随着 Kubernetes 作为 AI、大数据和高性能批量计算的下一代基础设施的趋势逐渐清晰,越来越多的企业对 Kubernetes 在深度学习、科学计算、高性能渲染等方面提出了更高的要求。
项目挑战
原生 Kubernetes 作为通用的容器调度方案,仍与高性能计算场景下业务调度诉求存在一定差距,主要体现在:
待完善作业视角调度能力
Kubernetes 本身是以资源视角进行资源调度,Pod 作为基本的调度单元存在。Kubernetes 采用依次调度的方式实现对每个容器的调度管理,缺乏业务的作业视角进行调度的能力。
在大数据、人工智能、高性能计算的应用场景下,往往需要多个容器同时配合执行计算。而 Kubernetes 原生的依次调度方式,完全无法满足大数据、人工智能场景下的调度需求。
例如,某个大数据应用需要跑1个 Driver 容器+10个 Executor 容器。如果容器以顺序的方式一个一个进行调度,在启动最后一个 Executor 容器时,由于资源不足而调度失败,最终造成服务无法启动。虽然,前面创建好的9个 Executor 容器运行正常,但平台无法提供该大数据应用的正常服务,从资源占用上来看也是一种浪费情况。
或者,当同时提交多个作业任务后,可能会因为资源不足而造成死锁,进而导致集群实际资源被占满,最终造成所有作业任务都无法运行的最坏情况。
待实现 GPU 资源共享切分
由于开源的 Kubernetes 本身对 GPU 提供的管理能力比较弱,无法实现 GPU共享按需调度的能力要求。
-
每个容器可以请求一个或多个 GPU,不支持 GPU 的资源切分
-
K8S 节点必须预装相应的驱动程序
-
必须预装 nvidia-docker 程序
在容器中,要想调用 NVIDIA 的 GPU ,需要通过 nvidia-docker 调用。nvidia-docker 是一个可以使用 GPU 的 docker,它在 docker 上做了一层封装,通过 nvidia - docker - plugin 将 GPU 调用到 docker 上。
从 K8S 1.8版本后,推荐使用 Device - Plugins 方式来调用 GPU 。
待增加大数据等场景基因
Kubernetes 的核心工作负载面向无状态应用、微服务应用等互联网类应用进行设计,对水平伸缩、滚动升级有支持比较好。而到了大数据和高性能计算领域,想直接使用 Kubernetes 完成相应的作业和任务是非常困难。
待完善传统方案资源隔离性
随着 Hadoop 生态崛起后,在资源的隔离方面 Yarn 就开始使用 cgroup 用来实现对 CPU 资源隔离管理,借助 JVM 的内存隔离机制从而实现对内存资源隔离管理;对于磁盘 IO 和网络 IO 的隔离,目前社区还在讨论中;对于文件系统环境的隔离,始终也无法做到完整的文件系统隔离方案。
从整体上看,Yarn 的资源隔离能力比较弱,这就造成了当多个任务运行到同一个工作节点上时,不同任务之间会存在资源抢占的问题,不同任务之间相互影响。
待增强弹性 按需扩容
大数据应用的高峰往往有明显的周期性特征。例如,实时计算资源消耗主要在白天。但大数据资源管理平台普遍缺乏弹性管理能力,无法按应用所需进行快速扩容,为了应对业务高峰和突发的计算任务,只能通过预留出足够多的资源方式来保证作业任务能够正常运行。
解决方案
从2020年开始,越来越多的大数据、高性能计算等业务开始往 K8S 迁移。博云智能算力引擎,通过引入组调度、公平调度等方式,实现了面向作业进行调度,解决原生 K8S 调度器面向 Pod 调度的问题;通过引入CNCF批量计算项目volcano,实现大数据生态作业、队列管理能力;通过引入博云容器云平台,实现了 GPU 调度能力、资源隔离和资源抽象化供给能力。从而,进一步加强容器作为资源平台的能力形成,为大数据、人工智能、高性能计算等场景提高算力服务做好了准备。
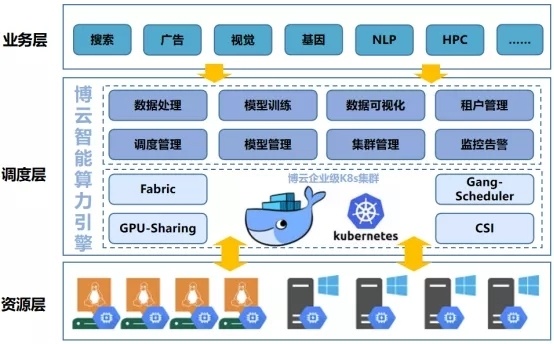
博云智能算力引擎整体由三部分组成:
-
业务层:由业务软件来调用博云智能算力引擎的接口,达到作业任务的批量计算和编排调度的管理要求;
-
调度层:由博云智能算力引擎来提供整体的调度、运算等服务能力;
-
资源层:由大量物理机或虚拟机为博云的企业级 K8S 集群提供为计算赋能。
实现灵活的作业调度算法
基于以下原则对作业进行排队,提升整个集群的资源利用率和作业吞吐量。
-
集群资源使用情况
-
作业提交时间
-
作业资源申请量
-
作业优先级
-
作业排他性
-
作业防饿死
实现 GPU 多维调度能力
平台实现了 GPU 的统一管理、多维隔离、资源共享等调度能力。支持多个节点可以配置不同数量、不同类型的 GPU 卡,实现统一 GPU 卡管理;支持租户或namespace 级别的 GPU 资源隔离,支持按照 GPU 卡类型进行隔离;支持多个业务共享 GPU 卡,支持 GPU 显存隔离,提升 GPU 卡资源利用率。
实现基于 MPI 类型作业
一般一个运行的 MPI 作业,由 master/worker 两部分组成,master 负责启动 mpirun 命令,worker 负责执行真正的计算作业。
平台通过对多个 pod 模板定义设置,实现分别对应 master/worker 的定义。借助 gang scheduling,保证作业中的所有 pod 能够同时启动,已实现作业的管理。支持作业生命周期管理功能,当 mpirun 结束时,结束整个任务。
实现基于 Spark 框架作业
自 Spark 2.3版本开始,原生支持在 Kubernetes 中部署。
借助容器的优势,将运行时打包进镜像中,可以加快分发速度并提升可移植性。借助 Kubernetes 的优势,能够实现容器化应用的快速部署、弹性扩容、性能监控、日志收集等管理功能。
实现队列和优先级抢占
将整个集群的资源分配到不同的队列中,让不同的用户可以按需配置使用不同的队列。当某队列中资源空闲时,可以提供给另一个队列中的作业使用。
当同时运行的作业众多时,平台可以实现高优先级的作业可以抢占低优先级的作业资源,从而实现提前调度管理。同时,平台也能够避免低优先的任务“饿死”,长时间得不到运行。
实现高性能的容器网络
大数据、超算等场景下,需要在短时间启动数以千计的计算实例并运行,这就对容器网络性能提出了更高的要求。
博云自研的 BeyondFabric 网络方案,经历了5个版本的迭代,已经在众多客户生产环境中稳定运行。目前,BeyondFabric 网络方案已实现对计算业务中的启动时间、网络带宽、网络就绪时间等指标的高性能支撑。
同时,BeyondFabric 网络能够为 Windows 系统提供更优秀的容器网络性能。
实现用户资源深度隔离
在租户层面,平台提供多租户共享底层物理资源(计算、存储、网络),做到不同租户的应用、数据、虚拟网络的隔离,对于租户自有的应用,租户可以自由选择隔离或者打通。
在资源层面,Docker 在一台 Linux 上启动多个在独立沙箱内运作的应用,相互不影响。对不同容器的 CPU、内存、网络、存储、进程等进行隔离。
实现资源弹性按需扩容
弹性伸缩是容器云的一个重要特性,也是实施容器云的一个重要业务场景。借助容器云的弹性能力,实现业务高峰时的资源快速扩容,避免为应对业务高峰预留过多的资源。
应用场景
HPC 高性能计算作为传统分布式计算模式的代表,在工业仿真、视觉渲染、气象环境、石油勘探、科研课题等诸多领域依然有着广泛的应用。
随着云原生技术的爆发,Kubernetes 作为云原生应用编排、管理的工具, 被越来越多的应用所接受和选择。众多用户开始希望能将 HPC 应用迁移到容器中运行,通过 Kubernetes 强大的功能来进行作业管理。
工业仿真
某用户有大量基于 Windows 的 HPC 应用,在迁移到容器环境之前,经常遇到资源占用高,作业没有隔离,维护需要后台手动操作等情况。
伴随 HPC 应用迁移到容器云后,平台通过优化作业任务,实现缩短计算时长;平台提供健全资源隔离,降低了不同部门因提交作业所造成的数据安全风险,大大提升了运行效率。实现了单次作业提交创建实例数从原来的 300+,提升到现在 1000+,使用内存资源约 15-20T 的规模。
视觉渲染
用户当前渲染业务还是以单机服务为主,现有软件对批量计算作业调度不够灵活,对集群控制能力也比较差,作业配置、创建、释放还都是以手工操作为主。
通过对业务的容器化改造,实现资源高性能调度、秒级弹性伸缩、GPU 统一管理等能力,轻松应对大规模的渲染需求。
方案优势
博云智能算力引擎解决方案,基于容器技术实现了高性能计算场景的统一调度管理平台,方案为上层各类超算业务提供了大数据、人工智能及云原生作业编排等技术服务。该方案具有如下技术优势:

统一的资源管理
-
支持 Linux/Windows 计算资源池
-
支持 GPU 计算
-
支持批次、节点组管理
-
提升资源利用率
灵活的调度机制
-
支持 gang-scheduling 机制
-
支持主流的调度算法
-
支持作业防饿死、排他性等机制
-
提升作业吞吐率
高效的作业提交
-
支持 HPC、大数据、人工智能等作业
-
支持 MPI、TensorFlow 快捷提交
-
通过 DAG 模式支持 ETL 等常规作业
-
作业以容器运行,提升作业隔离性
多样的排队策略
-
多队列管理,支持资源抢占
-
支持设置优先级
-
支持队列可视化
全面的数据可视
-
对接 S3 等存储系统
-
实时在线查看数据
集中的日志告警
-
在线查看作业日志
-
在线查看作业监控数据
-
在线配置告警规则
完善的租户体系
-
划分租户资源
-
租户数据隔离
-
操作权限审计
兼容全信创生态
-
支持 X86、海光、ARM 平台
-
支持中标麒麟、统信等操作系统
-
已获取主流认证证书
总结
通过容器化技术,博云智能算力引擎解决方案充分利用容器化技术,使大数据、人工智能、高性能计算等场景在容器化技术的应用下,进一步提升了资源使用效率和降低运维管理复杂性,使云原生技术价值得到进一步释放,支撑高性能等计算场景下的企业完成数字化转型。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:支持高性能计算场景,博云容器云打造智能算力引擎 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 