pandas的级联和合并
级联操作
pd.concat,pd.append
pandas使用pd.concat函数,与np.concatenate函数类似,只是多了一些参数:
objs
axis=0
keys
join='outer' / 'inner':表示的是级联的方式,outer会将所有的项进行级联(忽略匹配和不匹配),而inner只会将匹配的项级联到一起,不匹配的不级联
ignore_index=False
-
匹配级联
df1 = pd.DataFrame(data=np.random.randint(0,100,size=(5,3)),columns=['A','B','C']) df2 = pd.DataFrame(data=np.random.randint(0,100,size=(5,3)),columns=['A','D','C']) pd.concat((df1,df1),axis=1) #行列索引都一致的级联叫做匹配级联

-
不匹配级联
-
不匹配指的是级联的维度的索引不一致。例如纵向级联时列索引不一致,横向级联时行索引不一致
-
有2种连接方式:
-
外连接:补NaN(默认模式)
pd.concat((df1,df2),axis=0) or pd.concat((df1,df2),axis=1, join='outer')
-
内连接:只连接匹配的项
pd.concat((df1,df2),axis=0,join='inner') #inner直把可以级联的级联不能级联不处理
-
如果想要保留数据的完整性必须使用outer(外连接)
-
append函数的使用
-
-
-
-
append函数的使用
df1.append(df1)
合并操作
- merge与concat的区别在于merge需要依据某一共同列来进行合并
- 使用pd.merge()合并时,会自动根据两者相同column名称的那一列,作为key来进行合并。
- 注意每一列元素的顺序不要求一致
df1 = DataFrame({'employee':['regina','ivanlee','baby'],
'group':['Accounting','Engineering','Engineering'],
})
df2 = DataFrame({'employee':['regina','ivanlee','baby'],
'hire_date':[2004,2008,2012],
})
pd.merge(df1,df2,on='employee')

一对多合并
df3 = DataFrame({
'employee':['regina','ivanlee'],
'group':['Accounting','Engineering'],
'hire_date':[2004,2016]})
df4 = DataFrame({'group':['Accounting','Engineering','Engineering'],
'supervisor':['Carly','Guido','Steve']
})
pd.merge(df3,df4)#on如果不写,默认情况下使用两表中公有的列作为合并条件

多对多合并
df5 = DataFrame({'group':['Accounting','Engineering','HR'],
'supervisor':['Carly','Guido','Steve']
})
how 参数默认是inner,也可以是outer,right,left
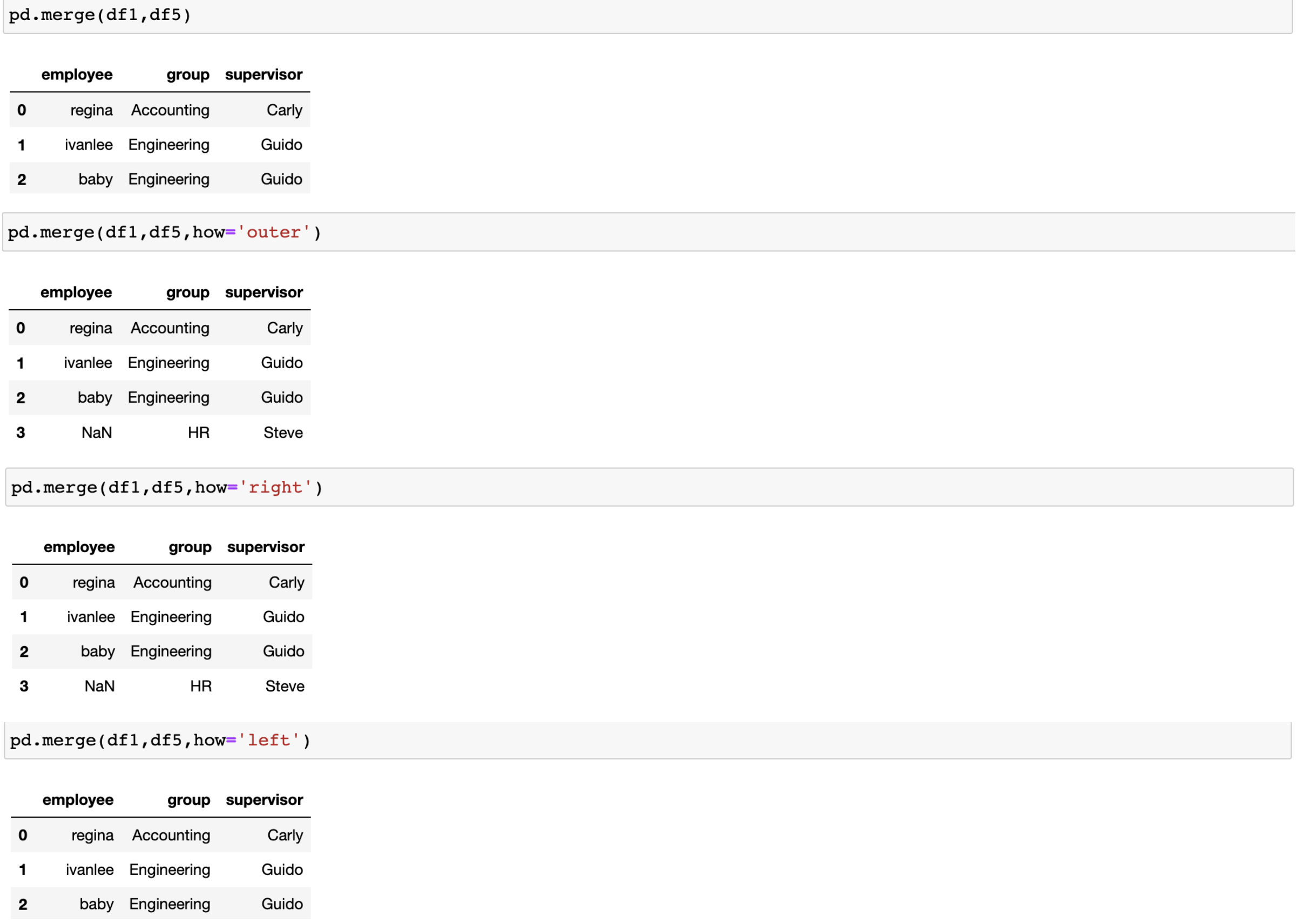
key的规范化
-
当两张表没有可进行连接的列时,可使用left_on和right_on手动指定merge中左右两边的哪一列列作为连接的列
df5 = DataFrame({'name':['ivanlee','zjr','liyifan'], 'hire_dates':[1998,2016,2007]}) pd.merge(df1,df5,left_on='employee',right_on='name')
内合并与外合并:out取并集 inner取交集
人口分析项目
- 需求:
- 导入文件,查看原始数据
- 将人口数据和各州简称数据进行合并
- 将合并的数据中重复的abbreviation列进行删除
- 查看存在缺失数据的列
- 找到有哪些state/region使得state的值为NaN,进行去重操作
- 为找到的这些state/region的state项补上正确的值,从而去除掉state这一列的所有NaN
- 合并各州面积数据areas
- 我们会发现area(sq.mi)这一列有缺失数据,找出是哪些行
- 去除含有缺失数据的行
- 找出2010年的全民人口数据
- 计算各州的人口密度
- 排序,并找出人口密度最高的州
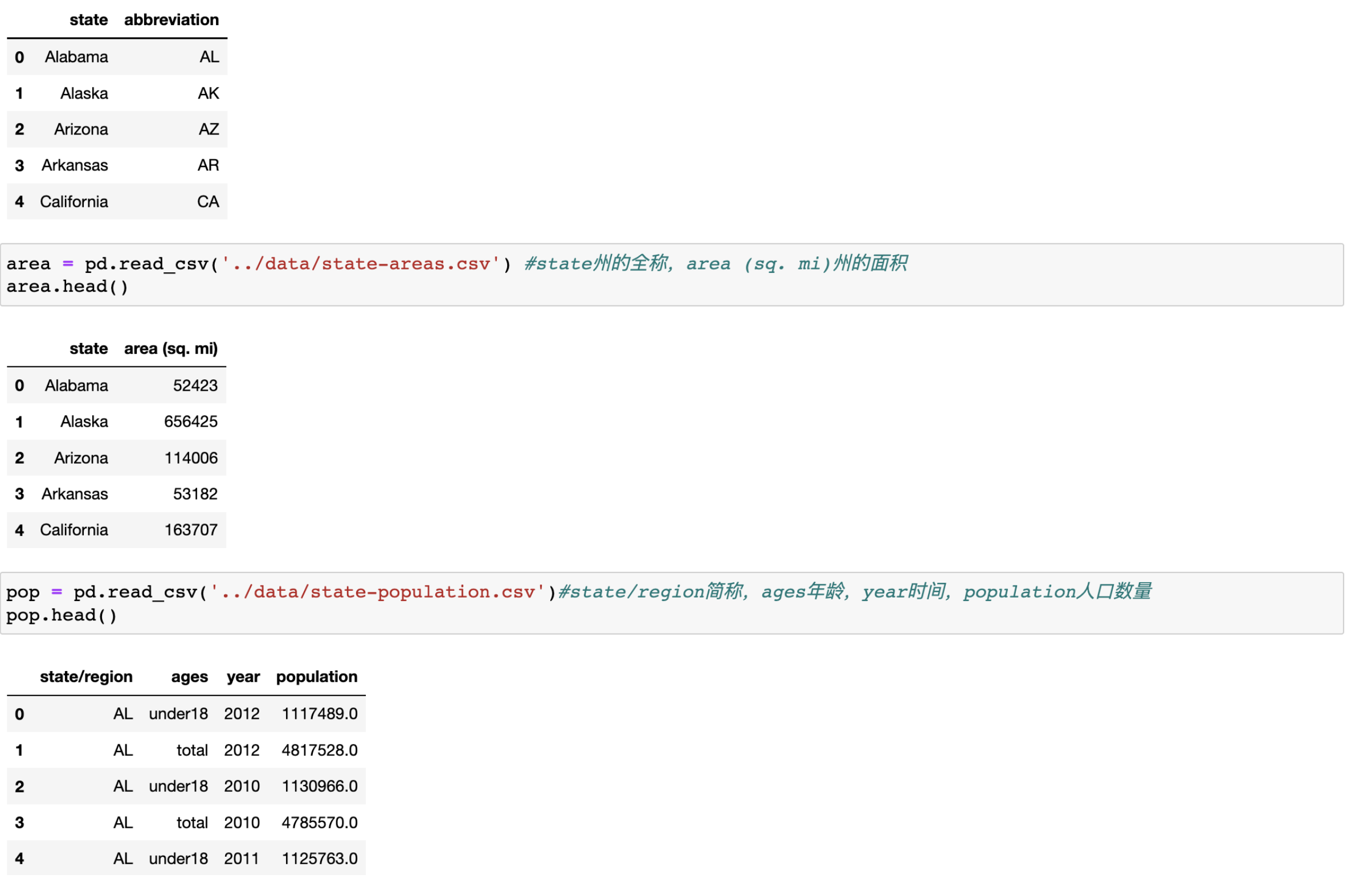
#导入文件,查看原始数据
abb = pd.read_csv('../data/state-abbrevs.csv') #state(州的全称)abbreviation(州的简称)
area = pd.read_csv('../data/state-areas.csv') #state州的全称,area (sq. mi)州的面积
pop = pd.read_csv('../data/state-population.csv')#state/region简称,ages年龄,year时间,population人口数量
#将人口数据和各州简称数据进行合并
abb_pop = pd.merge(abb,pop,left_on='abbreviation',right_on='state/region',how='outer') 必须保证数据完整
abb_pop.head()

#将合并的数据中重复的abbreviation列进行删除
abb_pop.drop(labels='abbreviation',axis=1,inplace=True)
#查看存在缺失数据的列
#方式1:isnull,notll,any,all
abb_pop.isnull().any(axis=0)
#state,population这两列中是存在空值

#1.将state中的空值定位到
abb_pop['state'].isnull()
#2.将上述的布尔值作为源数据的行索引
abb_pop.loc[abb_pop['state'].isnull()]#将state中空对应的行数据取出
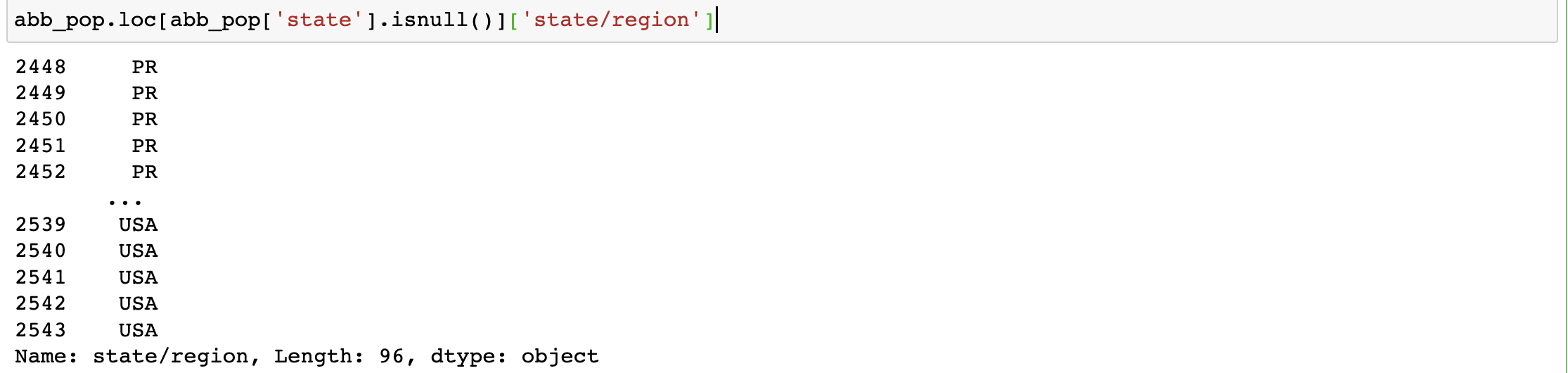
#3.将简称取出
abb_pop.loc[abb_pop['state'].isnull()]['state/region']
#4.对简称去重
abb_pop.loc[abb_pop['state'].isnull()]['state/region'].unique()
#结论:只有PR和USA对应的全称数据为空值
#为找到的这些state/region的state项补上正确的值,从而去除掉state这一列的所有NaN
#思考:填充该需求中的空值可不可以使用fillna?
# - 不可以。fillna可以使用空的紧邻值做填充。fillna(value='xxx')使用指定的值填充空值
# 使用给元素赋值的方式进行填充!
#1.先给USA的全称对应的空值进行批量赋值
abb_pop.loc[abb_pop['state/region'] == 'USA']#将usa对应的行数据取出
#1.2将USA对应的全称空对应的行索引取出
indexs = abb_pop.loc[abb_pop['state/region'] == 'USA'].index
abb_pop.iloc[indexs]
abb_pop.loc[indexs,'state'] = 'United States'
#2.可以将PR的全称进行赋值
abb_pop['state/region'] == 'PR'
abb_pop.loc[abb_pop['state/region'] == 'PR'] #PR对应的行数据
indexs = abb_pop.loc[abb_pop['state/region'] == 'PR'].index
abb_pop.loc[indexs,'state'] = 'PPPRRR'
#合并各州面积数据areas
abb_pop_area = pd.merge(abb_pop,area,how='outer')
#我们会发现area(sq.mi)这一列有缺失数据,找出是哪些行
abb_pop_area['area (sq. mi)'].isnull()
abb_pop_area.loc[abb_pop_area['area (sq. mi)'].isnull()] #空对应的行数据
indexs = abb_pop_area.loc[abb_pop_area['area (sq. mi)'].isnull()].index
#找出2010年的全民人口数据(基于df做条件查询)
abb_pop_area.query('ages == "total" & year == 2010')
#计算各州的人口密度(人口除以面积)
abb_pop_area['midu'] = abb_pop_area['population'] / abb_pop_area['area (sq. mi)']
abb_pop_area
#排序,并找出人口密度最高的州
abb_pop_area.sort_values(by='midu',axis=0,ascending=False).iloc[0]['state']
替换操作
-
替换操作可以同步作用于Series和DataFrame中
-
单值替换
- 普通替换: 替换所有符合要求的元素:to_replace=15,value='e'
- 按列指定单值替换: to_replace={列标签:替换值} value='value'
-
多值替换
- 列表替换:
to_replace=[] value=[] - 字典替换(推荐)
to_replace={to_replace:value,to_replace:value}
- 列表替换:

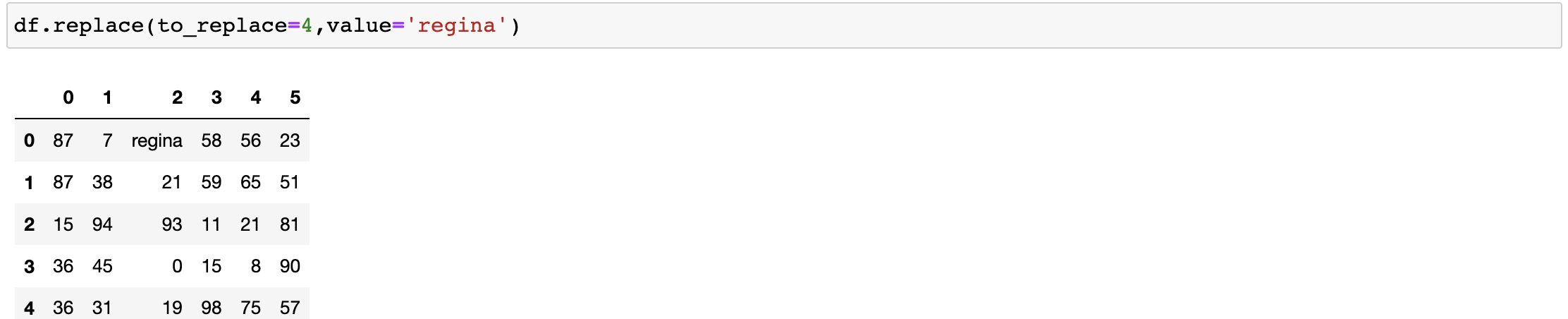
我们要替换某列当中的数值
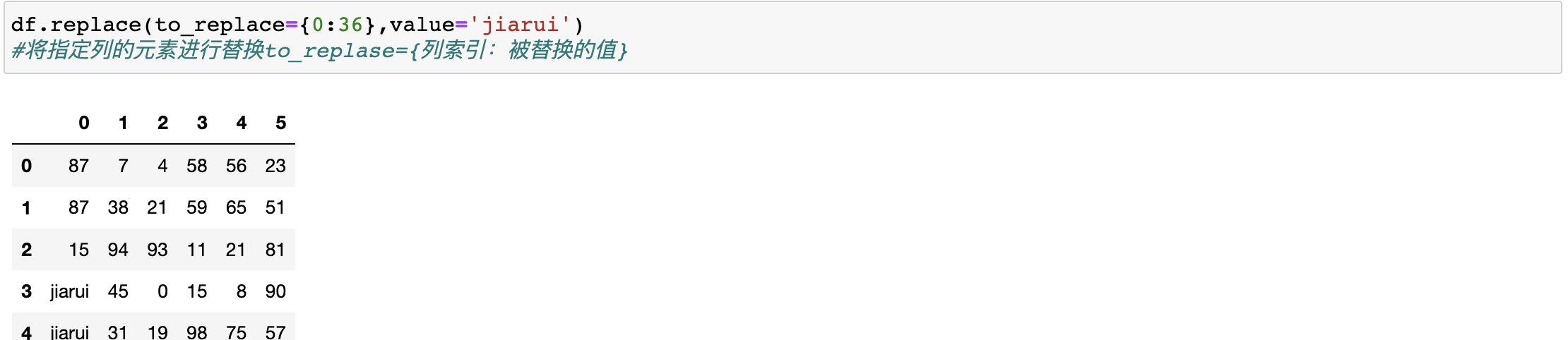
df.replace(to_replace={0,36},value='jiarui')
#将指定列的元素进行替换to_replase={列索引:被替换的值}
映射操作
-
概念:创建一个映射关系列表,把values元素和一个特定的标签或者字符串绑定(给一个元素值提供不同的表现形式)
-
创建一个df,两列分别是姓名和薪资,然后给其名字起对应的英文名
dic = {
'name':['regina','ivanlee','regina'],
'salary':[15000,20000,15000]
}
df = DataFrame(data=dic)

先指定给regina映射为zhangjiarui,首先建立一张映射关系表
#映射关系表
dic = {
'regina':'zhangjiarui',
'ivanlee':'liyifan'
}
df['e_name'] = df['name'].map(dic)

map是Series的方法,只能被Series调用
运算工具
-
超过3000部分的钱缴纳50%的税,计算每个人的税后薪资
#该函数是我们指定的一个运算法则 def after_sal(s):#计算s对应的税后薪资 return s - (s-3000)*0.5 df['after_sal'] = df['salary'].map(after_sal)#可以将df['salary']这个Series中每一个元素(薪资)作为参数传递给s
排序实现的随机抽样
- take()
- np.random.permutation()
df = DataFrame(data=np.random.randint(0,100,size=(100,3)),columns=['A','B','C'])
#生成乱序的随机序列
np.random.permutation(10)
#将原始数据打乱
df.take([2,0,1],axis=1)
df.take(np.random.permutation(3),axis=1)
数据的分类处理
- 数据分类处理的核心:
- groupby()函数
- groups属性查看分组情况
df = DataFrame({'item':['Apple','Banana','Orange','Banana','Orange','Apple'],
'price':[4,3,3,2.5,4,2],
'color':['red','yellow','yellow','green','green','green'],
'weight':[12,20,50,30,20,44]})

#想要水果的种类进行分析
df.groupby(by='item')
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x7fac66bd1b20>
#查看详细的分组情况
df.groupby(by='item').groups

-
分组聚合
#计算出每一种水果的平均价格 df.groupby(by='item')['price'].mean() out: item Apple 3.00 Banana 2.75 Orange 3.50 Name: price, dtype: float64#计算每一种颜色对应水果的平均重量 df.groupby(by='color')['weight'].mean() out: color green 31.333333 red 12.000000 yellow 35.000000 Name: weight, dtype: float64dic = df.groupby(by='color')['weight'].mean().to_dict() #将计算出的平均重量汇总到源数据 df['mean_w'] = df['color'].map(dic)
高级数据聚合
- 使用groupby分组后,也可以使用transform和apply提供自定义函数实现更多的运算
df.groupby('item')['price'].sum() <==> df.groupby('item')['price'].apply(sum)- transform和apply都会进行运算,在transform或者apply中传入函数即可
- transform和apply也可以传入一个lambda表达式
def my_mean(s):
m_sum = 0
for i in s:
m_sum += i
return m_sum / len(s)
可以通过自定义的方式设计一个聚合操作
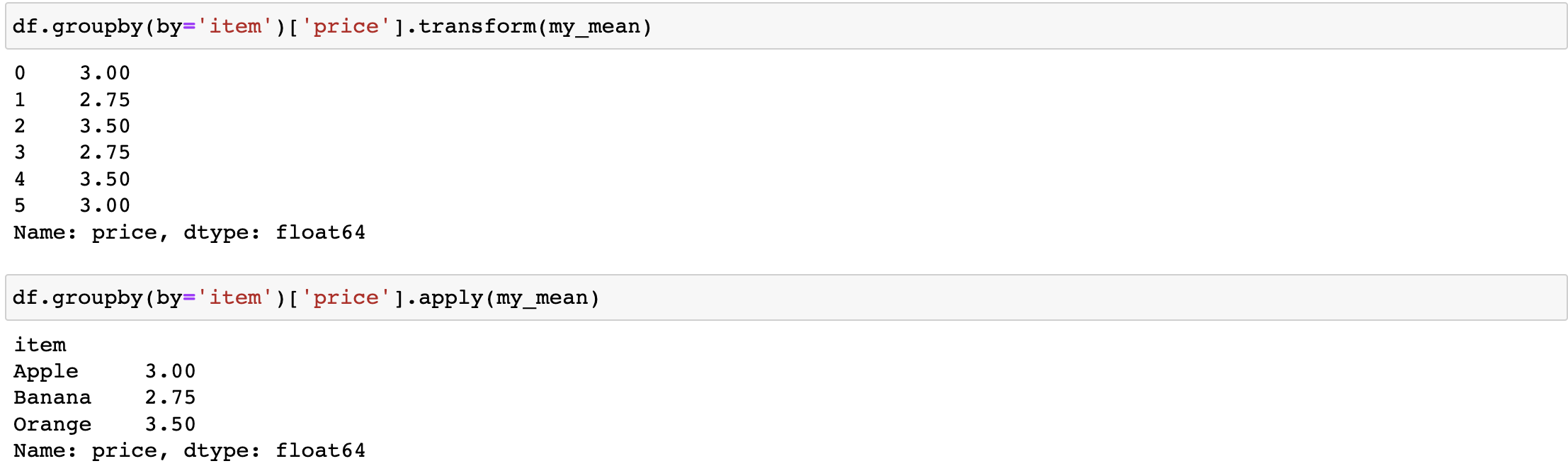
df.groupby(by='item')['price'].transform(my_mean) #经过映射
df.groupby(by='item')['price'].apply(my_mean) #不经过映射
数据加载
-
读取type-.txt文件数据
 第一行被认成了列索引
第一行被认成了列索引 -
将文件中每一个词作为元素存放在DataFrame中
pd.read_csv('../data/type-.txt',header=None,sep='-') 原始的第一句话就不再是列索引
-
读取数据库中的数据
#连接数据库,获取连接对象 import sqlite3 as sqlite3 conn = sqlite3.connect('../data/weather_2012.sqlite') #读取库表中的数据值 sql_df=pd.read_sql('select * from weather_2012',conn)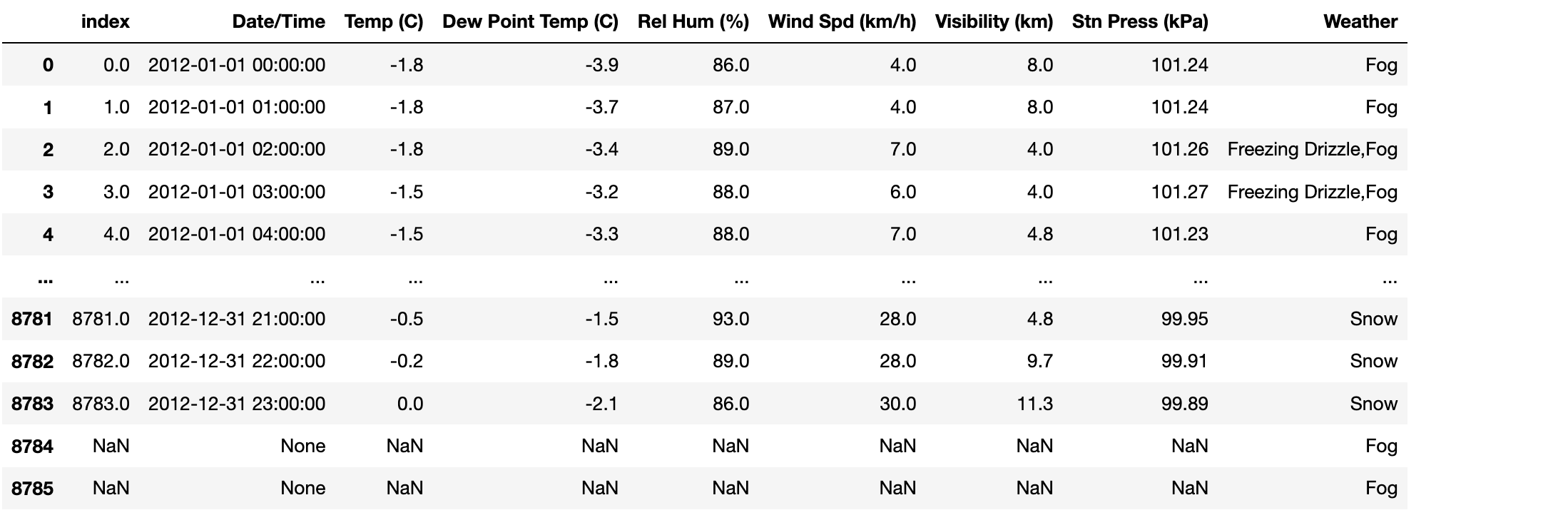
#将一个df中的数据值写入存储到db df.to_sql('sql_data456',conn)
透视表
-
透视表是一种可以对数据动态排布并且分类汇总的表格格式。或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table。
-
透视表的优点:
- 灵活性高,可以随意定制你的分析计算要求
- 脉络清晰易于理解数据
- 操作性强,报表神器
pivot_table有四个最重要的参数index、values、columns、aggfunc
-
index参数:分类汇总的分类条件
- 每个pivot_table必须拥有一个index。如果想查看对阵每个队伍的得分则需要对每一个队进行分类并计算其各类得分的平均值:
-
想看看对阵同一对手在不同主客场下的数据,分类条件为对手和主客场
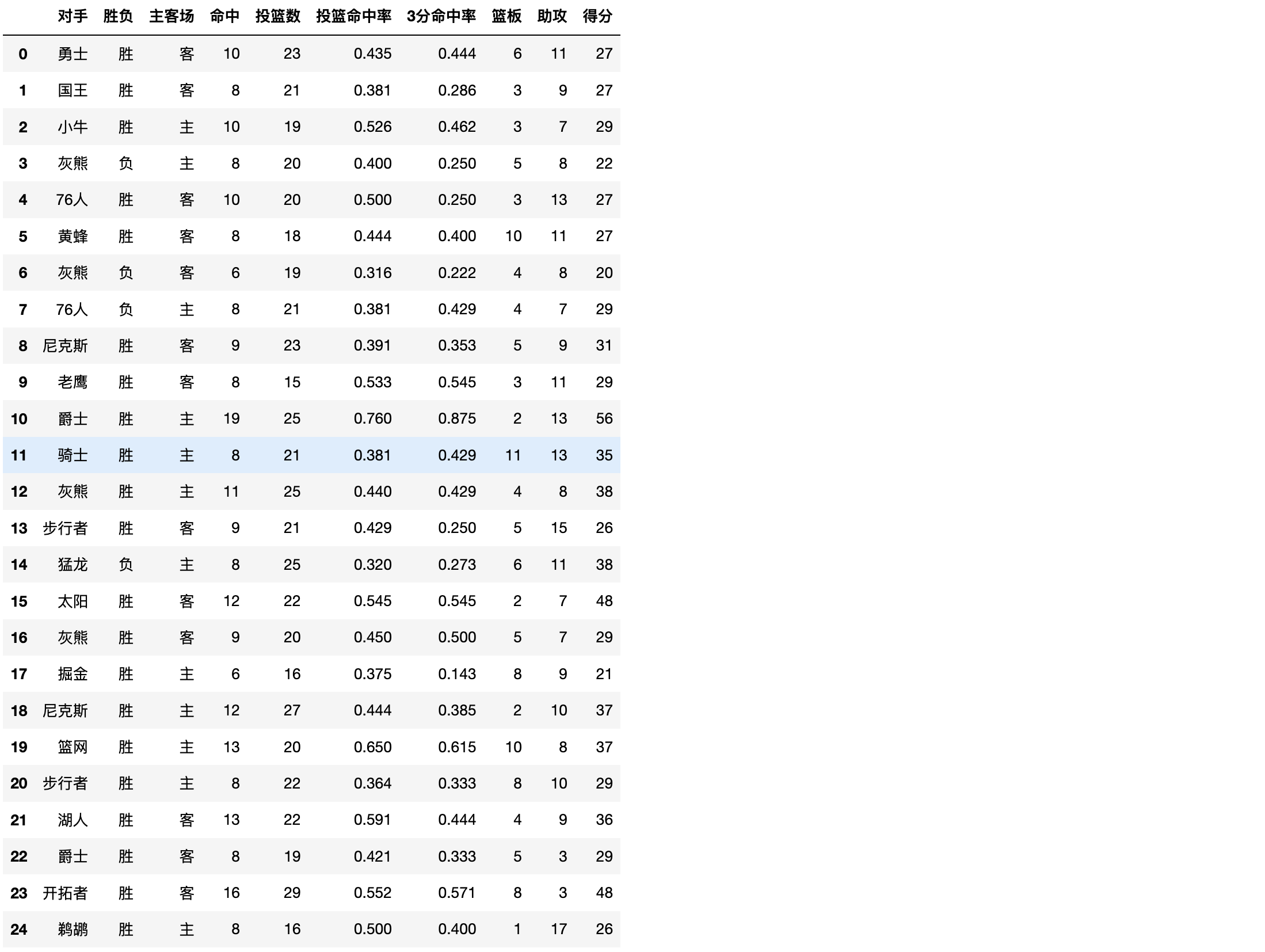
df.pivot_table(index=['对手','主客场'])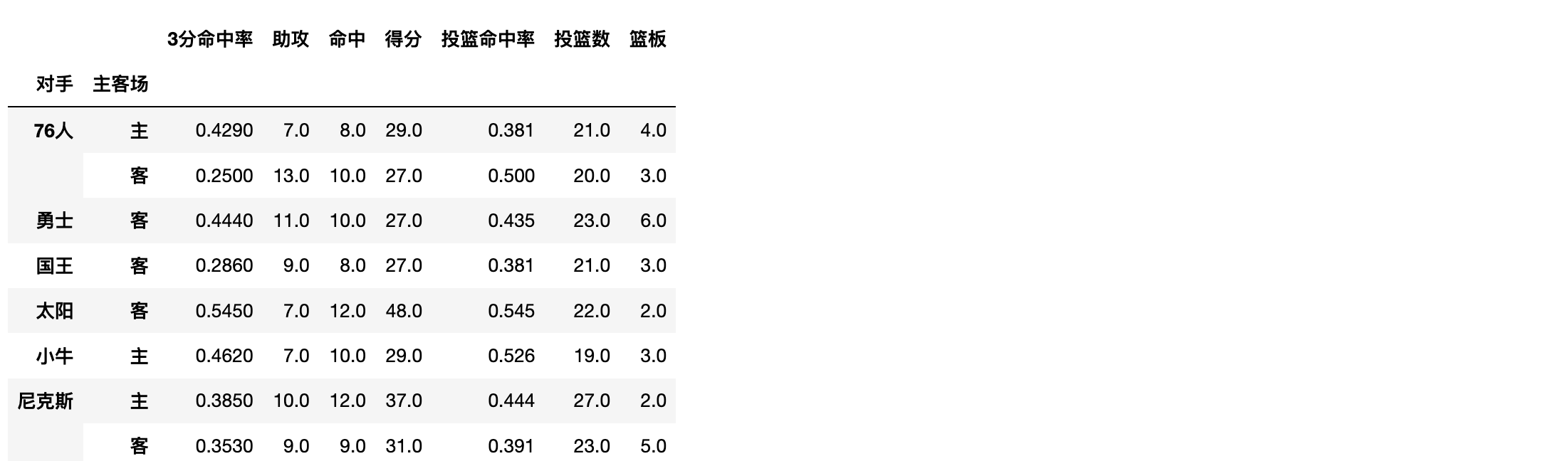
-
values参数:需要对计算的数据进行筛选
-
如果我们只需要在主客场和不同胜负情况下的得分、篮板与助攻三项数据:
df.pivot_table(index=['主客场','胜负'],values=['得分','篮板','助攻'])
-
-
Aggfunc参数:设置我们对数据聚合时进行的函数操作
- 当我们未设置aggfunc时,它默认aggfunc='mean'计算均值。
- 还想获得主客场和不同胜负情况下的总得分、总篮板、总助攻时:
df.pivot_table(index=['主客场','胜负'],values=['得分','篮板','助攻'],aggfunc='sum')

-
Columns:可以设置列层次字段
- 对values字段进行分类
#获取所有队主客场的总得分 df.pivot_table(index='主客场',values='得分',aggfunc='sum')
#获取每个队主客场的总得分(在总得分的基础上又进行了对手的分类) df.pivot_table(index='主客场',values='得分',columns='对手',aggfunc='sum',fill_value=none)
交叉表
- 是一种用于计算分组的特殊透视图,对数据进行汇总
pd.crosstab(index,colums)- index:分组数据,交叉表的行索引
- columns:交叉表的列索引

#求出不同性别的抽烟人数
pd.crosstab(df.smoke,df.sex)

本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:pandas替换,加载,透视表 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 