摘要:本文讲了关于服务发现的很多干货内容,核心内容为服务发现组件的选择、网关的介绍、 客户端侧如何发给已发现的服务。
本文分享自华为云社区《分布式场景下,如何对外提供易变的服务,打造可靠的注册中心?》,作者:breakDawn。
随着云原生的概念越来越火,服务的架构应该如何发展和演进,成为很多程序员关心的话题。大名鼎鼎的《深入理解java虚拟机》一书作者于21年推出了新作《凤凰架构》,从这本书中可以看到当前时下很多最新的技术或者理念。

本博文将沉淀发布这本书的学习笔记和思考。 如果希望了解更加详细的内容,欢迎购买该书继续详细学习。
从类库到服务
1 服务发现
1.1 服务发现的意义
以前是DNS以及DNS之后的负载均衡承担了服务地址翻译的一部分能力,但是随着微服务的流向 服务的非正常掉线、重启、上下线越来越频繁。zk曾经活跃过,但是过于底层,需要用户自己做很多额外工作。因此专用于服务发现的 eureka出现并被纳入spring cloud。后来就是Consul和nacos继承了eureka的衣钵。
如何在基础设置和网络协议层面,对应用尽可能无感知、方便地实现服务发现是目前服务发现的一个发展方向
1.2 服务发现组件中CA和AP的抉择
服务注册中心非常关键, 一旦崩溃将不可使用,因此必须最大程度保证可用。例如搞多个注册中心节点提供服务,不断复制各自的信息,随时提供服务。
但是复制信息又要即时响应的过程会造成结果的不一致,缺乏一致性。
- Eureka优先保证可用性,牺牲一致性, 选择异步复制来交换服务注册信息,同时并不会强行等待复制成功,有新服务注册对应节点可立刻宣布该服务。适合节点关系相对固定, 服务一般不会频繁上下线的系统。
- Consul是优先保证一致性,牺牲可用性。使用Raft算法,要求多数节点写入成功后服务的注册才算完成,严格保证了一致性。同时采用gossip协议,支持多个数据中心逐渐的服务同步。
选择哪个方案,一定程度上是基于产品现实而做的决策。当系统C因为网络问题,变成了A\B两个分区后,是否对你的服务有重大影响?是否是有状态的系统? 如果是,那么选择对一致性严格要求的Consul,如果不是,则选择Eureka。
1.3 注册中心的实现
在分布式KV存储框架上单独做的服务发现
典型代表: zk、 etcd。etcd采用Raft算法,zk采用的zab算法是MultiPaxos的派生算法。
共同特点是在整体较高复杂度的架构和算法的外部,维持着极为简单的应用接口,只有少量CRUD和watch的api, 所以要实现完整的服务发现,要做很大量的工作,只有自研大厂才会这么做,小厂不会首选耗费大量人力去从零实现。
基础设施实现服务发现
典型代表是k8s里用的skyDNS、 coreDNS。工作原理是从API-server中监听集群服务变化,根据服务生产DNS记录存到etcd中, k8s设置每个pos的dns服务地址, 调用服务时再做域名转换。
是CP还是AP取决于后端如何存储,用etcd就是CP,用内存赋值就是AP。好处是对应用透明,只依赖底层的HTTP和DNS,不依赖语言等。缺点是要自己额外做负载均衡、远程调用、服务缓存期限各种能力适配
专门用于服务发现的框架和工具
典型代表: Eureka、Consul、Nacos。
坏处在于对应用不是透明的,必须在应用中要去适配服务注册框架,但能够为编码开发、快速扩展能力提供方便。
2 网关路由
2.1 网关的职责
微服务网关的首要职责就是作为统一的出口对外提供服务, 将外部访问网关地址的流量,根据适当的规则路由到内部集群中正确的服务节点上。同时再作为流量过滤器增强使用
因此“网关= 路由器(基础职能)+ 过滤器(可选职能)”
网关的性能主要取决于他们如何处理代理网络请求,也就是他们的网络IO模型
2.2 网络IO模型介绍
同步和异步的区别, 是指调用端发出请求后,是否需要一直等待,是否会铜鼓哦状态变化和回调来通知矗立着。
阻塞和非阻塞是针对请求处理过程而言,调用请求返回结果之前,处理线程是否会被挂起。
阻塞IO、非阻塞IO、 多路复用、信号驱动IO都属于同步IO。
- 阻塞IO是发现结果没返回,会挂起线程,直到结果返回。
- 非阻塞IO是会不断轮询询问是否完成、
- 多路复用IO是阻塞IO的一种,但他只有一个监听线程在阻塞, 当有某个事件结果返回,再进行对应处理。
- 信号驱动IO和异步IO有点像, 但是异步IO是数据已经被传回到调用方了,然后通知, 而信号驱动IO只通知完成了,但是数据还要调用方重新阻塞式地去获取。
Linux系统下实现高并发编程时仍以多路复用IO模型为主。
网关里, zuul1.0网关是用阻塞IO模型,碰到IO密集型就很浪费上下文切换的性能, zuul2.0基于netty-server实现异步IO模型处理请求, 性能提升20%。可以自行指定 select、epoll等并发模型。
网关应该尽可能轻量、 成熟、 更成熟健壮的物理设施。
2.3 BFF网关
网关会针对不同的前端,聚合不同的服务,提供不同的接口和网络访问协议支持(例如http和grpc都能提供)
3 客户端负载均衡
用户客户端请求->某地域机房ip所在的服务网关->选择发往对应业务服务所属的负载均衡器->发给真正的服务
其中第三步的“发往业务服务负载均衡器”是有点浪费的, 从机房内网发出的服务请求, 绕道了网络边缘的负载均衡器上了,又重新回了内网。
3.1 客户端负载局衡器
就是在 机房网关->服务负载均衡器->服务节点的这个过程中, 去掉负载均衡器, 直接把负载均衡能力内置到机房网关的能力中。其他要用到负载均衡的场景也可以这样操作不一定局限于网关。
优点:
- 负载均衡器和服务之间的信息是进程内方法调用,不存在网络开销
- 不依赖集群边缘的设置,都是集群内部循环
- 避免了负载局衡器的单点问题。
- 可以针对每个服务实例单独设置负载均衡策略更灵活
缺点:
- 负载均衡代码受限于服务本身代码实现, 如果是go、python等会导致不得不适配多份负载均衡代码
- 负载均衡器会占用服务的一部分资源或者互相影响
- 当服务被攻破, 下游所有节点的信息也暴露,信任关系不安全
- 经常要轮询、上线、下线,负担不小
3.2 代理负载均衡器
基于k8s、docker部署的服务, 一般都有一个pod, 选择在pod的边缘部署一个代理负载均衡器(也叫边车代理),相当于是同一个节点内,部署了一个进程。是服务网格的一个概念。
好处
- 不再受语言限制
- 避免服务进程要频繁轮询造成浪费, 直接让控制平面给pod的边车代理
- 更安全也更容易实现对调用链路的详细统计。
3.3 地域和区域
region是地域的概念。
集群内部流量不会跨地域。
zone是区域的概念, 地理上是同一个地域,但是地域内可能放了不同的机房,每个大机房就是一个区域。
如果追求高可用,则系统要部署在多个区域中。
如果追去低延迟, 则应该所有服务都在同一个区域中。
相关思考
本文讲了关于服务发现的很多干货内容,核心内容为服务发现组件的选择、网关的介绍、 客户端侧如何发给已发现的服务。如果准备进行服务发现的选型工作,可以仔细阅读原文进行学习和了解。
文中关于注册中心的实现原理有很多种类型, 其中有提到一个k8s里用的 coreDNS。那部分笔记中关于coreDns的原理 比较少。而华为云的CCE容器引擎就包含了CoreDNS插件,他们的产品资料中给出的路由请求流程如下:
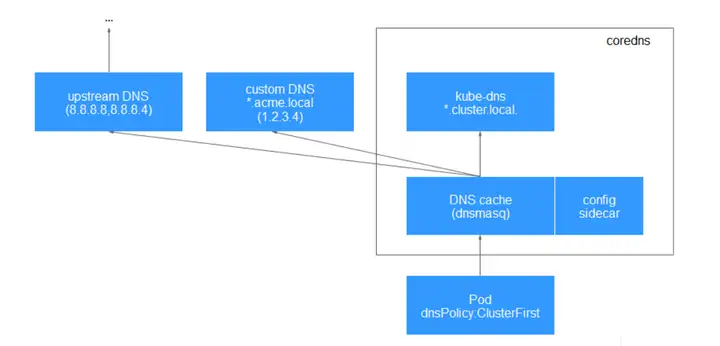
另外对于专门用于服务发现的框架和工具,华为云的CSE微服务引擎里关于服务注册发现的示意图如下:
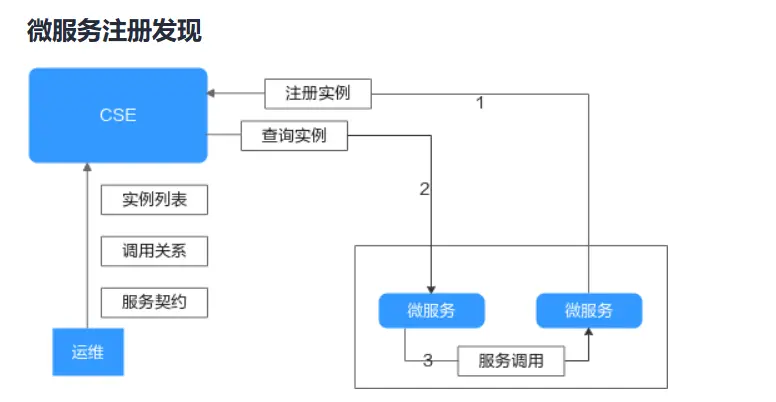
微服务启动时,将实例信息注册到CSE,微服务需要调用其他微服务的接口时,从CSE查询实例信息,并将实例信息缓存到本地,缓存会通过事件通知、定时查询等机制更新;通过本地缓存的地址信息,实现微服务之间的点到点调用。
同时也支持基于上述提到的3个服务发现代表,实现优化上下线的能力:

原文链接:https://www.cnblogs.com/huaweiyun/p/17377380.html
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:分布式场景下,如何对外提供易变的服务,打造可靠的注册中心? - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 