

大数据时代,各行各业对数据采集的需求日益增多,网络爬虫的运用也更为广泛,越来越多的人开始学习网络爬虫这项技术,K哥爬虫此前已经推出不少爬虫进阶、逆向相关文章,为实现从易到难全方位覆盖,特设【0基础学爬虫】专栏,帮助小白快速入门爬虫,本期为自动化工具 Pyppeteer 的使用。
概述
前两期文章中已经介绍到了 Selenium 与 Playwright 的使用方法,它们的功能都非常强大。而本期要讲的 Pyppeteer 与 Playwright 一致,都可以作为 Selenium 的替代者来使用。且与 Playwright 相比,Pyppeteer 的使用更加简单。
Pyppeteer 的使用
介绍
在上上期文章中,我们介绍了 Selenium 隐藏特征的方法,其中使用到了 stealth.min.js 文件。在介绍文件的来源时我们提到了 Puppeteer,Puppeteer是一个基于 Node.js 的自动化工具。而这期要将的 Pyppeteer 就是 Puppeteer 的 Python 版。
Pyppeteer 是一个使用 Python 语言封装的 Google Chrome 浏览器的非官方 API。它可以用来进行自动化测试、网站爬虫和数据抓取等工作。
Pyppeteer 的底层是通过调用 Chrome 浏览器的 DevTools Protocol 接口来实现的。DevTools Protocol 是一个基于 WebSocket 协议的远程调试接口,可以让开发者控制和检查 Chrome 浏览器的行为。Pyppeteer 利用这个接口实现了对 Chrome 浏览器的完全控制,包括加载页面、模拟用户操作、获取页面内容等等。
Pyppeteer 支持 Python 3.6 及以上版本,并且可以在 Windows、macOS 和 Linux 等操作系统上运行。它提供了简单易用的 API,可以方便地模拟用户在浏览器上的操作,例如点击链接、填写表单、触发事件等等。同时,它也支持对浏览器的调试、截屏、PDF 导出等高级功能。
Pyppeteer 的使用方式与其他 Python 库类似,可以通过 pip 包管理器进行安装。除了 Pyppeteer 本身外,还需要安装 asyncio 库和一个兼容的 Chrome 浏览器版本。在安装完成后,可以通过 Python 代码来控制浏览器的行为,实现各种自动化测试或数据抓取的任务。
安装
Pyppeteer 的安装与 Playwright 相似。
Pyppeteer 采用了async机制,所以必须使用Python 3.5及以上版本。
首先使用 pip 安装 Pyppeteer 包:
pip install pyppeteer
安装完成后可以选择执行 pyppeteer-install 下载用于 pyppeteer 的 chromium,这一步可以省略,因为第一次运行 Pyppeteer 时会自动检测是否安装了 chromium 浏览器,如果没有安装程序会自动进行安装配置。
使用
前两期文章中介绍到了 Selenium 与 Playwright 库的使用方法,因为自动化库的使用大同小异,所以这里只介绍 Pyppeteer 中比较特殊的方法
Pyppeteer 基于异步实现,所以它支持异步操作。
启动
以百度热搜榜为例:
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://top.baidu.com/board?tab=realtime')
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
示例代码中使用 launch 方法创建了一个浏览器对象 browser ,设置了 headless=False 来关闭无头模式,这一行代码的作用相当于启动一个浏览器,await的作用就是等待浏览器启动完毕。
创建完浏览器后,使用到了 newPage 方法,创建了一个 Page 对象,这一步相当于打开了一个新的标签页,通过 await 等待标签页创建完毕,然后调用 goto 方法打开目标网址,最后使用 close 方法关闭浏览器。
launch详解
launch 方法用于启动浏览器进程并返回浏览器实例,它包含了多个参数:
| 参数 | 描述 |
|---|---|
ignoreHTTPSErrors(bool) |
是否忽略HTTPS错误。默认为 False |
headless(bool) |
是否开启无头模式。默认为True |
executablePath (str) |
可执行文件的路径,设置该参数可以指定已有的 Chrome 或 Chromium 浏览器。 |
slowMo (int | float) |
传入指定时间(毫秒),用于延缓 Pyppeteer 的一些模拟操作。 |
args (List [str]) |
传递给浏览器的额外参数。 |
dumpio(bool) |
是否将 Pyppeteer 的输出信息传给 process.stdout和process.stderr。默认为False。 |
userDataDir (str) |
用户数据文件夹。 |
env(dict) |
浏览器环境。默认与 Python 进程相同。 |
devtools(bool) |
是否为每个标签页打开 DevTools 面板,默认为False,如果该参数为 True,则 headless 会被强制设置为 False。 |
logLevel(int | str) |
日志级别。默认值与根记录器相同。 |
autoClose(bool) |
脚本完成时自动关闭浏览器进程。默认为True。 |
loop(asyncio.AbstractEventLoop) |
事件循环。 |
禁用提示条
与 Selenium 一样,Pyppeteer 控制浏览器时会提示 Chrome 正受到自动测试软件的控制。可以通过 设置 launch 方法中的 args 参数来关闭提示。
browser = await launch(headless=False, args=['--disable-infobars'])
用户数据持久化
自动化工具如 Selenium 、Playwright 都有一个特征,就是每一次运行的时候创建的都是一个全新的浏览器,它不会记录用户之前的行为。如第一次运行时我登录了某个网站,而第二次运行时再次进入该网站时依旧需要登录。这是因为自动化工具没有记录用户行为信息。Pyppeteer 中,如果需要记录用户的行为信息,可以通过设置 launch 方法中的 userDataDir 方法来实现。
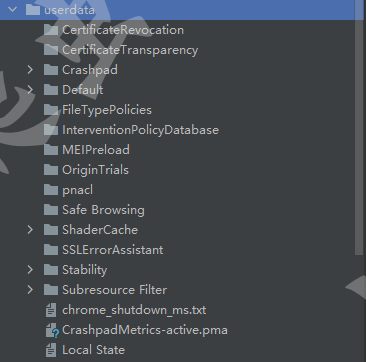
browser = await launch(headless=False, args=['--disable-infobars'], userDataDir='./userdata')
设置了用户数据文件夹后运行代码,会生成一个 userdata 文件夹,其中就存储着用户上次控制浏览器时记录的一些行为数据。
执行 JS 语句
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://top.baidu.com/board?tab=realtime')
dimensions = await page.evaluate('''() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio,
}
}''')
print(dimensions)
await browser.close()
# {'width': 783, 'height': 583, 'deviceScaleFactor': 1}
通过调用 Page 对象下的 evaluate 方法可以执行一段 JS 语句。
反检测
Pyppeteer 的反检测方式与 Selenium 和 Playwright 有些区别,但是思想是一样的。
首先需要安装 pyppeteer_stealth 库,它的作用就是用来隐藏特征。
pip install pyppeteer_stealth
以无头模式为例:
import asyncio
from pyppeteer import launch
from pyppeteer_stealth import stealth
async def main():
browser = await launch()
page = await browser.newPage()
# 隐藏特征
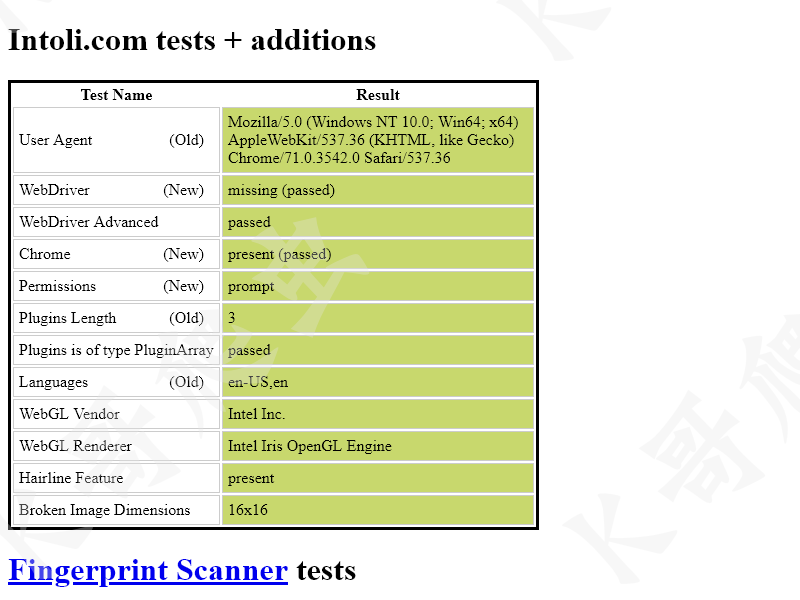
await stealth(page)
await page.goto('https://bot.sannysoft.com/')
await page.screenshot(path='page.png')
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
隐藏特征前:

隐藏特征后:
等待
waitForSelector :等待符合条件的节点加载完成
waitForFunction :等待某个 JavaScript 方法执行完毕或返回结果
waitForRequest :等待某个特定的请求发出
waitForResponse :等待某个特定请求对应的响应
waitForNavigation :等待页面跳转,如果页面加载失败则抛出异常
waitFor :通用等待
waitForXpath :等待符合 Xpath 的节点加载出来
选择器
Pyppeteer 提供了一些比较有意思的选择器方法。
J() :返回匹配到的第一个节点,等同于 querySelector 方法。
JJ() :返回匹配到的所有节点,等同于 querySelectorAll 方法。
JJeval() :执行 JS 脚本并返回一个 JSON 对象,等同于 querySelectorAllEval 方法。
Jeval() :执行 JS 脚本并返回执行结果,等同于 querySelectorEval 方法。
Jx() :通过 Xpath 匹配符合条件的内容,等同于 xpath 方法。
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://top.baidu.com/board?tab=realtime')
# 等待元素加载
await page.waitForXPath('//div[@class="c-single-text-ellipsis"]')
element_j = await page.J('.c-single-text-ellipsis')
element_jj = await page.JJ('.c-single-text-ellipsis')
# 打印元素的文本信息
print(await (await element_j.getProperty('textContent')).jsonValue())
for element in element_jj:
# 打印元素的文本信息
print(await (await element.getProperty('textContent')).jsonValue())
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
"""
运行结果:
青年强则国家强
青年强则国家强
乌代表举自家国旗挑衅暴揍俄代表
英王加冕礼彩排:黄金钻石马车亮眼
平凡岗位上的奋斗故事
俞敏洪建议24节气都放假
7人吃自助4小时炫300多个螃蟹
.
.
.
"""
总结
Pyppeteer 类似于轻量级的 Playwright ,它使用起来更加简单,且 Pyppeteer 与 Playwright 一样都支持异步,性能方面也比较强。缺点就是它基于 Chromium 内核,资源消耗比较大,不支持其它浏览器,而且 Pyppeteer 的作者近年来都没对该库进行维护,导致存在一些 bug。

原文链接:https://www.cnblogs.com/ikdl/p/17385159.html
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:【0基础学爬虫】爬虫基础之自动化工具 Pyppeteer 的使用 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 