卷积神经网络的前向传播
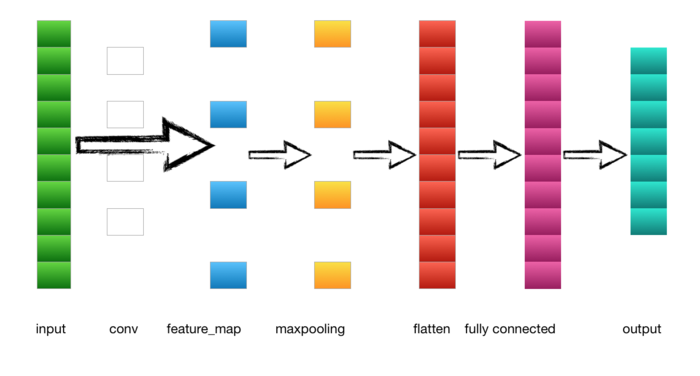
1.输入层---->卷积层
输入是一个4*4 的image,经过两个2*2的卷积核进行卷积运算后,变成两个3*3的feature_map

以卷积核filter1为例(stride = 1 ):
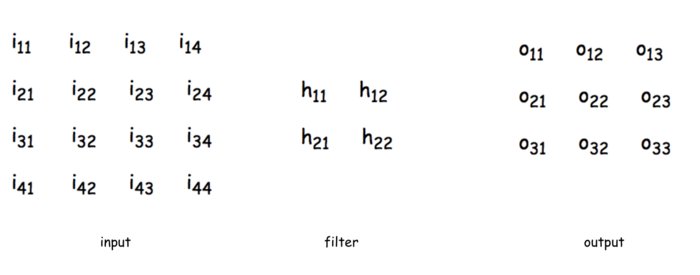
计算第一个卷积层神经元$ o_{11} $的输入:
$$
\begin{align}
net_{o11} \nonumber
& = conv(input, filter)\nonumber\\
& = i_{11}\times h_{11}+i_{12}\times h_{12}+i_{21}\times h_{21}+i_{22}\times h_{22}\\
& = 1\times 1+0\times (-1)+1\times 1+1\times (-1) = 1\nonumber
\end{align}
$$
神经元$ o_{11} $的输出:(此处使用Relu激活函数)
$$
\begin{align}
out_{o11} \nonumber
& = activators(net_{o11})\\
& = max(0, net_{o11})=1
\end{align}
$$
其他神经元的计算方式相同
2.卷积层---->池化层

计算池化层$ m_{11} $的输入(取窗口为 2 * 2),池化层没有激活函数
$$
\begin{align}
net_{m_{11}} \nonumber
& = max(o_{11},o_{12},o_{21},o_{22}) = 1\nonumber\\
& = out_{m_{11}}=net_{m_{11}}=1
\end{align}
$$
3.池化层---->全连接层
池化层的输出到flatten层把所有元素“拍平”,然后到全连接层。
4.全连接层---->输出层
全连接层到输出层就是正常的神经元与神经元之间的邻接相连,通过softmax函数计算后输出到output,得到不同类别的概率值,输出概率值最大的即为该图片的类别。
卷积神经网络的反向传播
传统的神经网络是全连接形式的,如果进行反向传播,只需要由下一层对前一层不断的求偏导,即求链式偏导就可以求出每一层的误差敏感项,然后求出权重和偏置项的梯度,即可更新权重。而卷积神经网络有两个特殊的层:卷积层和池化层。池化层输出时不需要经过激活函数,是一个滑动窗口的最大值,一个常数,那么它的偏导是1。池化层相当于对上层图片做了一个压缩,这个反向求误差敏感项时与传统的反向传播方式不同。从卷积后的feature_map反向传播到前一层时,由于前向传播时是通过卷积核做卷积运算得到的feature_map,所以反向传播与传统的也不一样,需要更新卷积核的参数。先回顾一下传统的反向传播算法:
- 通过前向传播计算每一层的输入值$ net_{i,j} $ (如卷积后feature_map的第一个神经元的输入:$ net_{i_{11}} $)
- 反向传播计算每个神经元的误差项$ \delta_{i,j} $,$ \delta_{i,j}=\frac{\partial E}{\partial net_{i,j}} $,其中 $ E $ 为损失函数计算得到的总体误差,可以用平方误差,交叉熵等表示。
- 计算每个神经元权重 $ w_{i,j} $ 的梯度,$ \eta _{i,j}=\frac{\partial E}{\partial net_{i,j}}\cdot \frac{\partial net_{i,j}}{\partial w _{i,j}} = \delta_{i,j}\cdot out_{i,j} $
- 更新权重$ w_{i,j} = w_{i,j}-\lambda \cdot \eta _{i,j} $ (其中 $ \lambda $ 为学习率)
卷积层的反向传播
由前向传播可得:
每一个神经元的值都是上一个神经元的输入作为这个神经元的输入,经过激活函数激活之后输出,作为下一个神经元的输入,在这里用 $ i_{11} $ 表示前一层; $ o_{11} $ 表示 $ i_{11} $ 的下一层。那么 $ net_{11} $ 就是 $ i_{11} $ 这个神经元的输入, $ out_{i_{11}} $ 就是 $ i_{11} $ 这个神经元的输出,同理, $ net_{o_{11}} $ 就是 $ o_{11} $ 这个神经元的输入,$ out_{o_{11}} $ 就是 $ o_{11} $ 这个神经元的输出,因为上一层神经元的输出=下一层神经元的输入,所以 $ out_{i_{11}}=net_{o_{11}} $ ,这里为了简化,直接把 $ out_{i_{11}} $ 记为 $ i_{11} $ 。
$$
\begin{align}
i_{11} \nonumber
& = out_{i_{11}}\nonumber\\
& = activators(net_{i_{11}})\nonumber\\
net_{o_{11}} \nonumber
& = conv(input,filter)\nonumber\\
& = i_{11}\times h_{11}+i_{12}\times h_{12}+i_{21} \times h_{21}+i_{22} \times h_{22}\\
out_{o_{11}} \nonumber
& = activators(net_{o_{11}}) \nonumber\\
& = max(0,net_{o_{11}})\nonumber
\end{align}
$$
$ net_{i_{11}} $ 表示上一层的输入, $ out_{i_{11}} $ 表示上次的输出
首先计算卷积的上一层的第一个元素 $ i_{11} $ 的误差项$ \delta_{11} $:
$$
\delta_{i,j}=\frac{\partial E}{\partial net_{i_{11}}}=\frac{\partial E}{\partial out_{i_{11}}}\cdot \frac{\partial out_{i_{11}}}{\partial net_{i_{11}}}=\frac{\partial E}{\partial i_{11}}\cdot \frac{\partial i_{11}}{\partial net_{i_{11}}}
$$
先计算 $ \frac{\partial E}{\partial i_{11}} $
此处还不清楚 $ \frac{\partial E}{\partial i_{11}} $ 怎么算,先可以把 $ input $ 层通过卷积核运算后的 $ feature\_map $ 写出来:
$$
\begin{align}
net_{o_{11}}= i_{11}\times h_{11}+i_{12}\times h_{12}+i_{21} \times h_{21}+i_{22} \times h_{22} \nonumber\\
net_{o_{12}}= i_{12}\times h_{11}+i_{13}\times h_{12}+i_{22} \times h_{21}+i_{23} \times h_{22} \nonumber\\
net_{o_{13}}= i_{13}\times h_{11}+i_{14}\times h_{12}+i_{23} \times h_{21}+i_{24} \times h_{22} \nonumber\\
net_{o_{21}}= i_{21}\times h_{11}+i_{22}\times h_{12}+i_{31} \times h_{21}+i_{32} \times h_{22} \nonumber\\
net_{o_{22}}= i_{22}\times h_{11}+i_{23}\times h_{12}+i_{32} \times h_{21}+i_{33} \times h_{22} \\
net_{o_{23}}= i_{23}\times h_{11}+i_{24}\times h_{12}+i_{33} \times h_{21}+i_{34} \times h_{22} \nonumber\\
net_{o_{31}}= i_{31}\times h_{11}+i_{32}\times h_{12}+i_{41} \times h_{21}+i_{42} \times h_{22} \nonumber\\
net_{o_{32}}= i_{32}\times h_{11}+i_{33}\times h_{12}+i_{42} \times h_{21}+i_{43} \times h_{22} \nonumber\\
net_{o_{33}}= i_{33}\times h_{11}+i_{34}\times h_{12}+i_{43} \times h_{21}+i_{44} \times h_{22} \nonumber
\end{align}
$$
然后依次对输入元素 $ i_{i,j} $ 求偏导
$ i_{11} $ 的偏导:
$$
\begin{align}
\frac{\partial E}{\partial i_{11}}
&= \frac{\partial E}{\partial net_{o_{11}}}\cdot \frac{\partial net_{o_{11}}}{\partial i_{11}}\nonumber\\
& = \delta _{11}\cdot h_{11}
\end{align}
$$
$ i_{12} $ 的偏导:
$$
\begin{align}
\frac{\partial E}{\partial i_{12}}
&= \frac{\partial E}{\partial net_{o_{11}}}\cdot \frac{\partial net_{o_{11}}}{\partial i_{12}}+\frac{\partial E}{\partial net_{o_{12}}}\cdot \frac{\partial net_{o_{12}}}{\partial i_{12}}\nonumber\\
& = \delta _{11}\cdot h_{12} + \delta _{12}\cdot h_{11}
\end{align}
$$
$ i_{13} $ 的偏导:
$$
\begin{align}
\frac{\partial E}{\partial i_{13}}
&= \frac{\partial E}{\partial net_{o_{12}}}\cdot \frac{\partial net_{o_{12}}}{\partial i_{13}}+\frac{\partial E}{\partial net_{o_{13}}}\cdot \frac{\partial net_{o_{13}}}{\partial i_{13}}\nonumber\\
& = \delta _{12}\cdot h_{12} + \delta _{13}\cdot h_{11}
\end{align}
$$
$ i_{21} $ 的偏导:
$$
\begin{align}
\frac{\partial E}{\partial i_{21}}
&= \frac{\partial E}{\partial net_{o_{11}}}\cdot \frac{\partial net_{o_{11}}}{\partial i_{21}}+\frac{\partial E}{\partial net_{o_{21}}}\cdot \frac{\partial net_{o_{21}}}{\partial i_{21}}\nonumber\\
& = \delta _{11}\cdot h_{21} + \delta _{21}\cdot h_{11}
\end{align}
$$
$ i_{22} $ 的偏导:
$$
\begin{align}
\frac{\partial E}{\partial i_{22}}
&= \frac{\partial E}{\partial net_{o_{11}}}\cdot \frac{\partial net_{o_{11}}}{\partial i_{22}}+\frac{\partial E}{\partial net_{o_{12}}}\cdot \frac{\partial net_{o_{12}}}{\partial i_{22}}+\frac{\partial E}{\partial net_{o_{21}}}\cdot \frac{\partial net_{o_{21}}}{\partial i_{22}}+\frac{\partial E}{\partial net_{o_{22}}}\cdot \frac{\partial net_{o_{22}}}{\partial i_{22}}\nonumber\\
& = \delta _{11}\cdot h_{22} + \delta _{12}\cdot h_{21}+ \delta _{21}\cdot h_{12} + \delta _{22}\cdot h_{11}
\end{align}
$$
观察上面式子的规律并归纳,可得表达式:
$$
\begin{align}
\left[
\begin{matrix}
0 & 0 & 0 & 0 & 0\\
0 & \delta _{11} & \delta _{12} & \delta _{13} & 0\\
0 & \delta _{12} & \delta _{22} & \delta _{23} & 0\\
0 & \delta _{13} & \delta _{32} & \delta _{33} & 0\\
0 & 0 & 0 & 0 & 0\\
\end{matrix}
\right]
\cdot
\left[
\begin{matrix}
h_{22} & h_{21}\\
h_{12} & h_{11}\\
\end{matrix}
\right]
=\left[
\begin{matrix}
\frac{\partial E}{\partial i_{11}} & \frac{\partial E}{\partial i_{12}} & \frac{\partial E}{\partial i_{13}} & \frac{\partial E}{\partial i_{14}}\\
\frac{\partial E}{\partial i_{21}} & \frac{\partial E}{\partial i_{22}} & \frac{\partial E}{\partial i_{23}} & \frac{\partial E}{\partial i_{24}}\\
\frac{\partial E}{\partial i_{31}} & \frac{\partial E}{\partial i_{32}} & \frac{\partial E}{\partial i_{33}} & \frac{\partial E}{\partial i_{34}}\\
\frac{\partial E}{\partial i_{41}} & \frac{\partial E}{\partial i_{42}} & \frac{\partial E}{\partial i_{43}} & \frac{\partial E}{\partial i_{44}}\\
\end{matrix}
\right]
\end{align}
$$
图中的卷积核进行了 $ 180^{\circ } $ 翻转,与这一层的误差敏感项矩阵 $ \delta _{i,j} $ 周围补零后的矩阵做卷积运算后,就可以得到 $ \frac{\partial E}{\partial i_{11}} $ ,即 $ \frac{\partial E}{\partial i_{11}}=\sum _{m}\cdot \sum _{n}h_{m,n}\delta _{i+m,j+n} $
第一项求完以后,再求第二项 $ \frac{\partial i_{11}}{\partial net_{i_{11}}} $
$$
\begin{align}
\because i_{11}\nonumber
& = out_{i_{11}}\nonumber\\
& = activators(net_{i_{11}})\nonumber\\
\therefore \frac{\partial i_{11}}{\partial net_{i_{11}}}={f}\'(net_{i_{11}})\nonumber\\
\therefore \delta _{11}\nonumber
& = \frac{\partial E}{\partial net_{i_{11}}}\nonumber\\
& = \frac{\partial E}{\partial i_{11}}\cdot \frac{\partial i_{11}}{\partial net_{i_{11}}}\\
& = \sum_{m}^{ }\cdot \sum_{n}^{ }h_{m,n}\delta _{i+m,j+n}\cdot {f}\'(net_{i_{11}})\nonumber
\end{align}
$$
此时误差敏感矩阵就求完了,得到误差敏感矩阵后,就可以求权重的梯度了。
由于上面已经写出来卷积层的输入 $ net_{o_{11}} $ 与权重 $ h_{i,j} $ 之间的表达式,所以可以直接求出:
$$
\begin{align}
\frac{\partial E}{\partial h_{11}}\nonumber
& = \frac{\partial E}{\partial net_{o_{11}}}\cdot \frac{\partial net_{o_{11}}}{\partial h_{11}}+...\nonumber\\
& + \frac{\partial E}{\partial net_{o_{33}}}\cdot \frac{\partial net_{o_{33}}}{\partial h_{11}}\nonumber\\
& = \delta +{11}\cdot h_{11}+...+\delta +{33}\cdot h_{11}
\end{align}
$$
推导出权重的梯度:
$$
\begin{align}
\frac{\partial E}{\partial h_{ij}} = \sum_{m}^{ }\cdot \sum_{n}^{ }\delta _{m,n}out_{o_{i+m,j+n}}
\end{align}
$$
偏置项的梯度:
$$
\begin{align}
\frac{\partial E}{\partial b}\nonumber
& = \frac{\partial E}{\partial net_{o_{11}}}\frac{\partial net_{o_{11}}}{\partial w_{b}}+\frac{\partial E}{\partial net_{o_{12}}}\frac{\partial net_{o_{12}}}{\partial w_{b}}\nonumber\\
& + \frac{\partial E}{\partial net_{o_{21}}}\frac{\partial net_{o_{21}}}{\partial w_{b}} +\frac{\partial E}{\partial net_{o_{22}}}\frac{\partial net_{o_{22}}}{\partial w_{b}}\\
& = \delta _{11}+\delta _{12}+\delta _{21}+\delta _{22}\nonumber\\
& = \sum_{i}^{ }\sum_{j}^{ }\delta _{ij}\nonumber
\end{align}
$$
可以看出,偏置项的偏导等于这一项多有误差敏感项之和,得到了权重和偏置项的梯度后,就可以根据梯度下降法更新权重和梯度了。
池化层的反向传播
池化层的反向传播就比较好求了,看着下面的图,左边是上一层的输出,也就是卷积层的输出feature_map,右边是池化层的输入,还是先根据前向传播,把式子都写出来,方便计算:

假设上一层的滑动窗口的最大值是 $ out_{o_{11}} $
$$
\begin{align}
\because net_{m_{11}} = max(out_{o_{11}}, out_{o_{12}},out_{o_{21}},out_{o_{22}})\nonumber\\
\therefore \frac{\partial net_{m_{11}}}{\partial out_{o_{11}}}=1\nonumber\\
\frac{\partial net_{m_{11}}}{\partial out_{o_{12}}}= \frac{\partial net_{m_{11}}}{\partial out_{o_{21}}} = \frac{\partial net_{m_{11}}}{\partial out_{o_{22}}} = 0\\
\therefore \delta _{l-1}^{11} = \frac{\partial E}{\partial out_{o_{11}}} = \frac{\partial E}{\partial net_{m_{11}}}\cdot \frac{\partial net_{m_{11}}}{\partial out_{o_{11}}} = \delta _{l}^{11}\nonumber\\
\delta _{l-1}^{12} = \delta _{l-1}^{21} = \delta _{l-1}^{22} = 0\nonumber
\end{align}
$$
这样就求出了池化层的误差敏感矩阵。同理可以求出每个神经元的梯度并更新权重。
手写一个卷积神经网络
1.定义一个卷积层
首先通过ConvLayer来实现一个卷积层,定义卷积层的超参数
1 class ConvLayer(object): 2 \'\'\' 3 参数含义: 4 input_width:输入图片尺寸——宽度 5 input_height:输入图片尺寸——长度 6 channel_number:通道数,彩色为3,灰色为1 7 filter_width:卷积核的宽 8 filter_height:卷积核的长 9 filter_number:卷积核数量 10 zero_padding:补零长度 11 stride:步长 12 activator:激活函数 13 learning_rate:学习率 14 \'\'\' 15 def __init__(self, input_width, input_height, 16 channel_number, filter_width, 17 filter_height, filter_number, 18 zero_padding, stride, activator, 19 learning_rate): 20 self.input_width = input_width 21 self.input_height = input_height 22 self.channel_number = channel_number 23 self.filter_width = filter_width 24 self.filter_height = filter_height 25 self.filter_number = filter_number 26 self.zero_padding = zero_padding 27 self.stride = stride 28 self.output_width = \ 29 ConvLayer.calculate_output_size( 30 self.input_width, filter_width, zero_padding, 31 stride) 32 self.output_height = \ 33 ConvLayer.calculate_output_size( 34 self.input_height, filter_height, zero_padding, 35 stride) 36 self.output_array = np.zeros((self.filter_number, 37 self.output_height, self.output_width)) 38 self.filters = [] 39 for i in range(filter_number): 40 self.filters.append(Filter(filter_width, 41 filter_height, self.channel_number)) 42 self.activator = activator 43 self.learning_rate = learning_rate
其中calculate_output_size用来计算通过卷积运算后输出的feature_map大小
1 @staticmethod 2 def calculate_output_size(input_size, 3 filter_size, zero_padding, stride): 4 return (input_size - filter_size + 5 2 * zero_padding) / stride + 1
2.构造一个激活函数
此处用的是RELU激活函数,因此我们在activators.py里定义,forward是前向计算,backforward是计算公式的导数
1 class ReluActivator(object): 2 def forward(self, weighted_input): 3 #return weighted_input 4 return max(0, weighted_input) 5 6 def backward(self, output): 7 return 1 if output > 0 else 0
其他常见的激活函数我们也可以放到activators里,如sigmoid函数,我们可以做如下定义:
1 class SigmoidActivator(object): 2 def forward(self, weighted_input): 3 return 1.0 / (1.0 + np.exp(-weighted_input)) 4 #the partial of sigmoid 5 def backward(self, output): 6 return output * (1 - output)
如果我们需要自动以其他的激活函数,都可以在activator.py定义一个类即可。
3.定义一个类,保存卷积层的参数和梯度
1 class Filter(object): 2 def __init__(self, width, height, depth): 3 #初始权重 4 self.weights = np.random.uniform(-1e-4, 1e-4, 5 (depth, height, width)) 6 #初始偏置 7 self.bias = 0 8 self.weights_grad = np.zeros( 9 self.weights.shape) 10 self.bias_grad = 0 11 12 def __repr__(self): 13 return \'filter weights:\n%s\nbias:\n%s\' % ( 14 repr(self.weights), repr(self.bias)) 15 16 def get_weights(self): 17 return self.weights 18 19 def get_bias(self): 20 return self.bias 21 22 def update(self, learning_rate): 23 self.weights -= learning_rate * self.weights_grad 24 self.bias -= learning_rate * self.bias_grad
4.卷积层的前向传播
1).获取卷积区域
1 # 获取卷积区域 2 def get_patch(input_array, i, j, filter_width, 3 filter_height, stride): 4 \'\'\' 5 从输入数组中获取本次卷积的区域, 6 自动适配输入为2D和3D的情况 7 \'\'\' 8 start_i = i * stride 9 start_j = j * stride 10 if input_array.ndim == 2: 11 input_array_conv = input_array[ 12 start_i : start_i + filter_height, 13 start_j : start_j + filter_width] 14 print "input_array_conv:",input_array_conv 15 return input_array_conv 16 17 elif input_array.ndim == 3: 18 input_array_conv = input_array[:, 19 start_i : start_i + filter_height, 20 start_j : start_j + filter_width] 21 print "input_array_conv:",input_array_conv 22 return input_array_conv
2).进行卷积运算
1 def conv(input_array, 2 kernel_array, 3 output_array, 4 stride, bias): 5 \'\'\' 6 计算卷积,自动适配输入为2D和3D的情况 7 \'\'\' 8 channel_number = input_array.ndim 9 output_width = output_array.shape[1] 10 output_height = output_array.shape[0] 11 kernel_width = kernel_array.shape[-1] 12 kernel_height = kernel_array.shape[-2] 13 for i in range(output_height): 14 for j in range(output_width): 15 output_array[i][j] = ( 16 get_patch(input_array, i, j, kernel_width, 17 kernel_height, stride) * kernel_array 18 ).sum() + bias
3).增加zero_padding
1 #增加Zero padding 2 def padding(input_array, zp): 3 \'\'\' 4 为数组增加Zero padding,自动适配输入为2D和3D的情况 5 \'\'\' 6 if zp == 0: 7 return input_array 8 else: 9 if input_array.ndim == 3: 10 input_width = input_array.shape[2] 11 input_height = input_array.shape[1] 12 input_depth = input_array.shape[0] 13 padded_array = np.zeros(( 14 input_depth, 15 input_height + 2 * zp, 16 input_width + 2 * zp)) 17 padded_array[:, 18 zp : zp + input_height, 19 zp : zp + input_width] = input_array 20 return padded_array 21 elif input_array.ndim == 2: 22 input_width = input_array.shape[1] 23 input_height = input_array.shape[0] 24 padded_array = np.zeros(( 25 input_height + 2 * zp, 26 input_width + 2 * zp)) 27 padded_array[zp : zp + input_height, 28 zp : zp + input_width] = input_array 29 return padded_array
4).进行前向传播
1 def forward(self, input_array): 2 \'\'\' 3 计算卷积层的输出 4 输出结果保存在self.output_array 5 \'\'\' 6 self.input_array = input_array 7 self.padded_input_array = padding(input_array, 8 self.zero_padding) 9 for f in range(self.filter_number): 10 filter = self.filters[f] 11 conv(self.padded_input_array, 12 filter.get_weights(), self.output_array[f], 13 self.stride, filter.get_bias()) 14 element_wise_op(self.output_array, 15 self.activator.forward)
其中element_wise_op函数是将每个组的元素对应相乘
1 # 对numpy数组进行element wise操作,将矩阵中的每个元素对应相乘 2 def element_wise_op(array, op): 3 for i in np.nditer(array, 4 op_flags=[\'readwrite\']): 5 i[...] = op(i)
5.卷积层的反向传播
1).将误差传递到上一层
1 def bp_sensitivity_map(self, sensitivity_array, 2 activator): 3 \'\'\' 4 计算传递到上一层的sensitivity map 5 sensitivity_array: 本层的sensitivity map 6 activator: 上一层的激活函数 7 \'\'\' 8 # 处理卷积步长,对原始sensitivity map进行扩展 9 expanded_array = self.expand_sensitivity_map( 10 sensitivity_array) 11 # full卷积,对sensitivitiy map进行zero padding 12 # 虽然原始输入的zero padding单元也会获得残差 13 # 但这个残差不需要继续向上传递,因此就不计算了 14 expanded_width = expanded_array.shape[2] 15 zp = (self.input_width + 16 self.filter_width - 1 - expanded_width) / 2 17 padded_array = padding(expanded_array, zp) 18 # 初始化delta_array,用于保存传递到上一层的 19 # sensitivity map 20 self.delta_array = self.create_delta_array() 21 # 对于具有多个filter的卷积层来说,最终传递到上一层的 22 # sensitivity map相当于所有的filter的 23 # sensitivity map之和 24 for f in range(self.filter_number): 25 filter = self.filters[f] 26 # 将filter权重翻转180度 27 flipped_weights = np.array(map( 28 lambda i: np.rot90(i, 2), 29 filter.get_weights())) 30 # 计算与一个filter对应的delta_array 31 delta_array = self.create_delta_array() 32 for d in range(delta_array.shape[0]): 33 conv(padded_array[f], flipped_weights[d], 34 delta_array[d], 1, 0) 35 self.delta_array += delta_array 36 # 将计算结果与激活函数的偏导数做element-wise乘法操作 37 derivative_array = np.array(self.input_array) 38 element_wise_op(derivative_array, 39 activator.backward) 40 self.delta_array *= derivative_array
2).保存传递到上一层的sensitivity map的数组
1 def create_delta_array(self): 2 return np.zeros((self.channel_number, 3 self.input_height, self.input_width))
3).计算代码梯度
1 def bp_gradient(self, sensitivity_array): 2 # 处理卷积步长,对原始sensitivity map进行扩展 3 expanded_array = self.expand_sensitivity_map( 4 sensitivity_array) 5 for f in range(self.filter_number): 6 # 计算每个权重的梯度 7 filter = self.filters[f] 8 for d in range(filter.weights.shape[0]): 9 conv(self.padded_input_array[d], 10 expanded_array[f], 11 filter.weights_grad[d], 1, 0) 12 # 计算偏置项的梯度 13 filter.bias_grad = expanded_array[f].sum()
4).按照梯度下降法更新参数
1 def update(self): 2 \'\'\' 3 按照梯度下降,更新权重 4 \'\'\' 5 for filter in self.filters: 6 filter.update(self.learning_rate)
6.MaxPooling层的训练
1).定义MaxPooling类
1 class MaxPoolingLayer(object): 2 def __init__(self, input_width, input_height, 3 channel_number, filter_width, 4 filter_height, stride): 5 self.input_width = input_width 6 self.input_height = input_height 7 self.channel_number = channel_number 8 self.filter_width = filter_width 9 self.filter_height = filter_height 10 self.stride = stride 11 self.output_width = (input_width - 12 filter_width) / self.stride + 1 13 self.output_height = (input_height - 14 filter_height) / self.stride + 1 15 self.output_array = np.zeros((self.channel_number, 16 self.output_height, self.output_width))
2).前向传播计算
1 # 前向传播 2 def forward(self, input_array): 3 for d in range(self.channel_number): 4 for i in range(self.output_height): 5 for j in range(self.output_width): 6 self.output_array[d,i,j] = ( 7 get_patch(input_array[d], i, j, 8 self.filter_width, 9 self.filter_height, 10 self.stride).max())
3).反向传播计算
1 #反向传播 2 def backward(self, input_array, sensitivity_array): 3 self.delta_array = np.zeros(input_array.shape) 4 for d in range(self.channel_number): 5 for i in range(self.output_height): 6 for j in range(self.output_width): 7 patch_array = get_patch( 8 input_array[d], i, j, 9 self.filter_width, 10 self.filter_height, 11 self.stride) 12 k, l = get_max_index(patch_array) 13 self.delta_array[d, 14 i * self.stride + k, 15 j * self.stride + l] = \ 16 sensitivity_array[d,i,j]
完整代码请见:cnn.py (https://github.com/huxiaoman7/PaddlePaddle_code/blob/master/1.mnist/cnn.py)


1 #coding:utf-8 2 \'\'\' 3 Created by huxiaoman 2017.11.22 4 5 \'\'\' 6 7 import numpy as np 8 from activators import ReluActivator,IdentityActivator 9 10 class ConvLayer(object): 11 def __init__(self,input_width,input_weight, 12 channel_number,filter_width, 13 filter_height,filter_number, 14 zero_padding,stride,activator, 15 learning_rate): 16 self.input_width = input_width 17 self.input_height = input_height 18 self.channel_number = channel_number 19 self.filter_width = filter_width 20 self.filter_height = filter_height 21 self.filter_number = filter_number 22 self.zero_padding = zero_padding 23 self.stride = stride #此处可以加上stride_x, stride_y 24 self.output_width = ConvLayer.calculate_output_size( 25 self.input_width,filter_width,zero_padding, 26 stride) 27 self.output_height = ConvLayer.calculate_output_size( 28 self.input_height,filter_height,zero_padding, 29 stride) 30 self.output_array = np.zeros((self.filter_number, 31 self.output_height,self.output_width)) 32 self.filters = [] 33 for i in range(filter_number): 34 self.filters.append(Filter(filter_width, 35 filter_height,self.channel_number)) 36 self.activator = activator 37 self.learning_rate = learning_rate 38 def forward(self,input_array): 39 \'\'\' 40 计算卷积层的输出 41 输出结果保存在self.output_array 42 \'\'\' 43 self.input_array = input_array 44 self.padded_input_array = padding(input_array, 45 self.zero_padding) 46 for i in range(self.filter_number): 47 filter = self.filters[f] 48 conv(self.padded_input_array, 49 filter.get_weights(), self.output_array[f], 50 self.stride, filter.get_bias()) 51 element_wise_op(self.output_array, 52 self.activator.forward) 53 54 def get_batch(input_array, i, j, filter_width,filter_height,stride): 55 \'\'\' 56 从输入数组中获取本次卷积的区域, 57 自动适配输入为2D和3D的情况 58 \'\'\' 59 start_i = i * stride 60 start_j = j * stride 61 if input_array.ndim == 2: 62 return input_array[ 63 start_i : start_i + filter_height, 64 start_j : start_j + filter_width] 65 elif input_array.ndim == 3: 66 return input_array[ 67 start_i : start_i + filter_height, 68 start_j : start_j + filter_width] 69 70 # 获取一个2D区域的最大值所在的索引 71 def get_max_index(array): 72 max_i = 0 73 max_j = 0 74 max_value = array[0,0] 75 for i in range(array.shape[0]): 76 for j in range(array.shape[1]): 77 if array[i,j] > max_value: 78 max_value = array[i,j] 79 max_i, max_j = i, j 80 return max_i, max_j 81 82 def conv(input_array,kernal_array, 83 output_array,stride,bias): 84 \'\'\' 85 计算卷积,自动适配输入2D,3D的情况 86 \'\'\' 87 channel_number = input_array.ndim 88 output_width = output_array.shape[1] 89 output_height = output_array.shape[0] 90 kernel_width = kernel_array.shape[-1] 91 kernel_height = kernel_array.shape[-2] 92 for i in range(output_height): 93 for j in range(output_width): 94 output_array[i][j] = ( 95 get_patch(input_array, i, j, kernel_width, 96 kernel_height,stride) * kernel_array).sum() +bias 97 98 99 def element_wise_op(array, op): 100 for i in np.nditer(array, 101 op_flags = [\'readwrite\']): 102 i[...] = op(i) 103 104 105 class ReluActivators(object): 106 def forward(self, weighted_input): 107 # Relu计算公式 = max(0,input) 108 return max(0, weighted_input) 109 110 def backward(self,output): 111 return 1 if output > 0 else 0 112 113 class SigmoidActivator(object): 114 115 def forward(self,weighted_input): 116 return 1 / (1 + math.exp(- weighted_input)) 117 118 def backward(self,output): 119 return output * (1 - output)
View Code
最后,我们用之前的4 * 4的image数据检验一下通过一次卷积神经网络进行前向传播和反向传播后的输出结果:
1 def init_test(): 2 a = np.array( 3 [[[0,1,1,0,2], 4 [2,2,2,2,1], 5 [1,0,0,2,0], 6 [0,1,1,0,0], 7 [1,2,0,0,2]], 8 [[1,0,2,2,0], 9 [0,0,0,2,0], 10 [1,2,1,2,1], 11 [1,0,0,0,0], 12 [1,2,1,1,1]], 13 [[2,1,2,0,0], 14 [1,0,0,1,0], 15 [0,2,1,0,1], 16 [0,1,2,2,2], 17 [2,1,0,0,1]]]) 18 b = np.array( 19 [[[0,1,1], 20 [2,2,2], 21 [1,0,0]], 22 [[1,0,2], 23 [0,0,0], 24 [1,2,1]]]) 25 cl = ConvLayer(5,5,3,3,3,2,1,2,IdentityActivator(),0.001) 26 cl.filters[0].weights = np.array( 27 [[[-1,1,0], 28 [0,1,0], 29 [0,1,1]], 30 [[-1,-1,0], 31 [0,0,0], 32 [0,-1,0]], 33 [[0,0,-1], 34 [0,1,0], 35 [1,-1,-1]]], dtype=np.float64) 36 cl.filters[0].bias=1 37 cl.filters[1].weights = np.array( 38 [[[1,1,-1], 39 [-1,-1,1], 40 [0,-1,1]], 41 [[0,1,0], 42 [-1,0,-1], 43 [-1,1,0]], 44 [[-1,0,0], 45 [-1,0,1], 46 [-1,0,0]]], dtype=np.float64) 47 return a, b, cl
运行一下:
1 def test(): 2 a, b, cl = init_test() 3 cl.forward(a) 4 print "前向传播结果:", cl.output_array 5 cl.backward(a, b, IdentityActivator()) 6 cl.update() 7 print "反向传播后更新得到的filter1:",cl.filters[0] 8 print "反向传播后更新得到的filter2:",cl.filters[1] 9 10 if __name__ == "__main__": 11 test()
运行结果:
1 前向传播结果: [[[ 6. 7. 5.] 2 [ 3. -1. -1.] 3 [ 2. -1. 4.]] 4 5 [[ 2. -5. -8.] 6 [ 1. -4. -4.] 7 [ 0. -5. -5.]]] 8 反向传播后更新得到的filter1: filter weights: 9 array([[[-1.008, 0.99 , -0.009], 10 [-0.005, 0.994, -0.006], 11 [-0.006, 0.995, 0.996]], 12 13 [[-1.004, -1.001, -0.004], 14 [-0.01 , -0.009, -0.012], 15 [-0.002, -1.002, -0.002]], 16 17 [[-0.002, -0.002, -1.003], 18 [-0.005, 0.992, -0.005], 19 [ 0.993, -1.008, -1.007]]]) 20 bias: 21 0.99099999999999999 22 反向传播后更新得到的filter2: filter weights: 23 array([[[ 9.98000000e-01, 9.98000000e-01, -1.00100000e+00], 24 [ -1.00400000e+00, -1.00700000e+00, 9.97000000e-01], 25 [ -4.00000000e-03, -1.00400000e+00, 9.98000000e-01]], 26 27 [[ 0.00000000e+00, 9.99000000e-01, 0.00000000e+00], 28 [ -1.00900000e+00, -5.00000000e-03, -1.00400000e+00], 29 [ -1.00400000e+00, 1.00000000e+00, 0.00000000e+00]], 30 31 [[ -1.00400000e+00, -6.00000000e-03, -5.00000000e-03], 32 [ -1.00200000e+00, -5.00000000e-03, 9.98000000e-01], 33 [ -1.00200000e+00, -1.00000000e-03, 0.00000000e+00]]]) 34 bias: 35 -0.0070000000000000001
参考:https://www.cnblogs.com/charlotte77/p/7783261.html
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:【深度学习】卷积神经网络CNN——手写一个卷积神经网络 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
