5分钟实现调用ChatGPT接口API完成多轮问答
最近ChatGPT也是火爆异常啊,在亲自使用了几个月之后,我发现这东西是真的好用,实实在在地提高了生产力。那么对于开发人员来说,有时候可能需要在自己的代码里加入这样一个智能问答的功能,我最近就出现了这样的想法和需求,所以简单研究了一下。网上类似的方法有很多,这里我提供一种我目前测试成功的也正在使用的一种,有其他需求可以自行上网查找。
1、下载openai库
我们可以直接使用Python中的openai库来实现对ChatGPT的调用。
首先第一步就是下载,下载方式也很简单,只需要一条命令pip install openai 。下载过程中可能会出现各种问题:比如pip版本太低,可以使用pip install --upgrade pip命令来升级。如果在命令行已经显示安装成功,但是调用的时候找不到库,可能是openai版本有问题,可以尝试使用这条命令pip install -U openai。
我的已经安装成功了,所以给我显示的是openai已安装的版本信息:


Windows进入命令行是WIN+R后输入cmd,然后运行相关命令。但是有个点需要注意,最好选择管理员权限来运行cmd命令行窗口。如果还有其他问题,可以尝试切换网络或者使用Anaconda来安装。
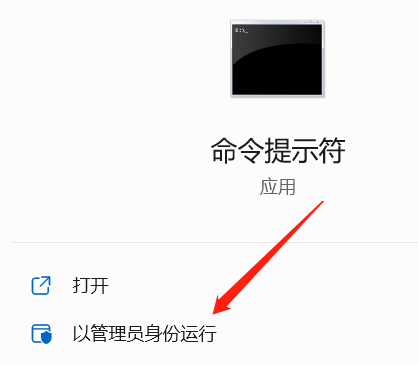
2、获取API KEY
在调用接口之前,我们需要申请一个API KEY来获取使用权限。获取方式有两种,可以自行去OpenAI官网(https://platform.openai.com/account/api-keys)注册账号,然后申请(需要魔法上网)。不过也可以选择其他方式去获取,网上有很多渠道,可以自行查找。这个key的格式大概是这个样子的:sk-[一大串混乱的字母和数字]。
3、模型简述
OpenAI 开放了两个新模型的api接口(也就是我们用的这个),专门为聊天而生的 gpt-3.5-turbo 和 gpt-3.5-turbo-0301。我查了一下这两个模型的区别:
gpt-3.5-turbo 需要在 content 中指明具体的角色和问题内容,而 gpt-3.5-turbo-0301 更加关注问题内容,而不会特别关注具体的角色部分。另外,gpt-3.5-turbo-0301 模型有效期到 6 月 1 日,而 gpt-3.5-turbo 会持续更新。
4、参数介绍
首先介绍一下主要参数的含义:
- model:模型名称,可选gpt-3.5-turbo或gpt-3.5-turbo-0301。
- messages:数据格式为json,问题描述或者角色定义,也是我们需要重点关注的字段。
- temperature:控制返回结果的随机性,0.0表示结果固定,随机性大可以设置为0.9。
- max_tokens:最大字数,通常一个汉字占两个长度,API最多支持的token数量为4096,需要注意的是这个字数同时包含了问题和答案的字数和。
- top_p:也即top probability,是指在生成文本时,模型将考虑概率最高的词语。设置为1即可。通过调节该值可以控制模型生成文本时的多样性。较小的 top_p 值会导致生成的文本更加确定性,而较大的 top_p 值则会导致生成的文本更加多样化但可能存在不连贯、不合理的情况。
- frequency_penalty:该参数用于对词汇进行惩罚(penalty),以减少重复性和不必要的单词或短语。当参数设置为较大的值时,模型会倾向于避免使用已经出现过的单词或短语。通过调节该值可以控制模型对文本的流畅度。较小的值会导致生成的文本更加流畅但可能存在重复或者不太符合逻辑的情况,而较大的值则会导致生成的文本更加严谨但可能会出现断句或者语义不连贯的情况。一般建议设置在0.6到1之间。
- stream:控制是否为流式输出。当参数设置为 True 时,API 的返回结果会以流的方式不断推送给客户端,无需等待全部结果生成完成。当参数设置为 False 时,则需要等待所有结果生成才能一次性返回给客户端。
messages字段需要重点解释一下:我们可以在代码中指定角色类型,在gpt-3.5-turbo模型中。主要包含三种角色,分别是系统system系统、user用户和assistant助手。
下面这一段是对此比较官方的阐释:
- System:系统角色指的是聊天机器人所运行的计算机系统或者软件平台。在对话过程中,System 负责接受用户请求并将其转发给 Assistant 进行处理或响应,并最终将结果返回给 User。
- User:用户角色指的是与聊天机器人进行对话的人。在对话交互中,User 可以提出各种问题,包括需要获取信息、解决问题、咨询建议等等。User 一般通过输入文本、语音等方式向 Assistant 发出请求,并通过系统获取相应的回复或结果。
- Assistant:Assistant 角色指的是聊天机器人中的智能助手程序,主要负责对用户请求进行处理和响应,并生成相应的回答或结果。Assistant 可以使用自然语言处理技术,如文本理解、知识库查询、逻辑推理等,从而实现与 User 的智能化交互。
代码示例:
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What year is this year?"},
{"role": "assistant", "content": "2023"},
{"role": "user", "content": " xxxx ?"}
]
5、调用接口
在我们完成了openai库的安装并了解了上述参数的含义之后,就可以着手写代码了,下面一个简单的多次问答机器人代码示例:
# -*- coding: utf-8 -*-
import openai
api_key = "在这里填入你的KEY"
openai.api_key = api_key
def askChatGPT(messages):
MODEL = "gpt-3.5-turbo"
response = openai.ChatCompletion.create(
model=MODEL,
messages = messages,
temperature=1)
return response['choices'][0]['message']['content']
def main():
messages = [{"role": "user","content":""}]
while 1:
try:
text = input('问:')
if text == 'quit':
break
# 问
d = {"role":"user","content":text}
messages.append(d)
text = askChatGPT(messages)
d = {"role":"assistant","content":text}
# 答
print('答:'+text+'\n')
messages.append(d)
except:
messages.pop()
print('ChatGPT:error\n')
if __name__ == '__main__':
main()
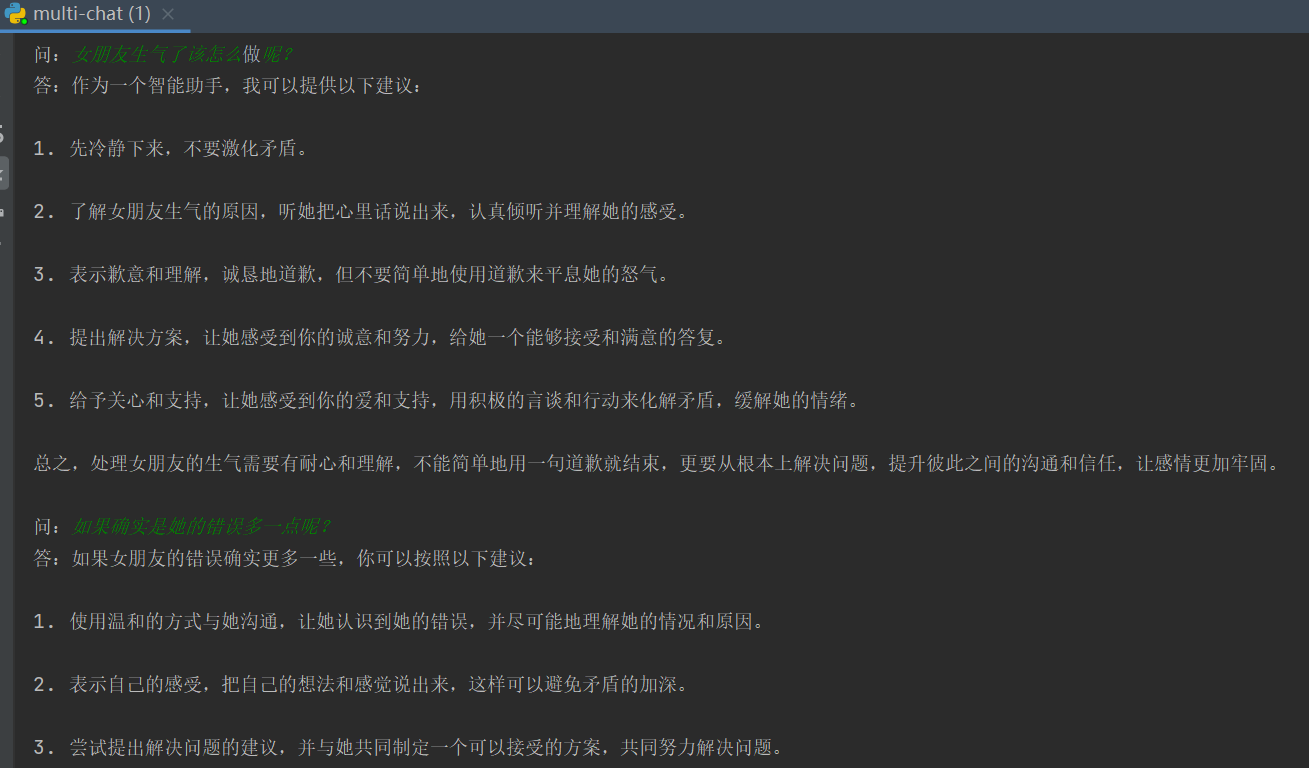
运行上述代码之后,在控制台会提示我们输入问题。每输入一个问题并敲回车之后,等待片刻会显示ChatGPT的回答,我们可以进行连续问答,下图是运行效果(测试问题无任何价值导向)。
下面这段代码实现了单次问答调用,本质上和上面的代码是一样的,各位按需自取:
# -*- coding: utf-8 -*-
import openai
def openai_reply(content, apikey):
openai.api_key = apikey
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-0301", # gpt-3.5-turbo-0301
messages=[
{"role": "user", "content": content}
],
temperature=0.5,
max_tokens=2048,
top_p=1,
frequency_penalty=0.7,
)
# print(response)
return response.choices[0].message.content
if __name__ == '__main__':
content = '我比较喜欢大海,请给我推荐几个景点。'
ans = openai_reply(content, '在这里填入你的KEY')
print(ans)
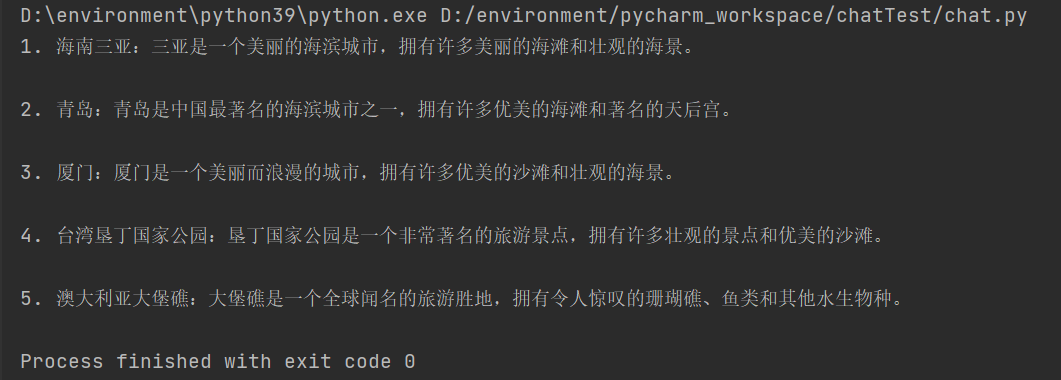
原始的返回值数据格式示例如下:
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "xxxx",
"role": "assistant"
}
}
],
"created": 1683542226,
"id": "chatcmpl-",
"model": "gpt-3.5-turbo-0301",
"object": "chat.completion",
"usage": {
"completion_tokens": 373,
"prompt_tokens": 30,
"total_tokens": 403
}
}
6、总结
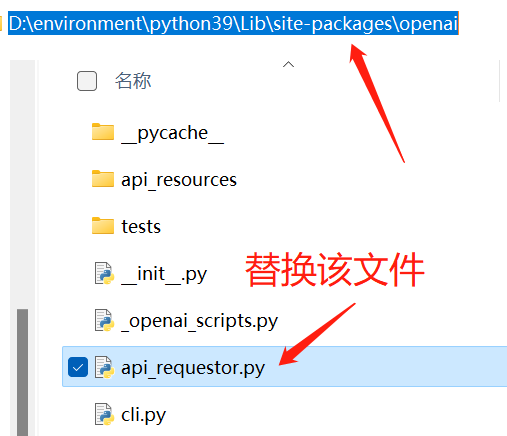
以上就是针对程序调用ChatGPT接口的全部步骤了,如果运行代码出现了问题可以最后尝试一下这个方法:找到目前所使用的python环境的安装目录,进入openai库文件夹下(D:\environment\python39\Lib\site-packages\openai),替换api_requestor.py文件。所需的替换文件可以关注我的订阅号【靠谱杨的挨踢生活】回复【chat】获取。
理性看待人工智能的发展,正确认识人的不可替代性。让AI作为一个越来越实用的工具服务于我们的生产和生活(仅代表个人观点)。
原文链接:https://www.cnblogs.com/rainbow-1/p/17382852.html
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:5分钟实现调用ChatGPT接口API实现多轮问答 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 