一.简介
在人工智能领域内,GAN是目前最为潮流的技术之一,GAN能够让人工智能具备和人类一样的想象能力。只需要给定计算机一定的数据,它就可以自动联想出相似的数据。我们学习和使用GAN的原因如下:
1.能够用GAN进行无监督学习:深度学习需要大量数据的标注才能够进行监督学习,而使用GAN则不需要使用大量标注的数据,可以直接生成数据进行无监督学习,比如使用GAN进行图像的语义分割,我们甚至根本不需要标注图像,计算机就可以自动对图像进行语义分割,目标检测等等。
2.使用GAN可以进行图像的风格迁移:我们可以将一段马的视频变成斑马,将一段真实世界里的视频变成动漫世界
3.使用GAN可以输入文字就输出图像:我们只需要随便对计算机说一句话,计算机就可以根据这段话想象出所对应的场景。
4.GAN:使用Gan可以恢复图像的分辨率,让图像变得更加清晰,或者去掉马赛克。比如前几个月的老北京项目,将100年前的一段北京街头的黑白视频变成了高清的彩色视频。
二.GAN的发展历史
GAN实际上从2014年才提出来,目前也只走过了6年的时间,当时Yun Lecun(LeNet-5的发明者)在Twitter上评论说GAN是人工智能领域最有顶尖的技术,但是因为在今年他所提出的去马赛克技术,因技术还不够成熟,将奥巴马(黑人)的打马赛克之后的图像去掉马赛克变成了白人,刺激了美国的种族主义者,因此把他骂退了Twitter的账号,Gan的发展历程如下: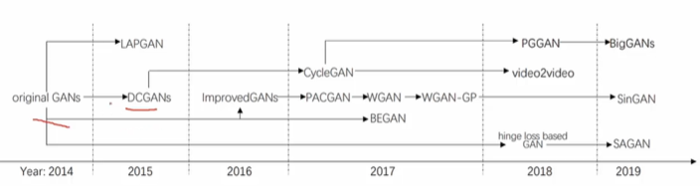

从DCGANs开始人们第一次在生成对抗网络当中引入了深度神经网络的思想,从而让GAN的效果得到极大的提升。那么GAN的基本结构是怎么的呢?
三.生成式对抗网络的结构
生成对抗网络GAN的结构如下: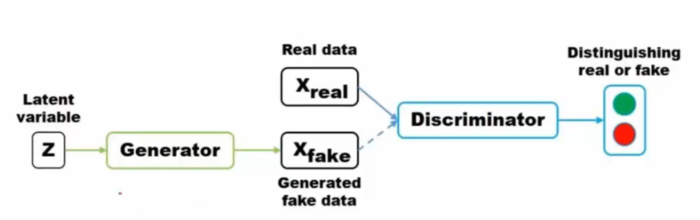
整个结构具有两个神经网络,一个是Generator神经网络,另一个则是Discriminator神经网络。Generator接受一个随机噪声(随机的一个向量的值)用于生成假的图片,Discriminator通过判定生成的图片和真实图片之间的差异来形成loss,同时在判定的时候更新自己的参数,直到能够完全分辨出假的图片和真实的图片,让loss变到最大为止。如下图所示就是一个用于生成二次元妹子头像的生成式对抗网络:
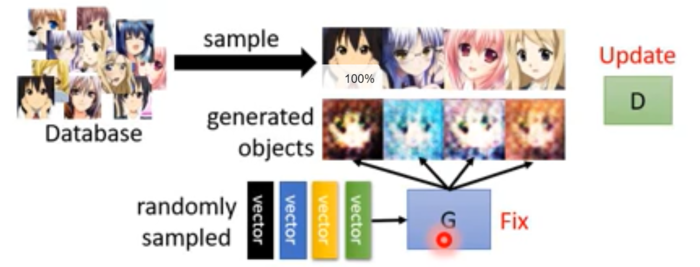
那么我们整个训练的步骤是怎样的呢?
第一步:
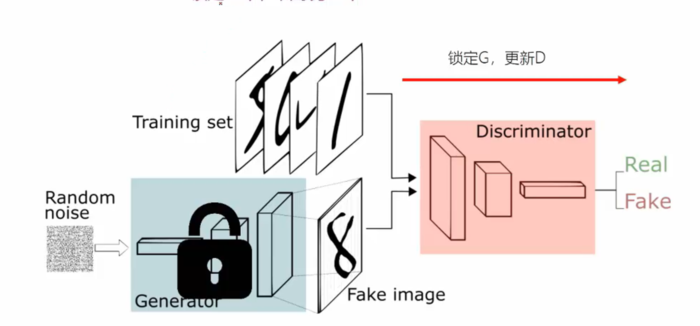
首先生成Fake image,然后固定住Generator,让其不更新参数,通过更新Discriminator的参数来让loss更小,这里的loss衡量的是什么呢??假设真是的图像的label为1,生成的fake image为0,loss就是衡量的Discriminator是否将真实的图片label为1以及将假的图片衡量为0的准确度,loss因此越小越好。从而使Discriminator能够区分真的图片和假的图片。
第二步:
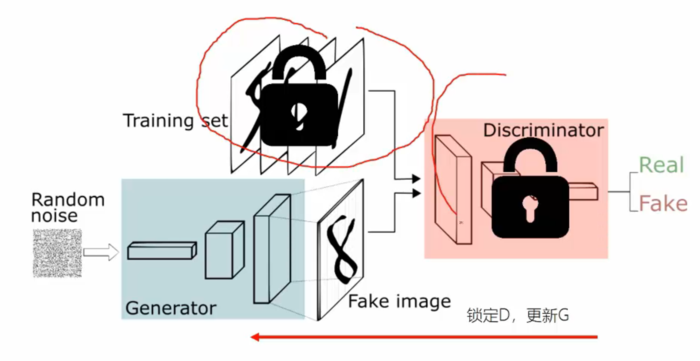
我们直接固定住Discriminator和Trainnig Set,更新Generator的参数,使Discriminator的loss越来越大,让Discriminator根本无法分辨。这个时候参数更新又重复之间的第一步,固定住Generator,不断地迭代。最终就可以让生成的图片完全让人类的肉眼无法分辨其真假。
四.GAN的缺点
第一点是:根据实验可得,生成式对抗网络不容易梯度下降达到全局最优点,如下所示: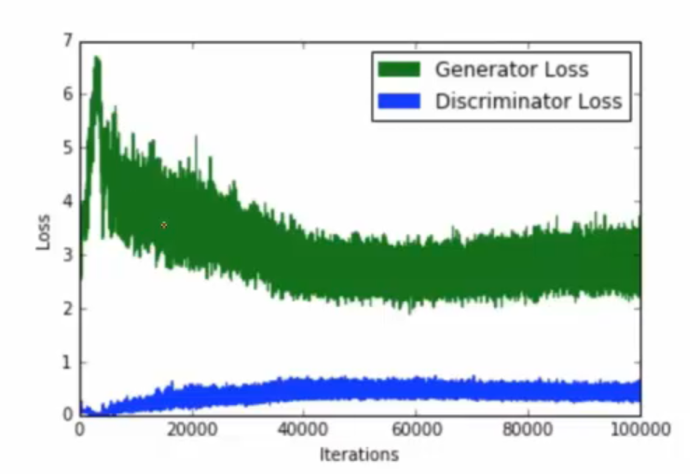
第二点则是容易出现模式坍塌,也就是训练出来的结果很可能让计算机丧失生成视频或者图片的多样性。比如说我们使用GAN生成的妹子图片和真实图片几乎像克隆人一般一模一样,从而丧失了GAN的想象力。
五.常见的对抗生成网络(GAN)
1.DCGAN是一种十分常见的对抗生成网络,如下图所示:
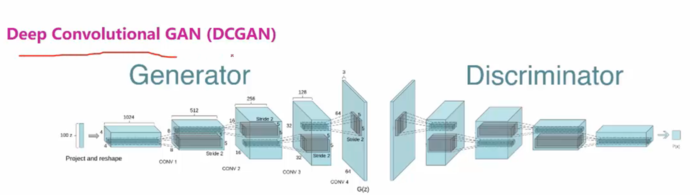
和原始GAN不同的是:
1.原始gan全都使用了全连接神经网络进行训练,而DCGAN将全连接网络层都替换成了卷积神经网络。
2.并在每一层之后添加了Batch Normilization,从而加速了训练,提升了训练的稳定性。
3.Generator的Hidden Layer都使用了Relu作为激活函数,Generator的最后一层使用了Tanh,Discriminator则使用了leakrelu作为了激活函数,可以防止梯度稀疏。
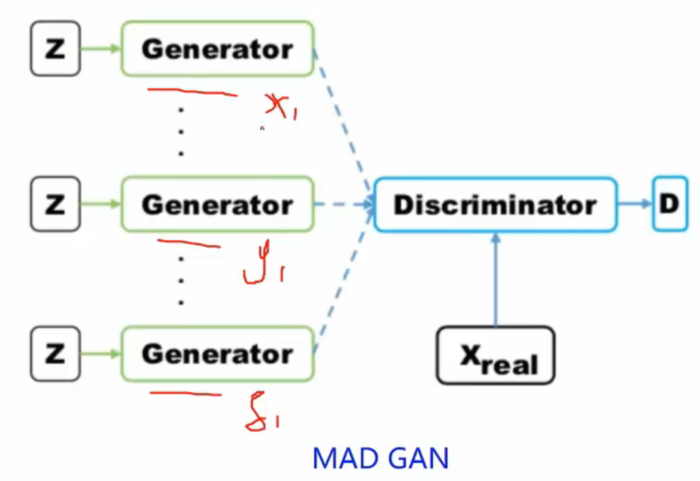
2.Multi agent diverse GAN(MAD-GAN)
通过增加多个生成器,从而让GAN生成的对象更加丰富:
这就是GAN入门所需要了解的知识啦!希望您看了有所收获,小编写得也挺辛苦的,如果觉得还行的话,不要忘了点击右下角的“推荐”和左下角的“关注”呀!
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:一文入门人工智能的掌上明珠:生成对抗网络(GAN) - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 