作者:京东科技 李永萍
GridGraph:Large-Scale Graph Processing on a Single Machine Using 2-Level Hierarchical Partitioning
图计算框架
图计算系统按照计算方式划分可分为:单机内存图处理系统,单机核外图处理系统,分布式内存图处理系统,分布式核外图处理系统。本文将详细介绍单机核外图处理系统GridGraph。
GridGraph论文分析
单机核外图处理系统
单机内存图处理系统受限于内存空间和单机算力,能够解决的图规模有限。分布式内存图处理系统理论上可以随着集群规模的增大进而解决更大的图规模,但集群间的网络带宽问题,负载不均衡,同步开销大,容错开销和图分割挑战也愈变明显。无论是单机还是分布式,内存式图处理系统能够处理的图规模都是有限的。因此想要使用更少的资源解决更大的图规模,可以使用单机核外图处理系统。单机核外图处理系统使用磁盘顺序读写进行数据置换,能够在有限的内存中计算更大规模的图。单机核外图处理系统在最大化利用磁盘顺序读写,在选择调度和同异步计算模式等方面做出了重要探索。
GridGraph
GridGraph是一种单机核外图处理系统,在大规模图处理系统中充分利用磁盘读写,在有限内存中高效完成大规模图计算。
GridGraph充分利用磁盘大容量,解决单机内存有限时实现大规模图计算问题。GridGraph采用Streaming-Apply方式减少计算中的IO 请求数量,通过文件调入顺序减少不必要的io开销。 同时GridGraph也利用顺序读和顺序写的特点,尽可能的较少硬盘的写操作。
主要贡献
GridGraph的主要贡献有:
1、基于边列表快速生成一种新的图表示形式--网格划分。网格划分是一种不同于邻接矩阵和邻接链表的表示形式,网格划分不需要将index排序,网格的边block可以由未排序的边列表转换而来,数据前置预处理开销小,可应用于不同的算法和不同的机器。
2、2-level hierarchical partitioning 使用两层分区划分模式,该模式不仅适用于核外,在内存中同样有效。
3、提出streaming-apply模式,以提高IO。通过双滑动窗口(Dual sliding windows)保证顶点访问的局部性。
4、提供灵活的点边流式接口函数,通过用户自定义过滤函数来跳过非活跃顶点(活跃顶点:bitmap中该顶点index的状态为1)或非活跃边的计算。对于活跃顶点集随着收敛而缩小的迭代算法,这种方法显著提高了算法的性能。
Grid Representation网格划分
为了在有限的内存中完成大规模图计算,并严格控制内存消耗,需要将图进行网格划分。
1、顶点集划分成P个均匀的chunk。
2、边集划分在P*P个block中,行表示源顶点,列表示目的顶点。
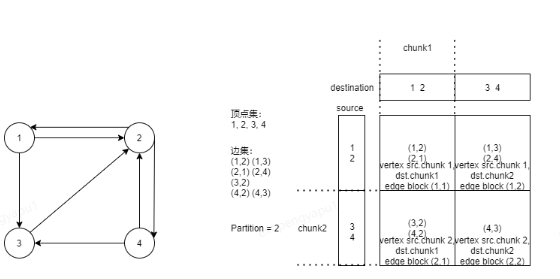

The Grid Format 网格格式
GridGraph partition预处理方式如下:
1、主线程从原始的无序边集中读取边,读取到一批边后,将这批边数据加入队列中。(根据磁盘带宽,一般选择24M做为这批边的大小)
2、每个工作线程从队列中获取任务,计算边所属的block,将边加入到边block文件中。为了提高I/O吞吐量,每个工作线程维护每个block的本地缓冲区,一旦缓冲区满就刷新到文件。
分区过程结束后,GridGraph就可以进行计算了。然而,由于现实世界图的不规则结构,一些边block可能太小,无法在HDD上实现大量的连续带宽。因此,可能由于频繁的磁盘寻道,有时无法实现顺序带宽。为了避免这种性能损失,GridGraph需要一个额外的合并阶段,以便在基于HDD的系统上更好地执行,该阶段将边block文件逐个追加到一个大文件中,并在元数据中记录每个块的起始偏移量。
不同于GraphChi的shard分片模式,GridGraph不需要对边block排序,减少了IO和计算开销,我们只需要在磁盘上读写一次边,而不是在GraphChi中多次遍历边。
而对于X-Stream来说,X-Stream不需要显式的预处理。根据流分区,边被打乱到几个文件。不需要排序,分区的数量非常少。对于许多顶点数据都能装进内存的图,只需要一个流分区。然而,这种划分策略使得它在选择调度中效率低下,这在很大程度上影响了它在许多迭代算法中的性能,因为在某些迭代中只使用了一部分顶点。(GraphChi和X-Stream都是单机核外图计算系统,在此不赘述。)
何为选择调度?选择调度是将图数据文件(一般是边文件)划分为多个block并按顺序编号,设置一个bitmap记录所有block的访问状态,若是需要访问则将bitmap中index为block编号的状态置为1,在调度时跳过状态为0的block,选择状态为1的block从磁盘置入内存中进行计算。若是bitmap为空,则默认所有block都需要参与计算,则将block按序从磁盘置入内存。block的大小决定了选择调度的差异,block越大,包含的数据越多,block置换的概率越低,选择调度越好。反之,block越小,包含的数据越少,计算时需要置换block的概率越高,选择调度越差。
GridGraph完成预处理的时间非常短。此外,生成的网格格式可用于运行在同一图上的所有算法。通过分区,GridGraph能够进行选择性调度,减少对没有活跃边的边块的不必要访问。这在许多迭代算法(如BFS和WCC)中贡献很大,因为其中大部分顶点在许多迭代中都是不活动的。
内存(In-memory)图计算系统将全都数据读取到Memory内存中,使用到系统中的Cache(缓存)和Memory(内存)来完成图计算过程,核外(Out-of-core)图计算系统则将数据存储到Disk磁盘中,计算时再将所需数据置换到Memory(内存)中,为了缓解CPU和Memory之间的速度差异,通常会将数据存储至Cache缓存中。磁盘存储空间>内存存储空间>缓存存储空间。
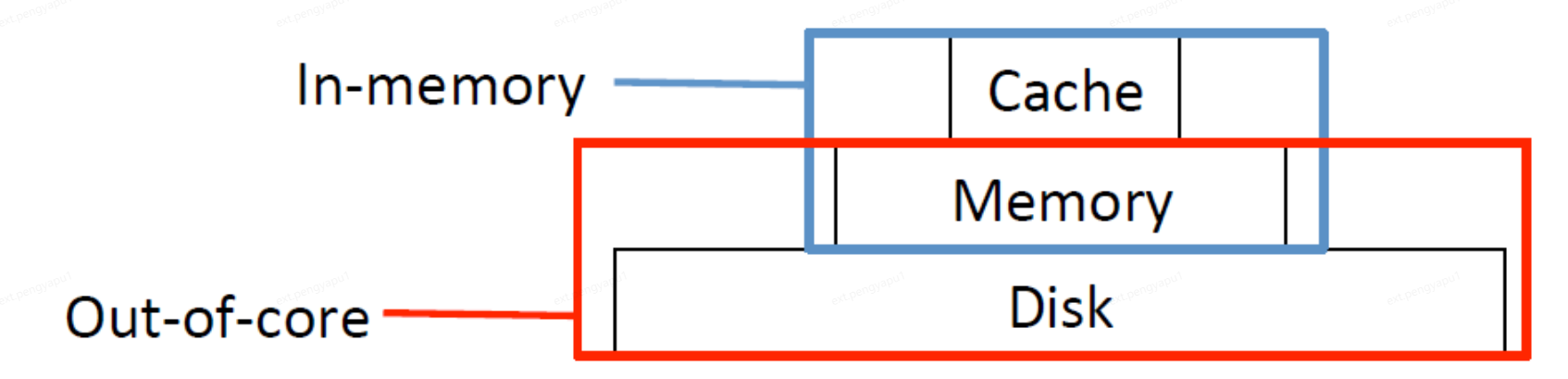
那么如何选择Partition呢?
粒度越细(即P值越大),预处理时间越长,P越大,每一个chunk能表示的范围越广,那么每个block能存储的边数据越多,顶点数据的访问局部性越好,block置换概率越低,选择性调度潜力就越大。因此,在划分时,P越大越好。目前,我们暂时选择P的最大值,这样顶点数据可以适应最后一级缓存。那么P的最小值可以这样设定:
(V/P)*U<=C<=>P>=C/UV
其中V是图的顶点数,C是最后一级cache缓存的大小,U是每个顶点的大小。(V/P)表示chunk中可表示的顶点范围,(V/P)*U则表示每个chunk的大小,为了适应最后一级缓存,能够一次将一个chunk的所有数据放入最后一级缓存中,则chunk的大小应小于等于C,公式进行变换得到P的最小值为C/UV.
这种分区方式不仅表现出良好的性能(特别是在内存情况下),而且节省了很多的预处理成本。
The Streaming-Apply Processing Model
GridGraph使用流应用处理模型,在该模型中只需要读取边一次,并且只需遍历一次顶点即可完成写I/O总量。
GridGraph提供了两个流式处理函数分别处理顶点(Algorithm1)和边(Algorithm2):

F是一个可选的用户自定义函数,它接受顶点作为输入(StreamVertices时是当前顶点,StreamEdges时是block中每一条边的源顶点),并且返回一个布尔值来指示流中是否需要该顶点。当算法需要选择性调度用于跳过一些无用的流时通常与位图一起使用,位图可以紧凑地表示活动顶点集。
Fe和Fv是用户自定义的描述流处理的函数,Fe接受一个边做为输入,Fv接受一个顶点做为输入,返回一个R类型的值,返回值被累加,并作为最终结果提供给用户。该值通常用于获取活跃顶点的数量,但不限于此用法,例如,用户可以使用这个函数来获得PageRank中迭代之间的差异之和,以决定是否停止计算。
GridGraph将顶点数据存储在磁盘上。使用内存映射机制(将顶点数据文件通过mmap内存映射机制映射到内存中)来引用文件中的顶点数据,每个顶点数据文件对应一个顶点数据数组。因此访问顶点数据文件就像访问内存中的数组一样,并简化了编程模型:开发人员可以将其视为普通数组,就像它们在内存中一样。
以PageRank为例,我们来看看GridGraph是如何实现算法的。
PageRank是一种链接分析算法(Algorithm3),计算图中每个顶点的数值权重,以测量其在顶点之间的相对重要性。初始所有顶点的PR值都是1,在每次迭代中,每个顶点向邻居发送自己的贡献,即当前PR值除以它的出度。每个顶点将从邻居收集到的贡献进行汇总,并将其设置为新的PR值。当均值差达到某个阈值时,算法收敛。

Dual Sliding windows 双滑动窗口模式
GridGraph流式读取每个block的边,当block在第i行第j列时,和这个block相关的顶点数据也落在第i行第j列的chunk中,每个block都包含两个顶点chunk,source chunk(源顶点chunk)和destination chunk(目的顶点chunk)。
通过P的设定,使得block足够小,能够将一个block放入最后一级缓存中,这样在访问与block相关的顶点数据时,可以确保良好的局部性。
根据更新模式,block的访问顺序可以是面向行或面向列的。假设顶点状态从源顶点传播到目标顶点(这是许多应用程序中的典型模式),即源顶点数据被读取,目标顶点数据被写入。由于每个边block的列对应于目标顶点块,需要对目标顶点块进行写操作,在这种情况下优先采用面向列的访问顺序。当目的顶点所在block被缓存在内存中时,GridGraph从上到下流向同一列中的block,因此昂贵的磁盘写操作被聚合和最小化。特别是对于SSD系统来说,这是一个非常重要的性能,写入大量数据写性能会相应下降。另一方面,由于SSD有写入周期的上限,因此尽可能减少磁盘随机写入以实现理想的持久性是很重要的。

以PageRank为例,我们来看看GridGraph是如何使用双滑动窗口对顶点信息进行更新。读窗口(从源顶点数据中读取当前顶点的PageRank值和出度)和写窗口(对目标顶点的新PageRank值的贡献进行累加)作为GridGraph流沿block以面向列的顺序滑动。
1、初始化,每个顶点初始的PR值都为1
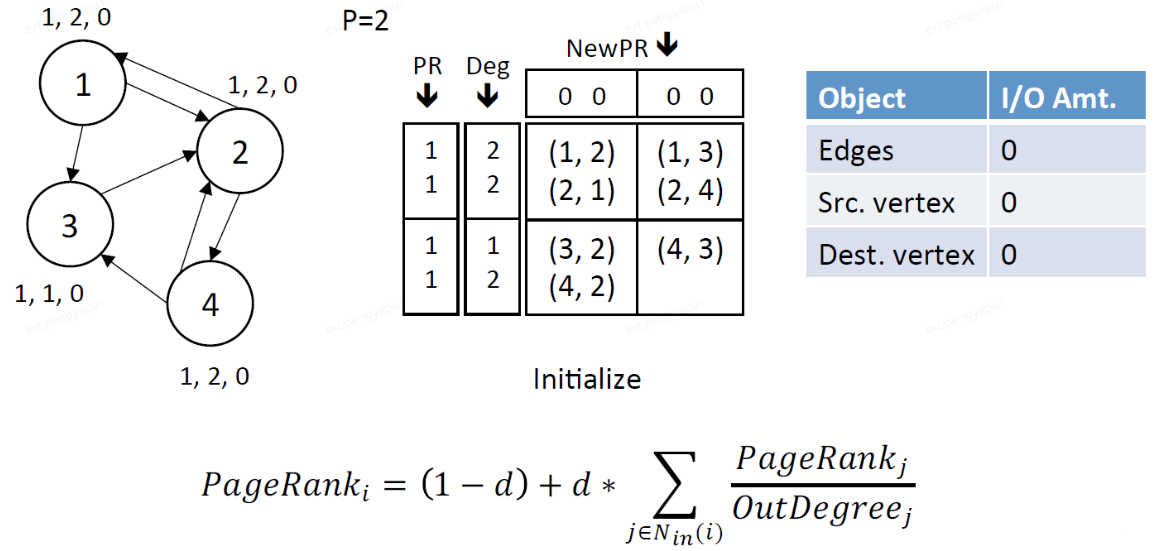
2、Stream edge block(1,1),此时src.chunk 1和dest.chunk 1都加载进内存中
读窗口:读取src.chunk 1的PR和Deg
写窗口:写dest.chunk 1的NewPR
IO总量:读取block中2条边,读取src.chunk 1中的顶点(1,2),读取dest.chunk 1中的顶点(1,2)
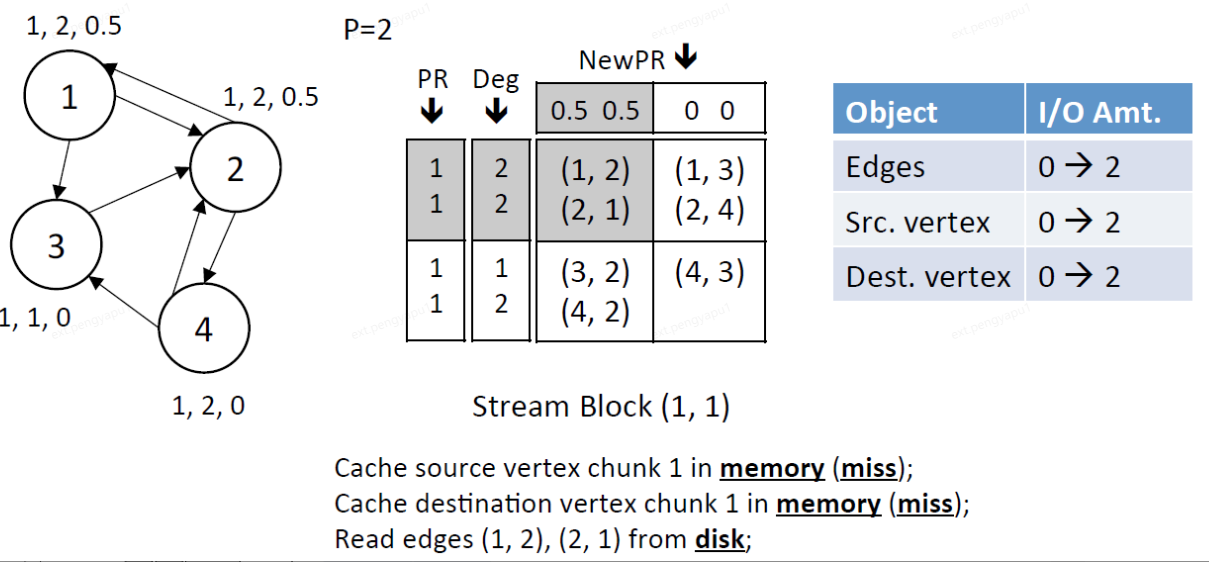
3、Stream edge block (2,1),此时dest.chunk 1在内存中,将src.chunk 2也加载进内存中
读窗口:读取src.chunk 2的PR和Deg
写窗口:写dest.chunk 1的NewPR
IO总量:读取block中2条边,读取src.chunk 2中的顶点(3,4)
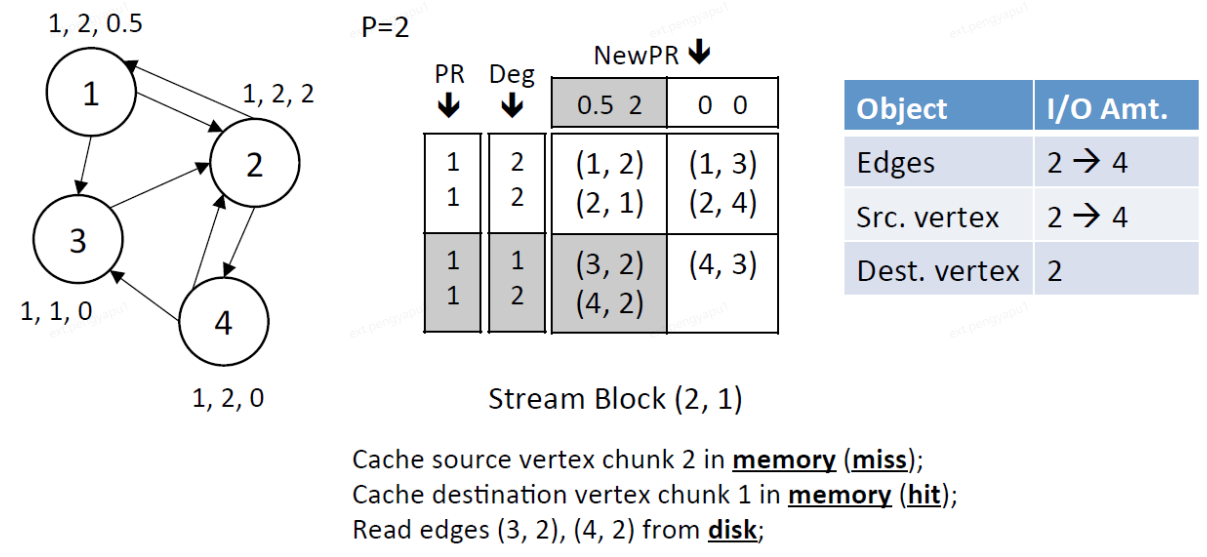
4、Stream edge block (1,2),dest.chunk 1已经全部更新完成,将更新后的dest.chunk1写回磁盘种,将src.chunk 1和dest.chunk 2加载进内存中
读窗口:读取src.chunk 1的PR和Deg
写窗口:写dest.chunk 2的NewPR
IO总量:读取block中2条边,将dest.chunk 1中的顶点(1,2)的结果写入磁盘,读取src.chunk 1中的顶点(1,2),读取dest.chunk 2中的顶点(3,4)
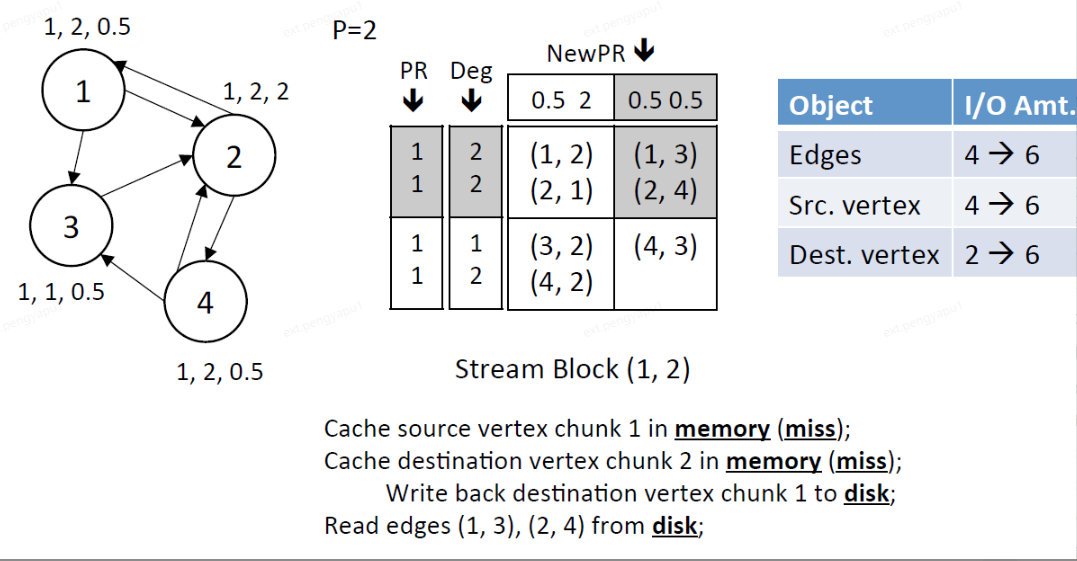
5、Stream edge block (2,2),此时dest.chunk 2在内存中,将src.chunk 2也加载进内存中
读窗口:读取src.chunk 2的PR和Deg
写窗口:写dest.chunk 2的NewPR
IO总量:读取block中1条边,读取src.chunk 2中的顶点(3,4)
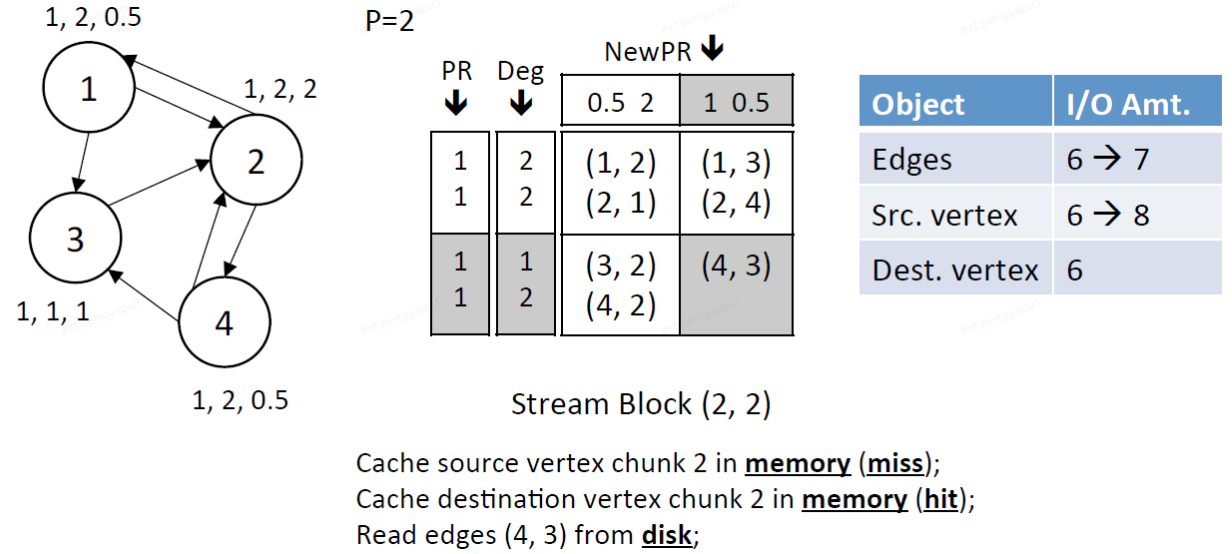
6、完成dest所有chunk的遍历,将dest.chunk 2更新后的结果写入磁盘中。
IO总量:将dest.chunk 2中的顶点(3,4)的结果写入磁盘中。
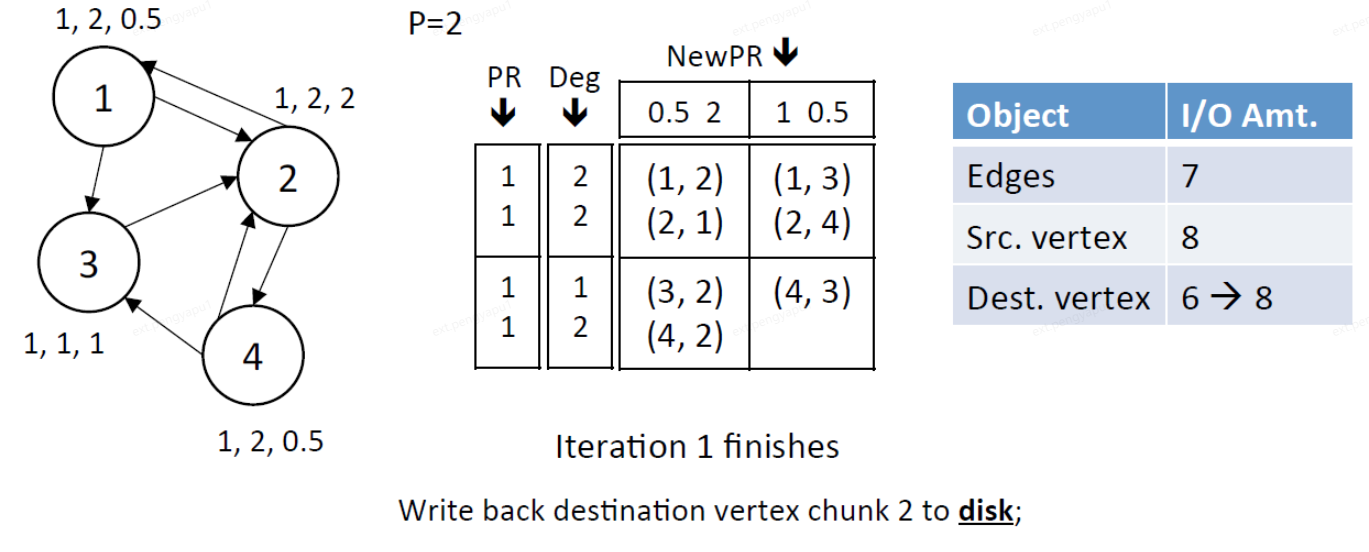
在上面的一次流应用迭代中给出了网格图的I/O分析,其中所有的边和顶点都被访问。以面向列的顺序访问边block为例:所有边被访问一次,源顶点数据被读取P次,而目标顶点数据被读写一次。在一次完整迭代并收敛中使用的IO:
E+(2+P)*V
E:表示读取所有边
2:读取和写入目标顶点的数据
P:读取每个P中源顶点数据
通过对边的只读访问,GridGraph所需的内存非常紧凑。事实上,它只需要一个小的缓冲区来保存正在Stream的边blocl,以便页缓存可以使用其他空闲内存来保存更多的边block,当活跃边block变得足够小以适合内存时,这是非常有用的。这种Streaming-Apply-Processing-Model流式应用模型的另一个优点是它不仅支持经典的BSP模型,而且还允许异步更新。由于顶点更新是即时的,更新的效果可以通过跟踪顶点的遍历来获得,这使得许多迭代算法收敛得更快。由此可看出:P应该是使顶点数据放入内存的最小值。因此,更小的P应该是最小化I/O量的首选,这似乎与上面我们所说P越大越好,更大的网格分区原则相反。
Selective scheduling 选择调度
前面我们已经解释过什么是选择调度,即跳过不活跃的边block。在Stream函数中的由F传入位图,由此跳过不活跃的边block。
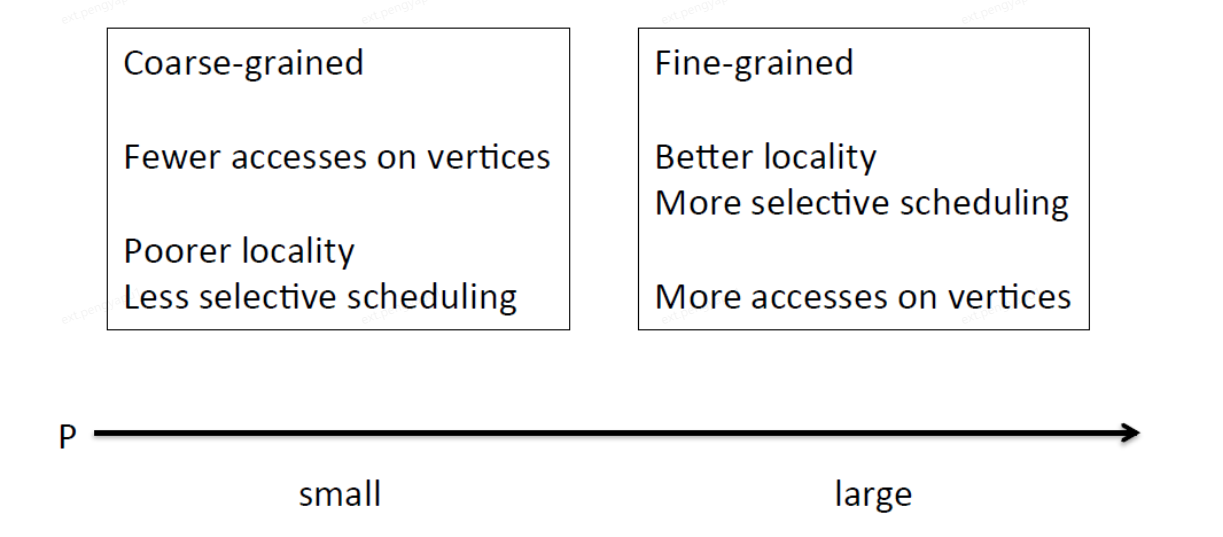
P越小,粒度越粗,访问顶点的次数更少,更差的局部性,选择调度更差
P越大,粒度越细,更好的局部性,选择调度更好,访问顶点的次数更多
为了解决这个难题,在边网格上应用了二级分区,以减少顶点的I/O访问。
2-level hierarchical partitioning
在P*P的网格中再进行一层网格划分,第二层网格有Q*Q个边网格。将Q*Q的分区应用在P*P的网格中。
Q的选择应满足:
(V/Q)*U <= M
M是给定的内存容量。
在前面我们提到,P的选择是为了将顶点数据放入容量远小于内存的上一级缓存中,因此P应该远大于Q。
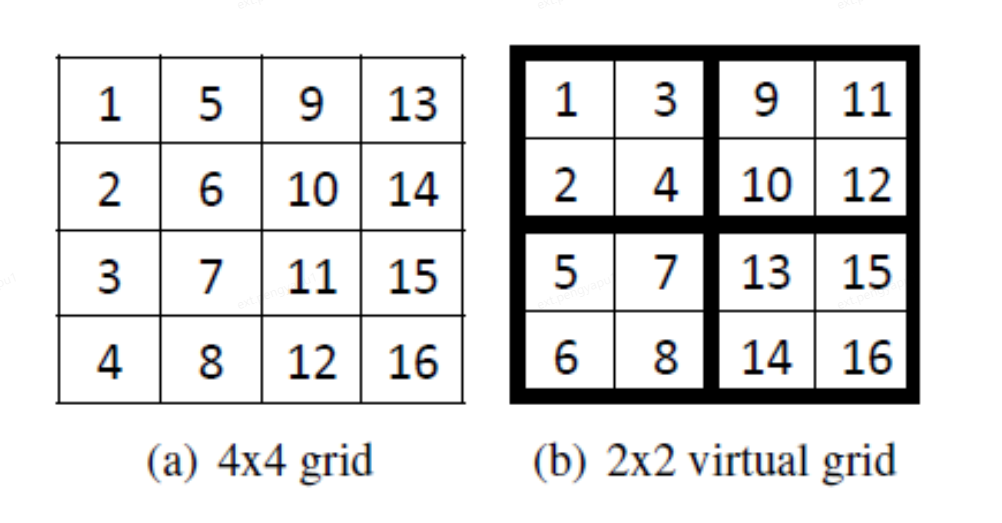
整个网格被分成4个大块,每个大块包含4个小块。每个块内的数字表示访问顺序。在原始的4×4分区中使用了精确的面向列的访问顺序。在应用了二级分区后,P:2×2 变成 Q:4×4分区之后,我们以面向列的顺序访问粗粒度(大)块,在每个大块中,我们访问细粒度的块(小)块以列为导向的顺序。这种2级分层分区不仅提供了灵活性,而且还提高了效率,因为高级分区(第二级分区)是虚拟分区,GridGraph能够利用较低级别分区(第一级分区)的结果,因此不会增加更多的实际开销。并且可以使用P网格划分的结果进行选择调度。
总结
GridGraph定义了一种新的图表示形式:网格划分,用于适应有限的内存;使用双窗口模式减少IO访问的总量,特别是写IO;使用选择调度减少掉无用的IO;使用2级分区划分方式保证了P尽可能大的同时减少IO访问。GridGraph在有限的内存中,并提高IO效率,高效的完成了核外图计算过程。
GridGraph源码分析
源码地址:https://github.com/thu-pacman/GridGraph
数据预处理模块
将原始二进制文件处理成grid格式的block文件
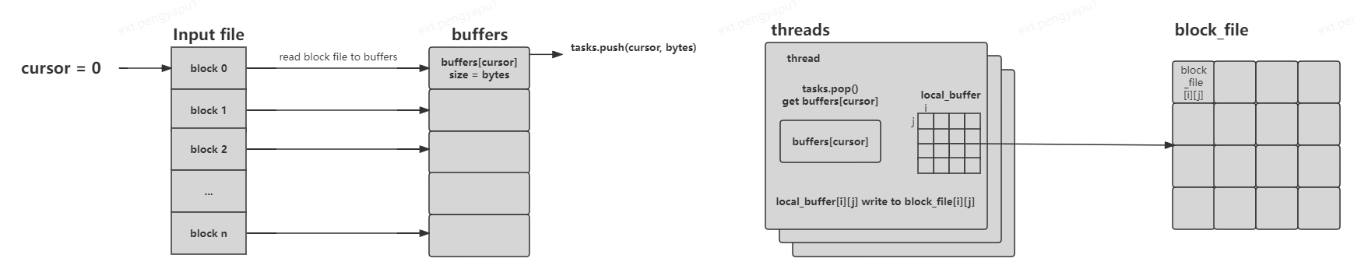
我们来看看block文件是如何划分处理的:
从input文件中遍历读取IOSIZE的数据放入buffers[cursor]中,tasks记录当前当前游标的字节数<cursor, bytes>,在threads中获取tasks中的cursor和bytes,根据cursor读取buffers中的数据,将buffers[cursor]中的数据根据src和dst所属的partition,放入local_buffer[i][j]中,将local_buffer[i][j]的数据分别写入block[i][j]文件中。如下图所示:
代码位于:tools/preprocess.cpp
1、打开文件读取数据,将数据加入task处理,在这里,buffers的定义是全局的,tasks保存cursor和buffers数据大小。
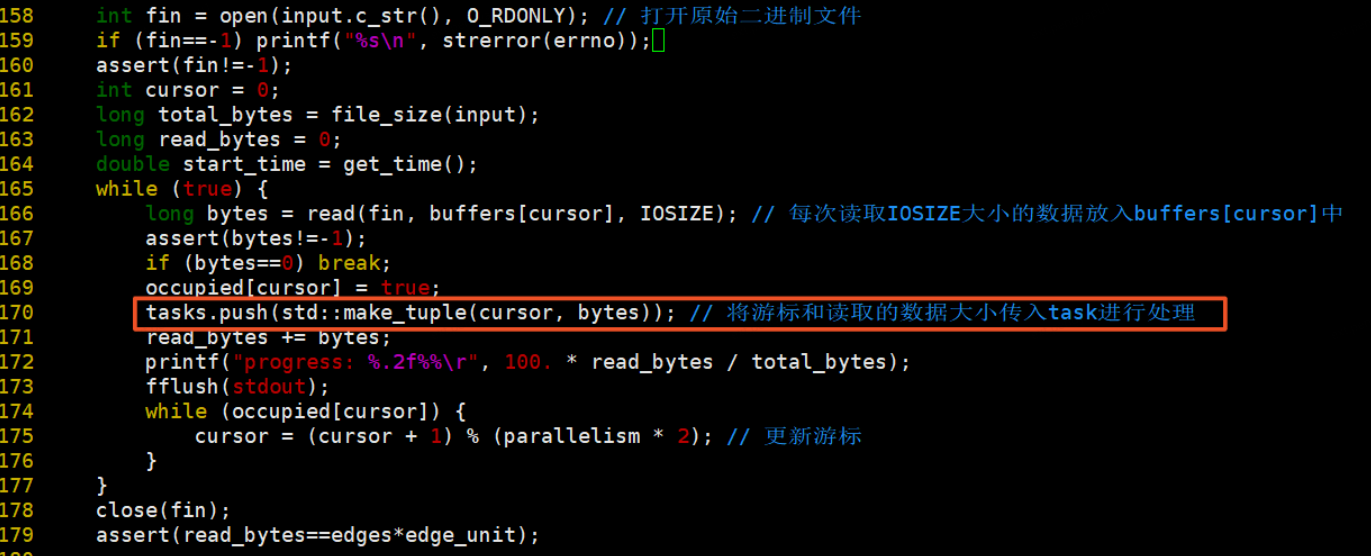
2、那么我们来看看tasks是什么,tasks是一个队列,保存当前游标和数据大小。grid_buffer_size = 12*8*8,12表示<4 byte source, 4 byte destination, 4 byte float typed weight>,8*8表示每次读取到64byte的数据时写一次磁盘,是个magic number。
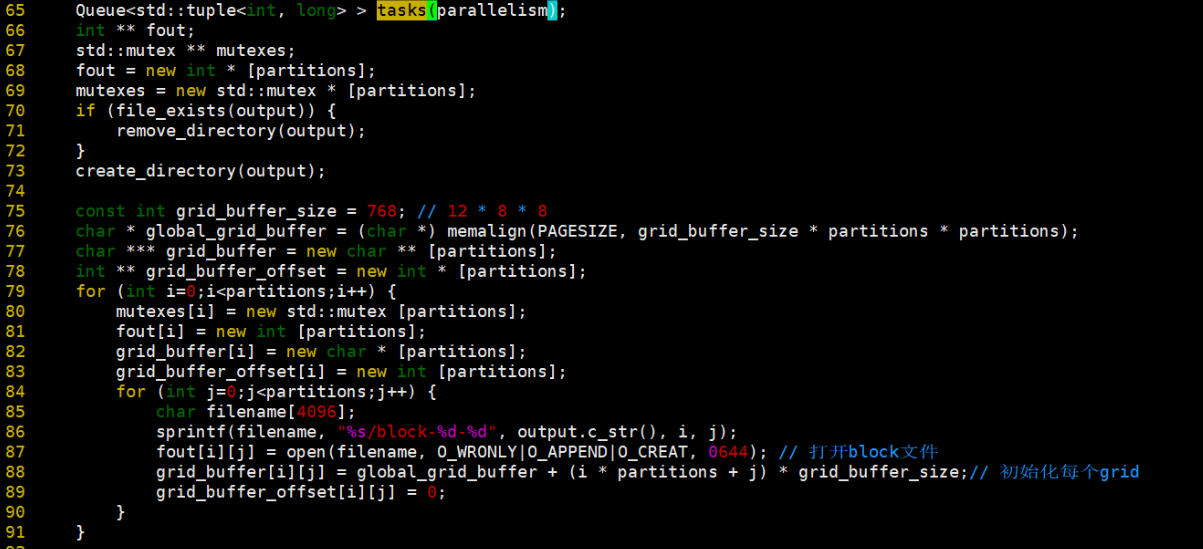
3、真正进行数据处理的是threads的任务。每个thread处理一个buffers[cursor]的数据。
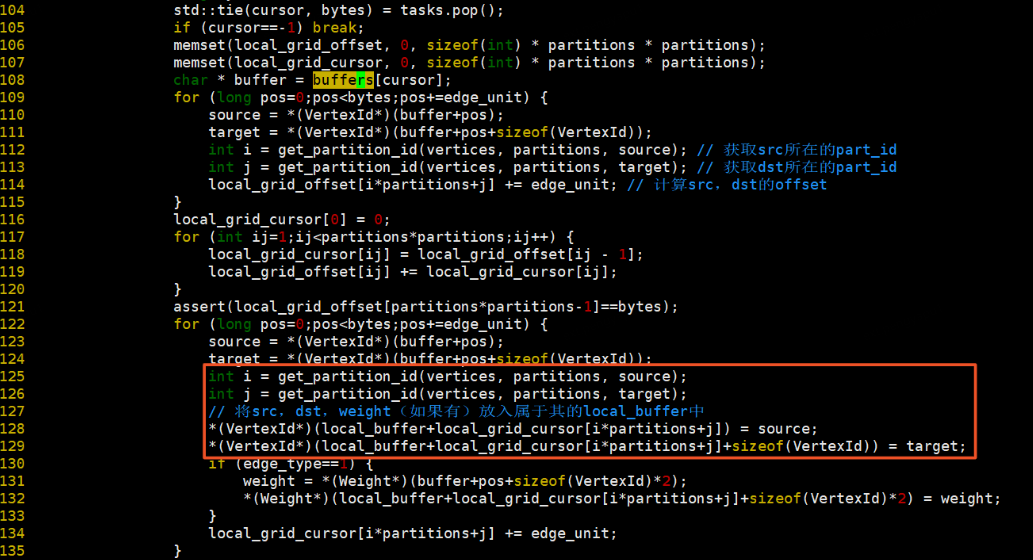
将local_buffer的数据写入对应的block文件中
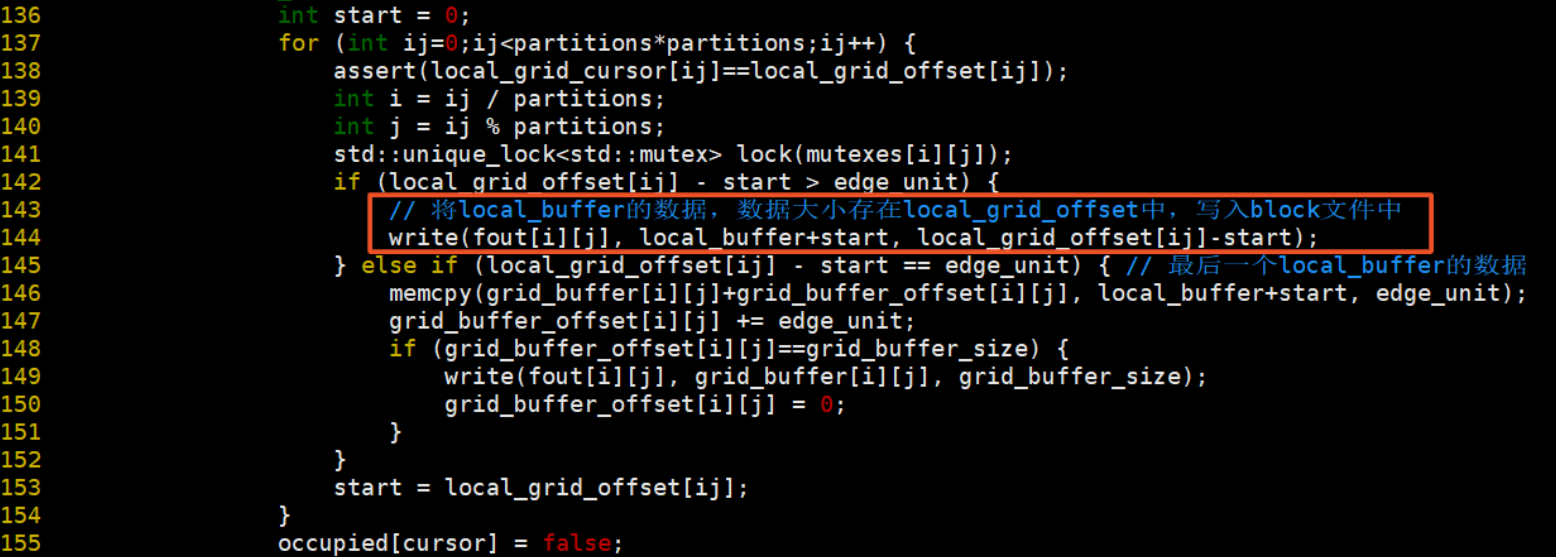
4、生成column文件,将所有block文件按照列遍历方式保存到column文件中,并将每个block文件的大小保存至column_offset文件中。
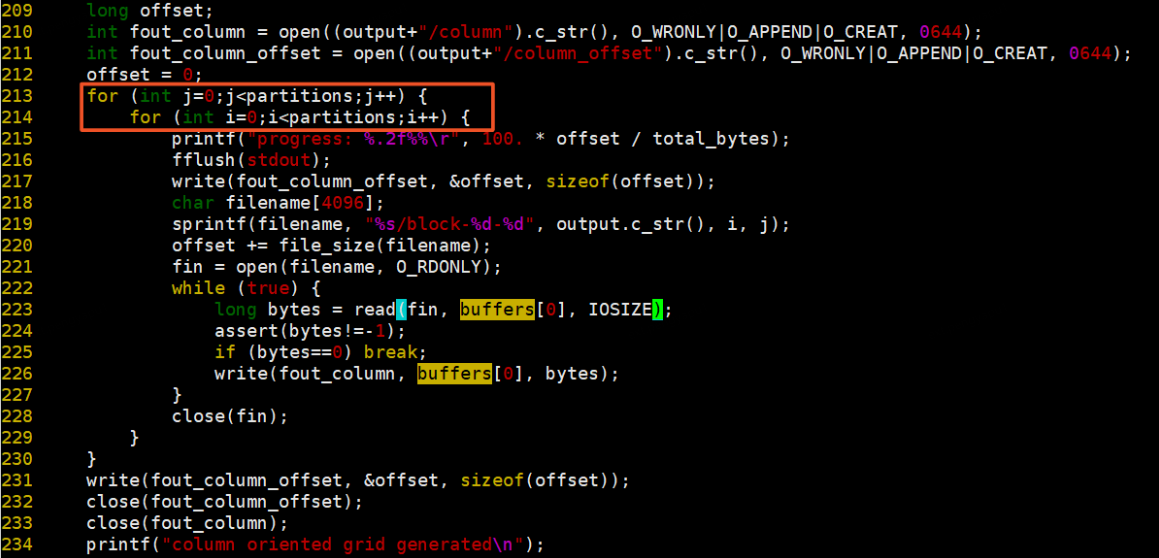
5、同理生成row文件,按照行遍历方式读取block文件写入row文件中,并记录offset。

6、最后将处理好的数据信息(是否含有权重,顶点数,边数,partition数)写入meta文件中。

执行grid代码后,会生成P*P个block文件,一个column文件、row文件、column_offset、row_offset及meta文件。
Graph实现
代码位于:core/graph.hpp
init
空间初始化,并读取meta信息和column_offset、row_offset的数据,并记录每个block文件大小
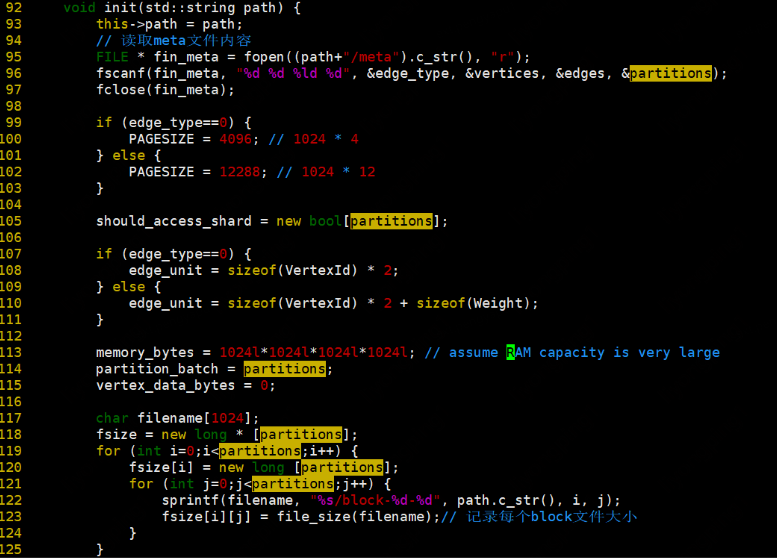
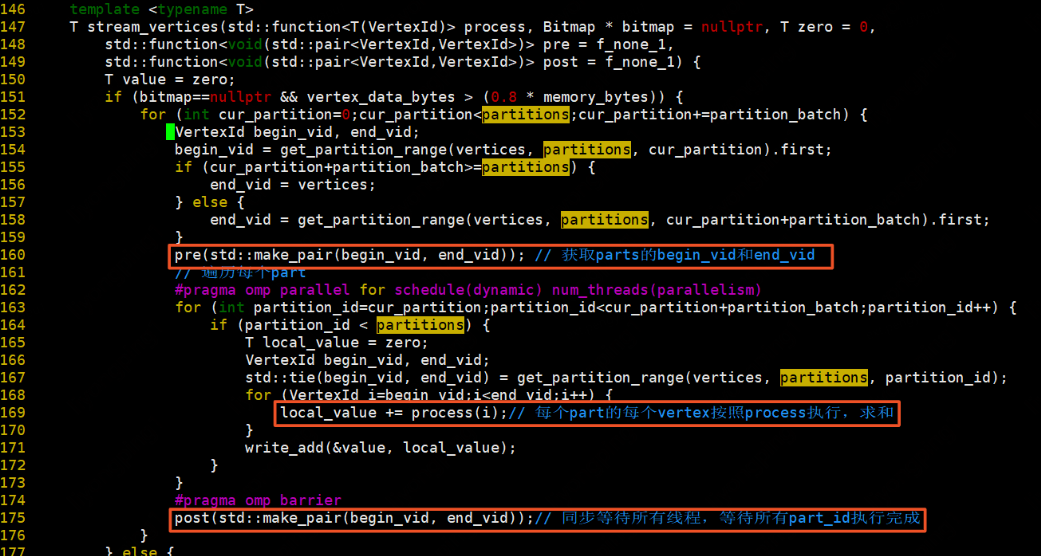
stream_vertices:
如果bitmap为空,并且顶点数据字节总数(顶点数据字节总数初始化为0,可在算法实现时设置,一般为顶点总数顶点大小)大于0.8内存字节数,先获取partitions的begin_vid和end_vid,再遍历每一个partition,每个partition中的每个vertex按照process执行,将返回值求和相加。最后等待所有partition执行结束,得到begin_vid和end_vid。
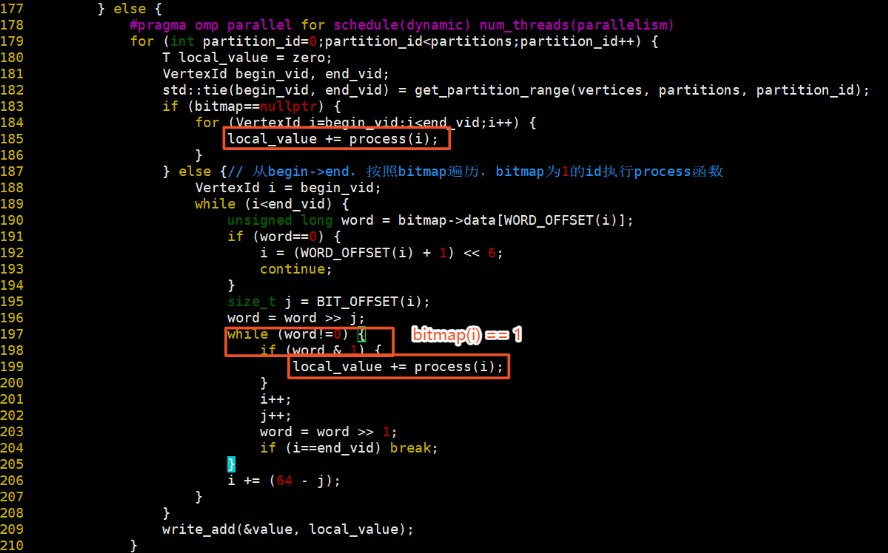
如果bitmap不为空或者顶点数据字节总数小于等于0.8*内存字节数,则遍历每一个partition,获取每个partition的begin_vid和end_vid。如果bitmap为空,则遍历partition中的所有顶点,按照process执行,返回值相加。否则,从begin_vid开始,按照bitmap遍历,bitmap为1的vid执行process,返回值相加。
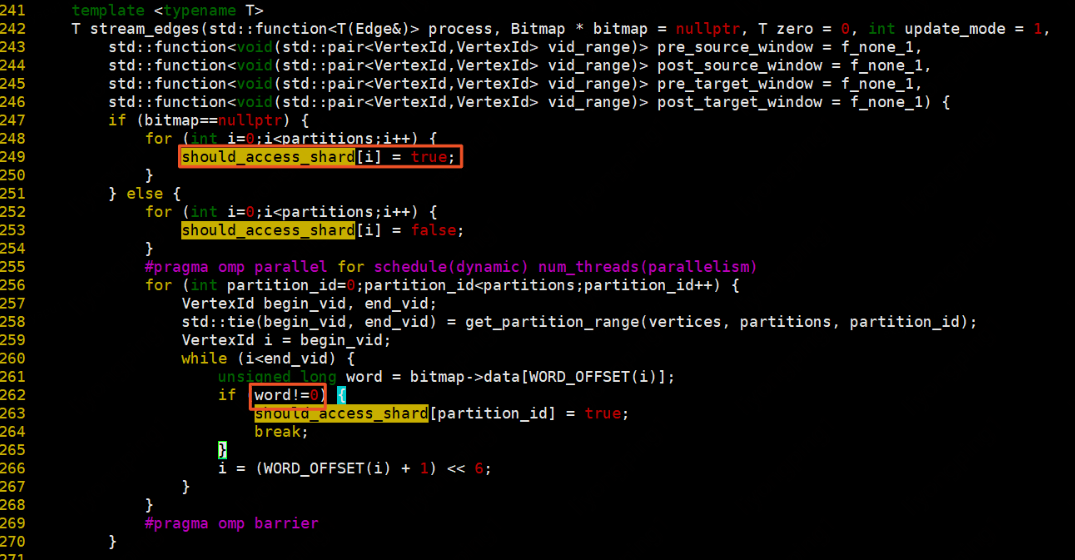
stream_edges:
根据bitmap决定需要遍历的partition,如果bitmap为空,则所有partition都要遍历,bitmap不为空根据partition中是否包含bitmap中的vid,包含则该partition需要遍历。
统计所有需要遍历的partition的文件总大小
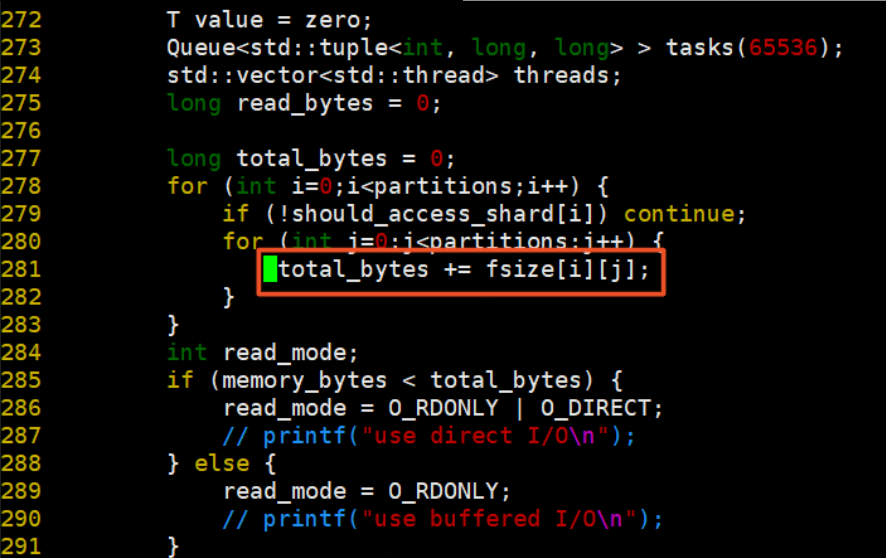
默认update_mode=1,若update_mode=0则为行更新模式(行主序更新),update_mode=1则为列更新模式(列主序)。数据准备阶段:
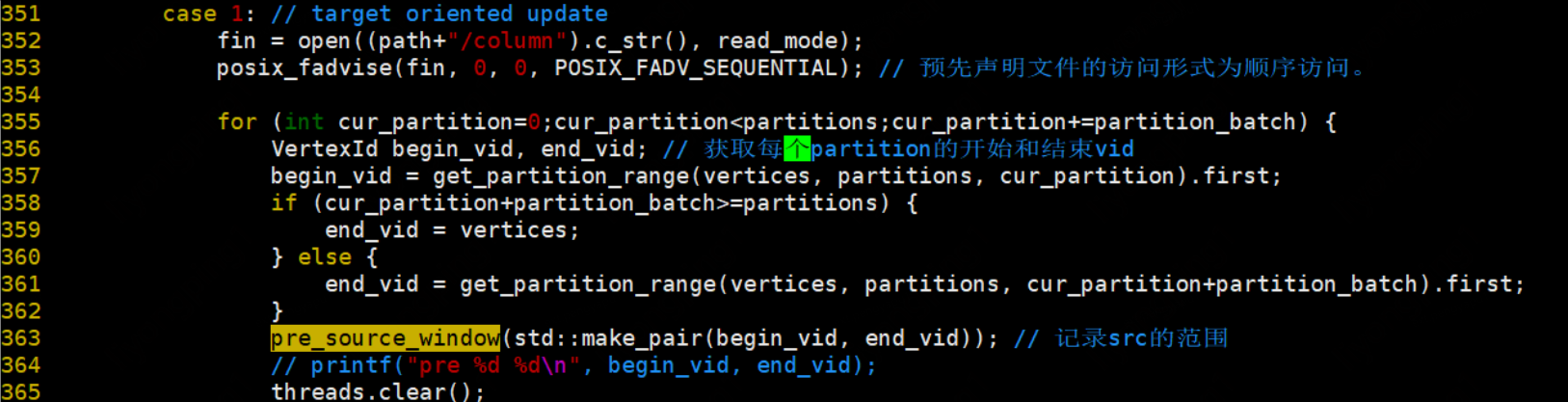
遍历需要访问的分区,分区访问方式为:列不变,行从小到大进行遍历,行遍历完后列再向右移。每次读取分区中IOSIZE大小的数据,最后不够IOSIZE则读取PAGESIZE大小的数据
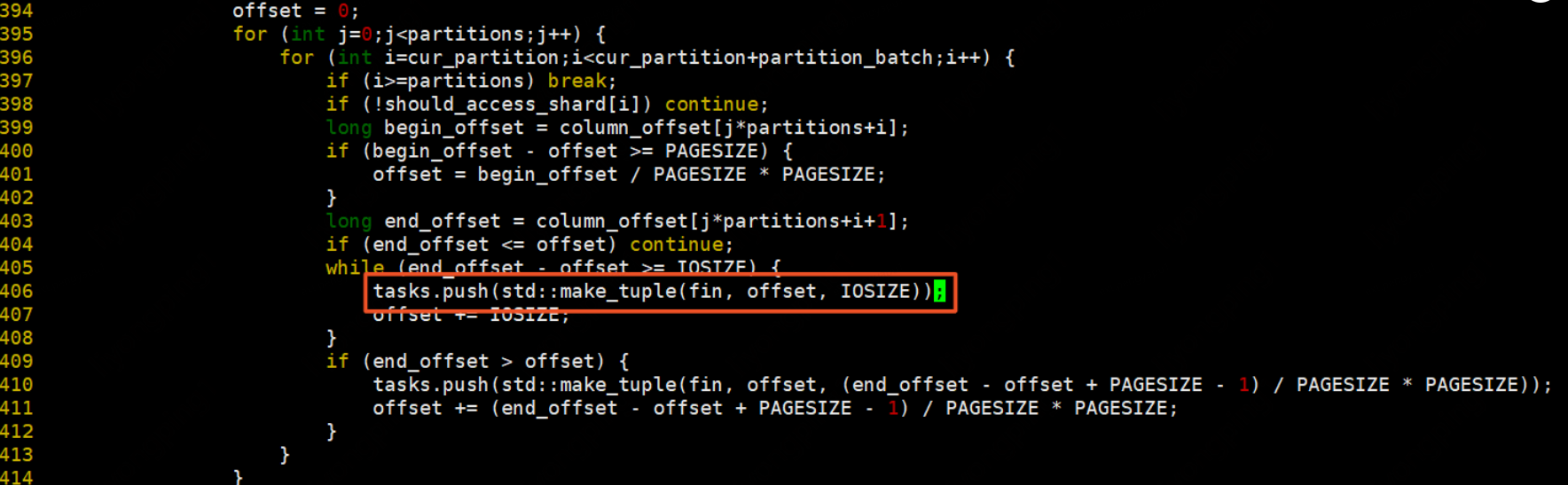
每条边按照process的方法执行操作

若是行主序,实现则如下:按照行遍历方式读取需要遍历的partition,每次处理IOSIZE大小的数据
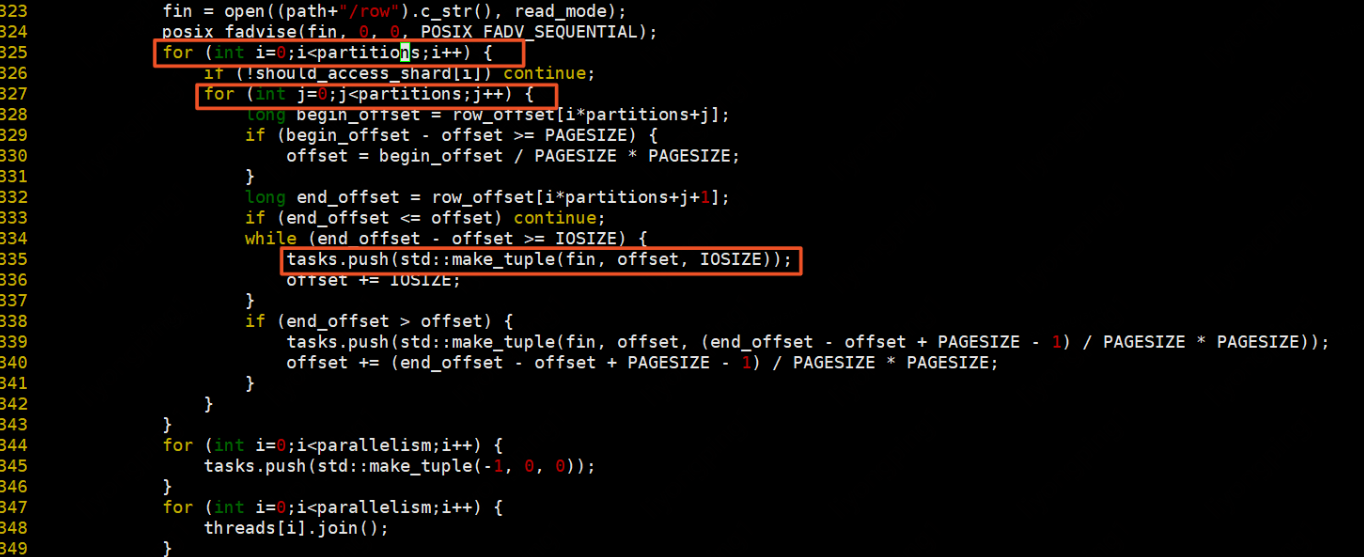
数据处理方式则是读取row文件,从offset开始读取length的数据放入buffer中,然后遍历每一条边,每条边按照process执行。
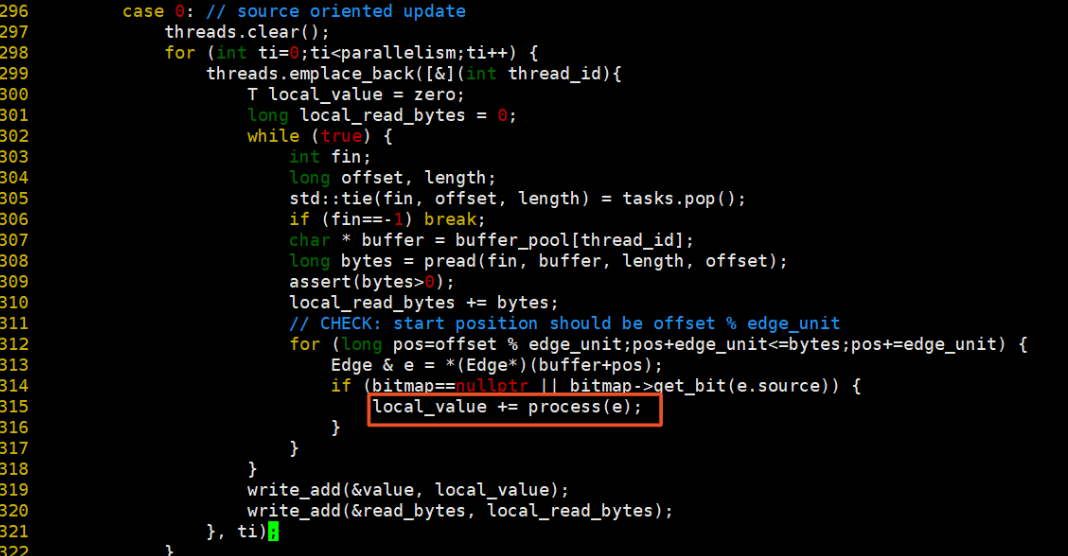
下面我们来看看实际使用,以PageRank算法实现为例,这里不再详述PageRank算法原理。
PageRank算法实现
代码位于:example/pagerank.cpp
先初始化每个顶点的degree:在这里update_mode=0,使用行主序更新。
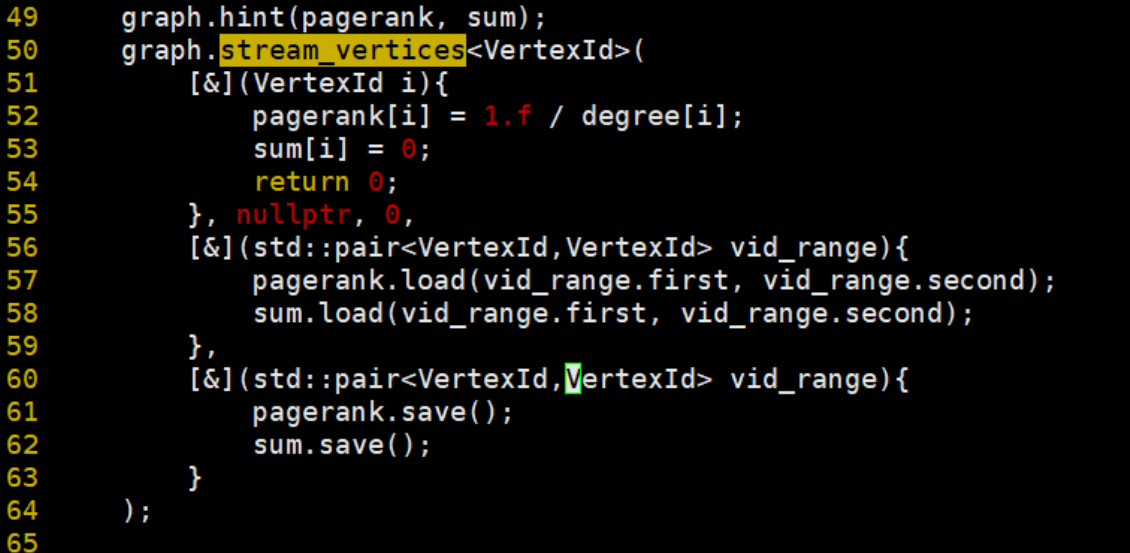
初始化每个顶点的pr值为1:
遍历每一条边更新计算每条边的贡献值:

更新每个顶点上的pr值,最后一轮迭代则直接计算并更新sum:
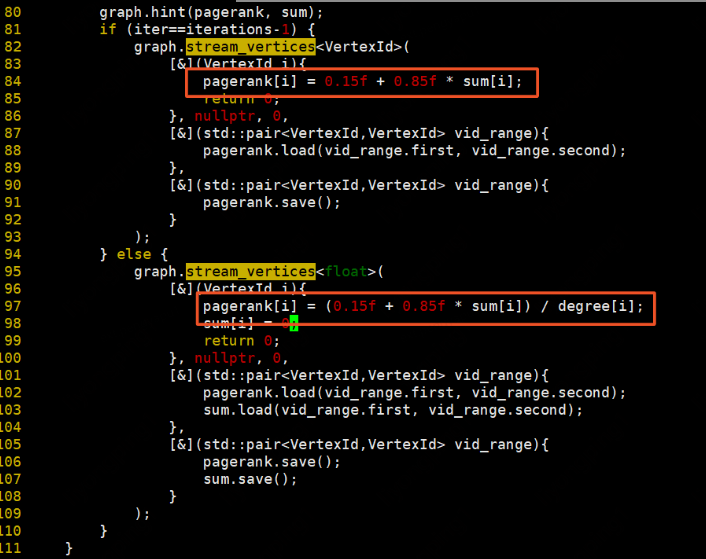
总结
在grid文件处理中,有几个可优化的点:
1)、在读取输入文件时,可以根据文件个数并行读取文件,加快文件处理速度。
2)、初始化grid空间,因为初始化时每个block互不影响,可以使用omp并行初始化提高效率。
3)、thread线程中,因为每个线程处理的是不同的cursor的buffers数据,每个thread生成自己的local_buffer写入block文件,因为threads中没有数据交互,因此也可以并行化。
在stream_vertices和stream_edges我们都进行了分析,可以看出,不论是行主序还是列主序,都免不了折线式(Z型)的边block遍历策略,其可优化的点如下:
1、可将Z型边遍历可更改一下,改成U形遍历,以列主序为例,当遍历到最后一行的src时,src不变保持在内存中,此时dst向右移,src从下往上遍历,以此类推,可节省P次的页面置换。
GridGraph提供一种在有限内存中完成大规模图计算系统。解决单机内存或分布式内存无法解决的大规模图计算问题。提供一种新式的切图方式,将顶点和边分别划分为1D chunk和2D block来表示大规模图的网格表示;使用一种新的streaming-apply模型,提高IO,对顶点的局部性友好的方式流化读取边block;GridGraph能够在不涉及I/O访问的情况下访问内存中的顶点数据,并且跳过不需要遍历的边block,提高算法执行效率。
GridGraph将顶点划分为P个顶点数量相等的chunk,将边放置在以P*P的网格中的每一个block中,边源顶点所在的chunk决定其在网格中的行,边目的顶点所在的chunk决定其在网格中的列。它对Cache/RAM/Disk进行了两层级的网格划分,采用了Stream vertices and edges的图编程模型。计算过程中的双滑动窗口(Dual Sliding Windows)也大大减少了I/O开销,特别是写开销。以block为单位进行选择调度,使用原子操作保证线程安全的方式更新顶点。论文中提到在边网格上采用压缩技术,以进一步降低所需的I/O带宽,提高效率。
参考文献:
1. Xiaowei Zhu, Wentao Han and Wenguang Chen. GridGraph: Large-Scale Graph Processing on a Single Machine Using 2-Level Hierarchical Partitioning. Proceedings of the 2015 USENIX Annual Technical Conference, pages 375-386.
2. ZHU Xiaowei — GridGraph: Large-‐Scale Graph Processing on a Single Machine. Using 2-‐Level Hierarchical Parffoning. Xiaowei ZHU, Wentao HAN, Wenguang CHEN.Presented at USENIX ATC '15
3. Amitabha Roy, Ivo Mihailovic, Willy Zwaenepoel. X-Stream: Edge-centric Graph Processing using Streaming Partitions
4. Aapo Kyrola Carnegie Mellon University akyrola@cs.cmu.edu, Guy Blelloch Carnegie Mellon University guyb@cs.cmu.edu,Carlos Guestrin University of Washington guestrin@cs.washington.edu. GraphChi: Large-Scale Graph Computation on Just a PC
原文链接:https://www.cnblogs.com/Jcloud/p/17334073.html
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:图计算引擎分析–GridGraph - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 