训练模型过程中,经常需要追踪一些性能指标的变化情况,以便了解模型的实时动态,例如:回归任务中的MSE、分类任务中的Accuracy、生成对抗网络中的图片、网络模型结构可视化…… 除了追踪外,我们还希望能够将这些指标以动态图表的形式可视化显示出来。
TensorFlow的附加工具Tensorboard就完美的提供了这些功能。不过现在经过Pytorch团队的努力,TensorBoard已经集成到了Pytorch中,只要安装有pytorch也可以直接使用TensorBoard。
Tensorboard同时提供了后端数据记录功能和前端数据可视化功能。通过后端数据记录功能,我们可以将需要追踪的性能指标写入到指定文件;通过前端数据可视化功能,我们可是实时查看当前训练情况。
在接下来的文章中,将对TensorBoard的使用方法进行介绍,如果你还没有安装,可以通过一下命令进行安装。注意,虽然torch集成有TensorBoard,但是并不完整,需要使用下面命令完整安装后,才能开启TensorBoard的WEB应用。
pip install tensorboard
1 开启TensorBoard的WEB应用¶
在通过上述命令完成tensorboard的安装后,即可在命令行调用tensorboard进行启动。如下所示:
tensorboard --logdir=./run
运行后输出如下:


logdir参数的作用是指定读取记录数据的目录,如果该目录内又多个记录文件,也会在页面中列表显示。另外从输出结果中,tensorboard默认从6006端口启动,当然也可以通过port参数指定端口,如下所示,我们指定从8088端口启动:
tensorboard --logdir=./run --port 8088
在浏览器地址栏,我们输入对应地址,打开页面如下:
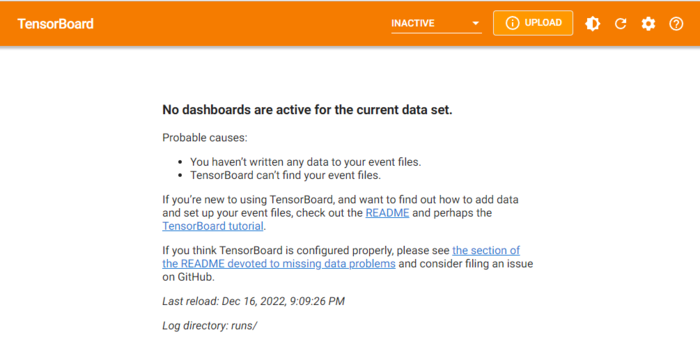
现在之所以提示这些信息,是因为我们还没有记录过任何数据。
2 SummaryWriter类¶
SummaryWriter是tensorboard中专门用来记录数据的类,只有通过SummaryWriter记录好的数据,才能在前端页面中展示。SummaryWriter类实例化时,主要参数如下:
-
log_dir (str):指定了数据保存的文件夹的位置,如果该文件夹不存在则会创建一个出来。如果没有指定的话,默认的保存的文件夹是./runs/现在的时间_主机名,例如:Dec16_21-13-54_DESKTOP-E782FS1,因此每次运行之后都会创建一个新的文件夹。
-
comment (string):给默认的log_dir添加的后缀,如果我们已经指定了log_dir具体的值,那么这个参数就不会有任何的效果
-
purge_step (int):TensorBoard在记录数据的时候有可能会崩溃,例如在某一个epoch中,进行到第$T + X$个step的时候由于各种原因(内存溢出)导致崩溃,那么当服务重启之后,就会从$T$个step重新开始将数据写入文件,而中间的$X$,即purge_step指定的step内的数据都被被丢弃。
- max_queue (int):在记录数据的时候,在内存中开的队列的长度,当队列慢了之后就会把数据写入磁盘(文件)中。
- flush_secs (int):以秒为单位的写入磁盘的间隔,默认是120秒,即两分钟。
- filename_suffix (string):添加到log_dir中每个文件的后缀.
import torch
from torch.utils.tensorboard import SummaryWriter
# 使用默认参数创建summary writer,程序将会自动生成文件名
writer = SummaryWriter()
# 生成的文件路径为: runs/Dec16_21-13-54_DESKTOP-E782FS1/
# 创建summary writer时,指定文件路径
writer = SummaryWriter("my_experiment")
# 生成的文件路径为: my_experiment
# 创建summary writer时,使用comment作为后缀
writer = SummaryWriter(comment="LR_0.1_BATCH_16")
# folder location: runs/Dec16_21-19-59_DESKTOP-E782FS1LR_0.1_BATCH_16/
3 写入数据¶
SummaryWriter类中定义了各式各样的方法,用于记录不同的数据,这些方法都已“add_”开头,我们先罗列一下这些方法:
writer = SummaryWriter('runs')
for i in SummaryWriter.__dict__.keys():
if i.startswith("add_"):
print(i)
add_hparams add_scalar add_scalars add_histogram add_histogram_raw add_image add_images add_image_with_boxes add_figure add_video add_audio add_text add_onnx_graph add_graph add_embedding add_pr_curve add_pr_curve_raw add_custom_scalars_multilinechart add_custom_scalars_marginchart add_custom_scalars add_mesh
大体来说,所能记录的数据类型包括标量(scalar)、图像(image)、统计图(diagram)、视频(video)、音频(audio)、文本(text)、Embedding等等。下面我们一次来说说怎么记录这些不同类型的数据。
3.1 标量数据¶
注意:训练过程中,添加loss等数据是,一定要通过item()方法,转换为标量之后才能添加到tensorboard中。
(1)add_scalar:一图一曲线
-
tag (str):用于给数据进行分类的标签,标签中可以包含父级和子级标签。例如给训练的loss以loss/train的tag,而给验证以loss/val的tag,这样的话,最终的效果就是训练的loss和验证的loss都被分到了loss这个父级标签下。而train和val则是具体用于区分两个参数的标识符(identifier)。此外,只支持二级标签。
-
global_step (int):首先,每个epoch中我们都会更新固定的step。因此,在一个数据被加入的时候,有两种step,第一种step是数据被加入时当前epoch已经进行了多少个step,第二种step是数据被加入时候,累计(包括之前的epoch)已经进行了多少个step。而考虑到我们在绘图的时候往往是需要观察所有的step下的数据的变化,因此global_step指的就是当前数据被加入的时候已经计算了多少个step。计算global_step的步骤很简单,就是$global_step=epoch∗len(dataloader)+current_step$
-
wlltime (int):从SummaryWriter实例化开始到当前数据被加入时候所经历时间(以秒计算),默认是使用time.time()来自动计算的,当然我们也可以指定这个参数来进行修改。这个参数一般不改
writer = SummaryWriter('runs/add_scalar')
for n_iter in range(100):
writer.add_scalar('Loss/train', np.random.random(), n_iter)
writer.add_scalar('Loss/test', np.random.random(), n_iter)
writer.add_scalar('Accuracy/train', np.random.random(), n_iter)
writer.add_scalar('Accuracy/test', np.random.random(), n_iter)
writer.close()
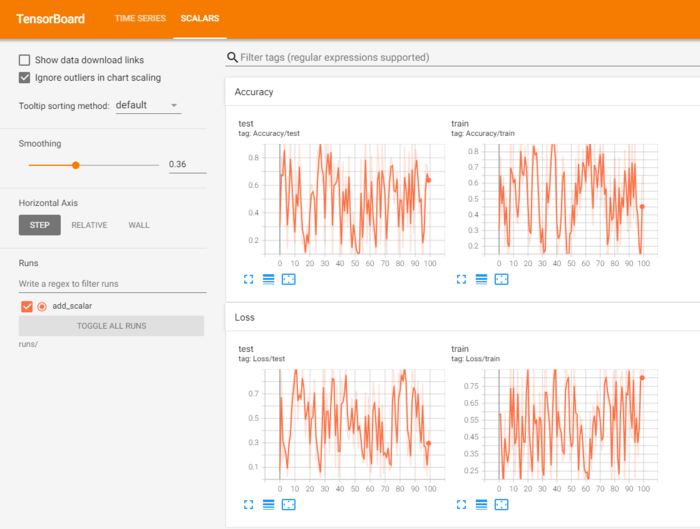
使用不同的SummaryWriter实例,相同的tag进行记录数据时,将可以实现在同一张图表中显示多条曲线。注意,实例化SummaryWriter时,必须指定不同的文件夹,否则多个记录数据虽然也是在同一图表中,但是图是混乱的。
# 两个Accuracy写入不同的文件夹中
writer1 = SummaryWriter('runs/add_scalar-1')
writer2 = SummaryWriter('runs/add_scalar-2')
for n_iter in range(100):
# 使用两个SummaryWriter分别记录LOSS和Accuracy,注意,tag必须一样
writer1.add_scalar('Loss', np.random.random(), n_iter)
writer2.add_scalar('Loss', np.random.random(), n_iter)
writer1.add_scalar('Accuracy', np.random.random(), n_iter)
writer2.add_scalar('Accuracy', np.random.random(), n_iter)
writer1.close()
writer2.close()
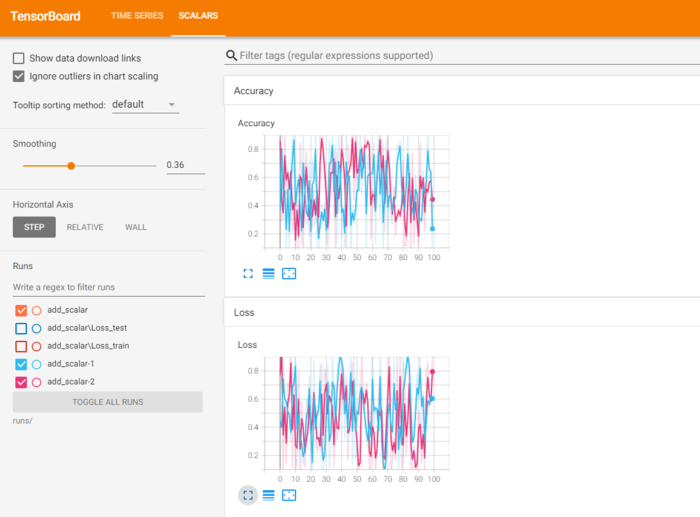
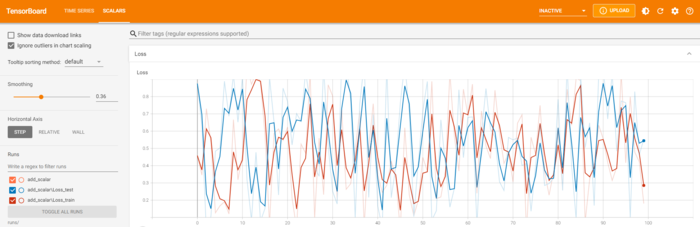
(2)add_scalars:一图多曲线
一张图显示多条曲线可以更加方便得对比数据,SummaryWriter中提供add_scalars方法实现在一张图中绘制多条曲线。
-
main_tag (str):多条曲线共用的标签
-
tag_scalar_dict (dict):多个需要记录的数据组成的键值对
-
global_step (int):训练的 step
-
walltime (float):从SummaryWriter实例化开始到当前数据被加入时候所经历时间(以秒计算)
writer = SummaryWriter('runs/add_scalar')
for n_iter in range(100):
writer.add_scalars('Loss', {'test':np.random.random(),'train':np.random.random()}, n_iter)
writer.close()
3.2 图像数据¶
(1)add_image
-
tag (str):数据标签
-
img_tensor:图像数据,数据类型可以使torch.Tensor, numpy.ndarray, string/blobname
-
global_step (int):训练的step
-
walltime (float):从SummaryWriter实例化开始到当前数据被加入时候所经历时间(以秒计算)
-
dataformats (str):图像数据的格式,可以是CHW, HWC, HW, WH等,默认为CHW,即Channel x Height x Width。通常来说,默认即可,但如果图像tensor不是CHW,就要通过这个参数指定了。
在本地文件夹有images下有多张图片,我们选择一张将其记录到tensorboard中:
from torchvision.io import read_image
# 将图片打开为torch.Tensor类型
img = read_image('images/0975.jpg')
img.shape
torch.Size([3, 224, 224])
可见,图片为CHW类型。我们将所有图片上传记录:
writer = SummaryWriter('runs/add_image')
path_lst = [os.path.join('images', i) for i in os.listdir('images')]
for i, img in enumerate(path_lst):
img = read_image(img)
writer.add_image('img', img, i)
writer.close()
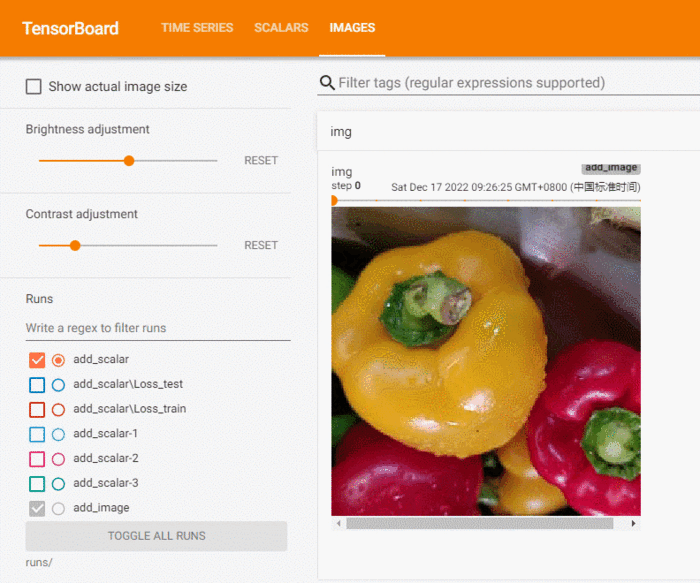
add_image方法一般情况下只能一次插入一张图片。如果要一次性插入多张图片,可以使用 torchvision 中的 make_grid 方法,将多张图片拼合成一张图片后,再调用 add_image 方法。
from torchvision.utils import make_grid
path_lst = [os.path.join('images', i) for i in os.listdir('images')]
img_lst = []
for i, img in enumerate(path_lst):
img = read_image(img)
img_lst.append(img)
writer = SummaryWriter('runs/add_image')
img_grid = make_grid(img_lst, nrow=5)
writer.add_image('img_grid', img_grid)
writer.close()
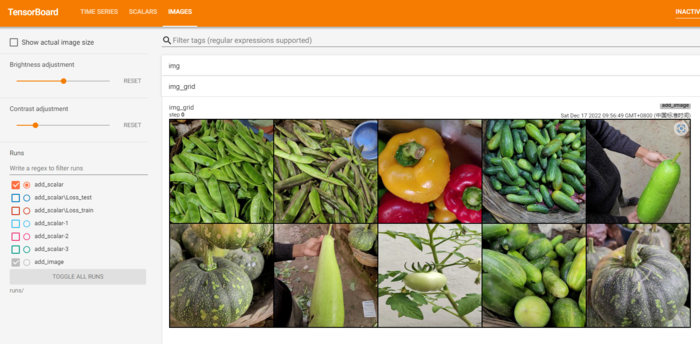
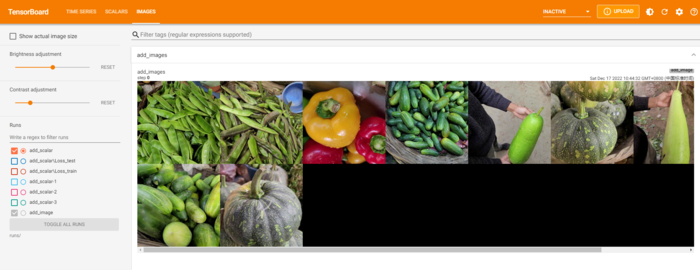
(2) add_images
add_images是tensorboard中提供直接一次性记录多张图片的方法,此方法参数与add_image基本一致,区别就在于记录的数据是多张图片组成的torch.Tensor或numpy.array, 数据的shape为(N,3,H,W),其中N为图片数量。
path_lst = [os.path.join('images', i) for i in os.listdir('images')]
img_lst = []
for i, img in enumerate(path_lst):
img = read_image(img)
img_lst.append(img)
imgs_tensor = torch.stack(img_lst,0)
writer = SummaryWriter('runs/add_image')
writer.add_images('add_images', imgs_tensor)
writer.close()
3.3 模型结构¶
使用add_graph方法,可以绘制模型结构:
-
model (torch.nn.Module) :需要绘制的模型
-
input_to_model (torch.Tensor or list of torch.Tensor):传递给模型的一个数据
-
verbose (bool) :是否同时在命令行中绘制
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
先定义一个模型:
class Net1(nn.Module):
def __init__(self):
super(Net1, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
self.bn = nn.BatchNorm2d(20)
def forward(self, x):
x = F.max_pool2d(self.conv1(x), 2)
x = F.relu(x) + F.relu(-x)
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = self.bn(x)
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
x = F.softmax(x, dim=1)
return x
dummy_input = Variable(torch.rand(13, 1, 28, 28))
model = Net1()
with SummaryWriter('runs/Net1') as w:
w.add_graph(model, (dummy_input, ))
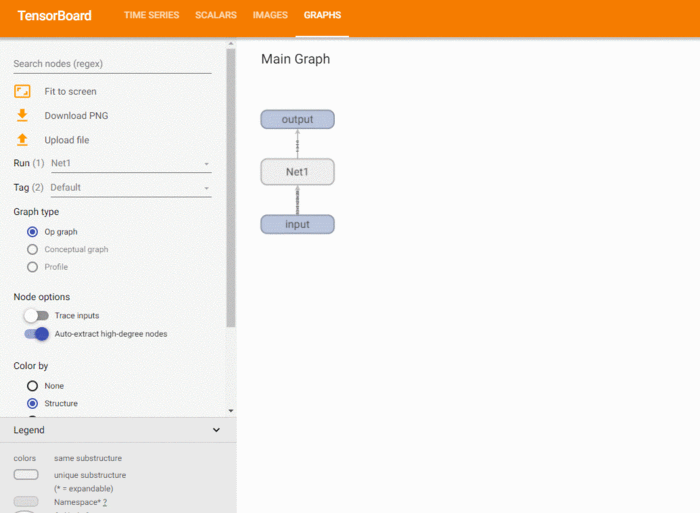
关于add_graph的例子,可以参考这里。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:Pytorch优化过程展示:tensorboard - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 