作者:卢运强,主要从事 Java、Python 和 Golang 相关的开发工作。热爱学习和使用新技术;有着十分强烈的代码洁癖;喜欢重构代码,善于分析和解决问题。原文链接。
我司从 2022 年 6 月开始使用 KubeSphere,到目前为止快一年时间,简要记录下此过程中的经验积累,供大家参考。
背景
公司当前有接近 3000 人的规模,主要业务为汽车配套相关的软硬件开发,其中专门从事软件开发约有 800 人,这其中 Java 开发的约占 70%,余下的为 C/C++ 嵌入式和 C# 桌面程序的开发。
在 Java 开发部分,约 80% 的都是 Java EE 开发,由于公司的业务主要是给外部客户提供软硬件产品和咨询服务,在早期公司和部门更关注的是如何将产品销售给更多的客户、获得更多的订单和尽快回款,对软件开发流程这块没有过多的重视,故早期在软件开发部分不是特别规范化。软件开发基于项目主要采用敏捷开发或瀑布模型,而对于软件部署和运维依旧采用的纯手工方式。
随着公司规模的扩大与软件产品线的增多,上述方式逐渐暴露出一些问题:
- 存在大量重复性工作,在软件快速迭代时,需要频繁的手工编译部署,耗费时间,且此过程缺乏日志记录,后续无法追踪审计;
- 缺乏审核功能,对于测试环境和生产环境的操作需要审批流程,之前通过邮件和企业微信无法串联;
- 缺乏准入功能,随着团队规模扩大,人员素质参差不齐,需要对软件开发流程、代码风格都需要强制固化;
- 缺乏监控功能,后续不同团队、项目采用的监控方案不统一,不利于知识的积累;
- 不同客户的定制化功能太多(logo,字体,IP 地址,业务逻辑等),采用手工打包的方式效率低,容易遗漏出错。
在竞争日益激烈的市场环境下,公司需要把有限的人力资源优先用于业务迭代开发,解决上述问题变得愈发迫切。
选型说明
基于前述原因,部门准备选用网络上开源的系统来尽可能的解决上述痛点,在技术选型时有如下考量点:
- 采用尽量少的系统,最好一套系统能解决前述所有问题,避免多个系统维护和整合的成本;
- 采用开源版本,避免公司内部手工开发,节约人力;
- 安装过程简洁,不需要复杂的操作,能支持离线安装;
- 文档丰富、社区活跃、使用人员较多,遇到问题能较容易的找到答案;
- 支持容器化部署,公司和部门的业务中自动驾驶和云仿真相关的越来越多,此部分对算力和资源提出了更高的要求。
我们最开始采用的是 Jenkins,通过 Jenkins 基本上能解决我们 90% 的问题,但依旧有如下问题影使用体验:
- 对于云原生支持不太好,不利于部门后续云仿真相关的业务使用;
- UI 界面简陋,交互方式不友好(项目构建日志输出等);
- 对于项目,资源的权限分配与隔离过于简陋,不满足多项目多部门使用时细粒度的区分要求。
在网络上查找后发现类似的工具有很多,经过初步对比筛选后倾向于 KubeSphere、Zadig 这 2 款产品,它们的基本功能都类似,进一步对比如下:
| KubeSphere | Zadig | |
|---|---|---|
| 云原生支持 | 高 | 一般 |
| UI 美观度 | 高 | 一般 |
| GitHub Star | 12.4k | 2k |
| 社区活跃度 | 高 | 一般 |
经过对比,KubeSphere 较为符合我们的需求,尤其是 KubeSphere 的 UI 界面十分美观,故最终选定 KubeSphere 作为部门内部的持续集成与容器化管理系统!
至此,部门内部经历了手工操作->Jenkins->KubeSphere这 3 个阶段,各阶段的主要使用点如下:
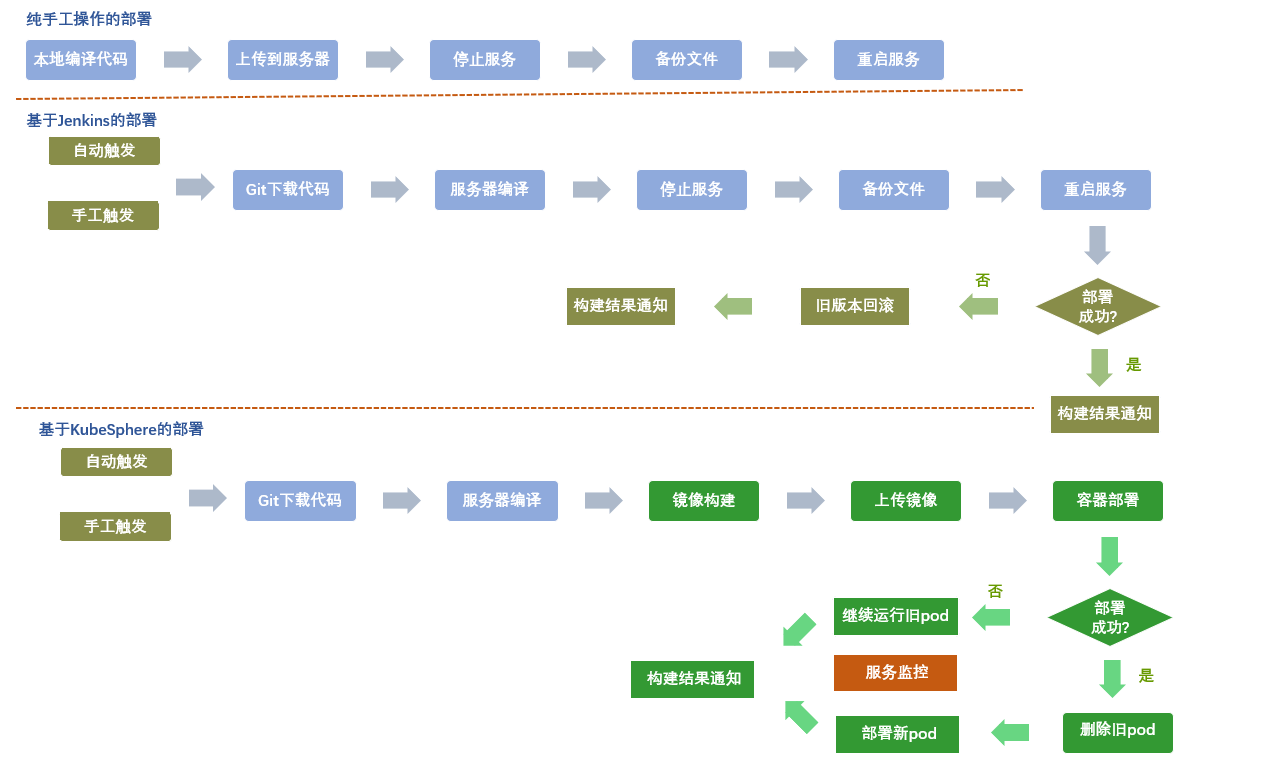
实践过程
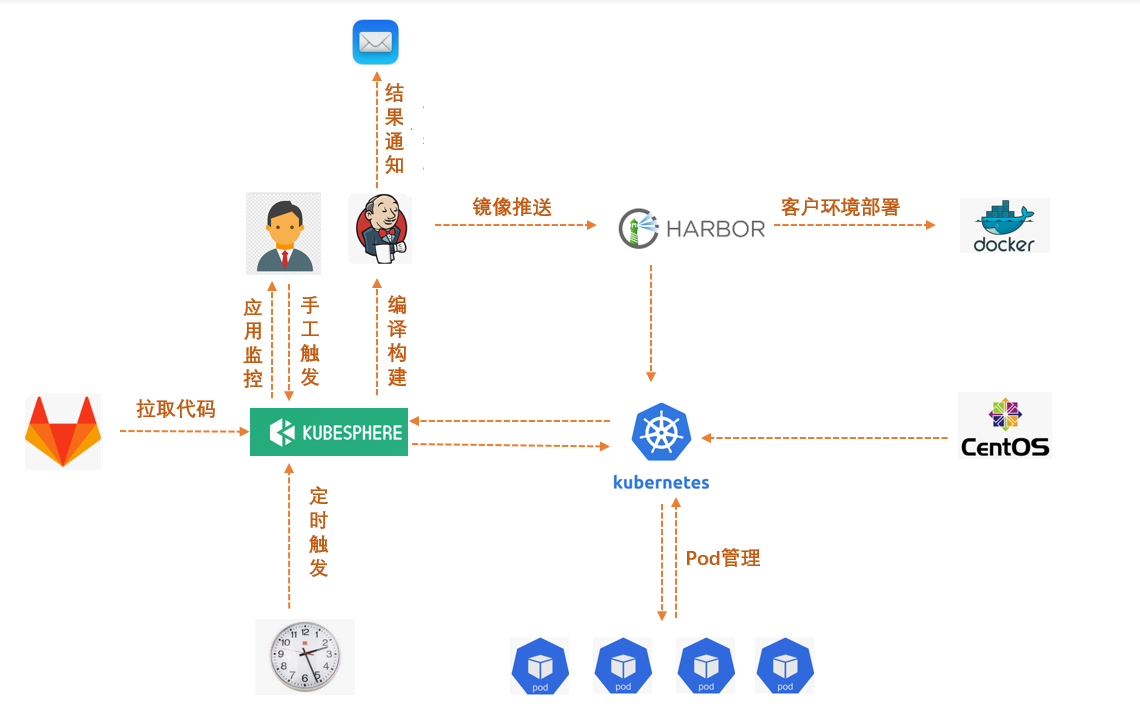
KubeSphere 在公司内部的整体部署架构如下图所示,其作为最顶层的应用程序直接与使用人员交互,提供主动/定时触发构建、应用监控等功能,使用人员不必关心底层的 Jenkins、Kubernetes 等依赖组件,只需要与 Gitlab 和 KubeSphere 交互即可。
持续集成
初始实现
在最初的尝试阶段只规划了 4 套环境:dev(开发环境)、sit(调试环境)、test(测试环境)、prod(生产环境)。
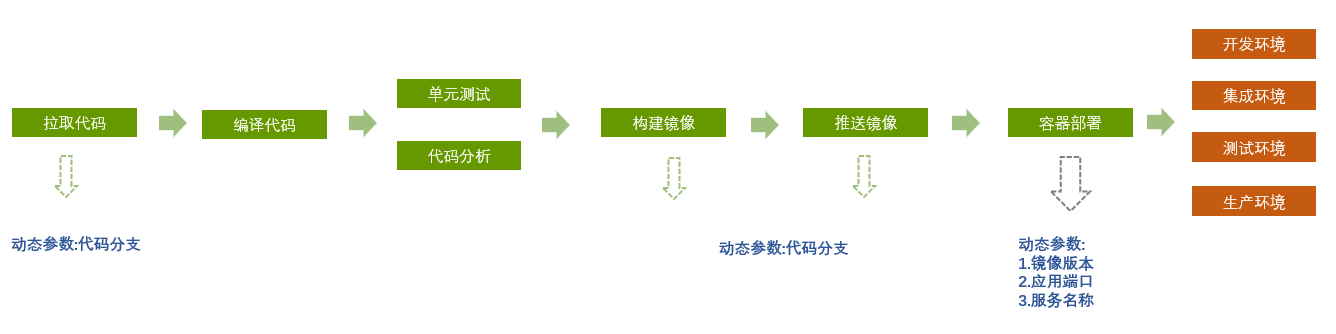
出于简化使用与维护的考虑,计划对每个工程模块只维护一条流水线,通过构建时选择不同的环境参数来实现定制化打包与部署。
KubeSphere 和 Kubernetes 目前在部门是以单机版形式安装的,故对于不同环境的区分主要是通过分配不同端口来实现,具体实现时需要能在 Jenkins 和 Kubernetes 的 yaml 文件中都能动态的获取对应的端口参数和项目名称,参考实现代码如下:
-
在基于
Groovy的script中根据选择环境动态分配相关端口switch(PRODUCT_PHASE) { case "sit": env.NODE_PORT = 13003 env.DUBBO_PORT = 13903 break case "test": env.NODE_PORT = 14003 env.DUBBO_PORT = 14903 break case "prod": env.NODE_PORT = 15003 env.DUBBO_PORT = 15903 break } -
script中读取参数print env.DUBBO_IP -
shell中读取参数docker build -f kubesphere/Dockerfile \ -t idp-data:$BUILD_TAG \ --build-arg PROJECT_VERSION=$PROJECT_VERSION \ --build-arg NODE_PORT=$NODE_PORT \ --build-arg DUBBO_PORT=$DUBBO_PORT \ --build-arg PRODUCT_PHASE=$PRODUCT_PHASE . -
yaml文件中读取参数spec: ports: - name: http port: $NODE_PORT protocol: TCP targetPort: $NODE_PORT nodePort: $NODE_PORT - name: dubbo port: $DUBBO_PORT protocol: TCP targetPort: $DUBBO_PORT nodePort: $DUBBO_PORT selector: app: lucumt-data-$PRODUCT_PHASE sessionAffinity: None type: NodePort
运行效果类似下图:
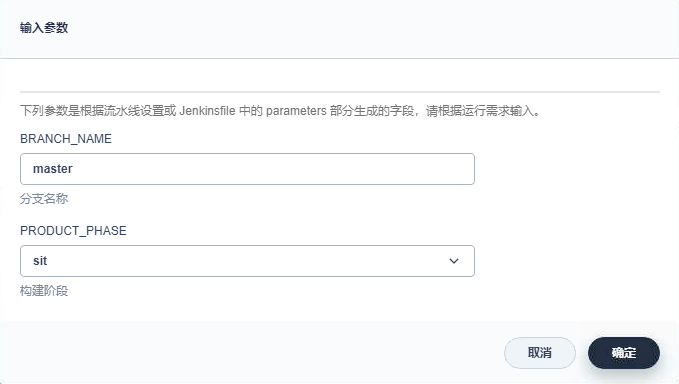
详细内容请参见KubeSphere 使用心得。
环境扩容
基于前述方式搭建的 4 套环境一开始使用较为顺利,但随着项目的推进以及开发人员的增多,同时有多个功能模块需要并行开发与测试,导致原有的 4 套环境不够用。经过一番摸索后,实现了结合 Nacos在 KubeSphere 中动态配置多套环境功能,通过修改 Nacos 中的JSON配置文件可很容易的从 4 套扩展为 16 套甚至更多。
结合项目实际情况以及避免后续再次修改 KubeSphere 流水线,为了实现灵活的配置多套环境,制定了如下 2 个规则:
- 端口信息存放到配置文件中,KubeSphere 在构建时去流水线读取相关配置
- 当需要扩展环境或修改端口时,不需要修改 KubeSphere 中的流水线,只需要修改对应的端口配置文件即可
由于项目中采用 Nacos 作为配置中心与服务管理平台,故决定采用 Nacos 作为端口的配置中心,实现流程如下:
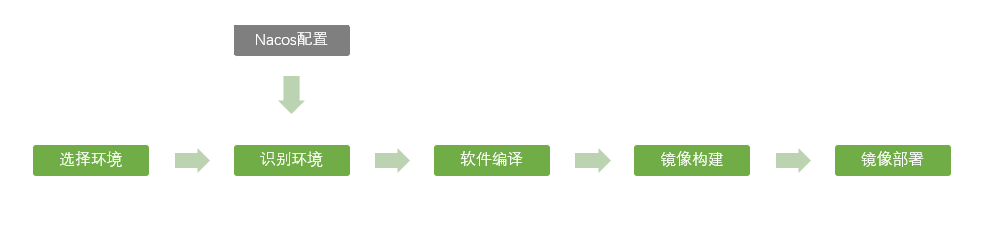
基于上述流程,在具体实现时面临如下问题:
- 利用
Groovy代码获取Nacos中特定的端口JSON配置文件,并能动态解析; - 利用
Groovy代码根据输入输入参数动态的获取Nacos中对应的namespace; - 由于环境的增多,不可能每套环境都准备一个
YAML文件,此时需要动态的读取并更新YAML文件。
由于 Jenkins 默认不支持 JSON、YAML 的解析,需要在 Jenkins 中预先安装 Pipeline Utility Steps插件,该插件提供了对 JSON、YAML、CSV、PROPERTIES 等常见文件格式的读取与修改操作。
-
JSON文件设计如下,通过 env、server、dubbo 等属性记录环境和端口信息,通过 project 来记录具体的项目名称,由于配置文件中的 key 都是固定的,后续Groovy解析时会较为方便,在需要扩展环境时只需要更新此JSON文件即可。{ "portConfig":[ { "project":"lucumt-system", "ports":[ { "env":"dev-1", "server":12001, "dubbo":12002 }, { "env":"dev-2", "server":12201, "dubbo":12202 } ] }, { "project":"lucumt-idp", "ports":[ { "env":"dev-1", "server":13001, "dubbo":13002 }, { "env":"dev-2", "server":13201, "dubbo":13202 } ] } ] } -
Nacos Open Api 中可知查询
namespace的请求为/nacos/v1/console/namespaces,查询配置文件的请求为/nacos/v1/cs/configs,基于Groovy的读取代码如下:response = sh(script: "curl -X GET 'http://xxx.xxx.xxx.xxx:8848/nacos/v1/console/namespaces'", returnStdout: true) jsonData = readJSON text: response namespaces = jsonData.data for(nm in namespaces){ if(BUILD_TYPE==nm.namespaceShowName){ NACOS_NAMESPACE = nm.namespace } } response = sh(script: "curl -X GET 'http://xxx.xxx.xxx.xxx:8848/nacos/v1/cs/configs?dataId=idp-custom-config.json&group=idp-custom-config&tenant=0f894ca6-4231-43dd-b9f3-960c02ad20fa'", returnStdout: true) jsonData = readJSON text: response configs = jsonData.portConfig for(config in configs){ project = config.project if(project!=PROJECT_NAME){ continue } ports = config.ports for(port in ports){ if(port.env!=BUILD_TYPE){ continue } env.NODE_PORT = port.server } } -
动态更新
yaml文件yamlFile = 'src/main/resources/bootstrap-dev.yml' yamlData = readYaml file: yamlFile yamlData.spring.cloud.nacos.discovery.group = BUILD_TYPE yamlData.spring.cloud.nacos.discovery.namespace = NACOS_NAMESPACE yamlData.spring.cloud.nacos.config.namespace = NACOS_NAMESPACE sh "rm $yamlFile" writeYaml file: yamlFile, data: yamlData
详细内容请参见利用 Nacos 与 KubeSphere 创建多套开发与测试环境。
扩展功能
-
在项目构建时添加审核功能,对于
test和prod环境必须经过相关人的审核才能进行后续构建流程,避免破坏相关版本的稳定性。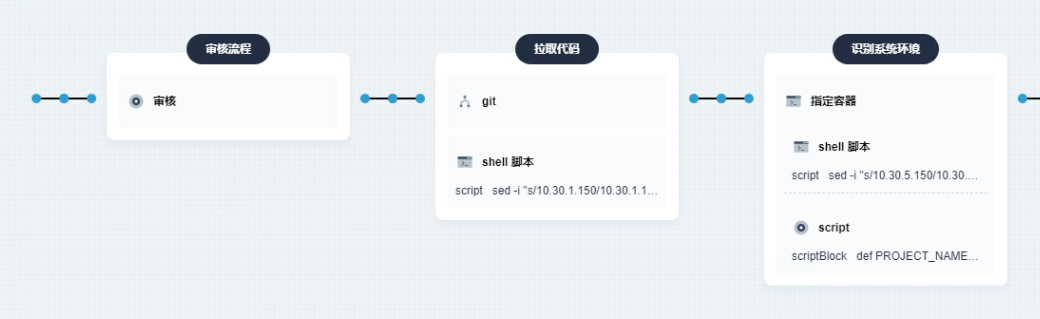
-
在 KubeSphere 的容器组页面可以查看 pod 节点的 CPU 和内存消耗,可初步满足对代码潜在性能问题的排查。
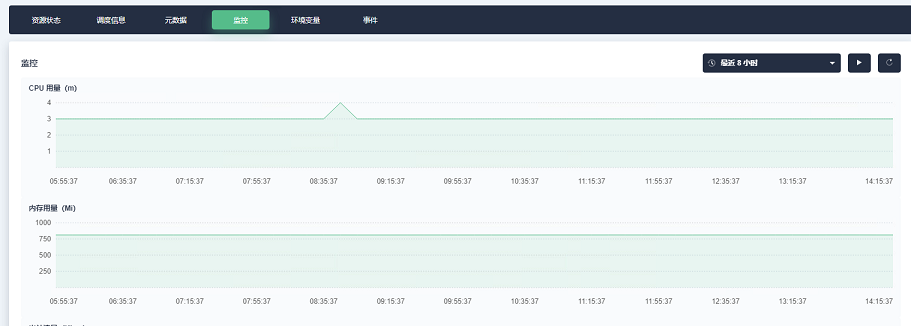
-
在项目构建完成时发送邮件通知给相关人。
外部部署
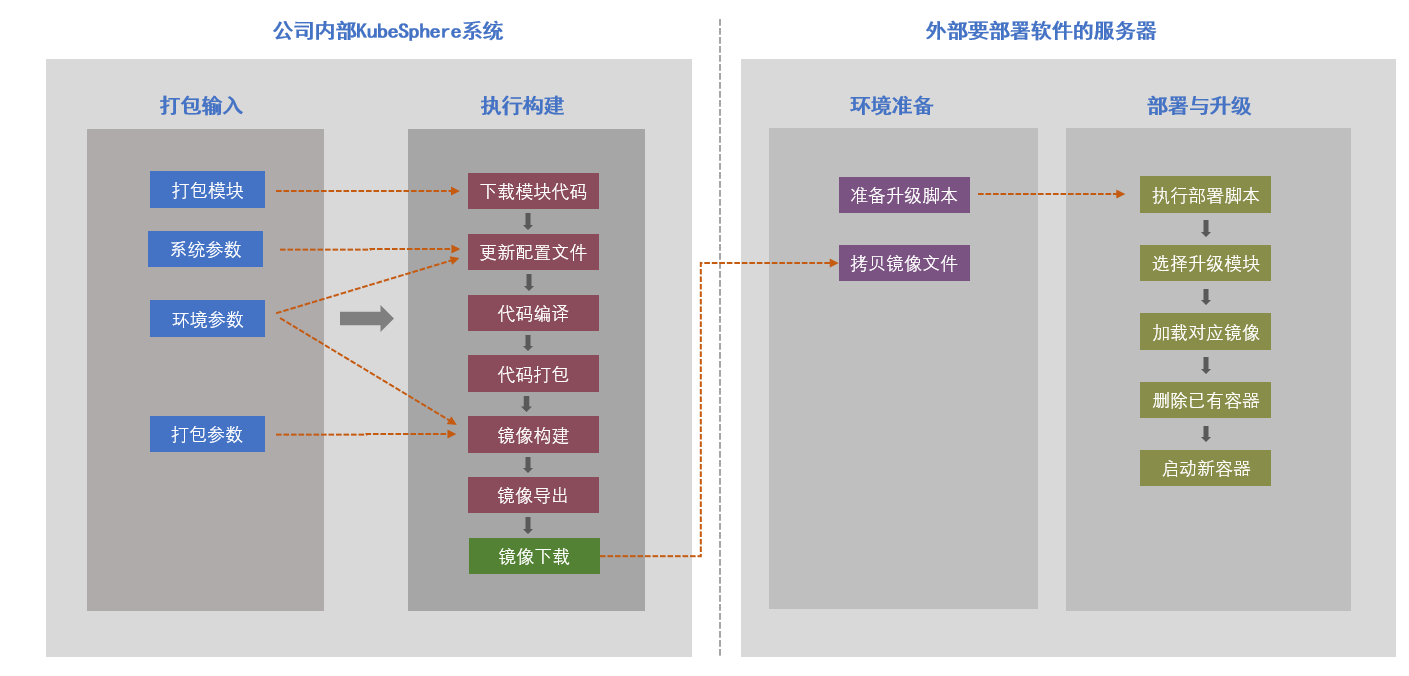
部门内部的软件最终都会销售并交付给相关客户,由于客户网络与公司网络不通以及代码保密等要求,无法在客户现场使用原有的 Jenkins 流水线进行部署交付。基于此部门采取折中方案:在公司内部通过 KubeSphere 进行编译打包,导出 Docker 镜像,拷贝到客户处然后基于 Docker 镜像部署运行,具体请参见如下链接:
使用协助
在使用过程中确实遇到了不少问题,主要通过如下三条途径解决:
根据部门使用经验,90% 的问题可通过官方文档或用户论坛获得答案。
使用效果
部分同事习惯于原始的手工操作或基于 Docker 部署,导致在推广过程中受到了一定的阻力,部门内部基于充分沟通和逐步替换的方式引导相关同事来慢慢适应。经过约一年的时间磨合,大家都认可了拥抱云原生和 KubeSphere 给我们带来的便利,使用过的同事都说很香!
对我司而言,有如下几个方面的提升:
- 研发人员几乎不用耗费时间在软件的部署和监控上,节省约 20% 时间,产品迭代速度更快;
- 定制化的功能通过脚本实现,彻底杜绝了给客户交付软件时由于人工疏漏导致的偶发问题,在提高软件交付质量的同时也提升了客户我司的认可度;
- 软件开发、测试流程更规范,通过在
Jenkins流水线强制添加各种规范检查和审核流程,实现了软件研发的规范统一,代码质量更高,更利于扩展维护,同时也在一定程序上减少了由于人员流失/变更对项目造成的影响; - 基于
KubeSphere的云原生部署结合Nacos可以更快速的分配多套环境,有效的实现了开发、测试、生产环境的隔离,在云仿真相关的业务场景中可基于业务场景更方便的对pod进行监控与调整,前瞻性的业务研发开展更顺利。

未来规划
结合公司与部门的实际情况,短期的规划依然是完善基于 Jenkins 的 CI/CD 使用来完善打包与部署流程,部门内部在进行全面 web 化,基于此中长期拥抱云原生。
- 接入企业微信,将构建与运行结果随时通知相关人,构建结果与项目监控更实时;
- 将部门内部基于
Eclipse RCP的桌面应用程序通过Jenkins实现标准化与自动化的构建; - 将底层的
Kubernetes从单机升级为集群,支持更多pod的部署,支持公司内部需要大量pod并发运行的云仿真项目; - 部门内部的
web项目全部通过KubeSphere构建部署,完善其使用文档,挖掘KubeSphere在部门业务中新的应用场景(如对设计文档、开发文档、bug 修复的定时与强制检查通知等)。
本文由博客一文多发平台 OpenWrite 发布!
原文链接:https://www.cnblogs.com/kubesphere/p/17336223.html
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:KubeSphere 助力提升研发效能的应用实践分享 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫