
def __init__(self,name,age = 0):
self.name = name
self.__age = age
def __run(self):
print("{}在跑步".format(self.name))
def sleep(self):
self.__run()
print("{}岁的{}在睡觉".format(self.__age,self.name))
human = Human(name="Kwan",age=88)
human.sleep()
human.__run()
print(human.__age)
29、property装饰器
"""
在方法的上方添加@property
作用:将方法转为属性
"""
class Human:
desc = "这是一个Human类"
def __init__(self,height=1.7,weight=60):
self.height = height
self.weight = weight
@property
def bmi(self):
"""
BMI指数:体重(kg)/身高(m)的平方
"""
return self.weight / self.height ** 2
def eat(self):
print("吃饭")
human = Human(height=1.88,weight=80)
bmi_val = human.bmi # 可以想属性一样调用了
print(f"BMI = {bmi_val}")
human.eat()
30.1、异常捕获
"""
异常捕获
try:
执行代码
except 错误类型 as 别名:
发生异常时执行的代码
else:
没有异常时执行的代码
finally:
无论有没有异常都会执行的代码
try/except语句: else和finally可有可无
try/finally语句:else和except可有可无
"""
try:
a = 5
b = "y"
c = a / b
# except(ValueError,TypeError,NameError)
except Exception as e:
# 万能错误类型:Exception
print(f"出现异常:{e}")
except ValueError as v:
print(f"出现异常:{v}")
else:
print("没出现异常")
finally:
print("无论有没有异常都会执行")
30.2、抛出异常
"""
raise 错误类型(错误信息)
"""
a = 1 + 1
if a == 2:
raise Exception("主动抛出异常")
# 自定义错误类型
class SpecialError(Exception):
def __init__(self,msg):
self.msg = msg
def __str__(self):
return f"出现特殊异常:{self.msg}"
raise SpecialError("未知错误")
30.3、断言
"""
assert 表达式,异常信息
1、异常信息可有可无
2、表达式的结果一定要是布尔值,即True或者False
等价于:
if not 表达式:
raise AssertionError(异常信息)
"""
assert 1 != 1, "肯定错了,1当然等于1"
31、可变对象和不可变对象
"""
可变对象:list、set、dict
不可变对象:int、float、string、tuple
不可变:对象的内容是不能改变的,
但是变量的对象引用是可变的
"""
# 次数变量a ---> "hello"
a = "hello"
print(f"a = {a}")
# 等号右边运行结果为"hello world" 新创建的字符串
# 此时变量a --x--> "hello"
# a -----> "hello world"
# "hello"会被垃圾回收机制清理
a = a + "world"
print(f"a = {a}")
# 此时 b[2] ---> 列表内存地址
# 列表内存地址 ---> [4,5,6]
b = (1, 2, [4, 5, 6])
print(f"b = {b}")
# 此时 b[2] ---> 列表内存地址(没变)
# 列表内存地址 ---> [7,5,6]
b[2][0] = 7
print(f"b = {b}")
32、生成器
a = [i for i in range(3)] # 列表生成式
b = (i for i in range(3)) # 生成器
print(type(b))
def generator():
tmp = [i for i in range(1000000)]
index = 0
while index < len(tmp):
print(f"当前值:{tmp[index]}")
index = index + 1
yield tmp[index]
raise StopIteration
gen = generator()
print(type(gen))
# 也可以使用for循环不断地执行next(gen)
next(gen)
# 可以通过send方法触发next
gen.send(None)
33、可迭代对象&迭代器对象
"""
1、可迭代对象:实现了__iter__()或__getitem__()
iterable
2、迭代器对象:实现了__iter__()和__next___()
iterator
3、使用函数iter(iterable),即可获得迭代器对象
"""
class Array:
def __init__(self,init_list,index = 0):
self.init_list = init_list
self.index = index
def __iter__(self):
"""返回值必须为一个迭代器对象"""
return iter(self.init_list)
def __getitem__(self, i):
"""返回对应索引的元素"""
return self.init_list[i]
def __next__(self):
if self.index > len(self.init_list) - 1:
raise StopIteration
self.index += 1
return self.init_list[self.index]
# 实例化得到一个可迭代对象
tmp = Array([1,2,3])
# 转换为迭代器对象
# gen = tmp.__iter__()
gen = iter(tmp)
# 使用next往后取值,超出长度则抛出异常
print(next(gen))
print(next(gen))
print(next(gen))
print(next(gen))
34、装饰器
"""
装饰器的作用:在不改变原函数的情况下增加功能
"""
# 不带参数的函数装饰器
def decorator(func):
def run(*args, **kwargs):
print("运行原函数之前")
func()
print("运行原函数之后")
return run
@decorator
def start():
print("开始运行")
start()
# 带参数的函数装饰器
def who(name):
def decorator(func):
def run():
print(f"传入了{name}")
print("运行原函数之前")
func()
print("运行原函数之后")
return run
return decorator
@who(name=921)
def start():
print("开始运行")
start()
# 不带参数的类装饰器
class decorator:
def __init__(self,func):
self.func = func
def __call__(self, *args, **kwargs):
print("运行原函数之前")
self.func(*args,**kwargs)
print("运行原函数之后")
@decorator
def start():
print("开始运行")
start()
# 带参数的类装饰器
class decorator:
def __init__(self,name):
self.name = name
def __call__(self, func):
def inner(*args,**kwargs):
print(self.name)
print("运行原函数之前")
func(*args,**kwargs)
print("运行原函数之后")
return inner
@decorator(name = "921")
def start():
print("开始运行")
start()
35、包和模块
"""
1、package(包):
一个包就是一个文件夹
只不过文件夹里面有一个__init__.py文件
2、module(模块):
一个模块就是一个.py文件
3、第三方模块:
官网:https://pypi.org/
终端命令:
安装 pip install XXX,XXX
pip3 install XXX,XXX
卸载 pip uninstall XXX,XXX
查看 pip list
第一次用记得改源
模块导入
import time
from time import time_ns
"""
"""
1.py
def plus(x,y):
return x + y
2.py
from 1 import plus
A = 1
B = 2
print(plus(A,B))
# 不能互相导入
"""
36、with
"""
with:上下文管理
"""
# 获取一个文件对象
fp = open("./test.txt","r")
res1 = fp.read()
print(f"读取结果:\n{res1}")
# 文件对象使用完毕后一点要关闭
fp.close()
with open("./text.txt","r") as fp:
res1 = fp.read()
print(f"读取结果:\n{res1}")
原文链接:https://www.cnblogs.com/lightwower/p/17382348.html
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:python快速直白入门(半新手向,老手复习向) - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 