爬虫
-
robots.txt协议——网络爬虫的“盗亦有道”
网络爬虫的限制: 来源审查:判断User-Agent进行限制 检查来访HTTP协议头的User-Agent域,只响应浏览器或友好爬虫的访问。 实际上HTTP协议头是可以通过技术上进行伪造。 发布公告:robots协议 告知所有爬虫网站的爬取策略,要求爬虫遵守。 robots协议(Robots Exclusion standar…
-
Java 实现 HttpClients+jsoup,Jsoup,htmlunit,Headless Chrome 爬虫抓取数据
最近整理一下手头上搞过的一些爬虫,有HttpClients+jsoup,Jsoup,htmlunit,HeadlessChrome 一、HttpClients+jsoup,这是第一代比较low,很快就被第二代代替了! 二、Jsoup 需要的jar包: 1 <dependency> 2 <groupId>org.jsoup</gr…
-
个推push数据统计(爬虫)
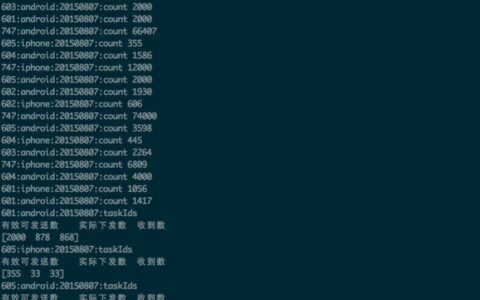
该方案基于任务调度框架Gearman,采用Python开发的分布式数据统计系统。 项目的目录结构很简单: # apple at localhost in ~/Develop/getui [11:24:26]$ tree.├── Browser.py├── PickleGearman.py├── SpiderWorker.py└── countPushNu…
-
python爬虫 JS逆向思路
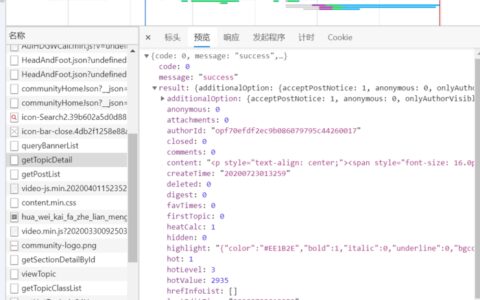
以下解密部分转自 [ 不止于python ] 破解参数 这篇来讲讲逆向破解js的方法, 先拿美团外卖的请求参数, X-FOR-WITH 练练手 请求地址: https://h5.waimai.meituan.com/waimai/mindex/home 打开Chrom, 打开控制台, 查看请求 发现需要解密的参数: X-FOR…
-
爬虫之路: 字体反扒升级版
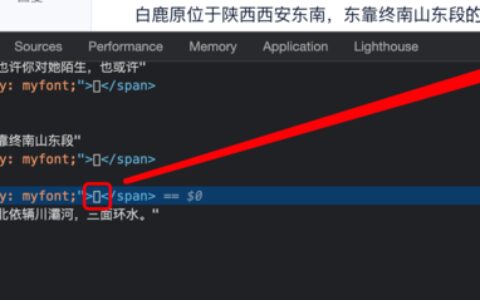
字体反扒系列 爬虫之路: 字体文件反爬一 爬虫之路: 字体文件反爬二(动态字体文件) 本文转自 [ 不止于python ] 开始吧! 小伙伴留言说, 脚本用不了了, 抽了空就先打开网站看一下, 结果发现看不见字符的源码了, 在控制台, 源码, 甚至python请求的html都变成了符号 页面html中 控制面板源码中 python请求源码中 …
-
NetCore控制台程序-使用HostService和HttpClient实现简单的定时爬虫
.NetCore承载系统 .NetCore的承载系统, 可以将长时间运行的服务承载于托管进程中, AspNetCore应用其实就是一个长时间运行的服务, 启动AspNetCore应用后, 它就会监听网络请求, 也就是开启了一个监听器, 监听器会将网络请求传递给管道进行处理, 处理后得到Http响应返回 有很多场景都会有服务承载的需求, 比如这篇博文要做的, …
-
防止网页被搜索引擎爬虫和网页采集器收录的方法汇总
来源:脚本之家 http://www.jb51.net/yunying/28470.html 下面的这些方法是可以标本兼治的:1、限制IP地址单位时间的访问次数 分析:没有哪个常人一秒钟内能访问相同网站5次,除非是程序访问,而有这种喜好的,就剩下搜索引擎爬虫和讨厌的采集器了。 弊端:一刀切,这同样会阻止搜索引擎对网站的收录 适用网站:不太依靠搜索引擎的网站 …
-
python简单爬虫
“”” 请求连接:https://maoyan.com/board/4 第二页:https://maoyan.com/board/4?offset=10 “”” import requests import re class myspider(): def __init__(self,base_url,headers): self.base_url = ba…
-
c# WPF——完成一个简单的百度贴吧爬虫客户端
话不多说先上图 爬取10页大概500个帖子大概10s,500页2w多个帖子大概2min,由此可见性能并不是特别好,但是也没有很差。 好了话不多说,我们来一步一步实现这么个简易的客户端。 1.创建项目 创建一个WPF空项目,导入需要的Devexpress的dll Devexpress可以到官网下载,基本16版本以上都可以。下载试用版的也可…
-
关于反爬虫
最近从网上看到的反爬虫帖子,记录下来。大家也可以观看视频回放,“现场”围观。 一、为什么要反爬虫 1、爬虫占总PV比例较高,这样浪费钱(尤其是三月份爬虫)。 三月份爬虫是个什么概念呢?每年的三月份我们会迎接一次爬虫高峰期。 最初我们百思不得其解。直到有一次,四月份的时候,我们删除了一个url,然后有个爬虫不断的爬取url,导致大量报错,测试开始找我们麻烦。我…