操作系统:Windows 10_x64
python版本:Python 3.9.2_x64
pyttsx3版本: 2.90
pyttsx3是一个tts引擎包装器,可对接SAPI5、NSSS(NSSpeechSynthesizer)、espeak等引擎,实现统一的tts接口。

pyttsx3的地址:https://pypi.org/project/pyttsx3/
帮助文档地址:https://pyttsx3.readthedocs.org/
安装pyttsx3依赖包:
pip install pyttsx3
接口介绍
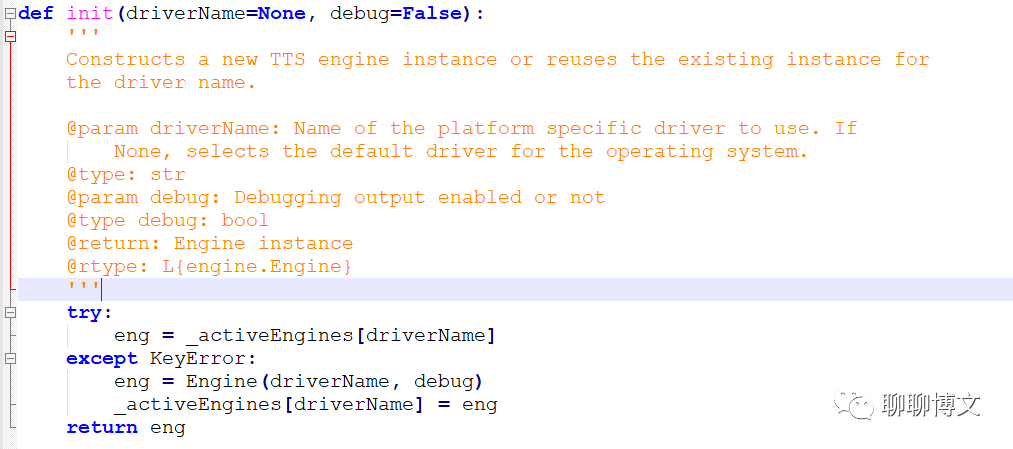
1、init接口
使用的具体引擎可以在init里面指定:
pyttsx3.init([driverName : string, debug : bool]) → pyttsx3.Engine
入参:
driverName : 可选,用于指定tts引擎,若未指定,则使用系统默认引擎。
- sapi5 - windows环境
- nsss - Mac OS X环境
- espeak - 非windows和Mac OS X 的其它系统
debug : 可选,用于指定是否开启调试功能,若未指定,则不开启。
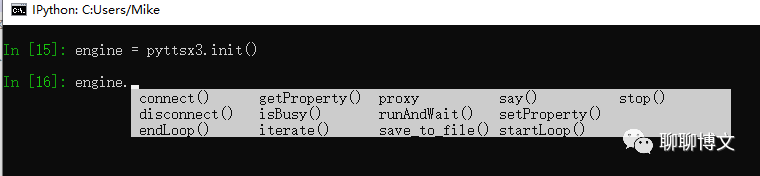
2、engine接口
使用init接口初始完毕,会返回engine对象。
engine对象的方法如下:
- connect
注册回调函数用于订阅事件。
入参及出参
connect(topic : string, cb : callable) → dict
topic :订阅事件的名称,有效的名称
cb : 回调函数
返回token信息,可用于后续取消订阅。
可用事件如下:
started-utterance
引擎开始说话时触发,回调函数定义如下:
onStartUtterance(name : string) -> None
started-word
引擎说词语时触发,回调函数定义如下:
onStartWord(name : string, location : integer, length : integer) -> None
finished-utterance
引擎说话结束时触发,回调函数定义如下:
onFinishUtterance(name : string, completed : bool) -> None
error
引擎遇到错误时触发,回调函数定义如下:
onError(name : string, exception : Exception) -> None
- disconnect
反注册回调函数。
disconnect(token : dict)
token是connect函数返回的数据。
- endLoop
结束正在运行的事件循环。
- getProperty
获取tts的属性,比如语速、嗓音、音量等。
getProperty(name : string) -> object
参数:
name - 属性名称
object - 属性对象
属性列表:
rate - 语速
voice - 嗓音
voices - 嗓音集,列出 pyttsx3.voice.Voice 里面定义的所有嗓音
volume - 音量
- isBusy
判断当前引擎是否在执行文本转语音。
isBusy() -> bool
返回值:
True - 正在执行文本转语音
False - 未执行
- iterate
当使用外部事件循环时,该方法需要被调用。
- runAndWait
runAndWait() -> None
执行缓存的命令并等待完成。
- save_to_file
执行语音转文本操作,并生成音频文件。
save_to_file(text : unicode, filename : string, name : string)
参数:
text - 要执行转语音的文本
filename - 文件名称
name - 可选,注册需要通知的关键字
示例:
engine.save_to_file('Hello World' , 'test.mp3')
- say
执行语音转文本操作,并播放文本内容。
say(text : unicode, name : string) -> None
参数:
text - 要执行转语音的文本
name - 可选,注册需要通知的关键字
示例:
engine.say('I will speak this text!', 'speak')
- setProperty
设置tts的属性,比如语速、嗓音、音量等。
setProperty(name, value) -> None
参数:
name - 属性名称
value - 属性值
属性列表:
rate - 语速,设置每分钟说几个字
voice - 嗓音,可以设置不同嗓音的说话人
volume - 音量,介于0到1的小数
- startLoop
开始事件循环。
startLoop([useDriverLoop : bool]) -> None
- stop
停止当前正在运行的文本转语音并清理命令队列。
使用示例
1、使用pyttsx3播放语音及生成文件
简单示例:
#! /usr/bin/env python3 #-*- coding:utf-8 -*- # pip install pyttsx3 import pyttsx3 def onStart(name): print('starting',name) def onWord(name,location,length): print('word',name,location,length) def onEnd(name,completed): print('finishing',name,completed) engine = pyttsx3.init() # 注册回调函数 engine.connect('started-utterance', onStart) engine.connect('started-word', onWord) engine.connect('finished-utterance', onEnd) # 语音转文本测试(直接播放) engine.say("I will speak this text") engine.say('I will speak this text!', 'speak') # 注册 speak 关键字,进行事件通知 engine.say("我可以说话了") # 语音转文本测试(文件存储到磁盘) engine.save_to_file('我可以说话了', 'test.mp3') # 运行并等待 engine.runAndWait()
运行效果如下:
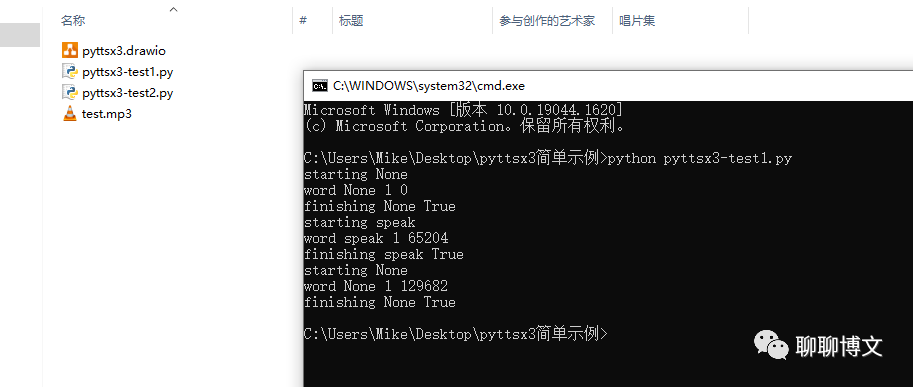
2、使用pyttsx3搭建简单的tts服务
这里使用tornado搭建简单的http服务(tornado是一个开源的网络服务器框架),来实现tts服务。
时序如下:
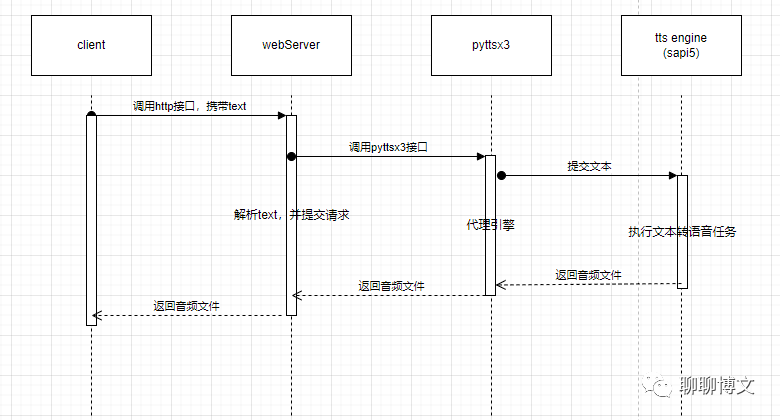
主逻辑代码如下:
def text2File(text,dstFile): engine = pyttsx3.init() engine.save_to_file(text,dstFile) engine.runAndWait() class MainHandler(tornado.web.RequestHandler): def get(self): tmpFile = "1.mp3" print("get",self.request.arguments) text = self.get_query_argument("text").strip() print("text : %s" % text) if len(text) > 0 : text2File(text,tmpFile) self.set_header('content-type', 'audio/mpeg') fbin = open(tmpFile,"rb").read() self.set_header('Content-Length', len(fbin)) self.set_header('Content-Disposition', 'attachment;filename="%s"'%tmpFile) self.write(fbin) self.finish() else: self.set_header('content-type', 'application/json') self.finish(json.dumps({"result" : "input text "})) def post(self): print("post") print(self.request.arguments)
运行效果如下:
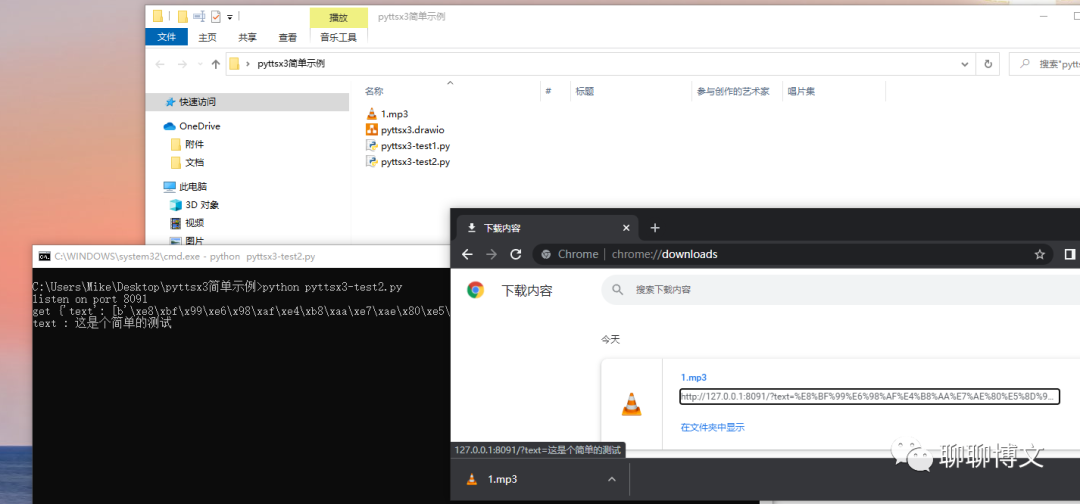
可关注微信公众号(聊聊博文)后回复 2022040401 获得提取码。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:使用pyttsx3实现简单tts服务 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 