Pytorch基础操作
numpy基础操作
- 定义数组(一维与多维)
- 寻找最大值
- 维度上升与维度下降
- 数组计算
- 矩阵reshape
- 矩阵维度转换
代码实现
import numpy as np
a = np.array([1, 2, 3, 4, 5, 6]) # array数组
b = np.array([8, 7, 6, 5, 4, 3])
print(a.shape, b.shape) # shape为数组的格式
aa = np.reshape(a, (2, 3)) # reshape为格式转换,格式转换为2行3列的二维数组
print(aa, aa.shape)
bb = np.reshape(b, (1, 1, 1, 6)) # 转换为 1*1*1*6 格式的数组
print(bb, bb.shape)
a1 = np.squeeze(aa) # squeeze方法会将只有 1 的维度去掉,只保留大于 1 的维度
b1 = np.squeeze(bb)
print(a1, a1.shape)
print(b1, b1.shape)
a2 = np.transpose(aa, (1, 0)) # transpose数组转置,原行列式形式为(0,1),后面的参数(1,0)表示将行列交换位置变为(1,0)格式
print(a2, a2.shape)
b_index = np.argmax(b) # argmax函数表示获取该数组中的最大值索引
bb_index = np.argmax(bb)
aa_index = np.argmax(aa[0]) # argmax函数可以获取多维数组中任意维度中最大值的索引,没有输入维度时会将多维数组转换为一维获取索引
print(b_index, b[b_index])
print(bb_index, bb[0][0][0][bb_index])
print(aa_index)
a3 = np.reshape(aa, -1) # 参数-1表示恢复成一维数组
print(a3, a3.shape)
# zeros函数以0填充生成指定行列大小的数组,数组数值类型默认为float64,可手动设置int8,uint8(无符号二进制整型),float16,float32,float64等
m1 = np.zeros((6, 6), dtype=np.uint8)
m2 = np.linspace(6, 10, 100) # linspace函数,以均匀步长生成数字序列,linspace(start,end,nums)
print(m1)
print(m2)
OpenCV-Python基础操作
- 读写图像与灰度转换
- 读取视频与显示
- 归一化与显示
- 创建空白图像
- 提取ROI与分离、合并通道
代码实现
import cv2 as cv
import numpy as np
src = cv.imread("D:/images/lena.jpg")
h, w, c = src.shape # 获取到图像的类型为HWC
print(h, w, c)
src1 = np.transpose(src, (2, 0, 1)) # 将输入图像的通道类型进行转置
print(src1.shape)
float_src = np.float32(src) / 255.0 # 将图像变成0-1的浮点数类型
gray = cv.cvtColor(src, cv.COLOR_BGR2GRAY)
rgb = cv.cvtColor(src, cv.COLOR_BGR2RGB) # opencv读取的图像默认为BGR三通道,转换为RGB三通道图像
dst = cv.resize(src, (224, 224))
cv.imshow("input", src)
cv.imshow("float_src", float_src)
cv.imshow("GRAY", gray)
cv.imshow("GRAY_0", src[:, :, 0]) # 进入图像第一个通道,前面两个:表示尺寸512
# cv.imshow("GRAY_1", src[:, :, 1]) # 进入图像第一个通道
# cv.imshow("GRAY_2", src[:, :, 2]) # 进入图像第一个通道
# cv.imshow("GRAY_3", src[:, :, :]) # 获取图像三个通道
cv.imshow("zoom out", dst) # zoom in放大,zoom out缩小
box = [50, 50, 100, 100] # x, y, w, h
roi = src[200:400, 200:400, :] # 截取目标区域 src[y1:y2, x1:x2, :] 灰度图则不需要最后的通道数:
cv.imshow("roi", roi)
m1 = np.zeros((512, 512), dtype=np.uint8) # 创建空白单通道灰度图像
m2 = np.zeros((512, 512, 3), dtype=np.uint8) # 创建空白三通道彩色图像
m2[:, :, :] = (127, 0, 0) # 对图像的三通道进行赋值
cv.imshow("m1", m1)
cv.imshow("m2", m2)
cv.rectangle(src, (200, 200), (400, 400), (0, 255, 0), 2, 8) # 对选定的左上角坐标与右下角坐标之间绘制矩形
cv.imshow("rect_src", src)
cap = cv.VideoCapture("D:/images/video/face_detect.mp4")
while True:
ret, frame = cap.read()
if ret is not True: # ret为布尔类型,表示是否获取到下一帧图像
break
cv.imshow("video", frame)
c = cv.waitKey(50) # waitKey方法是等待一定的时间获取键盘输入,参数为等待的毫秒数,默认可设为1
# c = cv.waitKey(1)
if c == 27: # 如果按下ESC则退出循环
break
cv.waitKey(0)
cv.destroyWindow()
效果:
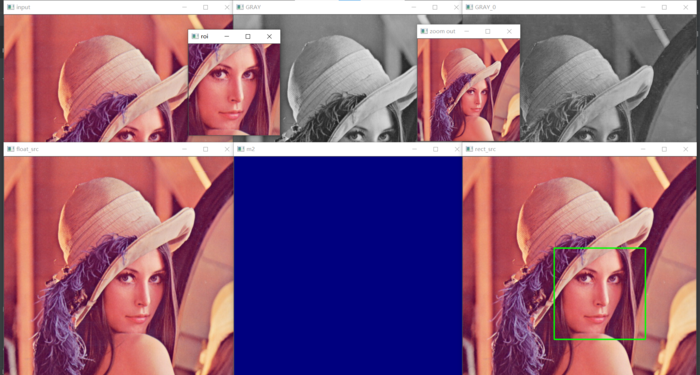

Pytorch基础操作
- 定义常量与变量
- Tensor与numpy转换
- 数据reshape与最大值索引
- 随机数据生成
- 基本算术操作
- 基本卷积操作
- GPU检测与支持
- 网格化与cat
代码实现
import torch
import numpy
x = torch.empty(2, 2)
x1 = torch.zeros(2, 2)
x2 = torch.randn(2, 2) # 随机生成指定大小的tensor
print(x)
print(x1)
print(x2)
y = torch.tensor([1, 2, 3, 4, 5, 6, 7, 8, 9, 0])
z = torch.tensor([11, 12, 13, 14, 15, 16, 17, 18, 19, 20])
print(y)
print(z)
res01 = torch.add(y, z)
res02 = y.add(z)
print(res01)
print(res02)
# x = x.view(-1, 4) # -1为自动补充,4表示转置为4列的tensor,最终转置成1行4列的tensor
x = torch.view_copy(x, (4, -1)) # 将x转置为4行1列
print(x)
print(x.size()) # 获取x的维度信息
nx = x.numpy() # tensor转换为numpy数组
print(nx)
tensor_x = torch.from_numpy(nx.reshape((2, 2))) # numpy数组转换为tensor
print(tensor_x)
if torch.cuda.is_available(): # 使用GPU对tensor进行运算
print("GPU Detected")
result = x.cuda() + y.cuda()
print(result)
else:
print("GPU is not available")
训练过程中关于LOSS的一些说明
- train loss 不断下降,test loss 不断下降,说明网络正在学习
- train loss 不断下降,test loss 趋于不变,说明网络过拟合
- train loss 趋于不变,test loss 趋于不变,说明学习遇到瓶颈,需要减小学习率或者批处理大小
- train loss 趋于不变,test loss 不断下降,说明数据集100%有问题
- train loss 不断上升,test loss 不断上升(最终变为NaN),可能是网络结构设计不当,训练超参数设置不当,程序bug等某个问题引起
自动梯度与回归
自动梯度
函数式的编程方式
- 所见即所得,定义类、方法、函数、参数
- 先检查语法错误
- 再编译与链接
- 生成可执行文件
- 支持各种参数输入与输出,界面的交互操作
图的编程方式(深度学习)
-
构建计算图
-
早期 - 先定义再执行,现在 JIT(just in time即时编译) 方式
-
静态图 VS 动态图
-
输入的数据 - 张量
-
图中的每个节点 - OP
-
构建完成后即可执行
-
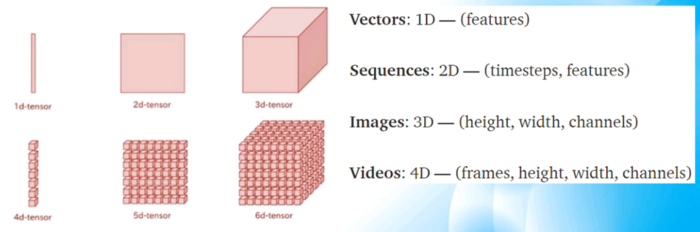
深度学习中的数据结构:tensor张量
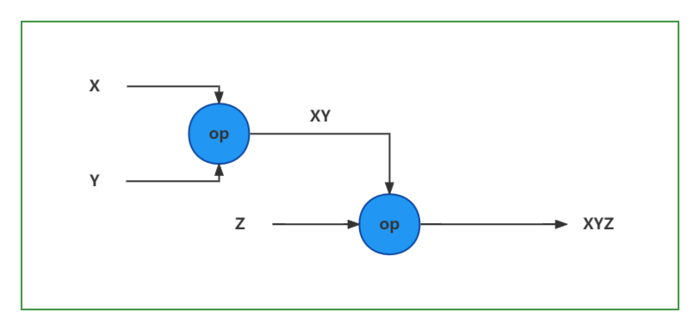
计算图构建与执行
- 计算图的构建 - 定义数据()与OP操作,通过链式求导法则
x, y, z输入被称为张量,整个计算过程定义被称为图的构建
自动梯度求导:
]
]
]
代码实现
import torch
x = torch.randn(1, 5, requires_grad=True) # randn()函数生成目标尺度的tensor,值随机
y = torch.randn(5, 3, requires_grad=True)
z = torch.randn(3, 1, requires_grad=True)
print("x:n", x, "nyn", y, "nzn", z)
xy = torch.matmul(x, y) # matmul()函数对两个输入的tensor张量矩阵计算乘积
print("xyn", xy)
xyz = torch.matmul(xy, z)
xyz.backward() # backward()函数,自动计算xyz之前的梯度
print(x.grad, y.grad, z.grad) # grad方法获取该tensor的梯度
zy = torch.matmul(y, z).view(-1, 5) # view()函数将矩阵转置为目标形式
print(zy)
线性回归
- 根据输入的数据拟合直线
X : 1, 2, 0.5, 2.5, 2.6, 3.1
Y : 3.7, 4.6, 1.65, 5.68, 5.98, 6.95
Y = kX + b
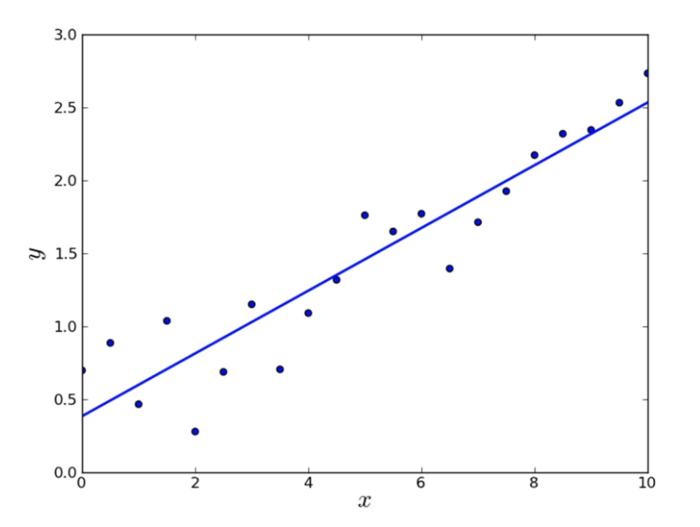
线性回归模型与拟合计算
- 构建模型
- 计算损失
- 更新参数(训练)
数据 + 模型 + 损失 + 优化
随机梯度下降法:
大多数机器学习或者深度学习算法都涉及某种形式的优化。 优化指的是改变 特征x以最小化或最大化某个函数 f(x) 的任务。 我们通常以最小化 f(x) 指代大多数最优化问题。 最大化可经由最小化算法最小化 -f(x) 来实现。我们把要最小化或最大化的函数称为目标函数或准则。 当我们对其进行最小化时,我们也把它称为损失函数或误差函数。
下面,我们假设一个损失函数为:
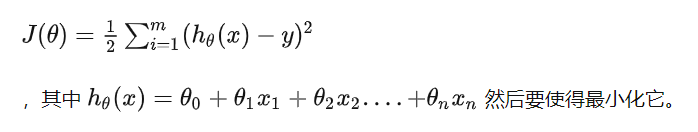
梯度下降:梯度的方向是函数在给定点上升最快的方向,那么梯度的反方向就是函数在给定点下降最快的方向,因此我们在做梯度下降的时候,应该是沿着梯度的反方向进行权重的更新,可以有效的找到全局的最优解。
随机梯度下降法(stochastic gradient descent,SGD)算法是从样本中随机抽出一个,训练后按梯度更新一次,然后再抽取一个,再更新一次,在样本量及其大的情况下,可能不用训练完所有的样本就可以获得一个损失值在可接受范围之内的模型了。(重点:每次迭代使用一组样本。)为什么叫随机梯度下降算法呢?这里的随机是指每次迭代过程中,样本都要被随机打乱,这个也很容易理解,打乱是有效减小样本之间造成的参数更新抵消问题。
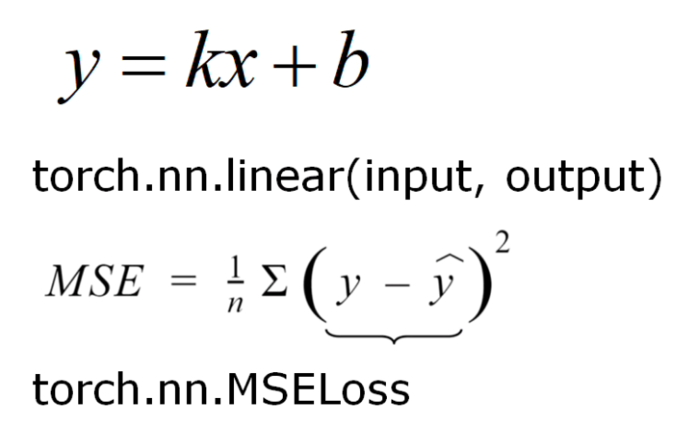
更新参数:
params = params - learning_rate * param_gradient
learning_rate = 0.01
optimizer = torch.optim.SGD(model.parameters(), lr = learning+rate)
代码实现
- 使用torch.nn.Module构建模型
- 前向计算损失
- 反向梯度优化与训练
- 使用训练好的模型完成预测
import torch
import numpy as np
import matplotlib.pyplot as plt
x = np.array([1, 2, 0.5, 2.5, 2.6, 3.1], dtype=np.float32).reshape(-1, 1)
y = np.array([3.7, 4.6, 1.65, 5.68, 5.98, 6.95], dtype=np.float32).reshape(-1, 1)
class LinearRegressionModel(torch.nn.Module):
def __init__(self, input_dim, output_dim):
super(LinearRegressionModel, self).__init__()
self.linear = torch.nn.Linear(input_dim, output_dim) # 根据输入输出数据维度初始化一个线性回归模型
def forward(self, x):
out = self.linear(x) # 根据输入数据计算当前线性回归模型的输出值
return out
input_dim = 1
output_dim = 1
model = LinearRegressionModel(input_dim, output_dim)
criterion = torch.nn.MSELoss() # 使用MSE(Mean Squared Error 均方误差)方法计算模型输出值与实际结果之间的差异
learning_rate = 0.01
# 使用SGD(stochastic gradient descent 随机梯度下降法)按输入的学习率优化模型参数
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
for epoch in range(100):
epoch += 1
# 将numpy数组转换为torch类型tensor
inputs = torch.from_numpy(x).requires_grad_()
labels = torch.from_numpy(y)
# 将优化器中的梯度清空
optimizer.zero_grad()
# 执行推理,获取模型输出
outputs = model(inputs)
# 计算模型输出结果与实际结果的差异
loss = criterion(outputs, labels)
# 自动计算梯度
loss.backward()
# 更新参数
optimizer.step()
print('epoch {}, loss {}'.format(epoch, loss.item()))
# 将x数组转换为tensor放入迭代训练好的模型获取计算结果,并转换为numpy数组
predicted_y = model(torch.from_numpy(x).requires_grad_()).data.numpy()
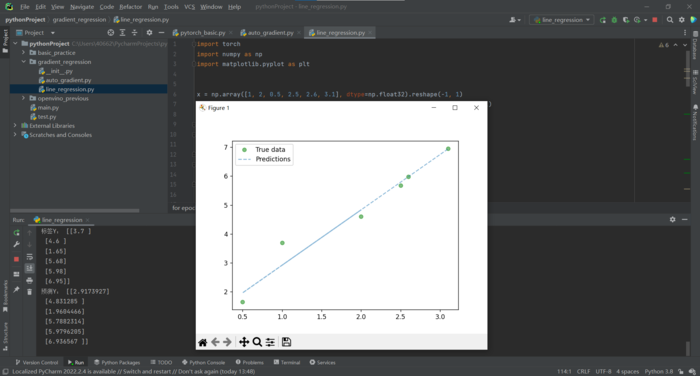
print("标签Y:", y)
print("预测Y:", predicted_y)
plt.clf()
# 绘制实际x与y对应的点与模型预测直线
plt.plot(x, y, 'go', label='True data', alpha=0.5)
plt.plot(x, predicted_y, '--', label='Predictions', alpha=0.5)
plt.legend(loc='best')
plt.show()
效果:
逻辑回归
- 在线性组合的基础上加上非线性变换
]
- 构建模型
- 计算损失
- 更新参数(训练)
数据 + 模型 + 损失(二分类交叉熵损失函数BCE(Binary Cross Entropy)详细内容可查看博客:一文搞懂熵(Entropy),交叉熵(Cross-Entropy)) + 优化

代码实现
- 使用torch.nn.Module构建模型
- 前向计算损失
- 反向梯度优化与训练
- 使用训练好的模型完成预测
import numpy as np
import torch
import matplotlib.pyplot as plt
x = np.linspace(-5, 5, 20, dtype=np.float32)
_b = 1/(1 + np.exp(-x))
y = np.random.normal(_b, 0.005) # 添加随机值来初始化逻辑回归的输入及目标值
x = np.float32(x.reshape(-1, 1))
y = np.float32(y.reshape(-1, 1))
class LogicRegressionModel(torch.nn.Module):
def __init__(self, input_dim, output_dim):
super(LogicRegressionModel, self).__init__()
self.linear = torch.nn.Linear(input_dim, output_dim)
def forward(self, x):
out = torch.sigmoid(self.linear(x))
return out
input_dim = 1
output_dim = 1
model = LogicRegressionModel(input_dim, output_dim) # 初始化逻辑回归模型
criterion = torch.nn.BCELoss() # 计算交叉熵损失函数
learning_rate = 0.01
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate) # 优化器优化模型参数
for epoch in range(1000):
epoch += 1
inputs = torch.from_numpy(x).requires_grad_()
labels = torch.from_numpy(y)
optimizer.zero_grad()
outputs = model(inputs) # 将获取模型输出值
loss = criterion(outputs, labels) # 计算loss
loss.backward() # 计算梯度
optimizer.step() # 优化模型参数
print('epoch {}, loss {}'.format(epoch, loss.item()))
predicted_y = model(torch.from_numpy(x).requires_grad_()).data.numpy()
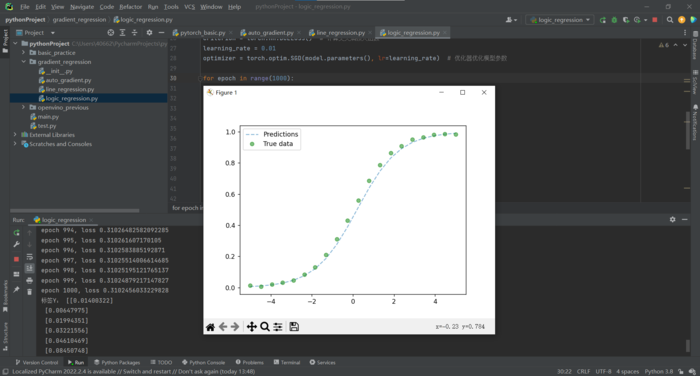
print("标签Y:", y)
print("预测Y:", predicted_y)
# 清除当前figure 的所有axes(容器),但是不关闭这个window,所以能继续复用于其他的plot
plt.clf()
plt.plot(x, predicted_y, '--', label='Predictions', alpha=0.5)
plt.plot(x, y, 'go', label='True data', alpha=0.5)
plt.legend(loc='best') # 图例自动放在坐标平面图标最少的位置
plt.show()
效果:
人工神经网络
人工神经网络基本概念
- 人工神经网络发展历史
- 多层感知机
- 前向网络与反向网络
- 反向传播算法
感知机(线性组合+非线性变换)
]
]
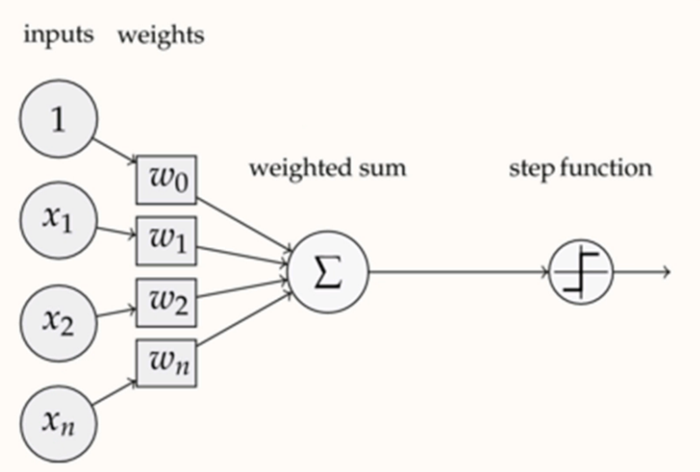
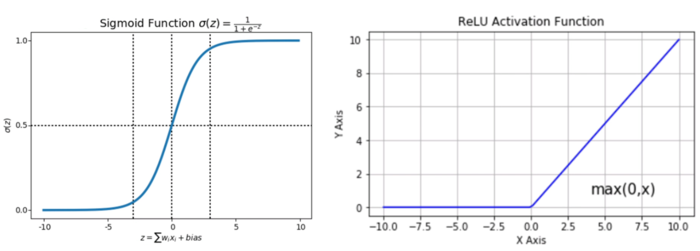
激活函数
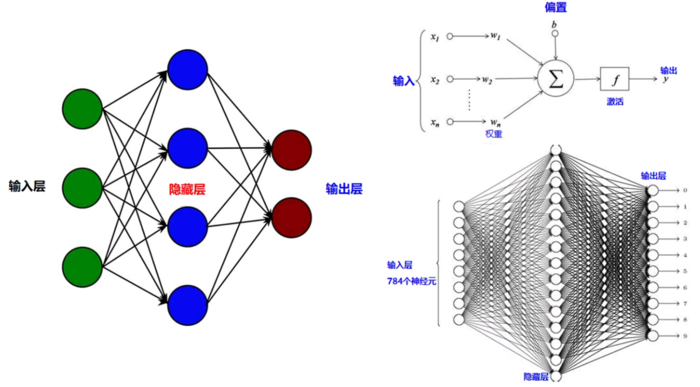
多层感知机(MLP,Multilayer Perceptron)
- 多层感知机,也叫人工神经网络(ANN,Artificial Neural Network)
反向传播算法
-
反向传播算法
静态反向传播、循环反向传播
-
两个阶段:
前向传播阶段、反向传播阶段
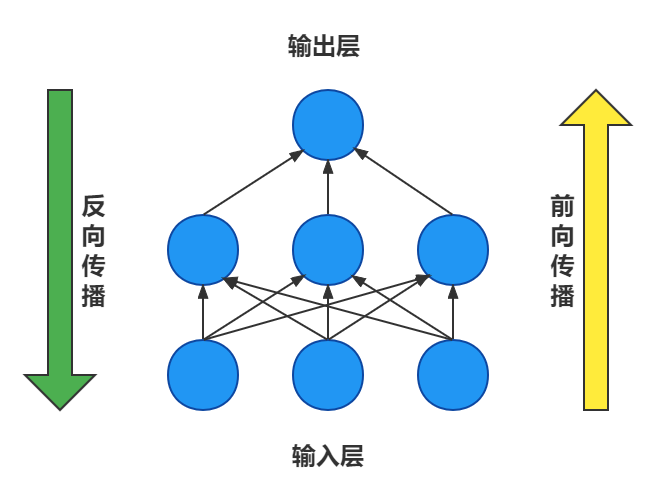
1、前向传播:
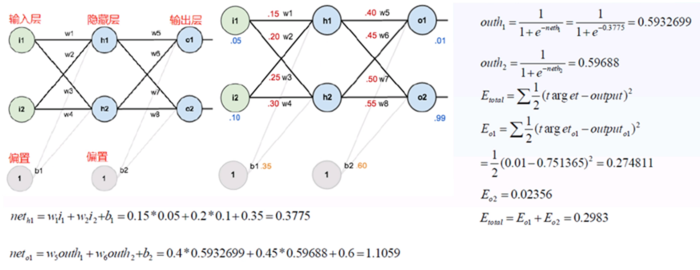
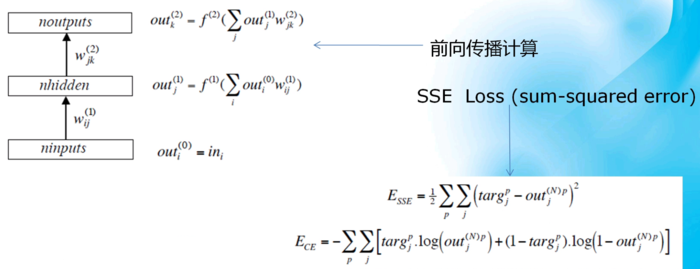
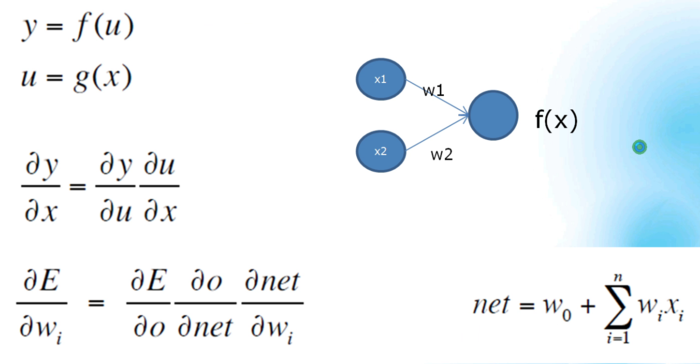
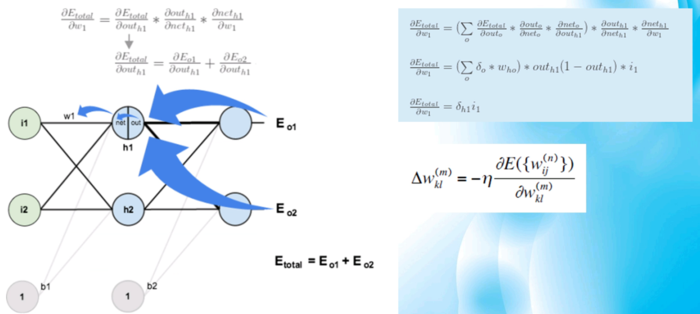
2、反向传播(链式求导):

3、训练方法
- 随机/世故梯度下降
- 从m个样本中每次随机抽取1个进行梯度下降
- 批量梯度下降
- 从m个样本中每次抽取所有样本进行梯度下降
- Mini-batch梯度下降(小批量梯度下降)
- 从m个样本中每次提取n个进行梯度下降(1<n<m)
Pytorch中的基础数据集
-
数据是深度学习核心之一
- 深度学习的三个关键组成要素
- 数据对深度学习模型训练的作用
- 数据来源与众包
- 常见数据集Pascal VOC / COCO
-
Pytorch基础数据集介绍
- torchvision.datasets 包
- Mnist/Fashion-Mnist/CIFAR
- ImageNet/Pascal VOC/MS-COCO
- Cityscapes/FakeData
-
加载/读取/显示/使用
-
数据集的读取与加载
-
torch.utils.data.Dataset的子集
-
torch.utils.data.DataLoader加载数据集
Dataset只负责数据的抽象,一次调用getitem只返回一个样本。在训练神经网络时,最好是对一个batch的数据进行操作,同时还需要对数据进行shuffle和并行加速等。对此,PyTorch提供了DataLoader帮助我们实现这些功能。
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, *, prefetch_factor=2, persistent_workers=False)
-
-
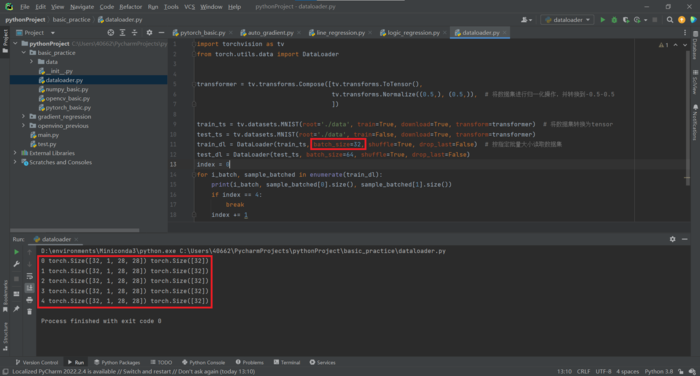
代码实现
import torchvision as tv
from torch.utils.data import DataLoader
transformer = tv.transforms.Compose([tv.transforms.ToTensor(),
tv.transforms.Normalize((0.5,), (0.5,)), # 将数据集进行归一化操作,并转换到-0.5~0.5
])
train_ts = tv.datasets.MNIST(root='./data', train=True, download=True, transform=transformer) # 将数据集转换为tensor
test_ts = tv.datasets.MNIST(root='./data', train=False, download=True, transform=transformer)
train_dl = DataLoader(train_ts, batch_size=32, shuffle=True, drop_last=False) # 按指定批量大小读取数据集
test_dl = DataLoader(test_ts, batch_size=64, shuffle=True, drop_last=False)
index = 0
for i_batch, sample_batched in enumerate(train_dl):
print(i_batch, sample_batched[0].size(), sample_batched[1].size())
if index == 4:
break
index += 1
效果:
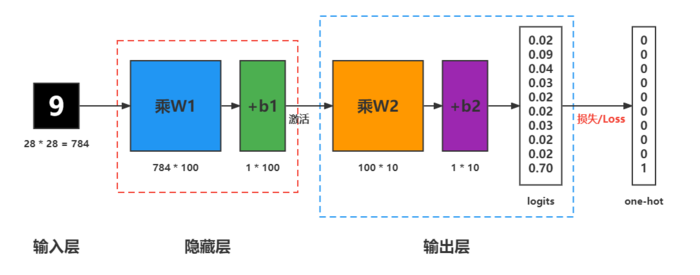
手写数字识别人工神经网络
- Mnist数据集
- 数据集下载地址 - http://yann.lecun.com/exdb/mnist
- 训练数据集 6W 张图像,测试数据集 1W 张图像,数据格式说明 28 * 28大小
- 构建模型(MLP构建)
- 模型训练
- 超参数设置(批次/学习率)
- 优化器选择
- Adam(Adaptive Moment Estimation)对每个不同的参数调整不同的学习率,对频繁变化的参数以更小的步长进行更新,而稀疏的参数以更大的步长进行更新。对梯度的一阶矩估计(First Moment Estimation,即梯度的均值)和二阶矩估计(Second Moment Estimation,即梯度的未中心化的方差)进行综合考虑,计算出更新步长。
- 训练epoch/step
代码实现
import torch
import torchvision
from torch.utils.data import DataLoader
transformer = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.5,), (0.5,)),
])
train_ts = torchvision.datasets.MNIST(root='./data', train=True, transform=transformer, download=True)
test_ts = torchvision.datasets.MNIST(root='./data', train=False, transform=transformer, download=True)
train_dl = DataLoader(train_ts, batch_size=128, shuffle=True, drop_last=False)
test_dl = DataLoader(test_ts, batch_size=64, shuffle=True, drop_last=False)
model = torch.nn.Sequential(
torch.nn.Linear(784, 100), # 输入784个值,输出100个值
torch.nn.ReLU(), # 使用ReLU()激活函数
torch.nn.Linear(100, 10), # 输入100个值,输出10个值
torch.nn.LogSoftmax(dim=1) # dim=1表示对每一行的值进行logsoftmax计算
)
# softmax为将每个输入样本中所有的值归一化后累加和为1,则其中最大值所对应的标签位置为该样本的预测结果
# logsoftmax为对每个输入样本求取softmax函数(值域为[0,1])再取log(值域为(-∞,0])
# NLLLoss为将logsoftmax结果取反,再将每个样本对应标签位置的值累加后求平均值
loss_fn = torch.nn.NLLLoss(reduction="mean") # Negative Log Likelihood Loss
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3) # 自适应梯度优化
for s in range(5):
print("run in epoch : %d"%s)
for i, (x_train, y_train) in enumerate(train_dl):
x_train = x_train.view(x_train.shape[0], -1) # x_train转置为batch_size行,y_train为每个样本对应的标签
y_pred = model(x_train)
train_loss = loss_fn(y_pred, y_train)
if (i + 1) % 100 == 0: # 每循环100次输出依次当前loss数据
print(i + 1, train_loss.item())
model.zero_grad()
train_loss.backward()
optimizer.step()
total = 0
correct_count = 0
for test_images, test_labels in test_dl:
for i in range(len(test_labels)):
image = test_images[i].view(1, 784)
# with 语句适用于对资源进行访问的场合,确保不管使用过程中是否发生异常都会执行必要的“清理”操作,释放资源,比如文件使用后自动关闭/线程中锁的自动获取和释放等。
# 在pytorch中,tensor有一个requires_grad参数,如果设置为True,则反向传播时,该tensor就会自动求导。
# with torch.no_grad的作用下,所有计算得出的tensor的requires_grad都自动设置为False。
with torch.no_grad():
pred_labels = model(image)
plabels = torch.exp(pred_labels) # 将pred_labels转换到0~+∞,便于获取最大值
probs = list(plabels.numpy()[0]) # 获取第一行plabels最大值的索引值
pred_label = probs.index(max(probs))
print(test_labels)
true_label = test_labels.numpy()[i]
if pred_label == true_label:
correct_count += 1
total += 1
print("total acc : %.2fn"%(correct_count / total))
torch.save(model, './nn_mnist_model.pt')
模型保存与预测调用
-
模型保存/加载
-
保存整个模型
-
# 保存模型 torch.save(model, PATH) # 加载模型 model = torch.load(PATH) model.eval()
-
-
保存推理模型
-
在模型中,我们通常会加上Dropout层和batch normalization层,在模型预测阶段,我们需要将这些层设置到预测模式,model.eval()就是帮我们一键搞定的,如果在预测的时候忘记使用model.eval(),会导致不一致的预测结果。
-
# 保存模型 torch.save(model.state_dict(), PATH) # 加载模型 model = model.load_state_dict(torch.load(PATH)) model.eval()
-
-
-
模型预测
-
认识state_dict
-
state_dict是Python格式的字典数据
-
只保存各层的参数相关信息
-
可以通过model跟optimizer获取
-
保存检查点
-
# 保存检查点 torch.save({ 'epoch': epoch, 'model_state_dict': model.state_dict(), 'optimizer_state_dict': optimizer.state_dict(), 'loss': loss, ... }, PATH) # 恢复检查点 model = TheModelClass(*args, **kwargs) optimizer = TheOptimizerClass(*args, **kwargs) checkpoint = torch.load(PATH) model.load_state_dict(checkpoint['model_state_dict']) optimizer.load_state_dict(checkpoint['optimizer_state_dict']) epoch = checkpoint['epoch'] loss = checkpoint['loss'] model.eval() # - or - model.train()
-
-
恢复/推理
-
import cv2 as cv import numpy # 推理 model = model.load_state_dict(torch.load("./nn_mnist_model.pt")) model.eval() input = cv.imread("D:/images/9.png", cv.IMREAD_GRAYSCALE) cv.imshow("input", input) img_f = numpy.float32(input) img_f = (img_f/255.0-0.5)/0.5 img_f = numpy.reshape(img_f, (1, 784)) pred_label = model(torch.from_numpy(img_f)) pred = torch.exp(pred_label) res = list(pred.detach().numpy()[0]) label = res.index(max(res)) print("predict digit number: ", label) cv.waitKey(0) cv.destroyAllWindows()
-
-
卷积神经网络
卷积的基本概念与术语
-
卷积的基本概念
-
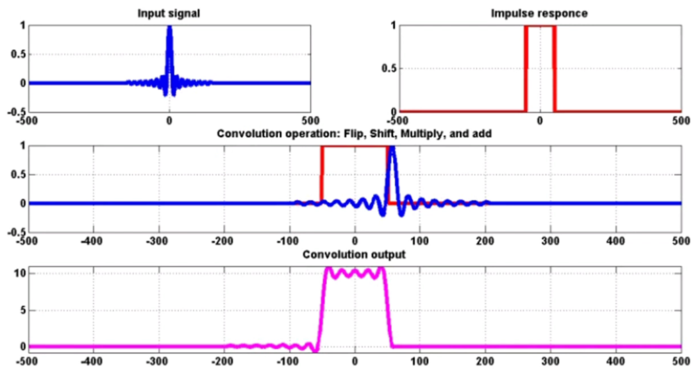
什么是卷积(输入 + 脉冲 = 输出)
-
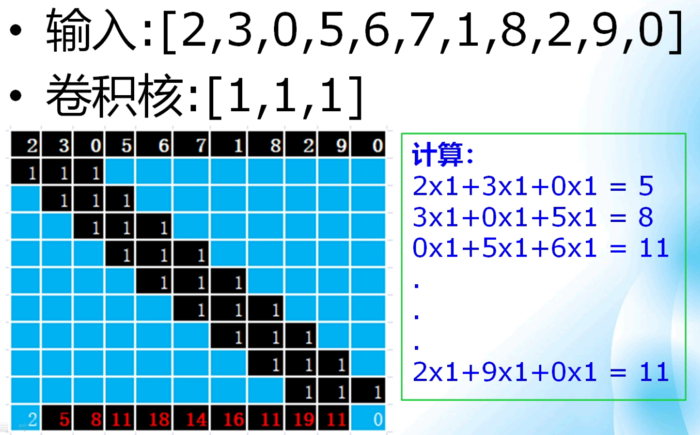
一维离散卷积
-
-
基本图像卷积
-
基本图像卷积,与之前写的OpenCV中的内容完全一样
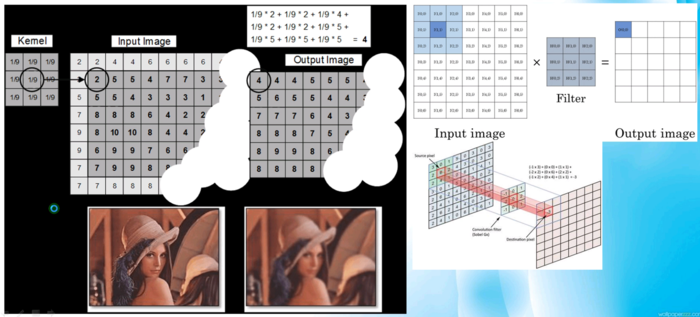
-
卷积操作相关的专业术语
- 卷积核/操作数/filter(一样的kernel,不同叫法)
- 卷积的锚定位置(默认中心位置)
- 卷积的边缘填充方式 valid/same
-
-
边缘处理
- full(卷积后周边增加像素)/same(卷积后保持原图大小)/valid(不填充像素直接进行卷积运算)

- 锚定位置(默认为(-1, -1))

-
Pytorch中的卷积
-
torch.nn.functional.conv2d(2D图像卷积)
-
代码实现
import cv2 as cv import torch import torch.nn.functional as F # 导入torch.nn中的functional模块进行卷积运算 import numpy input_img = cv.imread("D:/images/lena.jpg", cv.IMREAD_GRAYSCALE) # 以灰度图模式读取图像并显示 cv.imshow("input", input_img) h, w = input_img.shape # 获取输入图像的宽高信息(注意:此处shape不加括号,不是方法) img = numpy.reshape(input_img, (1, 1, h, w)) # 使用numpy转换输入图像为四个维度并转换为浮点型 img = numpy.float32(img) # 自定义7 * 7大小的浮点卷积核,因为求取的是49个像素的计算后累加和,因此再除以49.0将结果值转换到0-255范围内 k = torch.ones((1, 1, 7, 7), dtype=torch.float) / 49.0 res = F.conv2d(torch.from_numpy(img), k, padding=3) # 卷积运算输入tensor格式数据,边缘填充3个像素 out = numpy.reshape(res.numpy(), (h, w)) # 将结果转换为原图大小的numpy数组,并转换为整数类型 cv.imshow("result", numpy.uint8(out)) cv.waitKey(0) cv.destroyAllWindows() -
效果:
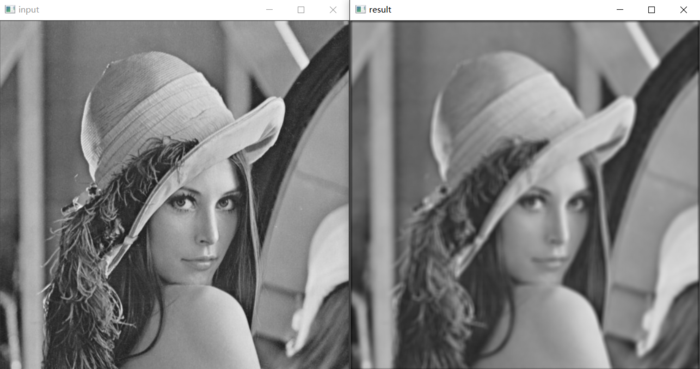
-
卷积神经网络基本原理与参数
-
卷积神经网络(CNN)基本原理
-
卷积神经网络的好处:共享权重、像素迁移、空间信息提取
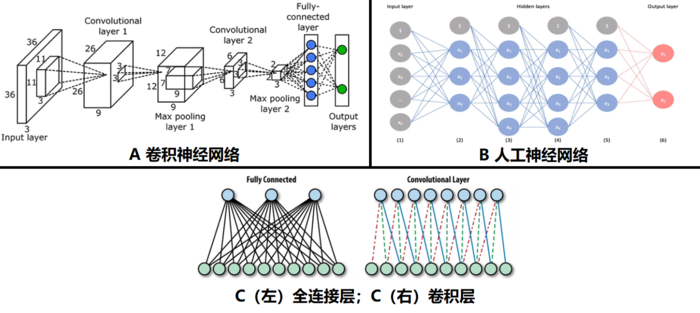
-
-
CNN中的层与参数
- 卷积层,提取图像特征
- 池化层,降低网络参数数量(layer增加,抵消降采样带来的空间和信息损失)
-
卷积层与池化层
-
卷积层操作:
-
步长 stride = 1;填充 VALID;卷积核 filter size = 3 * 3
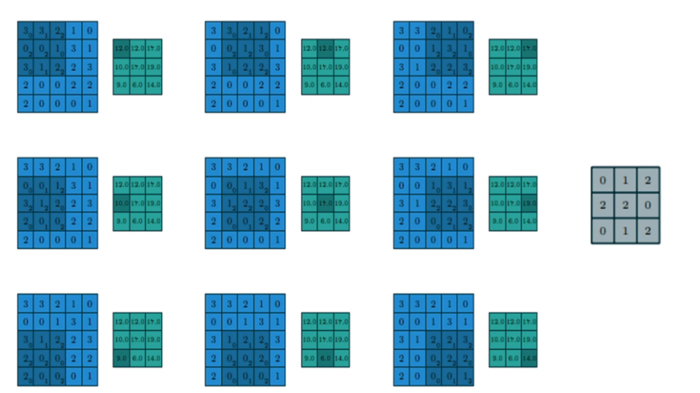
-
步长 stride = 2;填充 SAME;卷积核 filter size = 3 * 3
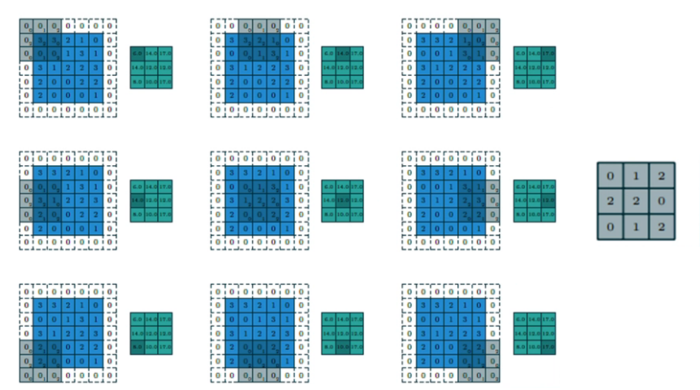
-
-
卷积层输出大小
-
W * W的feature map
-
Filter的大小为F * F
-
卷积时填充边缘P个像素
-
卷积步长(stride)为S
-
则输出的大小为:
[输出大小, =, frac {W, -, F, +, 2P} {S}, +, 1
]
-
-
卷积层详解
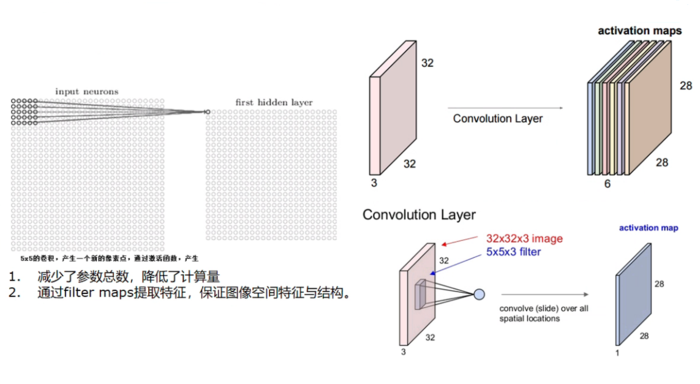
-
池化层详解
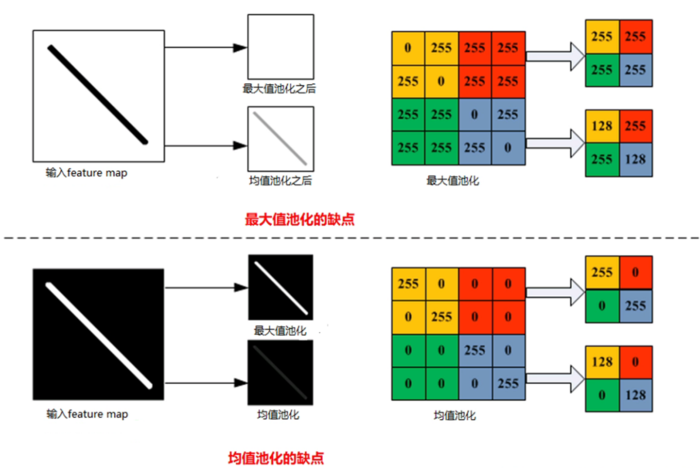
- 重叠池化
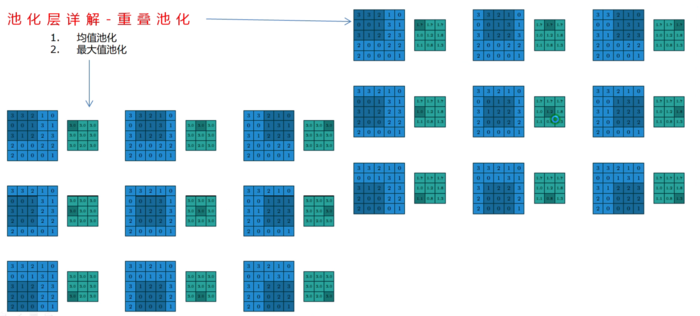
- 局部池化
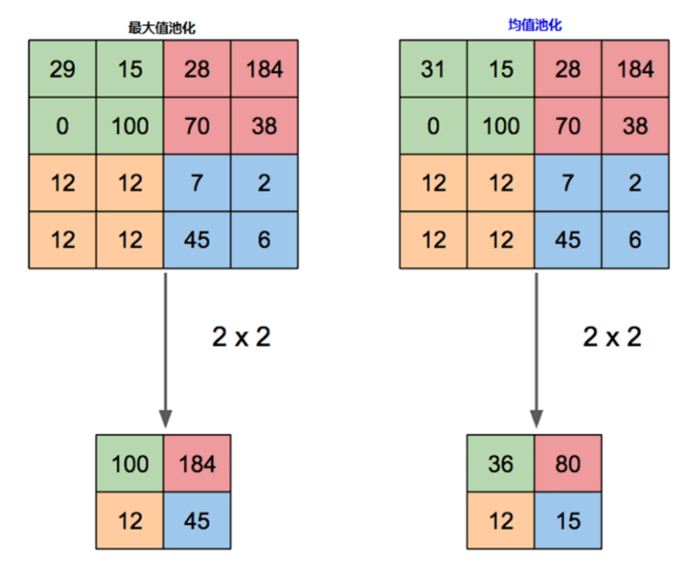
- 最大值池化与均值池化对比
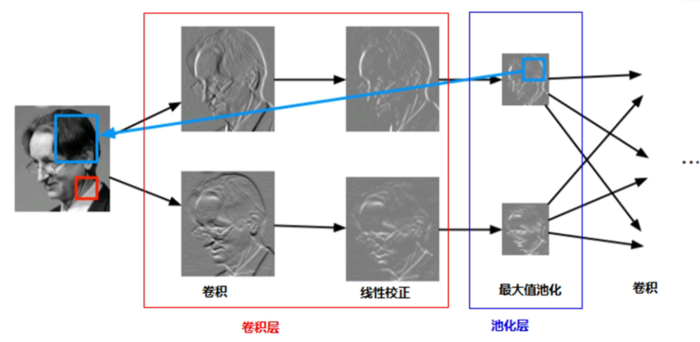
- 卷积层特点
- 局部感受野
- 权重共享机制
- 池化下采样操作
- 获取了图像的迁移、形变与尺度空间不变性特征
-
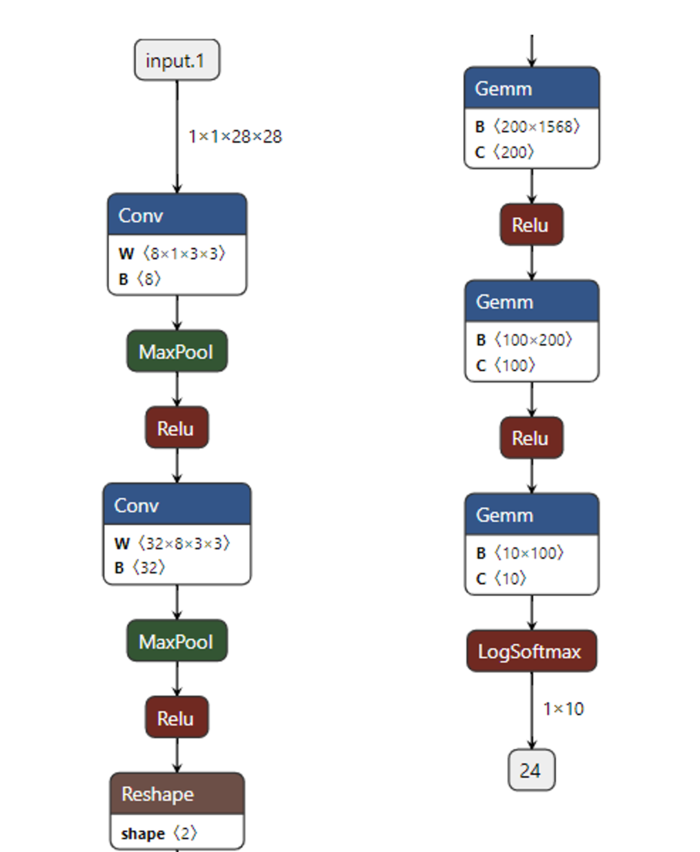
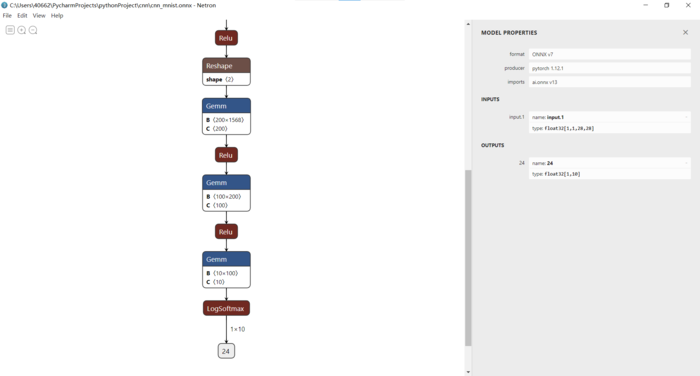
卷积神经网络构建、训练与预测使用
- CNN手写数字识别网络结构:
- 卷积层 + 池化层
- 全连接层
- 输出层
使用Netron查看网络结构
代码实现
import torch
import torchvision
import numpy
from torch.utils.data import DataLoader
transformers = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.5, ), (0.5, ))])
train_ts = torchvision.datasets.MNIST(root='./data', train=True, transform=transformers, download=True)
test_ts = torchvision.datasets.MNIST(root='./data', train=False, transform=transformers, download=True)
train_dl = DataLoader(train_ts, batch_size=64, shuffle=True, drop_last=False)
test_dl = DataLoader(test_ts, batch_size=32, shuffle=True, drop_last=False)
class CNN_Mnist(torch.nn.Module):
def __init__(self):
super(CNN_Mnist, self).__init__()
self.cnn_layers = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=1, out_channels=8, kernel_size=3, stride=1, padding=1),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=8, out_channels=32, kernel_size=3, stride=1, padding=1),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
torch.nn.ReLU()
)
self.fc_layers = torch.nn.Sequential(
torch.nn.Linear(7*7*32, 200),
torch.nn.ReLU(),
torch.nn.Linear(200, 100),
torch.nn.ReLU(),
torch.nn.Linear(100, 10),
torch.nn.LogSoftmax(dim=1)
)
def forward(self, x):
out = self.cnn_layers(x)
out = out.view(-1, 7*7*32)
out = self.fc_layers(out)
return out
model = CNN_Mnist().cuda()
print("Model's state_dict: ")
for param_tensor in model.state_dict():
print(param_tensor, "t", model.state_dict()[param_tensor].size())
loss = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
for s in range(5):
print("run in epoch : %d"%s)
for i, (x_train, y_train) in enumerate(train_dl):
x_train = x_train.cuda()
y_train = y_train.cuda()
y_pred = model.forward(x_train)
train_loss = loss(y_pred, y_train)
if (i + 1) % 100 == 0: # 每循环100次输出依次当前loss数据
print(i + 1, train_loss.item())
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
torch.save(model.state_dict(), './cnn_mnist_model.pt')
model.eval()
total = 0
correct_count = 0
for test_images, test_labels in test_dl:
pred_labels = model(test_images.cuda())
predicted = torch.max(pred_labels, 1)[1]
correct_count += (predicted == test_labels.cuda()).sum()
total += len(test_labels)
print("total acc : %.2fn"%(correct_count / total))
ONNX(Open Neural Network Exchange)格式模型导出与推理
代码实现
import cv2 as cv
import numpy
import pyttsx3
# 推理
model = cv.dnn.readNetFromONNX("./cnn_mnist_model.onnx")
input = cv.imread("D:/images/9.png", cv.IMREAD_GRAYSCALE)
cv.imshow("input", input)
# 转换为(1, 1, 28, 28)
blob = cv.dnn.blobFromImage(input, 0.00392, (28, 28), (127.0)) / 0.5 # 缩放比例,尺寸,减去的值
model.setInput(blob)
result = model.forward()
pred_label = numpy.argmax(result, 1) # 获取最大概率的索引
print("predict label : %d"%pred_label)
engine = pyttsx3.init() # 语音播报预测结果
engine.say(str(pred_label))
engine.runAndWait()
cv.waitKey(0)
cv.destroyAllWindows()
Pytorch数据集与训练可视化
Pytorch中的数据与数据集类
-
Pytorch的数据集类
-
Pytorch数据类torch.util.data包
-
Dataset数据抽象类
-
支持Map-style与Iterable-style
-
Map-style完成方法:
- _ _ getitem() _ _
- _ _ len() _ _
-
访问 dataset[idx] 其中 idx 表示索引
-
DataLoader
- 支持加载 Map-style 与 Iterable-style数据
- 自定义数据集加载
- 自动batch提取
- 单个或者多个数据加载
- 自动内存固定
-
DataLoader函数解释
torch.utils.data.DataLoader( dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None, generator=None, * , prefetch_factor=2, persistent_workers=False )import torch import numpy as np from torch.utils.data import Dataset, DataLoader from torchvision import transforms, utils import cv2 as cv class FaceLandmarksDataset(Dataset): def __init__(self, txt_file): self.transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]), transforms.Resize((64, 64)) ]) lines = [] with open(txt_file) as read_file: for line in read_file: # 逐行遍历并添加到lines数组中 line = line.replace('n', '') lines.append(line) self.landmarks_frame = lines def __len__(self): return len(self.landmarks_frame) def num_of_samples(self): return len(self.landmarks_frame) def __getitem__(self, idx): if torch.is_tensor(idx): idx = idx.tolist() contents = self.landmarks_frame[idx].split('t') image_path = contents[0] img = cv.imread(image_path) # BGR order h, w, c = img.shape # rescale # img = cv.resize(img, (64, 64)) # img = (np.float32(img) /255.0 - 0.5) / 0.5 landmarks = np.zeros(10, dtype=np.float32) for i in range(1, len(contents), 2): landmarks[i - 1] = np.float32(contents[i]) / w # w与h转换为0~1 landmarks[i] = np.float32(contents[i + 1]) / h landmarks = landmarks.astype('float32').reshape(-1, 2) # 矩阵大小转换为5行2列 # H, W C to C, H, W # img = img.transpose((2, 0, 1)) sample = {'image': self.transform(img), 'landmarks': torch.from_numpy(landmarks)} # 图像与其对应的标注信息 return sample if __name__ == "__main__": ds = FaceLandmarksDataset("D:/facedb/Face-Annotation-Tool/landmark_output.txt") for i in range(len(ds)): sample = ds[i] print(i, sample['image'].size(), sample['landmarks'].size()) if i == 3: break dataloader = DataLoader(ds, batch_size=4, shuffle=True) # data loader for i_batch, sample_batched in enumerate(dataloader): print(i_batch, sample_batched['image'].size(), sample_batched['landmarks'].size()) -
数据集预处理
- torchvision.transform数据预处理
- ToTensor转换为tensor数据取值0~1
代码实现:
import torch import cv2 as cv import torchvision.transforms as tf torch.manual_seed(17) transforms = torch.nn.Sequential( tf.Grayscale() ) scripted_transforms = torch.jit.script(transforms) c_transforms = tf.Compose([ tf.ToTensor(), tf.Normalize(mean=[0.485, 0.456, 0.406], # 转换为0~1,再减去均值mean,除以方差std std=[0.229, 0.224, 0.225]) ]) image = cv.imread("D:/images/lena.jpg") cv.imshow("input", image) # im_data = image.transpose((2, 0, 1)) # result = scripted_transforms(torch.from_numpy(numpy.float32(im_data)/255.0)) # 转换为灰度图 result = c_transforms(image) print(result.shape) result = result.numpy().transpose(1, 2, 0) # 对通道进行转置 cv.imshow("result", result) cv.waitKey(0) cv.destroyAllWindows()效果:
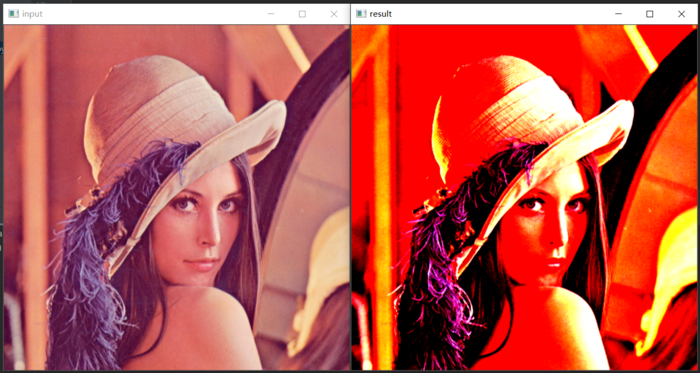
-
-
Landmark数据集标注
-
自定义图像数据集类
Pytorch训练可视化
Tensorboard可视化
-
来自tensorflow,torch.utils.tensorboard
-
启动与访问:http://localhost:6006
-
pip install tensorboard
-
from torch.utils.tensorboard import SummaryWriter
-
tensorboard --logdir=D:/python/experiment_01
-
标量与图像保存
-
writer.add_image(), writer.add_graph(), writer.add_scalar()
代码实现
import torch as t
from torch.utils.data import DataLoader
import torchvision as tv
from torch.utils.tensorboard import SummaryWriter
transform = tv.transforms.Compose([tv.transforms.ToTensor(),
tv.transforms.Normalize((0.5,), (0.5,)),
])
train_ts = tv.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_ts = tv.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
train_dl = DataLoader(train_ts, batch_size=32, shuffle=True, drop_last=False)
test_dl = DataLoader(test_ts, batch_size=64, shuffle=True, drop_last=False)
writer = SummaryWriter('D:/python/experiment_01') # 数据保存路径
# get some random training images
dataiter = iter(train_dl) # 将数据集中若干图片展示在tensorboard中
images, labels = dataiter.next()
# create grid of images
img_grid = tv.utils.make_grid(images) # make_grid的作用是将若干幅图像拼成一幅图像。其中padding的作用就是子图像与子图像之间的pad有多宽
# write to tensorboard
writer.add_image('four_fashion_mnist_images', img_grid)
class CNN_Mnist(t.nn.Module):
def __init__(self):
super(CNN_Mnist, self).__init__()
self.cnn_layers = t.nn.Sequential(
t.nn.Conv2d(in_channels=1, out_channels=8, kernel_size=3, padding=1, stride=1),
t.nn.MaxPool2d(kernel_size=2, stride=2),
t.nn.ReLU(),
t.nn.Conv2d(in_channels=8, out_channels=32, kernel_size=3, padding=1, stride=1),
t.nn.MaxPool2d(kernel_size=2, stride=2),
t.nn.ReLU()
)
self.fc_layers = t.nn.Sequential(
t.nn.Linear(7*7*32, 200),
t.nn.ReLU(),
t.nn.Linear(200, 100),
t.nn.ReLU(),
t.nn.Linear(100, 10),
t.nn.LogSoftmax(dim=1)
)
def forward(self, x):
out = self.cnn_layers(x)
out = out.view(-1, 7*7*32)
out = self.fc_layers(out)
return out
def train_and_test():
model = CNN_Mnist().cuda()
print("Model's state_dict:")
for param_tensor in model.state_dict():
print(param_tensor, "t", model.state_dict()[param_tensor].size())
loss = t.nn.CrossEntropyLoss()
optimizer = t.optim.Adam(model.parameters(), lr=1e-3)
writer.add_graph(model, images.cuda())
total = 0
correct_count = 0
for s in range(5):
m_loss = 0.0
print("run in epoch : %d" % s)
for i, (x_train, y_train) in enumerate(train_dl):
x_train = x_train.cuda()
y_train = y_train.cuda()
y_pred = model.forward(x_train)
train_loss = loss(y_pred, y_train)
m_loss += train_loss.item()
if (i + 1) % 100 == 0:
print(i + 1, train_loss.item())
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
writer.add_scalar('training/loss',
m_loss / 1000,
s * len(train_dl) + i)
count = 0
for test_images, test_labels in test_dl:
pred_labels = model(test_images.cuda())
predicted = t.max(pred_labels, 1)[1]
correct_count += (predicted == test_labels.cuda()).sum()
total += len(test_labels)
count += 1
writer.add_scalar('training/accuracy',
correct_count / total,
s * len(test_dl) + count)
t.save(model.state_dict(), './cnn_mnist_model_vis.pt')
model.eval()
total = 0
correct_count = 0
count = 0
for test_images, test_labels in test_dl:
pred_labels = model(test_images.cuda())
predicted = t.max(pred_labels, 1)[1]
correct_count += (predicted == test_labels.cuda()).sum()
total += len(test_labels)
writer.add_scalar('test/accuracy',
correct_count / total,
count)
count += 1
print("total acc : %.2fn"%(correct_count / total))
writer.close() # 使用完要关闭writer()
if __name__ == "__main__":
train_and_test()
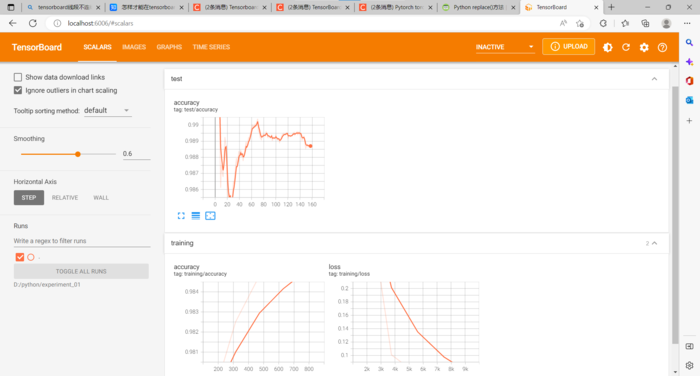
效果:
Visdom可视化
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:Pytorch框架详解之一 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 