论文pdf 地址:https://arxiv.org/pdf/1609.04802v1.pdf
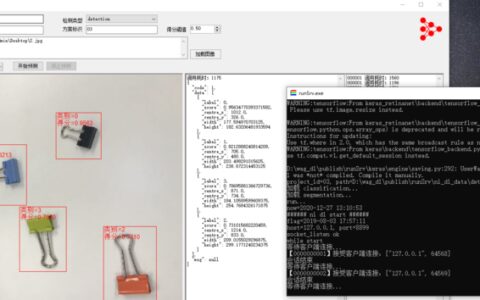
我的实际效果
清晰度距离我的期待有距离。
颜色上面存在差距。
解决想法
增加一个颜色判别器。将颜色值反馈给生成器
——SRGAN超高分辨率图片重构")
srgan论文是建立在gan基础上的,利用gan生成式对抗网络,将图片重构为高清分辨率的图片。
github上有开源的srgan项目。由于开源者,开发时考虑的问题更丰富,技巧更为高明,导致其代码都比较难以阅读和理解。
在为了充分理解这个论文。这里结合论文,开源代码,和自己的理解重新写了个srgan高清分辨率模型。
GAN原理
在一个不断提高判断能力的判断器的持续反馈下,不断改善生成器的生成参数,直到生成器生成的结果能够通过判断器的判断。(见本博客其他文章)
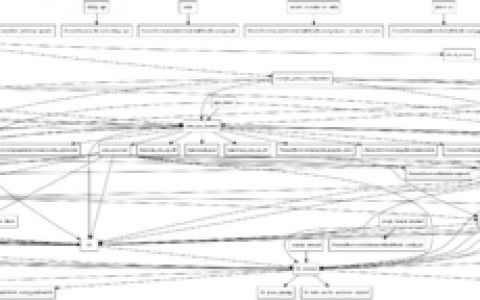
SRGAN用到的模块,及其关系
损失值,根据的这个关系结构计算的。——SRGAN超高分辨率图片重构")
注意:vgg19是使用已经训练好的模型,这里只是拿来提取特征使用,
对于生成器,根据三个运算结果数据,进行随机梯度的优化调整
①判定器生成数据的鉴定结果
②vgg19的特征比较情况
③生成图形与理想图形的mse差距
论文中,生成器和判别器的模型图
——SRGAN超高分辨率图片重构")
生成器结构为:一层卷积,16层残差卷积,再将第一层卷积结果+16层残差结,卷积+2倍反卷积,卷积+2倍反卷积,tanh缩放,产生生成结果。
判别器结构为:8层卷积+reshape,全连接。(论文中,用了两层。我这里只用了一层全连接,参数量太大,我6G 的gpu内存不够用)
vgg19结构:在vgg19的第四层,返回获取到的特征结果,进行MSE对比
注意:BN处理,leaky relu等等处理技巧
代码解释
import numpy as np
import os
import tensorlayer as tl
import tensorflow as tf
#获取vgg9.npy中vgg19的参数,
vgg19_npy_path = "./vgg19.npy"
if not os.path.isfile(vgg19_npy_path):
print("Please download vgg19.npz from : https://github.com/machrisaa/tensorflow-vgg")
exit()
npz = np.load(vgg19_npy_path, encoding='latin1').item()
w_params = []
b_params = []
for val in sorted(npz.items()):
W = np.asarray(val[1][0])
b = np.asarray(val[1][1])
# print(" Loading %s: %s, %s" % (val[0], W.shape, b.shape))
w_params.append(W, )
b_params.extend(b)
#tensorlayer加载图片时,用于处理图片。随机获取图片中 192*192的矩阵, 内存不足时,可以优化这里
def crop_sub_imgs_fn(x, is_random=True):
x = tl.prepro.crop(x, wrg=192, hrg=192, is_random=is_random)
x = x / (255. / 2.)
x = x - 1.
return x
#resize矩阵 内存不足时,可以优化这里
def downsample_fn(x):
x = tl.prepro.imresize(x, size=[48, 48], interp='bicubic', mode=None)
x = x / (255. / 2.)
x = x - 1.
return x
# 参数
config = {
"epoch": 5,
}
# 内存不够时,可以减小这个
batch_size = 10
class SRGAN(object):
def __init__(self):
# with tf.device('/gpu:0'):
#占位变量,存储需要重构的图片
self.x = tf.placeholder(tf.float32, shape=[batch_size, 48, 48, 3], name='train_bechanged')
#占位变量,存储需要学习的理想中的图片
self.y = tf.placeholder(tf.float32, shape=[batch_size, 192, 192, 3], name='train_target')
self.init_fake_y = self.generator(self.x) # 预训练时生成的假照片
self.fake_y = self.generator(self.x, reuse=True) # 全部训练时生成的假照片
#占位变量,存储需要重构的测试图片
self.test_x = tf.placeholder(tf.float32, shape=[1, None, None, 3], name='test_generator')
#占位变量,存储重构后的测试图片
self.test_fake_y = self.generator(self.test_x, reuse=True) # 生成的假照片
#占位变量,将生成图片resize
self.fake_y_vgg = tf.image.resize_images(
self.fake_y, size=[224, 224], method=0,
align_corners=False)
#占位变量,将理想图片resize
self.real_y_vgg = tf.image.resize_images(
self.y, size=[224, 224], method=0,
align_corners=False)
#提取伪造图片的特征
self.fake_y_feature = self.vgg19(self.fake_y_vgg) # 假照片的特征值
#提取理想图片的特征
self.real_y_feature = self.vgg19(self.real_y_vgg, reuse=True) # 真照片的特征值
# self.pre_dis_logits = self.discriminator(self.fake_y) # 判别器生成的预测照片的判别值
self.fake_dis_logits = self.discriminator(self.fake_y, reuse=False) # 判别器生成的假照片的判别值
self.real_dis_logits = self.discriminator(self.y, reuse=True) # 判别器生成的假照片的判别值
# 预训练时,判别器的优化根据值
self.init_mse_loss = tf.losses.mean_squared_error(self.init_fake_y, self.y)
# 关于判别器的优化根据值
self.D_loos = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=self.real_dis_logits,
labels=tf.ones_like(
self.real_dis_logits))) +
tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=self.fake_dis_logits,
labels=tf.zeros_like(
self.fake_dis_logits)))
# 伪造数据判别器的判断情况,生成与目标图像的差距,生成特征与理想特征的差距
self.D_loos_Ge = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=self.fake_dis_logits, labels=tf.ones_like( self.fake_dis_logits)))
self.mse_loss = tf.losses.mean_squared_error(self.fake_y, self.y)
self.loss_vgg = tf.losses.mean_squared_error(self.fake_y_feature, self.real_y_feature)
#生成器的优化根据值,上面三个值的和
self.G_loos = 1e-3 * self.D_loos_Ge + 2e-6 * self.loss_vgg + self.mse_loss
#获取具体条件下的更新变量集合。
t_vars = tf.trainable_variables()
self.g_vars = [var for var in t_vars if var.name.startswith('trainGenerator')]
self.d_vars = [var for var in t_vars if var.name.startswith('discriminator')]
# 生成器,16层深度残差+1层初始的深度残差+2次2倍反卷积+1个卷积
def generator(slef, input, reuse=False):
with tf.variable_scope('trainGenerator') as scope:
if reuse:
scope.reuse_variables()
n = tf.layers.conv2d(input, 64, 3, strides=1, padding='SAME', activation=None, use_bias=True,
bias_initializer=None)
prellu_param = tf.get_variable('p_alpha', n.get_shape()[-1], initializer=tf.constant_initializer(0.0),
dtype=tf.float32)
n = tf.nn.relu(n) + prellu_param * (n - abs(n)) * 0.02
# n = tf.nn.relu(n)
temp = n
# 开始深度残差网络
for i in range(16):
nn = tf.layers.conv2d(n, 64, 3, strides=1, padding='SAME', activation=None, use_bias=True,
bias_initializer=None)
nn = tf.layers.batch_normalization(nn, training=True)
prellu_param = tf.get_variable('p_alpha' + str(2 * i + 1), n.get_shape()[-1],
initializer=tf.constant_initializer(0.0),
dtype=tf.float32)
nn = tf.nn.relu(nn) + prellu_param * (nn - abs(nn)) * 0.02
nn = tf.layers.conv2d(nn, 64, 3, strides=1, padding='SAME', activation=None, use_bias=True,
bias_initializer=None)
nn = tf.layers.batch_normalization(nn, training=True)
# prellu_param = tf.get_variable('p_alpha' + str(2 * i + 2), n.get_shape()[-1],
# initializer=tf.constant_initializer(0.0),
# dtype=tf.float32)
# nn = tf.nn.relu(nn) + prellu_param * (nn - abs(nn)) * 0.02
n = nn + n
n = tf.layers.conv2d(n, 64, 3, strides=1, padding='SAME', activation=None, use_bias=True,
bias_initializer=None)
n = tf.layers.batch_normalization(n, training=True)
# prellu_param = tf.get_variable('p_alpha_34', n.get_shape()[-1],
# initializer=tf.constant_initializer(0.0),
# dtype=tf.float32)
# n = tf.nn.relu(n) + prellu_param * (n - abs(n)) * 0.02
#注意这里的temp,看论文里面的生成器结构图
n = temp + n
# 将特征还原为图
n = tf.layers.conv2d_transpose(n, 256, 3, strides=2, padding='SAME', activation=None, use_bias=True,
bias_initializer=None)
n = tf.layers.conv2d(n, 256, 3, strides=1, padding='SAME', activation=None, use_bias=True,
bias_initializer=None)
n = tf.layers.batch_normalization(n, training=True)
n = tf.nn.relu(n)
n = tf.layers.conv2d_transpose(n, 256, 3, strides=2, padding='SAME', activation=None, use_bias=True,
bias_initializer=None)
n = tf.layers.conv2d(n, 256, 3, strides=1, padding='SAME', activation=None, use_bias=True,
bias_initializer=None)
n = tf.layers.batch_normalization(n, training=True)
n = tf.nn.relu(n)
n = tf.layers.conv2d(n, 3, 1, strides=1, padding='SAME', activation=None, use_bias=True,
bias_initializer=None)
n = tf.nn.tanh(n)
return n
#判别器
def discriminator(self, input, reuse=False):
# input size: 384x384
with tf.variable_scope('discriminator') as scope:
if reuse:
scope.reuse_variables()
# 1
n = tf.layers.conv2d(input, 64, 3, strides=1, padding='SAME', activation=None, use_bias=True,
bias_initializer=None)
n = tf.maximum(0.01 * n, n)
# 2
n = tf.layers.conv2d(n, 64, 3, strides=2, padding='SAME', activation=None, use_bias=True,
bias_initializer=None)
n = tf.layers.batch_normalization(n, training=True)
n = tf.maximum(0.01 * n, n)
# 3
n = tf.layers.conv2d(n, 128, 3, strides=1, padding='SAME', activation=None, use_bias=True,
bias_initializer=None)
n = tf.layers.batch_normalization(n, training=True)
n = tf.maximum(0.01 * n, n)
# 4
n = tf.layers.conv2d(n, 128, 3, strides=2, padding='SAME', activation=None, use_bias=True,
bias_initializer=None)
n = tf.layers.batch_normalization(n, training=True)
n = tf.maximum(0.01 * n, n)
# 5
n = tf.layers.conv2d(n, 256, 3, strides=1, padding='SAME', activation=None, use_bias=True,
bias_initializer=None)
n = tf.layers.batch_normalization(n, training=True)
n = tf.maximum(0.01 * n, n)
# 6
n = tf.layers.conv2d(n, 256, 3, strides=2, padding='SAME', activation=None, use_bias=True,
bias_initializer=None)
n = tf.layers.batch_normalization(n, training=True)
n = tf.maximum(0.01 * n, n)
# 7
n = tf.layers.conv2d(n, 512, 3, strides=1, padding='SAME', activation=None, use_bias=True,
bias_initializer=None)
n = tf.layers.batch_normalization(n, training=True)
n = tf.maximum(0.01 * n, n)
# 8
n = tf.layers.conv2d(n, 512, 3, strides=2, padding='SAME', activation=None, use_bias=True,
bias_initializer=None)
n = tf.layers.batch_normalization(n, training=True)
n = tf.maximum(0.01 * n, n)
flatten = tf.reshape(n, (input.get_shape()[0], -1))
# 内存不够,减小全链接数量
# f = tf.layers.dense(flatten, 1024)
# 论文里面这里时leaky relu,这我用的dense里面自带的
f = tf.layers.dense(flatten, 1, bias_initializer=tf.contrib.layers.xavier_initializer())
return f
#vgg19特征提取
def vgg19(self, input, reuse=False):
VGG_MEAN = [103.939, 116.779, 123.68]
with tf.variable_scope('vgg19') as scope:
# if reuse:
# scope.reuse_variables()
# ====================
print("build model started")
rgb_scaled = (input + 1) * (255.0 / 2)
# Convert RGB to BGR
red, green, blue = tf.split(rgb_scaled, 3, 3)
assert red.get_shape().as_list()[1:] == [224, 224, 1]
assert green.get_shape().as_list()[1:] == [224, 224, 1]
assert blue.get_shape().as_list()[1:] == [224, 224, 1]
bgr = tf.concat(
[
blue - VGG_MEAN[0],
green - VGG_MEAN[1],
red - VGG_MEAN[2],
], axis=3)
assert bgr.get_shape().as_list()[1:] == [224, 224, 3]
# --------------------
n = tf.nn.conv2d(bgr, w_params[0], name='conv2_1', strides=(1, 1, 1, 1), padding='SAME')
n = tf.add(n, b_params[0])
n = tf.nn.relu(n)
n = tf.nn.conv2d(n, w_params[1], name='conv2_2', strides=(1, 1, 1, 1), padding='SAME')
n = tf.add(n, b_params[1])
n = tf.nn.relu(n)
n = tf.nn.max_pool(n, ksize=(1, 2, 2, 1), strides=(1, 2, 2, 1), padding='SAME')
# return n
# two
n = tf.nn.conv2d(n, w_params[2], strides=(1, 1, 1, 1), padding='SAME')
n = tf.add(n, b_params[2])
n = tf.nn.relu(n)
n = tf.nn.conv2d(n, w_params[3], strides=(1, 1, 1, 1), padding='SAME')
n = tf.add(n, b_params[3])
n = tf.nn.relu(n)
n = tf.nn.max_pool(n, ksize=(1, 2, 2, 1), strides=(1, 2, 2, 1), padding='SAME')
# three
n = tf.nn.conv2d(n, w_params[4], strides=(1, 1, 1, 1), padding='SAME')
n = tf.add(n, b_params[4])
n = tf.nn.relu(n)
n = tf.nn.conv2d(n, w_params[5], strides=(1, 1, 1, 1), padding='SAME')
n = tf.add(n, b_params[5])
n = tf.nn.relu(n)
n = tf.nn.conv2d(n, w_params[6], strides=(1, 1, 1, 1), padding='SAME')
n = tf.add(n, b_params[6])
n = tf.nn.relu(n)
n = tf.nn.conv2d(n, w_params[7], strides=(1, 1, 1, 1), padding='SAME')
n = tf.add(n, b_params[7])
n = tf.nn.relu(n)
n = tf.nn.max_pool(n, ksize=(1, 2, 2, 1), strides=(1, 2, 2, 1), padding='SAME')
# four
n = tf.nn.conv2d(n, w_params[8], strides=(1, 1, 1, 1), padding='SAME')
n = tf.add(n, b_params[8])
n = tf.nn.relu(n)
n = tf.nn.conv2d(n, w_params[9], strides=(1, 1, 1, 1), padding='SAME')
n = tf.add(n, b_params[9])
n = tf.nn.relu(n)
n = tf.nn.conv2d(n, w_params[10], strides=(1, 1, 1, 1), padding='SAME')
n = tf.add(n, b_params[10])
n = tf.nn.relu(n)
n = tf.nn.conv2d(n, w_params[11], strides=(1, 1, 1, 1), padding='SAME')
n = tf.add(n, b_params[11])
n = tf.nn.relu(n)
n = tf.nn.max_pool(n, ksize=(1, 2, 2, 1), strides=(1, 2, 2, 1), padding='SAME')
return n
# # five
# n = tf.nn.conv2d(n, w_params[12], strides=(1, 1, 1, 1), padding='SAME')
# n = tf.add(n, b_params[12])
# n = tf.nn.relu(n)
# n = tf.nn.conv2d(n, w_params[13], strides=(1, 1, 1, 1), padding='SAME')
# n = tf.add(n, b_params[13])
# n = tf.nn.relu(n)
#
# n = tf.nn.conv2d(n, w_params[14], strides=(1, 1, 1, 1), padding='SAME')
# n = tf.add(n, b_params[14])
# n = tf.nn.relu(n)
# n = tf.nn.conv2d(n, w_params[15], strides=(1, 1, 1, 1), padding='SAME')
# n = tf.add(n, b_params[15])
# n = tf.nn.relu(n)
# n = tf.nn.max_pool(n, ksize=(1, 2, 2, 1), strides=(1, 2, 2, 1), padding='SAME')
# return n
# 这里拿特征进行mse对比,不需要后面的全连接
# flatten = tf.reshape(n, (input.get_shape()[0], -1))
# f = tf.layers.dense(flatten, 4096)
# f = tf.layers.dense(f, 4096)
# f = tf.layers.dense(f, 1)
# return n
gan = SRGAN()
G_OPTIM_init = tf.train.AdamOptimizer(learning_rate=0.001, beta1=0.4).minimize(gan.init_mse_loss, var_list=gan.g_vars)
D_OPTIM = tf.train.AdamOptimizer(learning_rate=0.001, beta1=0.4).minimize(gan.D_loos, var_list=gan.d_vars)
G_OPTIM = tf.train.AdamOptimizer(learning_rate=0.001, beta1=0.4).minimize(gan.G_loos, var_list=gan.g_vars)
saver = tf.train.Saver(max_to_keep=3)
init = tf.global_variables_initializer()
#加载路径文件夹中的训练图片,这里加载的只是图片目录。防止内存中加载太多图片,内存不够
train_hr_img_list = sorted(tl.files.load_file_list(path='F:\theRoleOfCOde深度学习SRGAN_PFgaoqing', regx='.*.png', printable=False))[:100]
#加载图片
train_hr_imgs = tl.vis.read_images(train_hr_img_list, path='F:\theRoleOfCOde深度学习SRGAN_PFgaoqing', n_threads=1)
#加载路径文件夹中的测试图片目录
test_img_list = sorted( tl.files.load_file_list(path='F:\theRoleOfCOde深度学习SRGAN_PFSRGAN_PFimg\test', regx='.*.png', printable=False))[ :6]
test_img = tl.vis.read_images(test_img_list, path='F:\theRoleOfCOde深度学习SRGAN_PFSRGAN_PFimg\test', n_threads=1)
#分三种运行方式,
#pre,预训练判别器
#restore,回复训练好的模型,继续训练
#训练一会儿,就测试一下效果。将生成的图片矩阵,保存为numpy矩阵
#通过工具函数,变化为图片查看
#第三种,从零开始训练
with tf.Session() as sess:
type = 'go'
if type == 'restore':
saver.restore(sess, "./save/nets/ckpt-0-80")
print('---------------------恢复以前的训练数据,继续训练-----------------------')
for epoch in range(0):
for idx in range(0, (len(train_hr_imgs) // 10), batch_size):
# print(type(train_hr_imgs[idx:idx + batch_size]))
b_imgs_384 = tl.prepro.threading_data(train_hr_imgs[idx:idx + batch_size], fn=crop_sub_imgs_fn,
is_random=True)
b_imgs_96 = tl.prepro.threading_data(b_imgs_384, fn=downsample_fn)
print('-------------pre_generator:' + str(epoch) + '_' + str(idx) + '----------------')
for i in range(40):
init_mse_loss, _ = sess.run([gan.init_mse_loss, G_OPTIM_init],
feed_dict={
gan.x: b_imgs_96,
gan.y: b_imgs_384
})
print('init_mse_loss:' + str(init_mse_loss))
saver.save(sess, "save/nets/better_ge.ckpt")
for epoch in range(config["epoch"]):
for idx in range(0, len(train_hr_imgs), batch_size):
# print(type(train_hr_imgs[idx:idx + batch_size]))
b_imgs_384 = tl.prepro.threading_data(train_hr_imgs[idx:idx + batch_size], fn=crop_sub_imgs_fn,
is_random=True)
b_imgs_96 = tl.prepro.threading_data(b_imgs_384, fn=downsample_fn)
print('-------------' + str(epoch) + '_' + str(idx) + '----------')
for i in range(25):
loss_D, _ = sess.run([gan.D_loos, D_OPTIM],
feed_dict={
gan.x: b_imgs_96,
gan.y: b_imgs_384
})
loss_G, _ = sess.run([gan.G_loos, G_OPTIM],
feed_dict={
gan.x: b_imgs_96,
gan.y: b_imgs_384
})
print(loss_D, loss_G)
if idx % 20 == 0:
saver.save(sess, "./save/nets/better_all_" + str(epoch) + "_" + str(idx) + '.ckpt')
_imgs = (np.asanyarray(test_img[0:1]) / (255. / 2.)) - 1
_imgs = _imgs[:, :, :, 0:3]
result_fake_y = sess.run([gan.test_fake_y], feed_dict={
gan.test_x: _imgs
}) # 生成的假照片
# result=sess.run(result_fake_y)
strpath = './preImg/result_' + str(epoch) + '_' + str(idx) + '_1.npy'
np.save(strpath, result_fake_y)
_imgs2 = (np.asanyarray(test_img[1:2]) / (255. / 2.)) - 1
_imgs2 = _imgs2[:, :, :, 0:3]
result_fake_y = sess.run([gan.test_fake_y], feed_dict={
gan.test_x: _imgs2
}) # 生成的假照片
# result=sess.run(result_fake_y)
strpath = './preImg/result_' + str(epoch) + '_' + str(idx) + '_2.npy'
np.save(strpath, result_fake_y)
# print(type(result_fake_y))
elif type == 'pre':
saver.restore(sess, "save/nets/better_all_1_28.ckpt")
print('---------------------恢复训练好的模型,开始预测-----------------------')
for num in range(6):
_imgs = (np.asanyarray(test_img[num:(num + 1)]) / (255. / 2.)) - 1
print(_imgs.shape)
_imgs = _imgs[:, :, :, 0:3]
# time.sleep(1)
result_fake_y = sess.run([gan.test_fake_y], feed_dict={
gan.test_x: _imgs
}) # 生成的假照片
strpath = './preImg/pre_result_' + str(num) + '.npy'
np.save(strpath, result_fake_y)
print('ok')
else:
sess.run(init)
print('---------------------开始新的训练-----------------------')
for epoch in range(2):
for idx in range(0, len(train_hr_imgs), batch_size):
# print(type(train_hr_imgs[idx:idx + batch_size]))
b_imgs_384 = tl.prepro.threading_data(train_hr_imgs[idx:idx + batch_size], fn=crop_sub_imgs_fn,
is_random=True)
b_imgs_96 = tl.prepro.threading_data(b_imgs_384, fn=downsample_fn)
print('-------------pre_generator:' + str(epoch) + '_' + str(idx) + '----------------')
for i in range(25):
init_mse_loss, _ = sess.run([gan.init_mse_loss, G_OPTIM_init],
feed_dict={
gan.x: b_imgs_96,
gan.y: b_imgs_384
})
print('init_mse_loss:' + str(init_mse_loss))
saver.save(sess, "save/nets/cnn_mnist_basic_generator.ckpt")
for epoch in range(config["epoch"]):
for idx in range(0, len(train_hr_imgs), batch_size):
# print(type(train_hr_imgs[idx:idx + batch_size]))
b_imgs_384 = tl.prepro.threading_data(train_hr_imgs[idx:idx + batch_size], fn=crop_sub_imgs_fn,
is_random=True)
b_imgs_96 = tl.prepro.threading_data(b_imgs_384, fn=downsample_fn)
print('-------------' + str(epoch) + '_' + str(idx) + '----------')
for i in range(25):
loss_D, _ = sess.run([gan.D_loos, D_OPTIM],
feed_dict={
gan.x: b_imgs_96,
gan.y: b_imgs_384
})
loss_G, _ = sess.run([gan.G_loos, G_OPTIM],
feed_dict={
gan.x: b_imgs_96,
gan.y: b_imgs_384
})
print(loss_D, loss_G)
if idx % 20 == 0:
_imgs = (np.asanyarray(test_img[0:1]) / (255. / 2.)) - 1
_imgs = _imgs[:, :, :, 0:3]
result_fake_y = sess.run([gan.test_fake_y], feed_dict={
gan.test_x: _imgs
}) # 生成的假照片
# result=sess.run(result_fake_y)
strpath = './preImg/result_' + str(epoch) + '_' + str(idx) + '_1.npy'
np.save(strpath, result_fake_y)
_imgs2 = (np.asanyarray(test_img[1:2]) / (255. / 2.)) - 1
_imgs2 = _imgs2[:, :, :, 0:3]
result_fake_y = sess.run([gan.test_fake_y], feed_dict={
gan.test_x: _imgs2
}) # 生成的假照片
# result=sess.run(result_fake_y)
strpath = './preImg/result_' + str(epoch) + '_' + str(idx) + '_2.npy'
np.save(strpath, result_fake_y)
saver.save(sess, "save/nets/ckpt-" + str(epoch) + '-' + str(idx))
# print(type(result_fake_y))
查看效果的工具函数
将numpy矩阵转换为图片
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
npz = np.load('../preImg/pre_result_5.npy', encoding='latin1')
print(npz.shape)
data = ((npz[0][0]) + 1) * (255. / 2.)
print(data)
new_im = Image.fromarray(data.astype(np.uint8))
new_im.show()
new_im.save('result.png')
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:GAN生成式对抗网络(四)——SRGAN超高分辨率图片重构 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫