爬虫
-
python selenium结合PhantomJS对ajax异步页面进行压测或者爬虫
本人的程序是在mac上写的,windows的话可能略有不同主要是PhantomJS的路径上。首先要下载PhantomJS,然后创建一个到/usr/bin/phantomsjs的软链。为什么用selenium和PhantomJS是因为,公司是做电商的,页面很多都是ajax异步渲染出来的,使用urllib或者requests是无法渲染异步页面的,而Phant…
-
爬虫那些事儿–站点压力控制相关
经过前面的介绍,我们大致了解了站点压力控制对于爬虫的重要性。但是站点压力控制对于爬虫来说,是一个比较Open的话题。即到目前为止也没有一个很准确的压力控制方法。 主要的问题由于以下几点: 不同站点对于爬虫的压力允许程度不同。 即由于站点的规模不同、站点的服务器配置不同等。不同的站点能承受的压力是不同的。同时不同的站点对于爬虫的友好程度不同。有些站点允许爬…
-
爬虫那些事儿–Http返回码
由于爬虫的抓取也是使用http协议交互。因此需要了解Http的各种返回码所代表的意义,才能判断爬虫的执行结果。 返回码如下: 100 Continue 初始的请求已经接受,客户应当继续发送请求的其余部分。(HTTP 1.1新) 101 Switching Protocols 服务器将遵从客户的请求转换到另外一种协议(HTTP 1.1新) 200 OK 一切正…
-
爬虫那些事儿–页面变化检测策略
由于爬虫爬取的数据是为搜索引擎服务的。而搜索引擎是为互联网的数据做整合分类以便用户进行检索查看的。因此需要能感知互联网的数据的变化。 即对于爬虫已经爬取的数据还需要定期去重新抓取,以检测页面是否变化。 页面的变化我们将其划分为两类: 一: 页面仍存在,但是页面的内容改变了。我们称之为内容更新。由于搜索引擎是基于爬虫爬取的网页的内容建立…
-
[GO]并发的网络爬虫
package main import ( “fmt” “strconv” “net/http” “os” “io” ) //百度贴吧的地址规律 //第一页:https://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&ie=utf-8(&pn=0) //第二页:https…
-
04 Python网络爬虫 <<爬取get/post请求的页面数据>>之requests模块
一. urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求。其常被用到的子模块在Python3中的为urllib.request和urllib.parse,在Python2中就是urllib和urllib2。 二.requests库 - 安装: pip install requests -…
-
python 爬虫数据存入csv格式方法
python 爬虫数据存入csv格式方法 命令存储方式:scrapy crawl ju -o ju.csv 第一种方法:with open(“F:/book_top250.csv”,”w”) as f: f.write(“{},{},{},{},{}\n”.format(book_name ,rating, rating_num,comment, boo…
-
Python爬虫学习==>第五章:爬虫常用库的安装
爬虫有请求库(request、selenium)、解析库、存储库(MongoDB、Redis)、工具库,此节学习安装常用库的安装 正式步骤 Step1:urllib和re库 这两个库在安装Python中,会默认安装,下面代码示例调用: >>> import urllib >>> import urll…
-
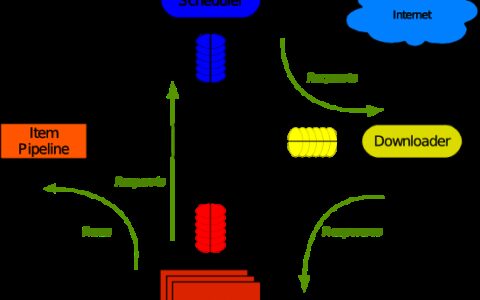
Python 爬虫七 Scrapy
Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可…
-
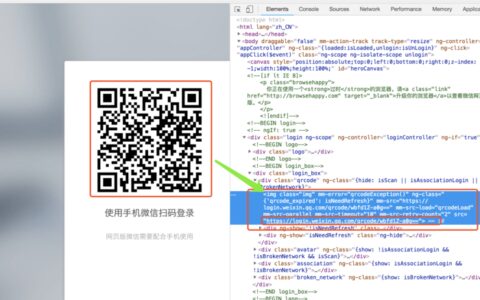
Python 爬虫五 进阶案例-web微信登陆与消息发送
首先回顾下网页微信登陆的一般流程 1、打开浏览器输入网址 2、使用手机微信扫码登陆 3、进入用户界面 1、打开浏览器输入网址 首先打开浏览器输入web微信网址,并进行监控: https://wx.qq.com/ 可以发现网页中包含了一个新的url,而这个url就是二维码的来源。 https://login.weixin.qq.com/…