爬虫
-
python爬虫实践——滑动登陆验证
1 from selenium import webdriver 2 from selenium.webdriver import ActionChains 3 import time 4 5 driver=webdriver.Chrome() 6 driver.implicitly_wait(10) 7 driver.get(‘http://www.run…
-
爬虫来啦!Day91
# 一.爬虫# 1.基本操作# 排名爬虫刷票# 抽屉网的所有发布新闻点赞# 自动化程序模拟用于的日常操作# 投票的机制是利用cookies,禁用cookies模式# 自定义的异步IO模块就是Socket的客户端# 基本操作:使用python登陆任何的网站,图片识别验证码比较困难,需要额外的图片识别或特殊api(伪造浏览器的任何行为)# 2.性能相关的操作# …
-
CrawlSpider —> 通用爬虫 项目流程
通用爬虫 通用网络爬虫 从互联网中搜集网页,采集信息,这些网页信息用于为搜索引擎建立索引从而提供支持,它决定着整个引擎系统的内容是否丰富,信息是否即时,因此其性能的优劣直接影响着搜索引擎的效果。 不扯没用的,上干货! 创建项目: cmd 命令: scrapy startproject 项目名 创建 cmd 命令:scrapy genspider -…
-
python爬虫,接口是post请求,参数是request payload 的形式,如何传参
payload = { “tmpFdt”: eta, “tmpNacd”: pol_code_ex, “tmpPod”: tmpPod, “tmpPol”: tmpPol } # 传json格式的参数 jdata = json.dumps(payload) res = session.post(t_url, timeout=20, data=jdat…
-
python爬虫(十三) lxml模块
lxml是一个HTML/XML的解析库,主要功能是如何解析和提取HTML/XML数据 lxml和正则一样,是用c实现的,我们可以用XPath语法,来快速的定位特定元素以及节点信息。需要用到pip。 使用: 1、解析一段html的字符串 from lxml import etree text=””” # 一段html代码 “”” htmlElement=etr…
-
python爬虫(十一) session
这是一个会话对象,对目标服务器得请求通过session来完成 例如人人网爬取大鹏主页信息, # requests使用session,不用登录查看人人网大鹏信息 import requests url=’http://www.renren.com/PLogin.do’ id = input(‘请输入用户名:’) pw = input(‘请输入密码:’) da…
-
分布式爬虫 redis + mongodb +scrapy
zhihuspider.py # -*- coding: utf-8 -*- import json import scrapy from scrapy import Request from zhihuuser.items import ZhihuuserItem class ZhihuspiderSpider(scrapy.Spider): name =…
-
爬虫学习:使用scrapy爬取猫眼电影
操作步骤 1.生成项目(在cmd或shell窗口运行以下3列代码) scrapy startproject movieinfo cd movieinfo scrapy genspider maoyanm 生成文件结构如下: 2.相关文件内容编辑 maoyanm.py # -*- coding: utf-8 -*- import scrapy from m…
-
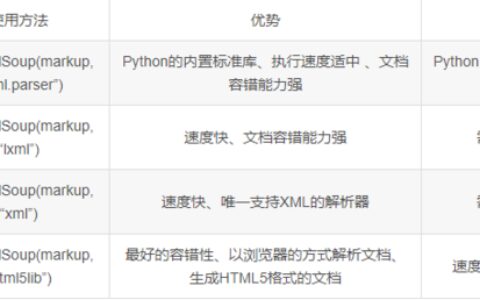
【Python爬虫学习(1)】BeautifulSoup库的使用
一、BeautifulSoup库简介 BeautifulSoup是一个灵活方便的网页解析库,处理搞笑,支持多种解析器。利用它可以不用编写正则表达式就可以方便的实现网页信息的抓取。 BeautifulSoup是爬虫必学技能,其最主要的功能是从网页抓取数据。BeautifulSoup自动的将输入文档转换为Unicode编码,输出文档转换为utf-8编码。Beau…
-
Python爬虫_qq音乐示例代码
import requests url = ‘https://c.y.qq.com/soso/fcgi-bin/client_search_cp’ for x in range(5): headers = { ‘origin’:’https://y.qq.com’, ‘referer’:’https://y.qq.com/portal/search.html…