爬虫
-
Python 爬虫二 requests模块
requests模块 Requests模块 get方法请求 整体演示一下: import requests response = requests.get(“https://www.baidu.com”) print(type(response)) print(response.status_code) print(type(response.text)…
-
Python 爬虫三 beautifulsoup模块
beautifulsoup模块 BeautifulSoup模块 BeautifulSoup是一个模块,该模块用于接收一个HTML或XML字符串,然后将其进行格式化,之后遍可以使用他提供的方法进行快速查找指定元素,从而使得在HTML或XML中查找指定元素变得简单。 安装: pip install beautifulsoup4 在python自动化模块对bs…
-
jieba库的基本介绍及爬虫基本操作
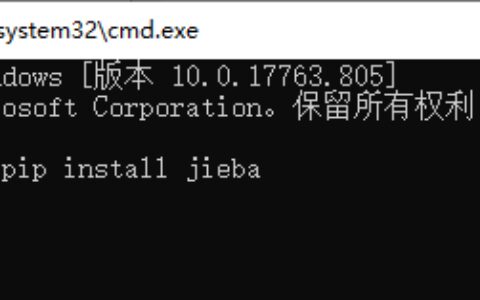
jieba库基本介绍 jieba库的安装 pip install jieba (cmd命令行) jieba分词的三种模式 精确模式、全模式、搜索引擎模式 精确模式:把文本精确的切分开,不存在冗余单词 全模式:把文本中所有可能的词语都扫描出来,有冗余 搜索引擎模式:在精确模式基础上,对长词再次切分 爬虫(爬取哔哩哔哩视频弹幕) 导…
-
nodejs爬虫笔记(二)—代理设置
node爬虫代理设置 最近想爬取YouTube上面的视频信息,利用nodejs爬虫笔记(一)的方法,代码和错误如下 var request = require(‘request’); var cheerio = require(‘cheerio’);**** var url = ‘https://www.youtube.com ‘; function cra…
-
python 黑板课爬虫闯关-第二关
#!/usr/bin/python # -*- coding:utf-8 -*- # Author: LiTianle # Time:2019/9/24 15:36 ”’ <h3>你需要在网址后输入数字53639</h3> <h3>下一个你需要输入的数字是10963. </h3> ”’ import r…
-
爬虫-识别图形验证码-tesserocr
引入: 在学习爬虫的过程中,需要解决识别图形验证码的这一难题,网上推荐的方法都是通过tesserocr模块来实现,下面就是安装步骤以及过程中遇到的问题,记录一下。 介绍: tesserocr 是 Python 的一个 OCR 识别库 ,但其实是对 tesseract 做的一 层 Python API 封装,所以它的核心是 tesseract。 因此,在安…
-
python 黑板课爬虫闯关-第五关
参考链接https://www.bbsmax.com/A/o75NvDYX5W/ 用到的tesserocr模块,安装过程可以参考我之前发的随笔或者网上自行搜索,识别率很低只能多试几次,我也没去研究如何提高识别率,用到再说了。 import re,requests,time,os from lxml import html etree=html.etree i…
-
python 黑板课爬虫闯关-第一关
#!/usr/bin/python # -*- coding:utf-8 -*- # Author: LiTianle # Time:2019/9/24 15:36 ”’ <h3>你需要在网址后输入数字53639</h3> <h3>下一个你需要输入的数字是10963. </h3> ”’ import r…
-
python 黑板课爬虫闯关-第三关
import re import requests import time def main(): # 访问第三关,需要登录,登录的url url_login = ‘http://www.heibanke.com/accounts/login/?next=/lesson/crawler_ex02/’ # 登录成功后,访问第三关url url = ‘htt…
-
增量式爬虫
增量式爬虫 概念:检测网站数据跟新的情况,爬取更新数据 核心:去重!!! 增量式爬虫 深度爬取类型的网站中需要对详情页的url进行记录和检测 记录:将爬取过的详情页的url进行记录保存 url存储到redis的set中 redis的sadd方法存取时,如果数据存在返回值为0,如果不存在返回值为1; 检测:如果对某一个详情页的url发起请求之前先要取记录表中进…