
在上一篇生信云实证《提速2920倍!用AutoDock Vina对接2800万个分子》里,我们基于不同用户策略,调用10万核CPU资源,帮用户进行了2800万量级的大规模分子对接,将运算效率提高2920倍。

对药物分子的虚拟筛选,仅仅实现分子对接是不够的,往往会面临一个问题就是药物分子活性的评价。许多药物和其它生物分子的活性都是通过与受体大分子之间的相互作用表现出来的,是动态的。
受体和配体之间结合自由能(Binding Afinity)评价是基于结构的计算机辅助药物分子设计的核心问题。
基于分子动力学(Molecular Dynamics, MD)模拟的炼金术自由能(Alchemical Free Energy,AFE)计算是提高我们对各种生物过程的理解以及加快多种疾病的药物设计和优化的关键工具。
MD模拟实验数据量大,计算周期长,常用软件包括Amber、NAMD、GROMACS、Schrödinger等等。GPU的并行处理技术能大大加速计算效率,所以很多MD模拟软件都开始支持GPU。

GROMACS作为一款开源软件,完全免费,但其成熟版本对于GPU的支持并不理想,教程相对少,对用户的要求比较高。
Schrödinger是商用软件,功能全面,GPU支持很好,但License是按使用核数计算的,价格相对昂贵。
Amber软件包包括两个部分:AmberTools和Amber。
AmberTools可以在Amber官网免费下载和使用,Tools中包含了Amber绝大部分模块,但不支持PMEMD和GPU加速。
Amber是收费的,从Amber11开始支持GPU加速仿真,Amber18开始支持GPU计算自由能,且教程齐全易操作,不限制CORE的使用数量。2020年4月,已经更新到Amber20版本。
学术/非营利组织/政府:500美元
企业:新Amber20用户 20000美元(原Amber18用户 15000美元)
今天实证的主角是Amber,有几个重点我们先说为敬:
第一、不同GPU型号价格差异极大,对Amber自由能计算的适配度和运算效率也不同,如何为用户选择最匹配的资源类型;
第二、用户对GPU的需求量比较大,而不同云厂商提供的可用GPU资源数量不确定,价格差异也很大,可能需要跨多家云厂商调度,如何实现?同时,尽可能降低成本;
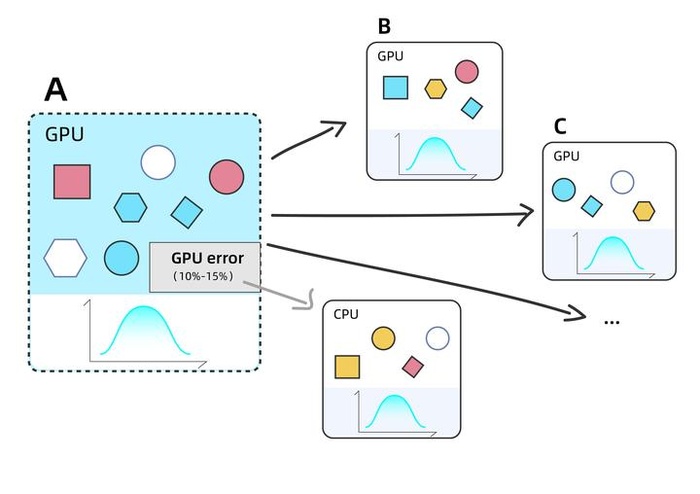
第三、用户使用的Amber18版本,根据我们的经验,在使用GPU计算时存在10%-15%的失败概率。一旦任务失败,需要调度CPU重新计算,能否及时且自动地处理失败任务,将极大影响运算周期。
用户需求
某高校研究所对一组任务使用Amber18进行自由能计算,使用本地48核CPU资源需要12小时,而使用1张GPU卡运算该组任务只需3小时。
该研究所目前面临16008个任务需要使用Amber18进行自由能计算,负责人根据以往数据估算使用本地CPU资源可能要1年以上才能完成任务,使用单个GPU需要至少4个月,周期过长,课题等不了。
因此,他们迫切希望通过使用云上资源,尤其是GPU资源来快速补充本地算力的不足,更快完成任务。
实证目标
1、Amber自由能计算能否在云端有效运行?
2、fastone是否能为用户选择合适的GPU实例类型?
3、fastone平台是否能在短时间内获取足够的GPU资源,大幅度缩短项目周期?
4、Amber18版本运行GPU的失败概率问题,fastone平台是否能有效处理?
实证参数
平台:
fastone企业版产品
应用:
Amber18
操作系统:
CentOS 7.5
适用场景:
基于分子动力学模拟的自由能预测
云端硬件配置:
NVIDIA Tesla K80
NVIDIA Tesla V100
调度器:
Slurm
技术架构图:
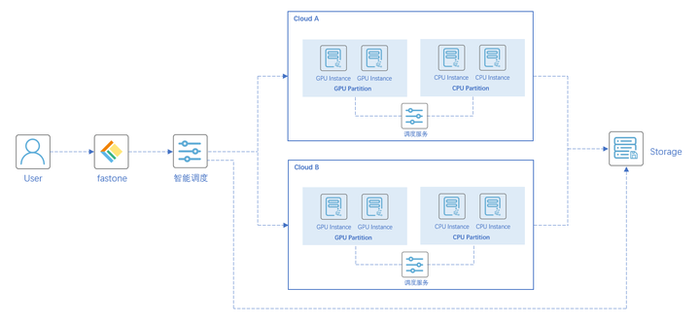
实证场景一
GPU实例类型验证——120个任务
新版的GPU资源,运行速度快,但是价格高。
老版的GPU资源,价格是便宜了,但是运行速度也慢。
老机型就一定划算吗?这可不一定。
结论:
1、无论是从时间效率还是成本的角度,都应选择更新型的NVIDIA Tesla V100;
2、在云端运算相同的Amber18任务时,NVIDIA Tesla K80的耗时是NVIDIA Tesla V100的约5-6倍,从时间效率的角度,V100明显占优;
3、NVIDIA Tesla K80云端GPU实例的定价约为NVIDIA Tesla V100云端GPU实例的不到三分之一(某公有云厂商官网上单个K80的按需价格为0.9美元/小时,V100则为3.06美元/小时),综合计算得出V100的性价比是K80的约1.4-1.8倍。
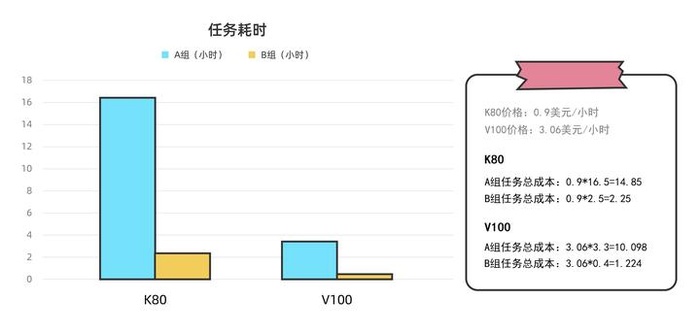
实证过程:
1、云端调度1个NVIDIA Tesla K80云端GPU实例运算A组Amber任务,耗时16.5小时;
2、云端调度1个NVIDIA Tesla K80云端GPU实例运算B组Amber任务,耗时2.5小时;
3、云端调度1个NVIDIA Tesla V100云端GPU实例运算A组Amber任务,耗时3.3小时;
4、云端调度1个NVIDIA Tesla V100云端GPU实例运算B组Amber任务,耗时0.4小时。
实证场景二
大规模GPU多云场景验证——16008个任务
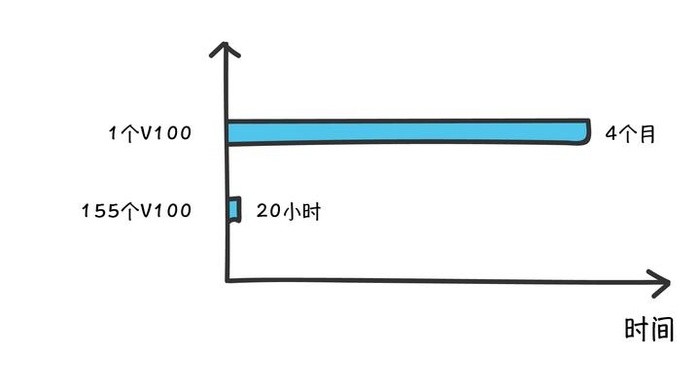
结论:
fastone平台根据用户任务需要和特性,跨两家公有云厂商,智能自动化调度云端GPU/CPU异构资源,包括155个NVIDIA Tesla V100和部分CPU资源,将运算16008个Amber任务的耗时从单GPU的4个月缩短到20小时。
1、怎么通过Auto-Scale功能提高GPU资源的利用率?
用户的Amber任务运算时存在依从机制,即每12个任务中包含1个主任务,只有当主任务运行结束后,其他11个任务才能开始并行运算。
在本场景中,由于任务数量高达16008个,这就意味着有1334个主任务需要率先跑完。

本次实证中:
第一,任务有先后,所以需要先跑主任务,在每个主任务完成之后自动调度资源并行运算其他11个任务;
第二,不同任务完成时间可能不同,对资源的需求量可能时高时低有波动,最终结束关机时间也不同。
fastone平台使用Slurm调度器按顺序调度任务排队,Auto-Scale功能可自动监控用户提交的任务数量和资源的需求,动态按需地开启与关闭所需算力资源,在提升效率的同时有效降低成本。
关键是,一切都是自动的。
随任务需要自动化开机和关机到底有多省钱省心,谁用谁知道。

用户还可根据自己需求,设置自动化调度集群规模上下限,相比手动模式能够节省大量时间与成本。
调度器是干嘛的,为什么大规模集群需要用到调度器,有哪些流派,不同调度器之间区别是什么等等问题可以参考亿万打工人的梦:16万个CPU随你用
2、任务用GPU运算失败,怎么及时用CPU自动重算?
Amber18在使用GPU时计算时有10-15%概率失败,需要及时调度CPU资源重新计算,这里会涉及到一个问题:错误的任务能否及时重新用CPU运行。(注:该问题已在Amber20中修复)

跟上一点一样,自动化还是手动的部署差别非常大。
失败任务自动跳出来重新运行,嗯,就是这么乖巧。
自动化模式和手动模式到底多大差别,多省钱省心可以看这篇:EDA云实证Vol.1:从30天到17小时,如何让HSPICE仿真效率提升42倍?
本次实证中:
由于任务总数高达16008个,全部使用GPU计算,预计将会有1600-2400个任务算错,对自动化调度CPU资源的响应速度和规模提出了很高的要求。
fastone平台提供的智能调度策略,能在使用GPU资源计算失败时,自动定位任务并按需开启CPU资源,对该任务重新进行计算,直到计算完成为止。
3、GPU资源的多云调度,如何兼顾成本和效率,最大化用户利益?
云上的GPU可用资源有限,155个NVIDIA Tesla V100不是一个小数目,单个公有云厂商单区域资源未必能够随时满足需求。
本次实证中:
第一,涉及到跨两家公有云厂商之间的资源调度;
第二,GPU资源的在不同云厂商之间有着显著的差异,而且往往资源多的售价高,便宜的资源少,怎么兼顾成本和效率。
以各大公有云厂商在北京地区的GPU实例(V100)按需价格为例,最高价格超过最低价2倍。
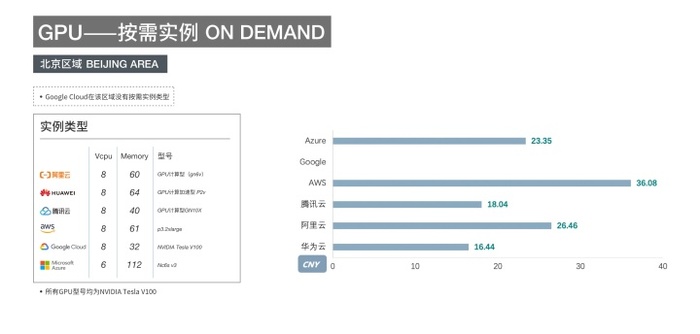
关于不同云厂商之间的价格比较和SPOT竞价实例到底能有多便宜,可以看这篇:【2020新版】六家云厂商价格比较:AWS/阿里云/Azure/Google Cloud/华为云/腾讯云
fastone平台可综合考量用户对完成任务所需时间和成本的具体要求,在多个云厂商的资源之间选择最适配的组合方案,为用户跨地区、跨云厂商调度所需资源。
下图场景是出于成本优化目的,我们为用户自动调度本区域及其他区域的目标类型或相似类型SPOT实例资源。

本次实证,fastone平台完美解决了以上三个挑战:
第一,自动监控用户提交的任务数量和资源的需求,动态按需地自动化开启与关闭所需算力资源,提高GPU资源利用率;
第二,在GPU资源计算失败时,自动定位任务并按需开启CPU资源,对该任务重新进行计算,直到计算完成为止;
第三,在多个云厂商的资源之间选择最适配的组合方案,为用户跨地区、跨云厂商调度所需GPU资源。
实证小结
1、Amber任务能够在云端有效运行;
2、fastone为用户任务推荐最适配的GPU资源类型;
3、fastone平台能够在短时间内跨区域,跨云厂商获取足够的GPU资源,满足用户短时间算力需求,大幅度缩短项目周期;
4、针对Amber18版本运行GPU任务失败概率问题,fastone平台可自动调度CPU资源重新计算,降低。
本次生信行业Cloud HPC实证系列Vol.6就到这里了。
在下一期的生信云实证中,我们聊MOE。
请保持关注哦!
- END -
我们有个【在线体验版】
集成多种应用,大量任务多节点并行
应对短时间爆发性需求,连网即用
跑任务快,原来几个月甚至几年,现在只需几小时
5分钟快速上手,拖拉点选可视化界面,无需代码
支持高级用户直接在云端创建集群
扫码免费试用,送300元体验金,入股不亏~


2020年新版《六大云厂商资源价格对比工具包》
扫码添加小F微信(ID: imfastone)获取

你也许想了解具体的落地场景:
关于云端高性能计算平台:
速石科技(ID:Fastone_tech)
算力,是一种能力,也是一种资源。
我们为有高算力需求用户提供一站式算力运营解决方案,不局限于HPC,AI,大数据,互联网服务等。希望和你共同建立起不断迭代更新的多云世界观。
咨询热线:021-31263638
(你要是唠这个我就不困了。)
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:生信云实证Vol.6:155个GPU!多云场景下的Amber自由能计算 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 