1.什么是爬虫
爬虫就是爬取网页数据,只要网页上有的,都可以通过爬虫爬取下来,比如图片、文字评论、商品详情等。
一般二言,Python爬虫需要以下几步:
- 找到网页URL,发起请求,等待服务器响应
- 获取服务器响应内容
- 解析内容(正则表达式、xpath、bs4等)
- 保存数据(本地文件、数据库等)
2.爬虫的基本流程
- 找到网页URL,发起请求,等待服务器响应
- 获取服务器响应内容
- 解析内容(正则表达式、xpath、bs4等)
- 保存数据(本地文件、数据库等)
3.正则表达式贪婪与非贪婪模式的区别
1)什么是贪婪匹配与非贪婪匹配
- 贪婪匹配在匹配字符串时总是尝试匹配尽可能多的字符
- 与贪婪匹配相反,非贪婪匹配在匹配字符串时总是尝试匹配尽可能少的字符
2)区别
- 在形式上,非贪婪模式有一个“?”作为该部分的结束标志
- 在功能上,贪婪模式是尽可能多的匹配当前正则表达式,可能会包含好几个满足正则表达式的字符串;非贪婪模式,在满足所有正则表达式的情况下尽可能少的匹配当前正则表单式
3)拓展
- *? 重复任意次,但尽可能少重复
- +? 重复1次或更多次,但尽可能少重复
- ?? 重复0次或1次,但尽可能少重复
- {n,m}? 重复n到m次,但尽可能少重复
- {n,}? 重复n次以上,但尽可能少重复
4.re模块中match与search的区别
1)相同点:都是在一个字符串中寻找子字符串,如果能找到,就返回一个Match对象,如果找不到,就返回None。
2)不同点:mtach() 方法是从头开始匹配,而 search() 方法,可以在字符串的任一位置查找。
5.正则表达式如何实现字符串的查找和替换
1)查找:findall()函数
re.findall(r"目标字符串",“原有字符串”) re.findall(r"张三",“I love 张三”)[0]
2)替换:sub()函数
re.sub(r"要替换原字符",“要替换新字符”,“原始字符串”) re.sub(r"李四",“python”,“I love 李四”)
6.写出匹配ip的正则表达式
1)ip 地址格式:(1-255).(0-255).(0-255).(0-255)
2)对应的正则表达式
- "^(1\d{2}|2[0-4]\d|25[0-5]|[1-9]\d|[1-9])\."
- +"(1\d{2}|2[0-4]\d|25[0-5]|[1-9]\d|\d)\."
- +"(1\d{2}|2[0-4]\d|25[0-5]|[1-9]\d|\d)\."
- +"(1\d{2}|2[0-4]\d|25[0-5]|[1-9]\d|\d)$"
3)解析
- \d 表示 0~9 的任何一个数字
- {2} 表示正好出现两次
- [0-4] 表示 0~4 的任何一个数字
- | 或者
- 小括号( )不能少,是为了提取匹配的字符串,表达式中有几个()就表示有几个相应的匹配字符串
- 1\d{2}:100~199之间的任意一个数字
- 2[0-4]\d:200~249之间的任意一个数
- 25[0-5]:250~255之间的任意一个数字
- [1-9]\d:10~99之间的任意一个数字
- [1-9]:1~9之间的任意一个数字
- \.:转义点号.
7.写一个邮箱地址的正则表达式
[A-Za-z0-9_-]+@[a-zA-Z0-9_-]+(.[a-zA-Z0-9_-]+)+$
8.group和groups的区别
- 1)m.group(N) 返回第N组匹配的字符
- 2)m.group() == m.group(0) == 所有匹配的字符
- 3)m.groups() 返回所有匹配的字符,以tuple(元组)格式
- m.groups() == (m.group(0), m.group(1),……)
9.requests请求返回的content和text的区别
1)返回类型不同
response.text 返回的是 Unicode 型数据,response.content 返回的是 bytes 类型,也就是二进制数据
2)使用场景不同
获取文本使用,response.text,获取图片和文件,使用 response.content
3)修改编码方式不同
- response.text类型:str,根据 HTTP 头部对响应的编码作出有根据的推测
- 修改编码方式:response.encoding=”gbk”
- response.content类型:bytes,没有指定解码类型
- 修改编码方式:response.content.decode(“utf8”)
10.urllib和requests模块的区别
1)urllib是python内置的包,不需要单独安装
2)requests是第三方库,需要单独安装
3)requests库是在urllib的基础上封装的,比urllib模块更加好用
4)requests可以直接发起get、post请求,urllib需要先构建请求,然后再发起请求
11.为什么requests请求需要带上header?
1)原因:模拟浏览器,欺骗服务器,获取和浏览器一致的内容
2)header格式:字典
headers = {“User-Agent”: “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36”}
3)用法:requests.get(url, headers=headers)
12.requests模块有哪些使用小技巧?
1)reqeusts.util.dict_from_cookiejar 把 cookie 对象转化为字典
2)设置请求不用 SSL 证书验证
response = requests.get("https://www.12306.cn/mormhweb/ ", verify=False)
3)设置超时
response = requests.get(url, timeout=10)
4)配合状态码判断是否请求成功
response.status_code == 200
13.json模块dumps、loads与dump、load方法的区别
- json.dumps(),将 python 的 dict 数据类型编码为 json 字符串
- json.loads(),将 json 字符串解码为 dict 的数据类型
- json.dump(x, y),x 是 json 对象,y 是文件对象,最终是将 json 对象写入到文件中
- json.load(y),从文件对象 y 中读取 json 对象
14.常见的HTTP请求方法有哪些?
- GET:请求指定的页面信息,返回实体主体
- HEAD:类似于get请求,只不过返回的响应中没有具体的内容,用于捕获报头
- POST:向指定资源提交数据进行处理请求(比如表单提交或者上传文件),数据被包含在请求体中
- PUT:从客户端向服务端传送数据取代指定的文档的内容
- DELETE:请求删除指定的页面
- CONNNECT:HTTP1.1协议中预留给能够将连接方式改为管道方式的代理服务器
- OPTIONS:允许客户端查看服务器的性能; TRACE:回显服务器的请求,主要用于测试或者诊断
15.HTTPS协议有什么优点和缺点?
1)优点
- 使用 HTTPS 协议可认证用户和服务器,确保数据发送到正确的客户机和服务器
- HTTPS 协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议,要比 http协议安全,可防止数据在传输过程中不被窃取、改变,确保数据的完整性
- HTTPS 是现行架构下最安全的解决方案,虽然不是绝对安全,但它大幅增加了中间人攻击的成本
2)缺点
- HTTPS 协议的加密范围也比较有限,在黑客攻击、拒绝服务攻击、服务器劫持等方面几乎起不到什么作用
- HTTPS 协议还会影响缓存,增加数据开销和功耗,甚至已有安全措施也会受到影响也会因此而受到影响
- SSL 证书需要钱,功能越强大的证书费用越高,个人网站、小网站没有必要一般不会用
- HTTPS 连接服务器端资源占用高很多,握手阶段比较费时对网站的相应速度有负面影响
- HTTPS 连接缓存不如 HTTP 高效
16.HTTP通信组成
HTTP通信由两部分组成:客户端请求消息与服务器响应消息。
17.robots.txt协议文件有什么作用?
搜索引擎访问一个网站的时候,最先访问的文件就是robots.txt,网站通过 Robots 协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
18.robots.txt文件放在哪里?
此文件需放置在网站的根目录,且对字母大小写有限制,文件名必须为小写字母。所有的命令第一个字母需大写,其余的小写,且命令之后要有一个英文字符空格。

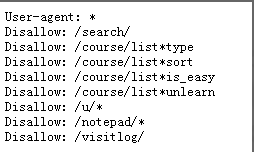
19.怎么书写Robots协议?
- User-agent:表示定义哪个搜索引擎,如User-agent:Baiduspider,定义百度
- Disallow:表示禁止访问
- Allow:表示运行访问
20.谈谈你对多进程,多线程,以及协程的理解,项目中是否使用?
- 进程:一个运行的程序(代码)就是一个进程,没有运行的代码叫程序,进程是系统资源分配的最小单位,进程拥有自己独立的内存空间,所以进程间数据不共享,开销大。
- 线程:调度执行的最小单位,也叫执行路径,不能独立存在,依赖进程存在一个进程至少有一个线程,叫主线程,而多个线程共享内存(数据共享,共享全局变量),从而极大地提高了程序的运行效率。
- 协程:是一种用户态的轻量级线程,协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
- 项目中有使用多线程爬取数据,提升效率。
21.线程的执行顺序
- 新建:线程创建(t=threading.Thread(target=方法名)或者线程类)
- 就绪:当启动线程后,线程就进入就绪状态,就绪状态的线程会被放到一个CPU调度队列里面,cpu会负责让其中的线程运行,变为运行状态
- 运行状态:CPU调度一个就绪状态的线程,该线程就变为运行状态
- 阻塞状态:当运行状态的线程被阻塞变为阻塞状态,阻塞状态的线程就会重新变为就绪状态才能继续运行
- 死亡状态:线程执行完毕
22.多线程和多进程的优缺点
1)多线程的优点
- 程序逻辑和控制方式复杂
- 所有线程可以直接共享内存和变量
- 线程方式消耗的总资源比进程方式好
2)多线程缺点
- 每个线程与主程序共用地址空间,受限于2GB地址空间
- 线程之间的同步和加锁控制比较麻烦
- 一个线程的崩溃可能影响到整个程序的稳定性
3)多进程优点
- 每个进程互相独立,不影响主程序的稳定性,子进程崩溃没关系
- 通过增加CPU,就可以容易扩充性能
- 每个子进程都有2GB地址空间和相关资源,总体能够达到的性能上限非常大
4)多进程缺点
- 逻辑控制复杂,需要和主程序交互
- 需要跨进程边界,如果有大数据量传送,就不太好,适合小数据量传送、密集运算
- 多进程调度开销比较大
在实际开发中,选择多线程和多进程应该从具体实际开发来进行选择,最好是多进程和多线程结合。
23.写爬虫是用多进程好?还是多线程好?为什么?
IO 密集型代码(文件读写处理、网络爬虫等),多线程能够有效地提升效率。单线程下有 IO 操作会进行 IO 等待,造成不必要的时间浪费,而开启多线程能在线程 A 等待时,自动切换到线程 B,可以不浪费 CPU等资源,从而能提升程序执行效率。
在实际的数据采集过程中,既考虑网速和响应的问题,也需要考虑自身机器的硬件情况,来设置多进程或多线程。
多进程适合在 CPU 密集型操作(cpu 操作指令比较多,如位数多的浮点运算)。多线程适合在 IO 密集型操作(读写数据操作较多的,比如爬虫)。
24.什么是多线程竞争?
线程是非独立的,同一个进程里线程是数据共享的,当各个线程访问数据资源时会出现竞争状态,即数据几乎同步会被多个线程占用,造成数据混乱,即所谓的线程不安全。
那么怎么解决多线程竞争问题? ——锁。
25.什么是锁,以及锁的优劣之处
锁(Lock)是 Python 提供的对线程控制的对象。
- 锁的好处:确保了某段关键代码(共享数据资源)只能由一个线程从头到尾完整地执行,能解决多线程资源竞争的问题。
- 锁的坏处:阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了。
- 锁的致命问题:死锁。
26.什么是死锁?
若干子线程在系统资源竞争时,都在等待对方对某部分资源解除占用状态,结果是谁也不愿先解锁,互相干等着,程序无法执行下去,这就是死锁。
27.XPath解析数据使用什么库
XPath解析数据需要依赖于lxml库。
28.用于网络爬虫的XPath的主要语法
- . 选取当前节点
- … 选取当前节点的父节点
- @ 选取属性
- * 任意匹配,//div/*,div下的任意元素
- // 从匹配选择的当前节点选择文档中的节点,不考虑他们的位置
- //div 选取所有的div
- //div[@class=”demo”] 选取class为demo的div节点
29.Mysql,Mongodb,redis三个数据库的理解
1)MySQL 数据库:开源免费的关系型数据库,需要实现创建数据库、数据表和表的字段,表与表之间可以进行关联(一对多、多对多),是持久化存储
2)Mongodb 数据库:是非关系型数据库,数据库的三元素是,数据库、集合、文档,可以进行持久化存储,也可作为内存数据库,存储数据不需要事先设定格式,数据以键值对的形式存储。
3)redis 数据库:非关系型数据库,使用前可以不用设置格式,以键值对的方式保存,文件格式相对自由,主要用与缓存数据库,也可以进行持久化存储
30.MongoDB常见命令
- use yourDB; 切换/创建数据库
- show dbs; 查询所有数据库
- db.dropDatabase(); 删除当前使用数据库
- db.getName(); 查看当前使用的数据库
- db.version(); 当前 db 版本
- db.addUser(“name”); 添加用户,db.addUser(“userName”, “pwd123”, true);
- show users; 显示当前所有用户
- db.removeUser(“userName”); 删除用户
- db.collectionName.count(); 查询当前集合的数据条数
- db.collectionName.find({key:value}); 查询数据
31.爬虫项目为什么使用MongoDB,而不使用MySQL数据库
1)MySQL属于关系型数据库,它具有以下特点:
- 在不同的引擎上有不同的存储方式
- 查询语句是使用传统的sql语句,拥有较为成熟的体系,成熟度很高
- 开源数据库的份额在不断增加,MySQL的份额也在持续增长
- 处理海量数据的效率会显著变慢
2)Mongodb属于非关系型数据库,它具有以下特点:
- 数据结构由键值对组成
- 存储方式:虚拟内存+持久化
- 查询语句是独特的Mongodb的查询方式
- 具备高可用性
- 数据是存储在硬盘上的,只不过需要经常读取的数据会被加载到内存中,将数据存储在物理内存中,从而达到高速读写
32.MongoDB的优点
面向文件、高性能、高可用、易扩展、可分片、对数据存储友好。
33.MongoDB支持哪些数据类型?
- String、Integer、Double、Boolean
- Object、Object ID
- Arrays
- Min/Max Keys
- Code、Regular Expression等
34.MongoDB "Object ID"由哪些部分组成?
"Object ID"数据类型用于存储文档id
一共有四部分组成:时间戳、客户端ID、客户进程ID、三个字节的增量计数器
35.Redis数据库支持哪些数据类型?
1)String:String 是 Redis 最为常用的一种数据类型,String 的数据结构为 key/value 类型,String 可以包含任何数据。常用命令有set、get、decr、incr、mget等。
2)Hash:Hash 类型可以看成是一个 key/value 都是 String 的 Map 容器。常用命令有hget、hset、hgetall等。
3)List:List 用于存储一个有序的字符串列表,常用的操作是向队列两端添加元素或者获得列表的某一片段。常用命令有lpush、rpush、lpop、rpop、lrange等。
4)Set:Set 可以理解为一组无序的字符集合,Set 中相同的元素是不会重复出现的,相同的元素只保留一个。常用命令有sadd、spop、smembers、sunion等。
5)Sorted Set(有序集合):有序集合是在集合的基础上为每一个元素关联一个分数,Redis 通过分数为集合中的成员进行排序。常用命令有zadd、zrange、zrem、zcard等。
36.Redis有多少个库?
Redis 一个实例下有 16 个库,默认使用 0 库,select 1 可以切换到 1 库。
37.谈谈Selenium框架
Selenium 是一个 Web 的自动化测试工具,可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。Selenium 自己不带浏览器,不支持浏览器的功能,它需要与Firefox、chrome等第三方浏览器结合在一起才能使用,需要先下载浏览器的Driver。
38.selenium有几种元素定位方式,你最常用哪种?
1)selenium有八种定位方式
- 和name有关的:ByName、ByClassName、ByTagName
- 和link有关的:ByLinkText、ByPartialLinkText
- 和id有关的:ById
- 全能的:ByXpath和ByCssSelector
2)最常用的是ByXpath,因为很多情况下,html标签的属性不够规范,无法通过单一的属性定位,这个时候使用xpath可以去重实现定位唯一元素;事实上定位最快的应当属于ById,因为id是唯一的,然而大多数网页元素并没有设置id。
39.selenium使用过程中你都遇到过哪些坑,都是如何解决的?
程序运行不稳定,有时运行失败抓取不到数据
解决方法:
- 添加元素智能等待时间 driver.implicitly_wait(30)
- 添加强制等待时间(比如python中写time.sleep())
- 多用 try 捕捉,处理异常,多种方式进行定位,如果第一种失败可以自动尝试第二种
40.driver对象有哪些常用属性和方法?
- driver.page_source:当前标签页浏览器渲染之后的网页源代码
- driver.current_url:当前标签页的url
- driver.close() :关闭当前标签页,如果只有一个标签页则关闭整个浏览器
- driver.quit():关闭浏览器
- driver.forward():页面前进
- driver.back():页面后退
- driver.screen_shot(img_name):页面截图
41.谈谈你对 Scrapy的理解
Scrapy框架,只需要实现少量代码,就能够快速的抓取到数据内容。Scrapy 使用了 Twisted异步网络框架来处理网络通讯,可以加快下载速度,不用自己去实现异步框架,并且包含各种中间件接口,可以灵活的完成各种需求。
scrapy 框架的工作流程:
- 1)首先Spiders(爬虫)将需要发送请求的 url(requests)经ScrapyEngine(引擎)交给Scheduler(调度器)。
- 2)Scheduler(排序,入队)处理后,经ScrapyEngine,交给Downloader。
- 3)Downloader向互联网发送请求,并接收下载响应(response),将响应(response)经ScrapyEngine交给Spiders。
- 4)Spiders处理response,提取数据并将数据,经ScrapyEngine交给ItemPipeline 保存(可以是本地,可以是数据库),提取url重新经ScrapyEngine交给Scheduler进行下一个循环,直到无Url请求程序结束。
42.Scrapy框架的基本结构
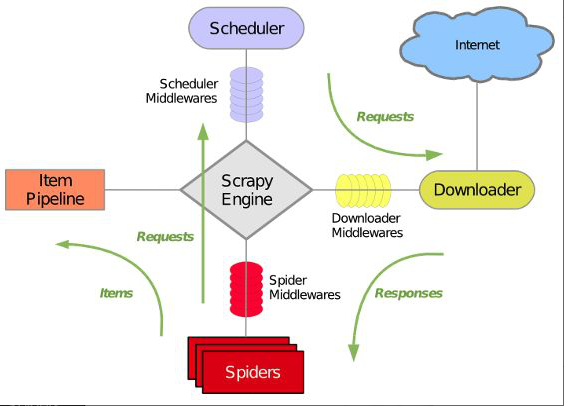
1)引擎(Scrapy):用来处理整个系统的数据流处理, 触发事务(框架核心)。
2)调度器(Scheduler):用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回。可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址。
3)下载器(Downloader):用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)。
4)爬虫(Spiders):爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
5)项目管道(Pipeline):负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
6)下载器中间件(Downloader Middlewares):位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
7)爬虫中间件(Spider Middlewares):介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
8)调度中间件(Scheduler Middewares):介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
43.Scrapy框架去重原理
需要将dont_filter参数设置为False,开启去重。
对于每一个url的请求,调度器都会根据请求的相关信息加密得到一个指纹信息,并且将指纹信息和set()集合中得指纹信息进行比对,如果set()集合中已经存在这个数据,就不在将这个Request放入队列中。如果set()集合中没有,就将这个Request对象放入队列中,等待被调度。
44.Scrapy框架的优缺点
1)优点:
- Scrapy 是异步的,他的异步机制是基于 twisted 异步网络框架处理的,在 settings.py文件里可以设置具体的并发量数值(默认并发量 16)
- 采取可读性更强的xpath代替正则
- 强大的统计和log系统
- 同时在不同的url上爬行
- 支持shell方式,方便独立调试
- 写middleware,方便写一些统一的过滤器
- 通过管道的方式存入数据库
2)缺点:
- 不能实现分布式爬取
- 异步框架出错后不会停掉其他任务,数据出错后难以察觉
45.Scrapy和requests的区别
1)scrapy 是封装起来的框架,包含了下载器、解析器、日志及异常处理,基于多线程, twisted 的方式处理,可以加快我们的下载速度,不用自己去实现异步框架。扩展性比较差,不够灵活。
2)requests 是一个 HTTP 库, 它只是用来进行请求,对于 HTTP 请求,他是一个强大的库,下载、解析全部自己处理,灵活性更高,高并发与分布式部署也非常灵活。
46.Scrapy和Scrapy-Redis的区别
Scrapy是一个Python爬虫框架,爬取效率极高,具有高度定制性,但是不支持分布式。
而Scrapy-Redis一套基于redis数据库、运行在Scrapy框架之上的组件,可以让Scrapy支持分布式策略,Slaver端共享Master端Redis数据库里的item队列、请求队列和请求指纹集合。
47.分布式爬虫为什么选择Redis数据库?
因为Redis支持主从同步,而且数据都是缓存在内存中的,所以基于Redis的分布式爬虫,对请求和数据的高频读取效率非常高。
Redis的优点:
- 数据读取快,因为数据都放在内存上
- 支持事务机制
- 数据持久化,支持快照和日志,方便恢复数据
- 拥有丰富的数据类型:list,string,set,qset,hash
- 支持主从复制,可以进行数据备份
- 丰富的特性:可以作为缓存,消息队列,设置过期时间,到期自动删除
48.分布式爬虫主要解决什么问题?
IP、带宽、CPU、io等问题。
49.Scrapy框架如何实现分布式抓取?
可以借助scrapy_redis类库来实现。
在分布式爬取时,会有master机器和slave机器,其中,master为核心服务器,slave为具体的爬虫服务器。
在master服务器上安装Redis数据库,并将要抓取的url存放到redis数据库中,所有的slave爬虫服务器在抓取的时候从redis数据库中去链接,由于scrapy-redis自身的队列机制,slave获取的url不会相互冲突,然后抓取的结果最后都存储到数据库中。master的redis数据库中还会将抓取过的url的指纹存储起来,用来去重。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:爬虫(17) – 面试(2) | 爬虫面试题库 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
