Attention and Augmented Recurrent Neural Networks

神经 Turing 机器有它们能够读和写的外部的记忆
attention接口让循环神经网络聚焦于部分输入
自适应计算时间允许每一步的计算量不同
神经程序员能调用函数,在它们运行时构建程序
都依靠相同的基本技巧(称为attention)来工作。
神经 Turing 机器
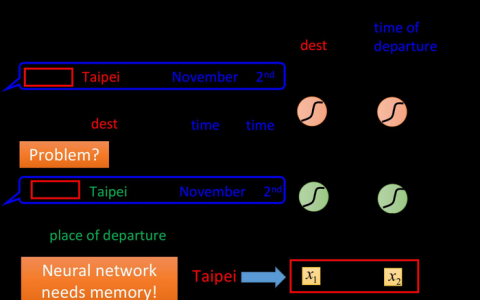
神经 Turing 机器将循环神经网络与外部记忆库相结合。由于向量是神经网络的自然语言,所以记忆是向量的数组:

想根据读和写的位置让读和写不同,所以可以学习在哪里读和写
这是一个棘手的问题,因为记忆地址似乎基本上是离散的。
神经 Turing 机器们在每一步在任何位置都读和写,只是程度不同
读
循环神经网络输出一个“attention分布”,描述如何分散所关心的不同记忆位置,而不是指定一个位置。因此,读操作的结果是一个加权和。

写
在不同程度上同时在任何位置写,只是程度不同
attention分布描述了应该对每个记忆位置的写值进行多大程度的改变。
通过让在记忆中一个位置的新值是旧记忆内容和写值的凸组合来实现这一点,而两者之间的位置由attention权重决定。

决定将attention集中在记忆中的位置
神经 Turing 机器们结合使用了两种不同的方法,来决定将attention集中在记忆中的位置在哪
1、基于内容的attention允许神经 Turing 机器们在他们的记忆中进行搜索,并将attention集中在与他们正在寻找的相匹配的地方
2、基于位置的attention允许在记忆中进行相对移动,从而使神经 Turing 机器能够进行循环。
动图点击我
1、控制器给出一个query向量
通过点乘来对每个记忆条目与query向量的相似性进行评分,得到相似性分数。
越蓝越相似,越粉越不相似
2、使用softmax将分数转换为分布
3、从上一个时间步 interpolate attention
输出attention = interpolation amount * 上一个时间步的attention + (? - interpolation amount) * 分布
interpolation amount 越大,输出attention 越像 上一个时间步的attention
interpolation amount 越小,输出attention 越像 分布
4、将attention与移位滤波器进行卷积,这允许控制器移动它的focus
5、sharpen attention 分布。
这个最后的attention分布被提供给读或写操作。
简单的算法
这种读写能力使得神经 Turing 机器们能够执行许多简单的算法,这在以前是神经网络所不能企及的。
1
神经 Turing 机器们可以学习在记忆中存储一个很长的序列,然后对其进行循环,重复地将其返回。
当他们这样做的时候,可以观察他们读和写的地方,以便更好地理解他们在做什么:

2
神经 Turing 机器们还可以学习模仿查找表,甚至学习对数字排序(尽管它们有点欺骗)!
3
神经 Turing 机器们仍然不能做很多基本的事情,比如加法或乘法。
论文
神经GPU[PDF]克服了神经 Turing 机器不能加和乘数字的缺点。
[PDF]使用强化学习来训练神经 Turing 机器们,而不是原始的可区分的读写。
神经随机存取机器[PDF]基于指针工作。
可区分的数据结构,如栈和队列[PDF][PDF]
记忆网络[PDF][PDF]
Code
神经 Turing 机器
Taehoon Kim’s (TensorFlow), Shawn Tan’s (Theano), Fumin’s (Go), Kai Sheng Tai’s (Torch), and Snip’s (Lasagne).
Neural GPU
Memory Networks
Facebook’s (Torch/Matlab), YerevaNN’s (Theano), and Taehoon Kim’s (TensorFlow).
attention接口
神经网络可以使用attention来只关注他们所获得信息的一部分。 例如,一个循环神经网络的输出可以作为另一个循环神经网络的输入。 在每个时间步,它关注于另一个循环神经网络的不同位置。
我们希望attention是可以区分的,所以我们可以学习在哪里focus。
为了做到这一点,使用在神经 Turing 机器中相同的技巧:focus任何位置,只是程度不同。

attention distribution通常是由基于内容的attention产生的。
参与的循环神经网络生成一个query,描述它希望关注什么。
每个item都与query点乘,以生成一个分数,该分数描述item与query的匹配程度。
分数被输入到一个softmax中,以创建attention distribution。

循环神经网络们之间的这种attention的用途
翻译
传统的序列到序列模型必须将整个输入简化为单个向量,然后再将其展开。
attention避免了这个问题,通过让循环神经网络处理输入,来传递它看到的每个单词的信息,然后当这些单词变得相关时,让循环神经网络生成输出,将attention集中在这些单词上

语音识别
语音识别允许一个循环神经网络处理音频,然后让另一个循环神经网络浏览它,在生成transcript时focusing on相关部分。

解析文本
允许模型在生成解析树时查看单词
会话建模
允许模型在生成响应时关注会话的前一部分
卷积神经网络和循环神经网络之间的接口
卷积神经网络和循环神经网络之间的接口也可以使用attention。
这使得循环神经网络可以在每一步中查看图像的不同位置。
这种attention的一个流行用法是图像标注。
1、conv网络对图像进行处理,提取高级特征。
2、运行循环神经网络,生成图像的描述。
当循环神经网络生成描述中的每个单词时,它focuses on conv网络对图像相关部分的解释上。
我们可以明确地把它可视化:

Show, attend and tell: Neural image caption generation with visual attention
当想要interface with输出中具有重复结构的神经网络时,可以使用attentional interfaces
自适应计算时间
标准的循环神经网络们对每个时间步执行相同的计算量。当事情变得困难时,应该多想想。它还限制了循环神经网络们对长度为n的列表执行O(n)操作。
自适应计算时间在每一步为循环神经网络们做不同数量的计算。
总体思路是允许循环神经网络为每个时间步执行多个计算步骤。
为了让网络了解要执行的步骤个数,用以前使用的相同技巧实现步骤数是可区分的:不决定要运行一个离散的步骤个数,而是对要运行的步骤个数进行attention distribution。

对于每个时间步,循环神经网络都可以执行多个计算步骤。
设置一个特殊位来表示第一个计算步骤。
输出是每个步骤的输出的加权组合。
对于每个时间步都重复此过程。
细节

运行循环神经网络并输出状态的加权组合
在较高级别上,仍在运行循环神经网络并输出状态的加权组合

每个计算步骤的权重由“halting 神经元”确定
每个计算步骤的权重由“halting 神经元”确定
“halting 神经元”是一个sigmoid神经元
“halting 神经元”观察循环神经网络状态并给出一个halting权重
可以将halting权重视为应该在该步骤stop的概率。

1 - 权重 - 权重 - …… < epsilon 就stop
有一个halting权重为1的总budget,所以沿着顶部跟踪这个budget。当它小于epsilon时就stop

剩余的 halting budget 归到最后一步
当stop时,可能会有一些剩余的halting budget,因为当它小于epsilon时stop了。
它已被给到以后的步骤,但不想计算这些,因此把它归到最后一步。

在训练自适应计算时间模型时,会在cost函数中增加一个“ponder cost” term。 这penalizes模型使用的计算量。 这个term越大,就越会trade-off性能for减少计算时间。
Code
Mark Neumann’s (TensorFlow)
神经程序员
神经程序员学习创建程序,而无需正确的程序的例子。
本文中的实际模型回答有关表的问题,通过生成类似 SQL 的程序来查询表。
从想象一个稍微简单的模型开始,它被给出一个算术表达式并生成一个程序来评估它。
生成的程序是一系列操作。每个操作都定义为对过去操作的输出进行操作。因此,操作可能类似于"将2步前的操作的输出和1步前的操作的输出相加"。它更像是一个 Unix pipe,而不是 a program with variables being assigned to and read from

该程序由控制器循环神经网络一次生成一个操作。 在每个步骤中,控制器循环神经网络输出下一操作应该是什么的概率分布。
例如,可能很确定要在第一个时间步执行加法,然后很难决定在第二步应乘还是除,依此类推...

现在可以评估操作的最终分布。 没有在每个步骤上执行单个操作,而是执行了通常的attention技巧,即运行所有这些操作,然后将输出在一起平均,并根据运行该操作的概率进行加权。

只要可以通过操作定义导数,程序的输出就概率而言是可区分的。
然后可以定义损失,并训练神经网络以生成给出正确答案的程序。
通过这种方式,在没有好的程序例子的情况下,神经程序员学习生成的程序。
唯一的监督是程序应产生的答案。
本文中的版本回答了有关表而不是算术表达式的问题。
一些其他巧妙的技巧
多种类型
神经编程器中的许多操作都处理其他类型,而不是标量数字。
一些操作输出对表列的选择或对单元格的选择。
只有相同类型的输出会合并在一起。
引用输入
神经程序员需要回答诸如“有多少个城市的人口超过1,000,000?”之类的问题,给出带有人口列的城市表。
为方便起见,某些操作允许网络引用常量在其回答的问题中或列名。
这种引用发生是通过attention,以pointer网络的style
Neural Programmer Interpreter
神经程序解释器需要以正确程序的形式进行监督
Code
Neural Programmer
更新一点的版本的Neural Programmer for 问题回答 已由其作者开源,并且可以使用,作为 TensorFlow Model.
Neural Programmer Interpreter
Ken Morishita (Keras).
The Big Picture
……
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:Attention和增强循环神经网络 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫