selenium介绍
由于requests模块不能执行js,有的页面内容,我们在浏览器中可以看到,但是请求下来没有。
selenium模块:模拟操作浏览器,完成人的行为。
selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器。
模块安装:
pip install selenium
下载驱动
驱动浏览器需要下载相应的驱动,谷歌要下谷歌的驱动,火狐要下火狐的驱动,并且版本要与当前浏览器对应。
这里我选择谷歌浏览器,首先查看当前谷歌浏览器的版本:

版本:
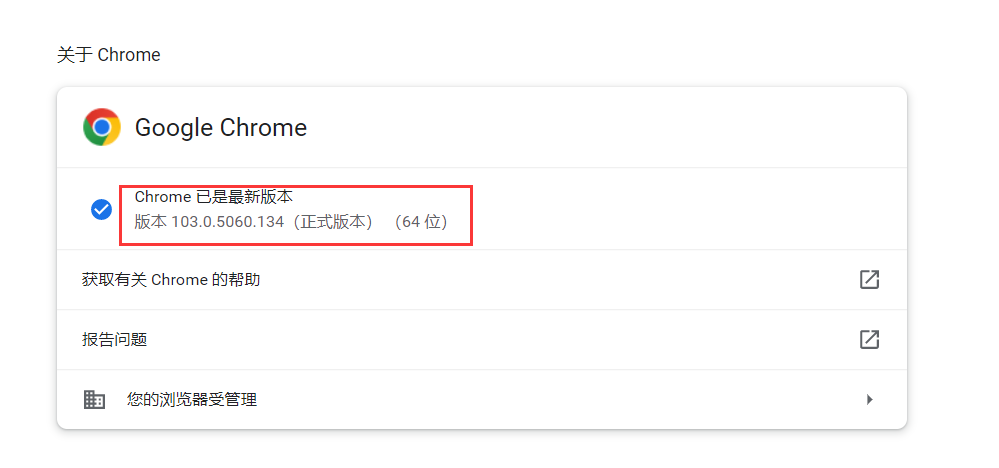
下载驱动,地址:CNPM Binaries Mirror (npmmirror.com),一定要下载对应的版本驱动,比如我谷歌浏览器版本为103.0.5060.134,就要下103.0.5060.134的驱动
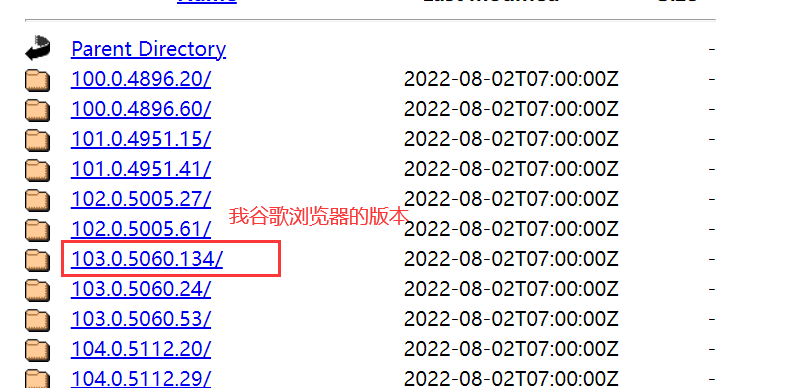
下载对应操作系统即可。
基本使用
导入模块:
from selenium import webdriver
初始化(打开浏览器):
browser = webdriver.Chrome(executable_path='驱动路径')
# 不写路径,要放到项目路径下或环境变量中
browser = webdriver.Chrome()
在地址栏输入地址:
browser.get('http://www.baidu.com')
关闭标签:
browser.close()
关闭浏览器:
browser.quit()
selenium用法
元素操作
操作浏览器页面中的标签。
1.搜索标签
新版本:by=根据什么查找,value=查找的值
- find_element(by, value):找第一个
- find_elements(by, value):找所有
| by的参数 | 含义 |
|---|---|
| By.ID | 根据标签id属性查找 |
| By.LINK_TEXT | 根据a标签的文字查找 |
| By.PARTIAL_LINK_TEXT | 根据a标签的文字模糊匹配 |
| By.TAG_NAME | 根据标签名查找 |
| By.CLASS_NAME | 根据标签class属性查找 |
| By.NAME | 根据标签name属性查找 |
| By.CSS_SELECTOR | 根据css选择器查找 |
| By.XPATH | 根据xpath查找 |
from selenium.webdriver.common.by import By
# 查找网页中id为'login'的标签
tag = browser.find_element(by=By.ID, value='login')
# 查找网页中class为'login'的所有标签
tags = browser.find_elements(By.CLASS_NAME, value='login')
# 查找网页div标签中class属性为'dd'的标签
tag = browser.find_element(by=By.CSS_SELECTOR, value='div .dd')
# 查找网页中a标签文字为'登录'的标签
tag = browser.find_element(by=By.LINK_TEXT, value='登录')
老版本:
browser.find_element_by_id() # 根据id
browser.find_element_by_link_text() # 根据a标签的文字
browser.find_element_by_partial_link_text() # 根据a标签的文字模糊匹配
browser.find_element_by_tag_name() # 根据标签名
browser.find_element_by_class_name() # 根据类名
browser.find_element_by_name() # 根据name属性
browser.find_element_by_css_selector() # css选择器
2.点击标签
# 查找网页中id为'login'的标签
tag = browser.find_element(by=By.ID, value='login')
# 标签点击
tag.click()
3.向输入框中写内容
tag = browser.find_element(by=By.ID, value='inputTag')
tag.send_keys('内容')
4.清空
tag = browser.find_element(by=By.ID, value='inputTag')
tag.clear()
举例:打开百度搜索'博客园':
from selenium import webdriver
from selenium.webdriver.common.by import By
# 打开浏览器
browser = webdriver.Chrome()
# 输入网址进入
browser.get('http://www.baidu.com')
# 查找百度输入框
word = browser.find_element(By.ID, 'kw')
# 输入框添加内容
word.send_keys('博客园')
# 查找搜索按钮
btn = browser.find_element(By.ID, 'su')
# 点击搜索按钮
btn.click()
# 等待2秒关闭浏览器
import time
time.sleep(2)
browser.quit()
等待元素被加载
程序操作页面非常快,所以在取每个标签的时候,标签可能没有加载好,取标签时就会报错,所以需要设置等待时间。
如果标签找不到,就会等待,还找不到就会报错:
from selenium import webdriver
from selenium.webdriver.common.by import By
# 打开浏览器
browser = webdriver.Chrome()
# 找不到标签就等待2秒
browser.implicitly_wait(2)
# 输入网址进入
browser.get('http://www.baidu.com')
# 查找百度输入框
word = browser.find_element(By.ID, 'kw')
# 输入框添加内容
word.send_keys('博客园')
# 查找搜索按钮
btn = browser.find_element(By.ID, 'su')
# 点击搜索按钮
btn.click()
# 找到能进入博客园的a标签
cnblog = browser.find_element(By.LINK_TEXT, '博客园')
# 进入博客园
cnblog.click()
# 等待2秒关闭浏览器
import time
time.sleep(2)
browser.quit()
元素各项属性
| 标签对象调用 | 含义 |
|---|---|
| 标签对象.location | 标签所在位置 |
| 标签对象.size | 标签大小(高宽) |
| 标签对象.id | 标签id号(随机给的),不是id属性 |
| 标签对象.tag_name | 标签名 |
| 标签对象.get_attribute('属性') | 标签属性值 |
from selenium import webdriver
from selenium.webdriver.common.by import By
# 打开浏览器
browser = webdriver.Chrome()
# 输入网址进入
browser.get('http://www.baidu.com')
# 查找百度输入框
word = browser.find_element(By.ID, 'kw')
print(word.location) # 标签所在位置,{'x': 298, 'y': 188}
print(word.size) # 标签大小,{'height': 44, 'width': 550}
print(word.id) # 标签id号,不是id属性
print(word.tag_name) # 标签名字,input
print(word.get_attribute('class')) # 获取标签的class属性值,s_ipt
browser.quit()
执行js代码
执行js用途:
- 普通滑屏,打开新标签
- 可以执行js代码,别人网站的变量,函数,都可以拿到并执行
滚动条到最底部
from selenium import webdriver
# 打开浏览器
browser = webdriver.Chrome()
# 输入网址进入
browser.get('https://www.cnblogs.com/')
# 滚动条到最底部
browser.execute_script('scrollTo(0,document.body.scrollHeight)')
import time
time.sleep(3)
browser.quit()
打开新标签
from selenium import webdriver
# 打开浏览器
browser = webdriver.Chrome()
# 输入网址进入
browser.get('https://www.cnblogs.com/')
# 打开新标签
browser.execute_script('window.open()')
import time
time.sleep(3)
browser.quit()
切换选项卡
浏览器打开了多个选项卡,需要切换时:
browser.switch_to.window(browser.window_handles[1])
# 已弃用的方法
browser.switch_to_window(browser.window_handles[1])
browser.window_handles[0]代表第一个选项卡
browser.window_handles[1]代表第二个选项卡
from selenium import webdriver
import time
# 打开浏览器
browser = webdriver.Chrome()
# 进入博客园
browser.get('https://www.cnblogs.com/')
time.sleep(1)
# 打开新标签
browser.execute_script('window.open()')
# 切换到新标签
browser.switch_to.window(browser.window_handles[1])
# 新标签进入百度
browser.get('https://www.baidu.com/')
time.sleep(1)
# 切换回博客园
browser.switch_to.window(browser.window_handles[0])
time.sleep(2)
browser.quit()
浏览器前进后退
浏览器前进:
browser.forward()
浏览器后退:
browser.back()
无界面浏览器
不显示的打开浏览器的图形化界面,还能获取数据
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('window-size=1920,3000') # 指定浏览器分辨率
chrome_options.add_argument('--disable-gpu') # 谷歌文档提到需要加上这个属性来规避bug
chrome_options.add_argument('--hide-scrollbars') # 隐藏滚动条, 应对一些特殊页面
chrome_options.add_argument('blink-settings=imagesEnabled=false') # 不加载图片, 提升速度
chrome_options.add_argument("--disable-blink-features=AutomationControlled") # 不被检测到是测试环境
chrome_options.add_argument('--headless') # 浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
browser = webdriver.Chrome(options=chrome_options)
browser.get('https://www.cnblogs.com/')
print(browser.page_source) # 当前页面的内容(html内容)
browser.quit()
xpath的使用
简单介绍
XPath 是一门在 XML 文档中查找信息的语言。
| 表达式 | 描述 |
|---|---|
| nodename | 选取此标签的所有子标签。如:div,选取div标签下的子标签 |
| / | 找当前路径下的标签 |
| // | 找当前路径子子孙孙下的标签 |
| . | 表示当前路径 |
| .. | 表示上一次 |
| @ | 选取属性。 |
举例:
| 表达式 | 描述 |
|---|---|
| //* | 所有标签 |
| //head | 所有head标签 |
| //div/a | 所有div标签下的a标签 |
| //a[@class="a1"] | 所有class属性为'a1'的a标签 |
| /div | 所有最外层的div标签 |
| //head/text() | 所有head标签的文本内容 |
| //div/a[1] | div标签下的第一个a标签 |
| //div/a[contains(@class,"li")] | 多个属性要用contains |
selenium中使用
网页中打开F12,找到标签,右键-->复制-->复制 Xpath,把值用在代码中即可。
from selenium.webdriver.common.by import By
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.cnblogs.com/')
res = browser.find_element(By.XPATH, '//*[@id="post_list"]/article[1]/section/div')
print(res.text)
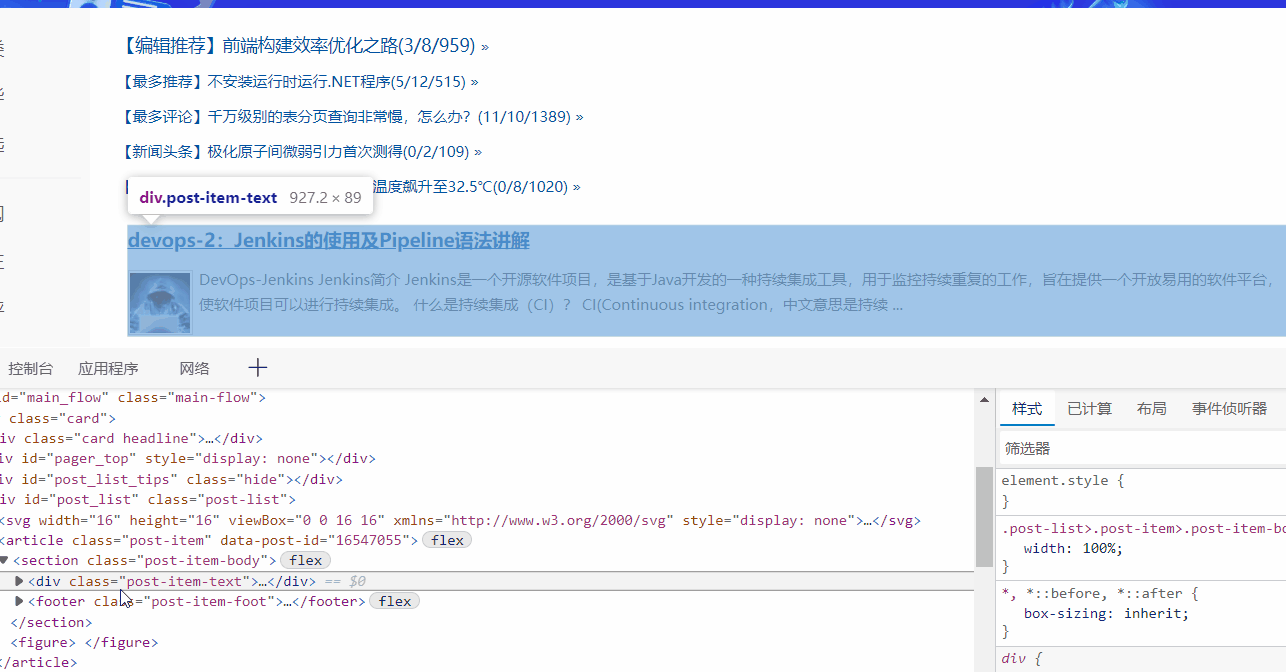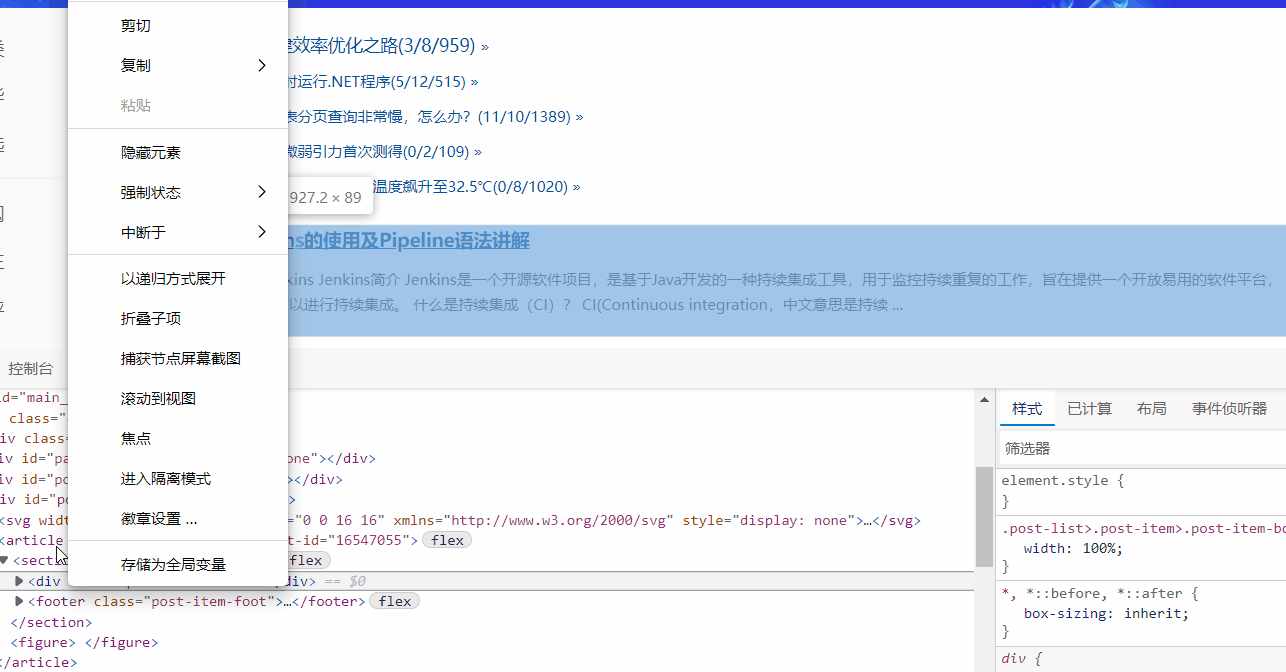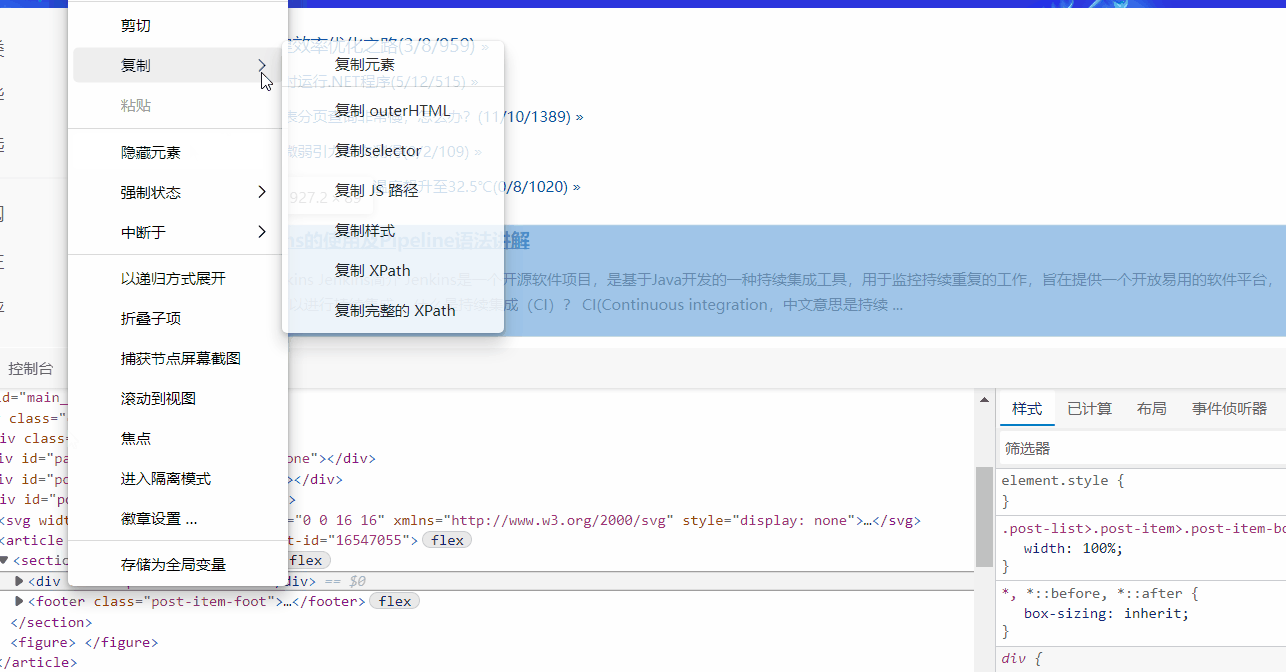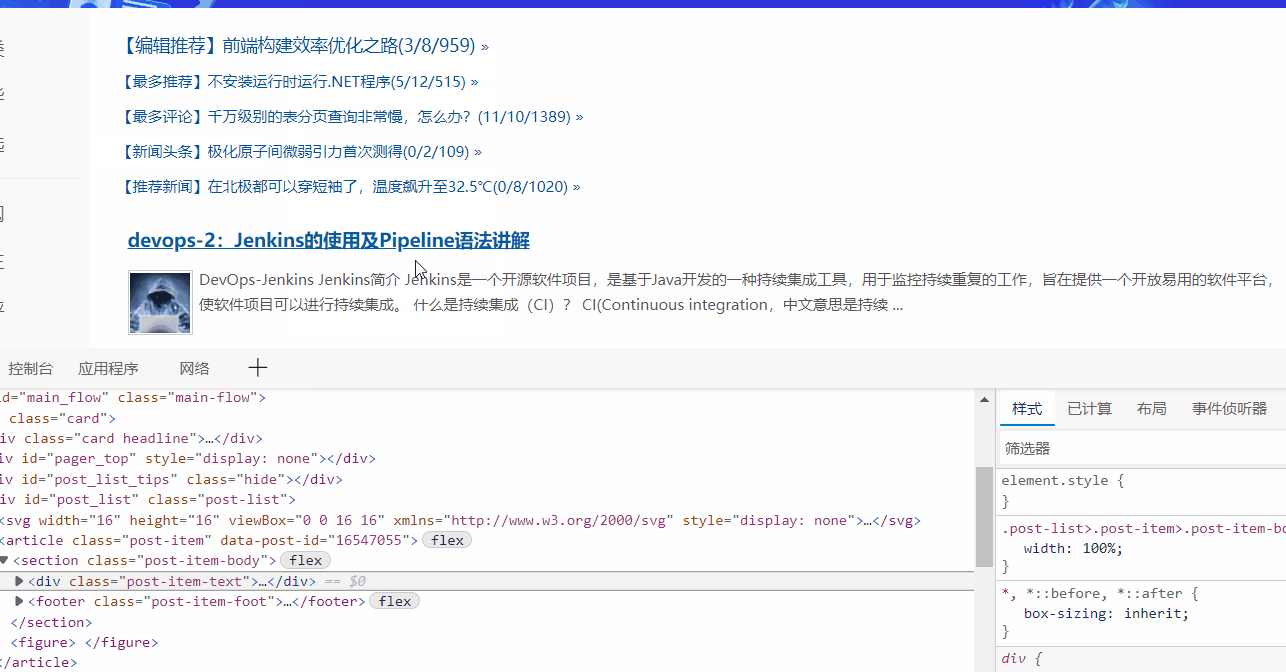
异常处理
由于有时候程序操作浏览器过快,有些标签会找不到等一些情况会出现报错,这时候可以用异常处理:
from selenium.common.exceptions import TimeoutException, NoSuchElementException, NoSuchFrameException
from selenium import webdriver
from selenium.webdriver.common.by import By
# 打开浏览器
browser = webdriver.Chrome()
try:
# 输入网址进入
browser.get('http://www.baidu.com')
# 查找百度输入框
word = browser.find_element(By.ID, 'kw')
# 输入框添加内容
word.send_keys('博客园')
# 查找搜索按钮
btn = browser.find_element(By.ID, 'su')
# 点击搜索按钮
btn.click()
# 找到能进入博客园的a标签
cnblog = browser.find_element(By.LINK_TEXT, '博客园')
except Exception as e:
print(e)
finally: # 不管报不报错最后都关闭浏览器
# 等待2秒关闭浏览器
import time
time.sleep(2)
browser.quit()
登录获取cookie保存
获取浏览器所有cookie:
cookies = browser.get_cookies()
print(cookies)
登录博客园并保存cookie:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 打开浏览器
browser = webdriver.Chrome()
browser.implicitly_wait(2)
try:
# 进入博客园
browser.get('https://www.cnblogs.com/')
# 查找登录按钮
login_btn = browser.find_element(By.LINK_TEXT, '登录')
login_btn.click()
# 查找用户名和密码输入框
username = browser.find_element(By.ID, 'mat-input-0')
password = browser.find_element(By.ID, 'mat-input-1')
# 输入用户名密码
username.send_keys('xx')
password.send_keys('123')
btn = browser.find_element(By.CSS_SELECTOR, 'body > app-root > app-sign-in-layout > div > div > app-sign-in > app-content-container > div > div > div > form > div > button')
btn.click()
# 可能要验证,睡眠一下手动过验证
time.sleep(10)
# 保存cookie
import json
cookies = browser.get_cookies()
with open('cnblog.json', 'w', encoding='utf-8') as f:
json.dump(cookies, f)
except Exception as e:
print(e)
finally: # 不管报不报错最后都关闭浏览器
# 等待2秒关闭浏览器
time.sleep(2)
browser.quit()
如果标签不好找出来,可以打开F12,找到标签位置,复制css选择器:
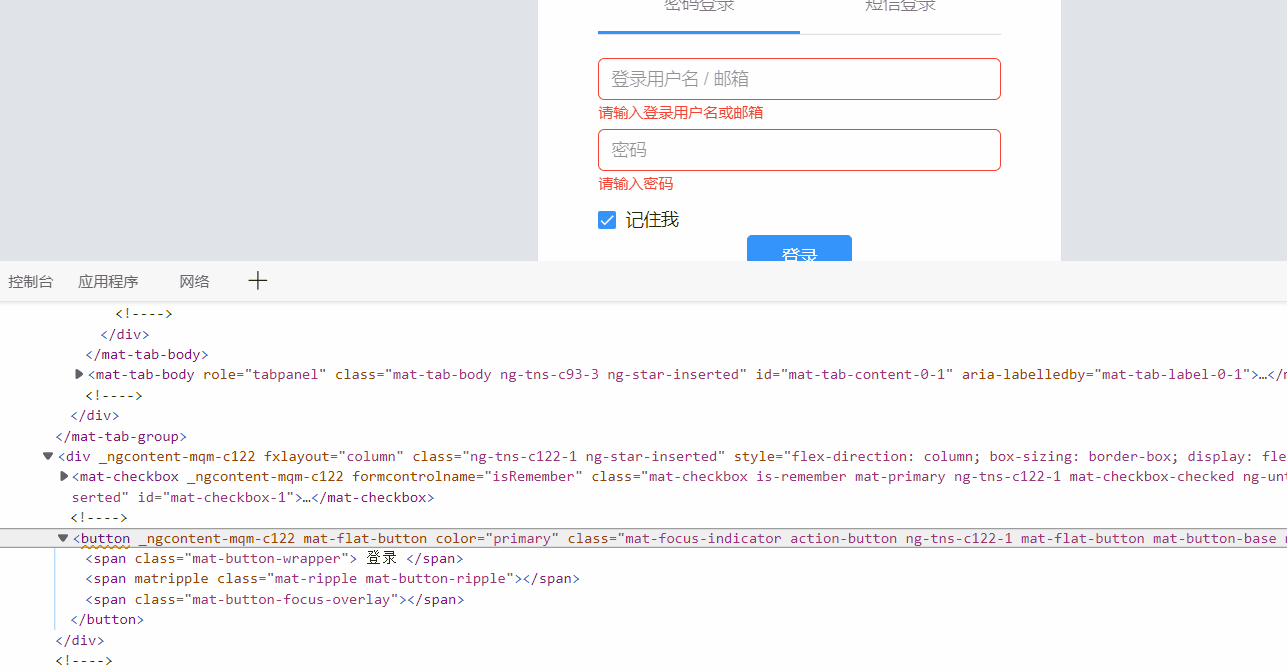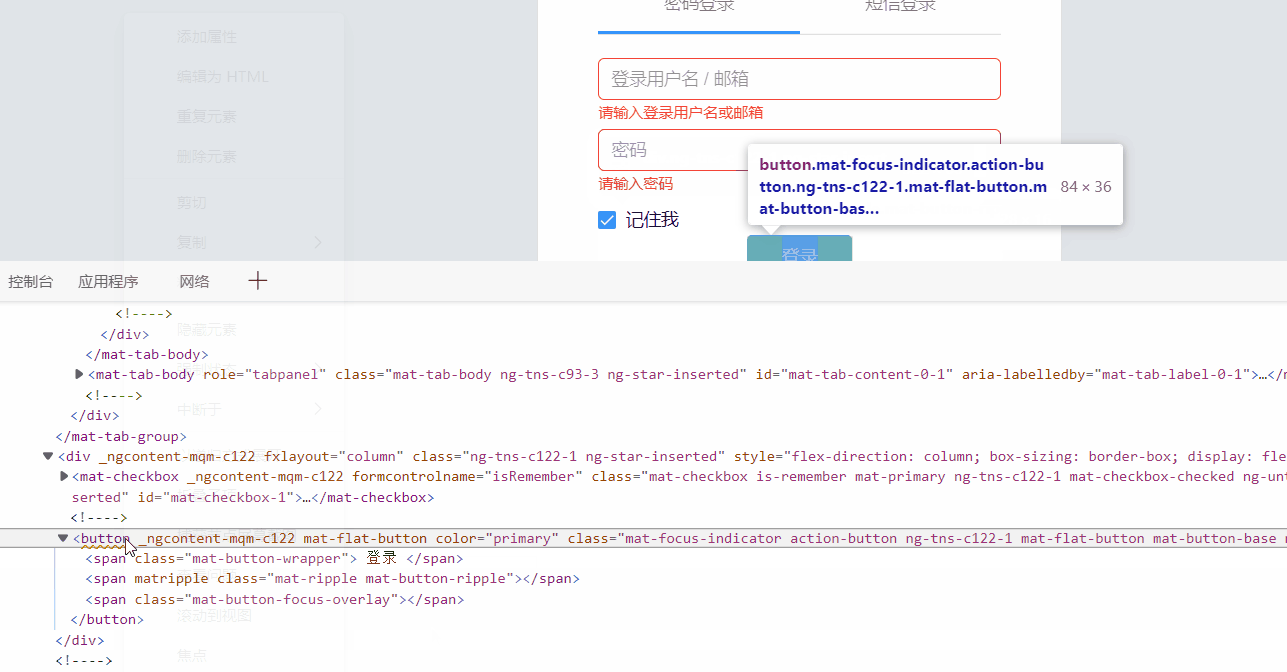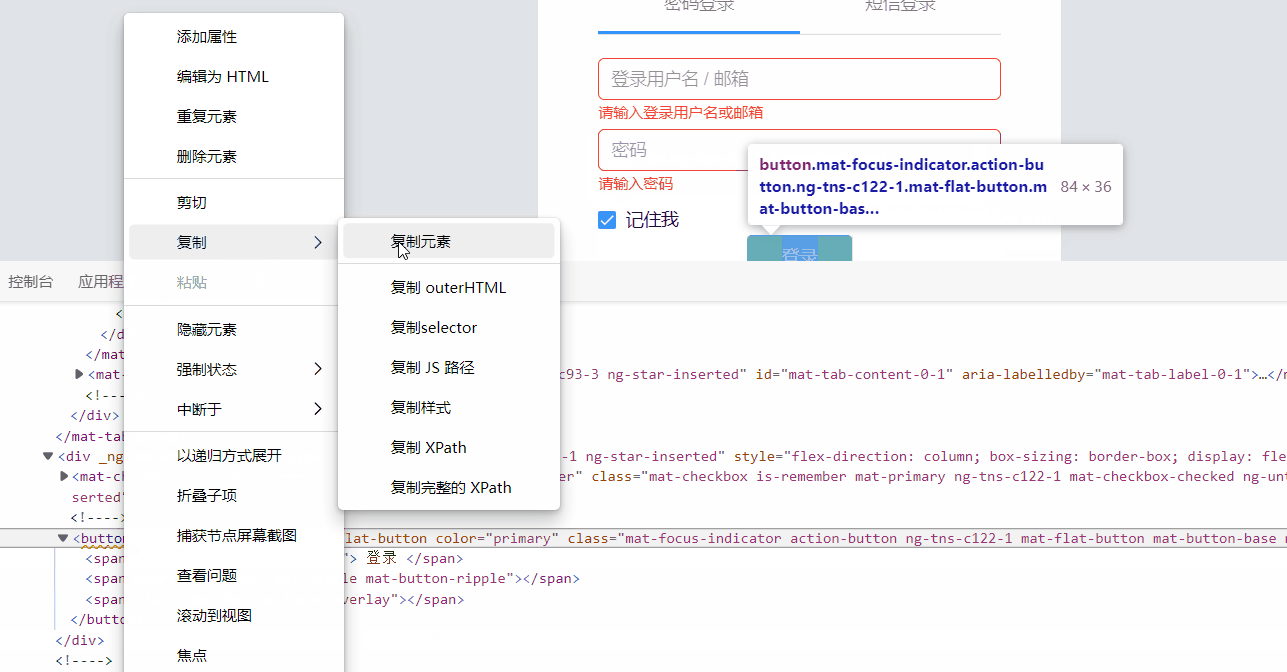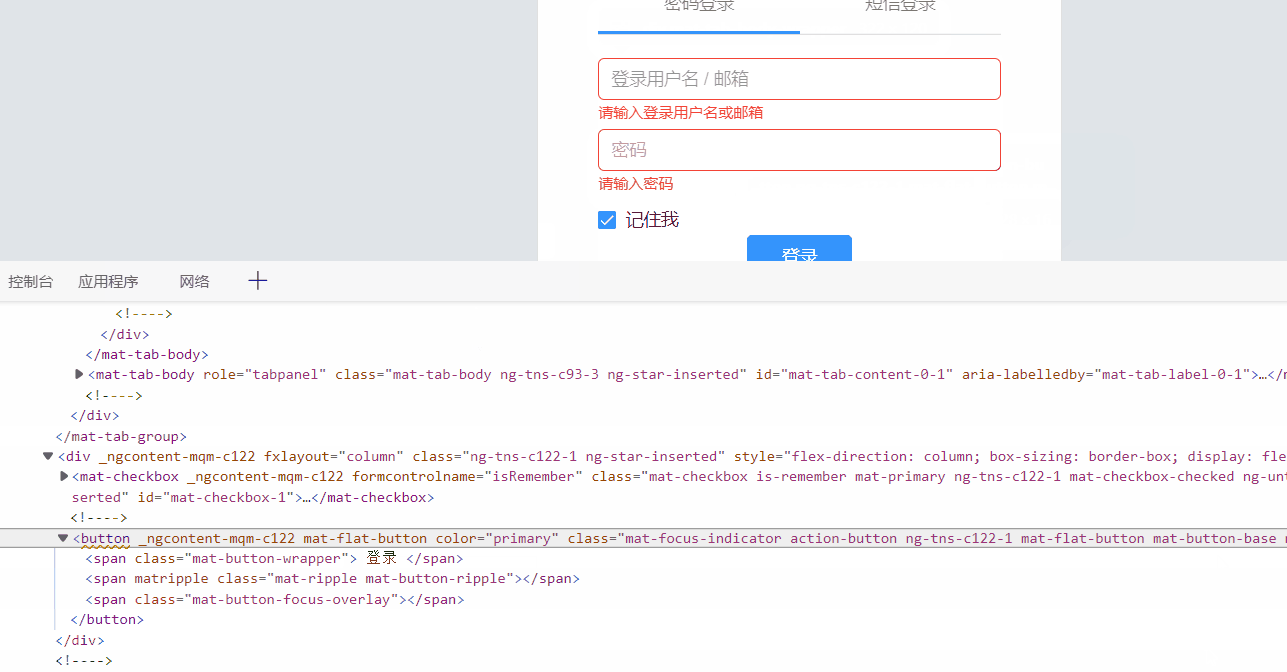
通过cookie达成登录效果
from selenium import webdriver
import time
# 打开浏览器
browser = webdriver.Chrome()
browser.implicitly_wait(2)
try:
# 进入博客园
browser.get('https://www.cnblogs.com/')
# 此时还不是登录后的状态
time.sleep(2)
# 拿出cookie
import json
with open('cnblog.json', 'r', encoding='utf-8') as f:
cookies = json.load(f)
# cookie保存时是列表套字典,但写入cookie需要用字典格式,所以用循环
for cookie in cookies:
browser.add_cookie(cookie)
# cookie全写入后刷新页面
browser.refresh()
# 此时是登录后的状态
except Exception as e:
print(e)
finally: # 不管报不报错最后都关闭浏览器
# 等待2秒关闭浏览器
time.sleep(2)
browser.quit()
动作链
模拟按住鼠标拖动的效果,或者是在某个标签上的某个位置点击的效果,主要用来做验证码的破解(滑动验证码)。
导入:
from selenium.webdriver import ActionChains
初始化:得到动作链对象
actions = ActionChains(浏览器对象)
添加动作的方法:
# 按住标签的动作,按住source
actions.click_and_hold(sourse)
# 移动标签的动作,source移到target
actions.drag_and_drop(sourse, target)
# 移动标签的动作,按住source移到target并偏移
actions.click_and_hold(sourse).drag_and_drop_by_offset(target, xoffset, yoffset)
# 移动标签的动作,按住source并移动(x, y)
actions.click_and_hold(sourse).move_by_offset(xoffset, yoffset)
# 松开动作
actions.release()
执行动作:上述方法需要语句执行动作
# 执行动作
actions.perform()
实战:
方式一:基于同一个动作链串行执行
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains
import time
browser = webdriver.Chrome()
browser.implicitly_wait(5)
browser.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
# 页面有一个iframe标签,需要切换进去
browser.switch_to.frame('iframeResult')
# 可移动标签
source = browser.find_element(By.ID, 'draggable')
# 目标标签
target = browser.find_element(By.ID, 'droppable')
# 拿到动作链对象
actions = ActionChains(browser)
# 移动动作
actions.drag_and_drop(source, target)
# 执行动作
actions.perform()
time.sleep(2)
browser.quit()
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains
import time
browser = webdriver.Chrome()
browser.implicitly_wait(5)
browser.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
browser.switch_to.frame('iframeResult')
source = browser.find_element(By.ID, 'draggable')
target = browser.find_element(By.ID, 'droppable')
# 拿到动作链对象
actions = ActionChains(browser).click_and_hold(source)
actions.drag_and_drop_by_offset(target, 10, 10)
# 执行动作
actions.perform()
time.sleep(2)
browser.quit()
方式二:不同的动作链,每次移动的位移都不同
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains
import time
browser = webdriver.Chrome()
browser.implicitly_wait(5)
browser.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
browser.switch_to.frame('iframeResult')
source = browser.find_element(By.ID, 'draggable')
target = browser.find_element(By.ID, 'droppable')
ActionChains(browser).click_and_hold(source).perform()
distance = target.location['x'] - source.location['x'] # 两个控件的x轴的距离
track = 0
while track < distance:
ActionChains(browser).move_by_offset(xoffset=20, yoffset=0).perform()
track += 20
ActionChains(browser).release().perform()
time.sleep(2)
browser.quit()
打码平台使用(验证码破解)
简单的数字字母组合可以使用图像识别(python 现成模块),但是成功率不高,所以可以使用第三方打码平台(破解验证码平台),花钱,把验证码图片给它,它给你识别完,返回给你。
超级鹰验证码识别-专业的验证码云端识别服务,让验证码识别更快速、更准确、更强大 (chaojiying.com)
超级鹰开发文档:
import requests
from hashlib import md5
class ChaojiyingClient:
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files,
headers=self.headers)
return r.json()
def PostPic_base64(self, base64_str, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
'file_base64': base64_str
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
if __name__ == '__main__':
chaojiying = ChaojiyingClient('超级鹰用户名', '超级鹰用户名的密码', '96001') # 用户中心>>软件ID 生成一个替换 96001
im = open('a.jpg', 'rb').read() # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
print(chaojiying.PostPic(im, 1902)) # 1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
# print chaojiying.PostPic(base64_str, 1902) #此处为传入 base64代码
用超级鹰破解超级鹰验证码并登录:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
from PIL import Image
# 验证码获取
def get_code():
browser.save_screenshot('main.png') # 把当前页面截图
img = browser.find_element(By.XPATH, '/html/body/div[3]/div/div[3]/div[1]/form/div/img') # 获取图片标签
location = img.location # 图片位置
size = img.size # 图片宽高
# 使用pillow扣除大图中的验证码,pip install pillow
img_tu = (
int(location['x']) * 1.25,
int(location['y']) * 1.25,
int(location['x'] + size['width']) * 1.25,
int(location['y'] + size['height']) * 1.25
)
# 打开当前页面截图
img_main = Image.open('./main.png')
# 抠出验证码图片
img_code = img_main.crop(img_tu)
# 保存验证码图片
img_code.save('code.png')
# 破解亚验证码
from chaojiying import ChaojiyingClient
chaojiying = ChaojiyingClient('zbh332525', '332525', '937257')
# chaojiying = ChaojiyingClient('用户名', '密码', '软件id')
im = open('code.png', 'rb').read()
code = chaojiying.PostPic(im, 1902)['pic_str']
return code
browser = webdriver.Chrome()
browser.implicitly_wait(5)
browser.get('https://www.chaojiying.com/user/login/')
browser.maximize_window() # 浏览器全屏,免得有偏差
# 写入用户名、密码、验证码
username = browser.find_element(By.NAME, 'user').send_keys('zbh332525')
password = browser.find_element(By.NAME, 'pass').send_keys('332525')
code = browser.find_element(By.NAME, 'imgtxt').send_keys(get_code())
time.sleep(2)
# 登录按钮点击
browser.find_element(By.XPATH, '/html/body/div[3]/div/div[3]/div[1]/form/p[4]/input').click()
time.sleep(2)
browser.quit()
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:爬虫之selenium - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 