原创:扣钉日记(微信公众号ID:codelogs),欢迎分享,非公众号转载保留此声明。
在之前的OOM问题复盘中,我们添加了jmap脚本来自动dump内存现场,方便排查OOM问题。
但当我反复模拟OOM场景测试时,发现jmap有时可以dump成功,有时会报错,如下:

经过网上一顿搜索,发现两种原因可能导致这个问题,一是执行jmap用户与jvm进程用户不一致,二是/tmp/.java_pidXXX文件被删除,但经过检查,这都不是我们jmap失败的原因。
经过了解,jmap导出内存的原理,大致如下: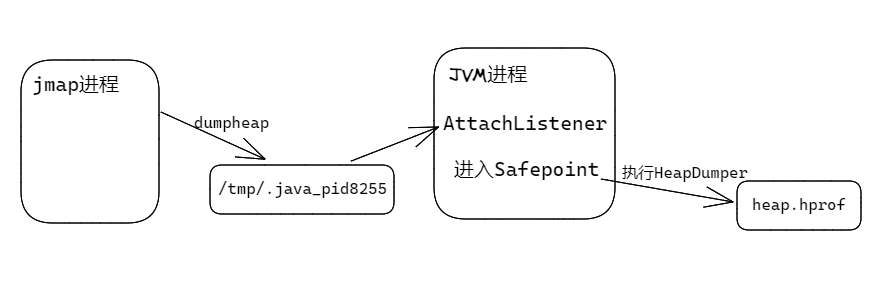
- 如果jvm进程id是8255,jmap会先创建一个
/tmp/.java_pid8255文件,然后发送SIGQUIT信号给jvm。 - jvm收到信号后启动AttachListener线程,以UNIX domain socket的形式监听
/tmp/.java_pid8255文件,以接收命令。 - jmap也以UNIX domain socket的形式连接上
/tmp/.java_pid8255文件,并发送dumpheap命令给jvm,这个过程中jvm会检查命令发送方用户的euid/egid是否与自己一致。 - AttachListener线程收到dumpheap命令后,等到JVM进入Safepoint后,执行HeapDumper操作以导出heap.hprof文件。
可以看出,当jvm已经卡死,或有长时间的GC正在Safepoint中执行,都会导致jmap长时间读不到命令的响应而超时失败!
使用jmap -F
当给jmap添加-F参数时,jmap会使用Linux的ptrace机制来导出堆内存,ptrace是Linux平台的一种调试机制,像strace、gdb都是基于它开发的,它使得调试进程(jmap)可以直接读取被调试进程(jvm)的原生内存,然后jmap再根据jvm的内存布局规范,将原生内存转换为hprof格式。
但在实际执行时,会发现jmap -F执行得非常慢,可能要几个小时,这是因为ptrace每次只能读一个字的内存,而我们的堆有10G,因此jmap -F对于我们几乎无法使用。
注:这里说的原生程序,指的是类似于C/C++这种直接编译出来、不需要依赖语言虚拟机的程序,而原生内存,指的是通过malloc或mmap等直接申请出来的内存。
使用gcore
有过Linux下原生程序调试经验的,应该会知道gcore这个实用工具,它可用来生成程序原生内存的core文件,然后jstack、jmap等都可以读取此类文件,如下:
# 生成core文件,8787是进程号
$ gcore -o core 8787
Saved corefile core.8787
[Inferior 1 (process 8787) detached]
$ ll -lh core.8787
-rw-r--r-- 1 work work 5.8G 2023-04-16 11:40:00 core.8787
# 从core文件中读取线程栈
$ jstack `which java` core.8787
# 将core文件转换为hprof文件,很慢,建议摘流量后执行
$ jmap -dump:format=b,file=heap.hprof `which java` core.8787
但是当我使用jmap转换core文件时,我发现我本机测试时可以成功,但在测试服务器上却一直报错,如下:
我网上找了好久,都没找到报此错误的原因...
但我发现gcore执行时,是有一些警告信息的,如下: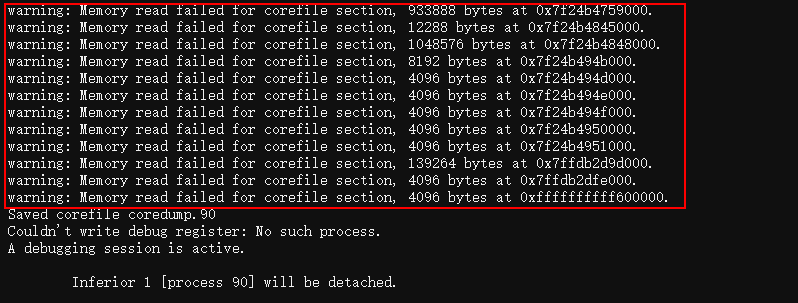
看起来可能是gcore导出的core文件不全,联想到jvm部署在容器中,怀疑是有某些权限限制,导致部分程序内存导出失败了。
使用Linux内核的coredump机制
除了gcore可以导原生内存,其实Linux内核也有自动的coredump机制,即进程在收到某些信号后,会自动触发内核的coredump机制,内核会负责将进程的原生内存保存为core文件,而内核一般是最高权限运行的,所以它生成的core文件应该是完整的。
先开启coredump机制,如下:
# 检查是否开启,输出unlimited表示core文件不受限制,即完全开启
$ ulimit -c
# 临时开启coredump
$ ulimit -c unlimited
# 永久开启
$ echo "ulimit -c unlimited" >> /etc/profile
然后,配置一下coredump文件保存位置,如下:
# 查看当前配置
$ cat /proc/sys/kernel/core_pattern
/home/core/core.%e.%p.%t
# 配置coredump文件保存位置,并使其生效
$ vi /etc/sysctl.conf
kernel.core_pattern=/home/core/core.%e.%p.%t
$ sysctl –p /etc/sysctl.conf
core_pattern占位符解释
| 占位符 | 解释 |
|---|---|
| %p | pid |
| %u | uid |
| %g | gid |
| %s | signal number |
| %t | UNIX time of dump |
| %h | hostname |
| %e | executable filename |
注:如果没有权限修改core_pattern路径,可考虑使用软链接
ln -s做路径跳转,当然,还需要保证coredump路径有写入权限。
配置ok后,可通过kill发送信号来触发内核coredump,可触发coredump的常见信号如下:
- SIGQUIT 数值2 从键盘输入
Ctrl+'\'可以产生此信号 - SIGILL 数值4 非法指令
- SIGABRT 数值6 abort调用
- SIGSEGV 数值11 非法内存访问
- SIGTRAP 数值5 调试程序时使用的断点
我选择了SIGABRT信号,即kill -6,经过验证,可生成core文件,而且core文件也能被jmap转换为hprof文件。
有了hprof文件,就可以愉快地使用MAT、JVisualVM、JMC等工具进行内存分析啦?
原文链接:https://www.cnblogs.com/codelogs/p/17323197.html
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:jmap执行失败了,怎么获取heapdump? - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 