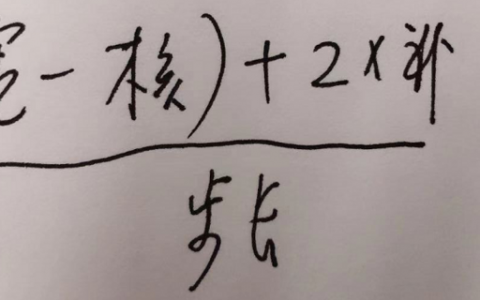卷积神经网络是在BP神经网络的改进,与BP类似,都采用了前向传播计算输出值,反向传播调整权重和偏置;CNN与标准的BP最大的不同是:CNN中相邻层之间的神经单元并不是全连接,而是部分连接,也就是某个神经单元的感知区域来自于上层的部分神经单元,而不是像BP那样与所有的神经单元相连接。CNN的有三个重要的思想架构:
- 局部区域感知
- 权重共享
- 空间或时间上的采样
公式参考《Notes on Convolutional Neural Networks》。
1.卷积层前向计算
上面的*号实质是让卷积核k在第l-1层所有关联的feature maps上做卷积运算,然后求和,再加上一个偏置参数,取sigmoid得到最终激励值的过程。
假设第l-1层只有两个feature map,大小为4*4像素,一个卷积核K(二维卷积核K11和K12),大小为2*2,则计算第l层的一个feature map结果如下,大小为3*3像素。
(在计算前要把卷积核旋转180°)第一步在python中的代码实现如下。
def conv(self,a, v, full=0): # valid:0 full:1 ah, aw = np.shape(a) vh, vw = np.shape(v) if full: temp = np.zeros((ah + 2 * vh - 2, aw + 2 * vw - 2)) temp[vh - 1:vh - 1 + ah, vw - 1:vw - 1 + aw] = a a = temp ah, aw = np.shape(a) k = [[np.sum(np.multiply(a[i:i+vh,j:j+vw],v)) for j in range(aw - vw + 1)] for i in range(ah - vh + 1)] return k
2.卷积层的残差计算
其中第l层为卷积层,第l+1层为subsampling层,subsampling层与卷积层是一一对应的。其中up(x)是将第l+1层的大小扩展为和第l层大小一样。
○指点乘,对应numpy.multiply。
假如第l+1层为2*2的,subsampling的采样大小为2*2,其中第l+1层的一个feature map所对应的残差为:
那么扩展之后就变为了
实现代码如下。
def up(self,a,n): b=np.ones((n,n)) return np.kron(a,b)
3.卷积层的梯度计算
如卷积层为3*3的大小,卷积核的大小为2*2上一层feature map大小为4*4。
实际等于convolve2d(xl-1,delta)。
4.subsampling层前向计算
这里的down(x)是将x中采样大小中像素值进行采样操作,如求和、最大值。
5.subsampling层残差计算(假设下一层为卷积层)
对于下图中第l-1层值为6的元素,根据卷积层前向计算的过程,与第l层的关联运算如下。
故根据bp算法中残差计算方法等于第l层与其连接的所有结点的权值和残差的加权和再乘以该点对z的导数值,相当于用旋转180度的卷积核直接在下一层卷积层的残差上做卷积运算,方式为full类型。
6.subsampling层梯度计算(假设下一层为卷积层)
7.Python实现
不使用theano或者类似工具包时,上述一些运算速度很慢,有待优化。
使用了一个卷积层,一个下采样层,再连接全连接层,softmax输出。
参考下一篇随笔(卷积层不用bi,池化层不用w,两层公用一个激活函数),正确率仅能达到90%左右。
在CNN1 递归网络中进行修改完善。
# coding:utf8 import cPickle import numpy as np class ConvLayer(object): # layer init def __init__(self, image_shape,filter_shape): self.filter_shape = filter_shape # 5, 5, 5, 卷积核5*5,5个 self.image_shape = image_shape # 28, 28 self.w = np.random.normal(loc=0, scale=np.sqrt(4.0/125), size=filter_shape) # 5*5*5/2/2 def conv(self,a, v, full=0): # valid:0 full:1 ah, aw = np.shape(a) vh, vw = np.shape(v) if full: temp = np.zeros((ah + 2 * vh - 2, aw + 2 * vw - 2)) temp[vh - 1:vh - 1 + ah, vw - 1:vw - 1 + aw] = a a = temp ah, aw = np.shape(a) k = [[np.sum(np.multiply(a[i:i+vh,j:j+vw],v)) for j in range(aw - vw + 1)] for i in range(ah - vh + 1)] return k def rot180(self,a): temp=np.rot90(a) return np.rot90(temp) def feedforward(self, a): #28*28 self.out = [self.conv(a, self.rot180(w_)) for w_ in self.w] #self.out = [sg.convolve2d(a, self.rot180(w_),mode='valid') for w_ in self.w] return np.array(self.out) #5*24*24 def backprop(self, x, dnext): u = self.out #5*24*24 delta = [(np.multiply(u_,self.up(d_,2))) for u_,d_ in zip(u,dnext)] w = np.array([self.rot180(self.conv(x, d_)) for d_ in delta]) #w = np.array([self.rot180(sg.convolve2d(x, d_,mode='valid')) for d_ in delta]) return w def up(self,a,l): b=np.ones((l,l)) return np.kron(a,b) class PoolLayer(object): # layer init def __init__(self, image_shape, poolsize=(2, 2)): self.image_shape = image_shape # 5, 24, 24 self.poolsize = poolsize # 2,2 self.b = np.random.normal(loc=0, scale=1.0, size=(image_shape[0],)) # 5 def samp(self,a): # 24*24->12*12 ah, aw = self.image_shape[1:] # 24,24 vh, vw = self.poolsize # 2,2 k = [[np.max(a[i*vh:i*vh+vh,j*vw :j*vw+vw]) for j in range(aw / vw)] for i in range(ah / vh)] return np.array(k) def feedforward(self, a): self.out=np.array([self.relu(self.samp(a_)+b_) for a_,b_ in zip(a,self.b)]) return self.out def backprop(self, dnext): u=self.out delta = np.multiply(dnext, self.relu_prime(u)) b= np.array([np.sum(d) for d in delta]) return delta,b def relu(self,z): return np.maximum(z, 0.0) def relu_prime(self,z): z[z>0]=1 return z class Network(object): def __init__(self, sizes): self.num_layers = len(sizes) self.cl=ConvLayer([28,28],[5,5,5]) self.pl=PoolLayer([5,24,24],[2,2]) self.sizes = sizes self.biases = [np.random.randn(y) for y in sizes[1:]] self.weights = [np.random.randn(y, x)/np.sqrt(y) for x, y in zip(sizes[1:],sizes[:-1])] def feedforward(self, x): cout=self.cl.feedforward(x) pout=self.pl.feedforward(cout) a=np.reshape(pout,(1,self.sizes[0])) for b_, w_ in zip(self.biases[:-1], self.weights[:-1]): a = self.sigmoid(np.dot(a, w_)+b_) a=self.softmax(np.dot(a, self.weights[-1])+self.biases[-1]) return a def SGD(self, training_data, test_data,epochs, mini_batch_size, eta=0.01): n_test = len(test_data) self.n = len(training_data) self.mini_batch_size=mini_batch_size self.eta=eta cx=range(epochs) for j in cx: np.random.shuffle(training_data) for k in xrange(0, self.n , mini_batch_size): mini_batch = training_data[k:k+mini_batch_size] self.update_mini_batch(mini_batch) if k%1000==0: print "Epoch {0}:{1} train: {2} / {3} cost={4}, test: {5} / {6}".format(j,k, self.evaluate(training_data[:500],1),500 ,self.cost, self.evaluate(test_data), n_test) def update_mini_batch(self, mini_batch): for x, y in mini_batch: self.backprop(x, y) def backprop(self, x_in, y): b=np.zeros_like(self.biases) w=np.zeros_like(self.weights) cout=self.cl.feedforward(x_in) pout=self.pl.feedforward(cout) x=np.reshape(pout,(1,self.sizes[0])) a_ = x a = [x] for b_, w_ in zip(self.biases, self.weights): a_ = self.sigmoid(np.dot(a_, w_)+b_) a.append(a_) for l in xrange(1, self.num_layers): if l==1: delta =self.softmax(np.dot(a[-2],w_) + b_)-y else: sp=self.sigmoid_prime(a[-l]) delta = np.dot( delta,self.weights[-l+1].T) * sp b[-l] = delta w[-l] = np.dot( a[-l-1].T,delta) self.weights-=self.eta*(w) self.biases -= self.eta*b dnext=np.dot(delta,self.weights[0].T) dnext=np.reshape(dnext,(5,12,12)) delta_p,delta_pb=self.pl.backprop(dnext) self.pl.b-=self.eta*delta_pb delta_cw=self.cl.backprop(x_in,delta_p) self.cl.w-=self.eta*delta_cw def evaluate(self, test_data, train=0): if train: xy=[(self.feedforward(x),np.argmax(y)) for (x, y) in test_data] test_results = [(np.argmax(x), y) for (x, y) in xy] xl=[x[0] for x,_ in xy] yl=[y for _,y in xy] self.cost = -np.mean(np.log(xl)[np.arange(500),yl]) else: test_results = [(np.argmax(self.feedforward(x)), y) for (x, y) in test_data] return sum(int(x == y) for (x, y) in test_results) def sigmoid(self,z): return 1.0/(1.0+np.exp(-z)) def sigmoid_prime(self,z): return z*(1-z) def softmax(self,a): m = np.exp(a) return m / np.sum(m,axis=1) def get_label(i): c=np.zeros((10)) c[i]=1 return c if __name__ == '__main__': def get_data(data): return [np.reshape(x, (28,28)) for x in data[0]] f = open('data/mnist.pkl', 'rb') training_data, validation_data, test_data = cPickle.load(f) training_inputs = get_data(training_data) training_label=[get_label(y_) for y_ in training_data[1]] data = zip(training_inputs,training_label) test_inputs = training_inputs = get_data(test_data) test = zip(test_inputs,test_data[1]) net = Network([720, 100, 10]) net.SGD(data,test[:500],epochs=10,mini_batch_size=10, eta=0.001)
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:卷积层和池化层 CNN1 递归网络 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫