摘要:本文介绍了一种MATLAB实现的目标检测系统代码,采用 YOLOv4 检测网络作为核心模型,用于训练和检测各种任务下的目标,并在GUI界面中对各种目标检测结果可视化。文章详细介绍了YOLOv4的实现过程,包括算法原理、MATLAB 实现代码、训练数据集、训练过程和图形用户界面。在GUI界面中,用户可以选择各种图片、视频、摄像头进行检测识别,可更换检测模型。本文提供了完整的 MATLAB 代码和使用教程,适合新入门的朋友参考。完整代码资源文件请参见文末的下载链接。
完整代码下载:https://mbd.pub/o/bread/ZJiYm51v
参考视频演示:https://www.bilibili.com/video/BV15a4y1G7yJ/
1. 引言
十年前博主在初学人工智能时,经常发现网上可供参考的高质量的完整教程或博客很少,要实现一个复杂点的代码基本无从参考,自己很多时候都是在瞎摸索。撰写这篇博客的初衷是为了分享技术知识,为初学者提供启发,我希望通过博客的实例和解释,激发读者的兴趣和热情,帮助他们更好地理解和应用相关技术。正所谓“博学而笃志,切问而近思”,也希望读者在阅读博客的过程中,不要停止思考,在掌握基本原理和技术之后,尝试自己解决问题,提出新的观点和想法。在学习的过程中,可能会遇到挑战和困难,一个Bug的解决或许正是提高技能、拓展知识边界的时机。本博客内容为博主原创,相关引用和参考文献我已在文中标注,考虑到可能会有相关专业人员看到,博主的博客这里尽可能以学术期刊的格式撰写,如需参考可引用本博客格式如下:
[1] 思绪无限. 基于YOLOv4的目标检测系统(附MATLAB代码+GUI实现)[J/OL]. CSDN, 2023.05. https://wuxian.blog.csdn.net/article/details/130470598.
[2] Wu, S. (2023, May). Object Detection System Based on YOLOv4 (with MATLAB Code and GUI Implementation) [J/OL]. CSDN. https://wuxian.blog.csdn.net/article/details/130470598.
目标检测作为计算机视觉领域的一个重要研究方向,旨在从图像或视频中识别和定位特定类别的物体(Redmon et al., 2016)[1]。在过去的几年里,随着深度学习技术的发展,基于卷积神经网络(CNN)的目标检测方法取得了显著的进步。一些经典的目标检测方法包括R-CNN(Girshick et al., 2014)[2]、Fast R-CNN(Girshick, 2015)[3]、Faster R-CNN(Ren et al., 2015)[4]、SSD(Liu et al., 2016)[5]和RetinaNet(Lin et al., 2017)[6]。这些方法在各种基准数据集上取得了不俗的成绩,如PASCAL VOC(Everingham et al., 2010)[7]、COCO(Lin et al., 2014)[8]和ImageNet(Russakovsky et al., 2015)[9]。YOLO系列算法(Redmon et al., 2016; Redmon & Farhadi, 2017; Redmon & Farhadi, 2018; Bochkovskiy et al., 2020)[1, 10-12]相较于其他方法,更注重检测速度和实时性,因此在许多实际应用场景中具有较大优势。
尽管上述方法在目标检测领域取得了显著成果,但每种方法都存在一定的局限性。例如,R-CNN系列方法在检测精度上表现优异,但计算复杂度较高,导致检测速度较慢(Girshick et al., 2014; Girshick, 2015; Ren et al., 2015)[2-4]。相比之下,SSD和RetinaNet等一阶段检测方法在检测速度上有所改进,但精度相对较低(Liu et al., 2016; Lin et al., 2017)[5, 6]。YOLO系列算法在检测速度和精度之间取得了较好的平衡(Redmon et al., 2016; Redmon & Farhadi, 2017; Redmon & Farhadi, 2018; Bochkovskiy et al., 2020)[1, 10-12]。尤其是YOLOv4算法,凭借其较高的检测精度和速度成为了目标检测领域的一种重要方法(Bochkovskiy et al., 2020)[12]。
目前,许多研究者和工程师已经成功地将YOLOv4应用于各种实际场景,如无人驾驶(Geiger et al., 2012)[13]、视频监控(Sindhu et al., 2021)[14]、医学影像(Shewajo et al., 2023)[15]等。然而,尽管YOLOv4在目标检测任务中取得了令人瞩目的成果,但在MATLAB环境中实现YOLOv4的相关研究仍相对较少(MathWorks, 2021)[16]。基于MATLAB实现YOLOv4目标检测系统具有较强的实用性,可以为计算机视觉和图像处理领域的研究人员和工程师提供便捷的开发和调试工具。因此,本博客的主要贡献点如下:
- 提供一个基于MATLAB实现的YOLOv4目标检测系统,该系统具有用户友好的界面,支持多种检测模式,如图片检测、批量检测、视频检测和实时摄像头检测;
- 详细介绍在MATLAB环境中准备YOLOv4模型训练所需的数据集格式,以及给出一个自定义动物识别数据集的实例;
- 提供YOLOv4模型的训练代码,并通过训练曲线和模型评估结果展示其性能;
- 结合GUI界面,详细阐述系统的设计框架和实现原理。
2. 系统界面演示效果
为了方便用户进行目标检测,我们基于MATLAB开发了一个具有用户友好界面的YOLOv4目标检测系统。该系统支持以下功能:
(1)选择图片检测:用户可以选择单张图片进行目标检测,系统将识别图片中的物体并在图片上标注出物体的边界框和类别。
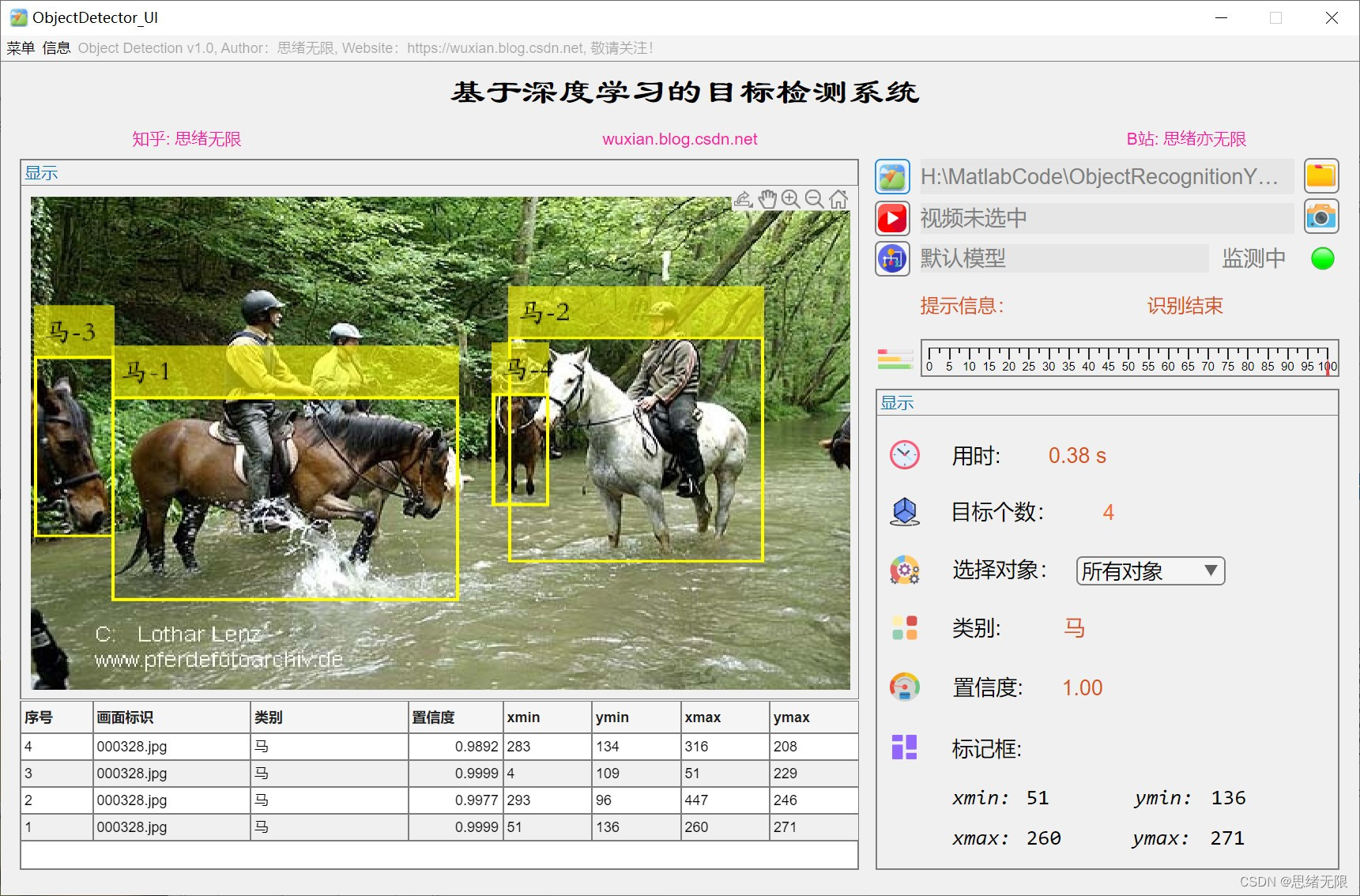

(2)选择文件夹批量检测:用户可以选择一个文件夹进行批量检测,系统将自动识别文件夹中的所有图片,并将检测结果保存到指定的输出文件夹中。
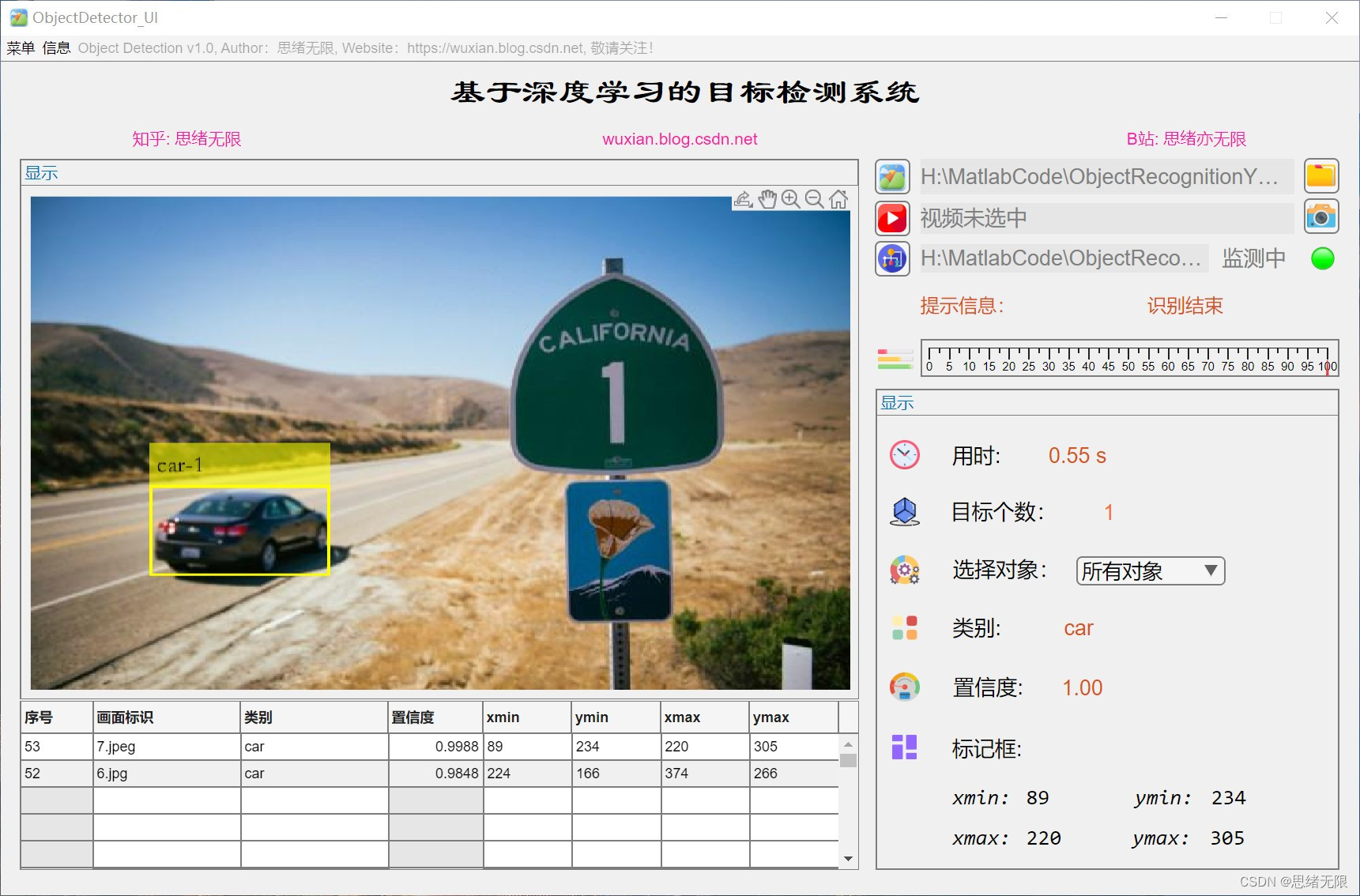
(3)选择视频检测:用户可以选择一个视频文件进行目标检测,系统将实时识别视频中的物体并在视频画面上标注出物体的边界框和类别。
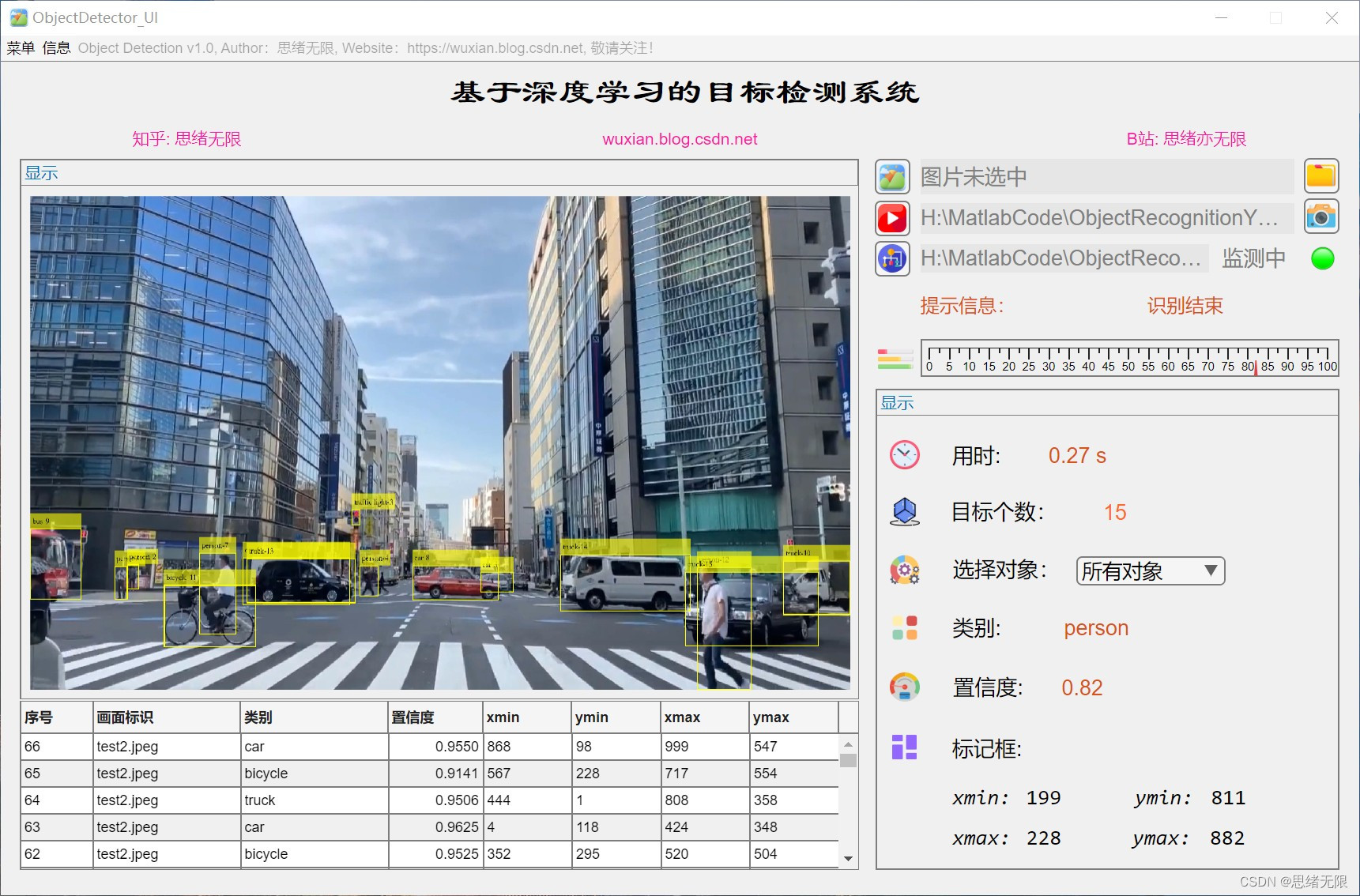
(4)调用摄像头检测:用户可以启用计算机摄像头进行实时目标检测,系统将实时识别摄像头捕捉到的画面中的物体,并在画面上标注出物体的边界框和类别。

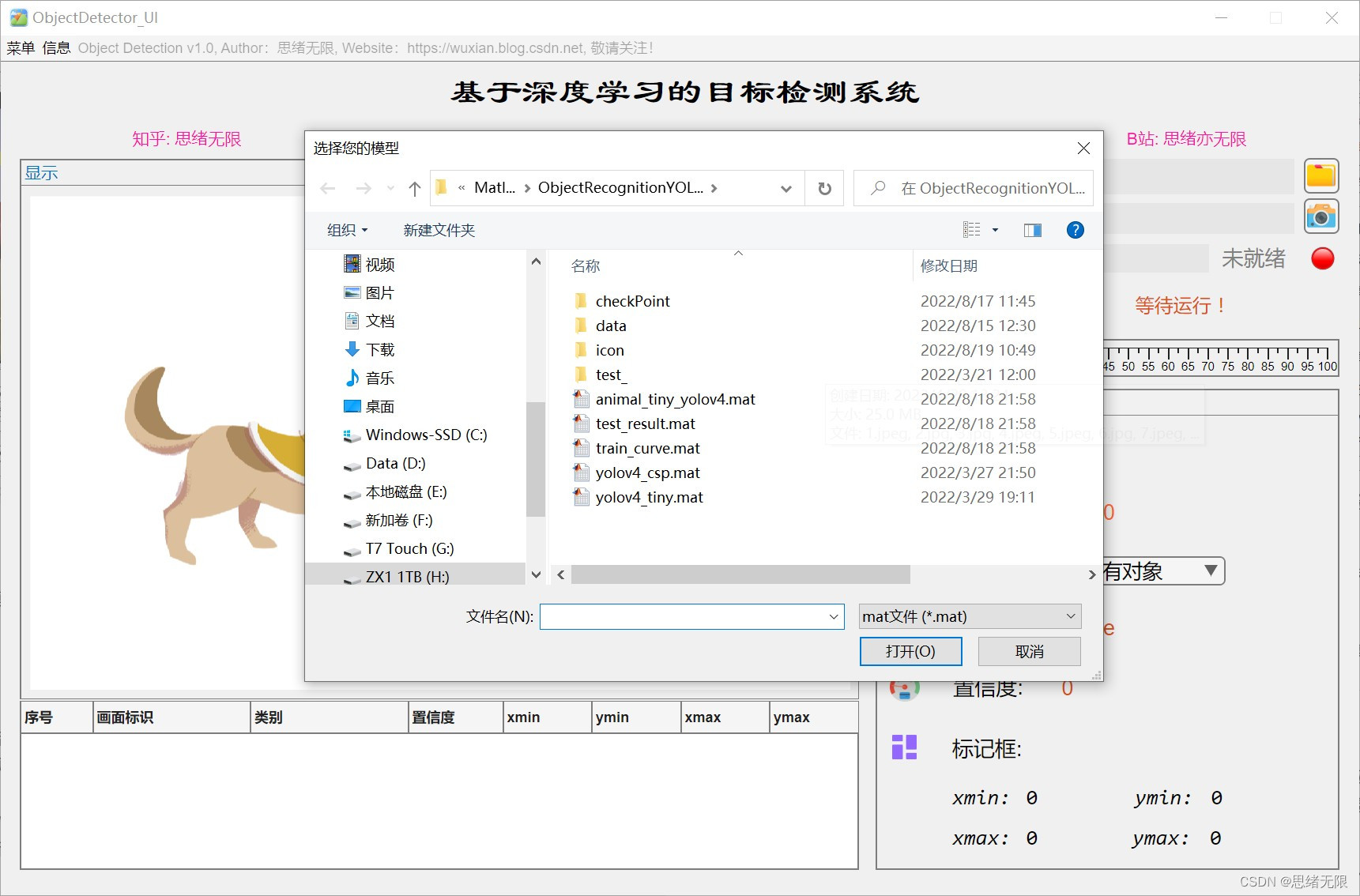
(5)更换不同网络模型:用户可以根据需要选择不同的YOLOv4预训练模型进行目标检测,以适应不同的检测任务和性能要求。
(6)通过界面显示结果和可视化:系统的界面将直观地展示检测结果,包括物体的边界框、类别以及置信度得分。同时,用户可以通过界面查看检测过程的可视化效果,以便更好地了解模型的检测性能。

3. 数据集格式介绍
在MATLAB环境中训练YOLOv4模型,首先需要准备一个合适的数据集。数据集应包含大量标注的图片,以便训练模型学会识别不同类别的物体。本节将详细介绍MATLAB官方支持的YOLOv4模型训练所需的数据集标注文件格式,以及如何创建一个自定义的动物识别数据集作为示例。
在MATLAB中,YOLOv4训练所需的数据集标注信息采用table类型进行存储。每个table的行表示一个样本(即一张图片),每一列对应一个特定的信息。第一列为图片文件的路径,而从第二列开始,每一列对应一个特定类别的标注信息。每个类别的标注信息包括在该类别下的边界框坐标。如果一张图片中有多个边界框属于同一类别,则使用二维数组表示这些边界框。若某类别在图片中没有出现,则用空数组([])表示。
自定义动物识别数据集为例,可以看到数据集的结构如下:

在这个示例中,有6个类别:鸟(bird)、猫(cat)、牛(cow)、狗(dog)、马(horse)和羊(sheep)。每个类别的标注信息包括边界框的左上角坐标(x, y)以及边界框的宽度和高度(w, h)。
4. 模型训练代码
在本节中,将介绍如何使用MATLAB进行YOLOv4模型的训练。我们将使用在前面部分准备好的自定义动物识别数据集。首先,需要加载训练集、验证集和测试集的数据,并添加图像文件的完整路径。以下是加载数据集的MATLAB代码:
% 加载数据集
data = load("data/Animal_dataset_train.mat");
trainData = data.Dataset; % 训练集
data = load("data/Animal_dataset_val.mat");
validData = data.Dataset; % 验证集
data = load("data/Animal_dataset_test.mat");
testData = data.Dataset; % 测试集
% 为数据集添加完整路径
dataDir = fullfile(pwd, 'data');
trainData.imageFilename = fullfile(dataDir, trainData.imageFilename);
validData.imageFilename = fullfile(dataDir, validData.imageFilename);
testData.imageFilename = fullfile(dataDir, testData.imageFilename);
接下来,使用imageDatastore和boxLabelDatastore创建数据存储,以便在训练和评估期间加载图像和标签数据。
% 创建数据存储
imdsTrain = imageDatastore(trainData{:,"imageFilename"});
bldsTrain = boxLabelDatastore(trainData(:, 2:end));
imdsValidation = imageDatastore(validData{:,"imageFilename"});
bldsValidation = boxLabelDatastore(validData(:, 2:end));
imdsTest = imageDatastore(testData{:,"imageFilename"});
bldsTest = boxLabelDatastore(testData(:, 2:end));
% 整合图片和标签
trainingData = combine(imdsTrain, bldsTrain);
validationData = combine(imdsValidation, bldsValidation);
testData = combine(imdsTest, bldsTest);
为了训练YOLOv4模型,需要调整输入图像的大小,并根据锚框数量估计锚框。
inputSize = [320 224 3]; % 输入尺寸
classes = {'bird', 'cat', 'cow', 'dog', 'horse', 'sheep'};
numAnchors = 6;
% 预处理数据
trainingDataForEstimation = transform(trainingData, @(data)preprocessData(data, inputSize));
[anchors, meanIoU] = estimateAnchorBoxes(trainingDataForEstimation, numAnchors);
% 计算每层的锚框
area = anchors(:,1) .* anchors(:,2);
[~, idx] = sort(area, "descend");
anchors = anchors(idx, :);
anchorBoxes = {anchors(1:3, :); anchors(4:6, :)};
接下来使用COCO数据集上训练的预训练YOLOv4检测网络创建YOLOv4对象检测器。在此之前,可以选择性地应用数据增强方法,例如随机水平翻转、随机缩放和颜色变换等。然后,设置训练参数,如学习率、批量大小和最大迭代次数等。
% 使用 COCO 数据集上训练的预训练 YOLO v4 检测网络创建YOLOv4对象检测器
detector = yolov4ObjectDetector("tiny-yolov4-coco",classes,anchorBoxes,InputSize=inputSize);
if flag_augment % 进行数据增强
augmentedTrainingData = transform(trainingData, @augmentData); % 为数据配置增强操作
% 展示增强效果
augmentedData = cell(4,1);
for k = 1:4
data = read(augmentedTrainingData);
augmentedData{k} = insertShape(data{1},"rectangle",data{2});
reset(augmentedTrainingData);
end
figure
montage(augmentedData,BorderSize=10) % 演示数据增强效果
end
% 训练参数设置
options = trainingOptions("adam", ...
ExecutionEnvironment=exe_env,...
GradientDecayFactor=0.9,...
SquaredGradientDecayFactor=0.999,...
InitialLearnRate=0.001,...
LearnRateSchedule="none",...
MiniBatchSize=16,...
L2Regularization=0.0005,...
MaxEpochs=300,...
BatchNormalizationStatistics="moving",...
DispatchInBackground=true,...
ResetInputNormalization=false,...
Shuffle="every-epoch",...
VerboseFrequency=20,...
CheckpointPath='./checkPoint/',...
CheckpointFrequency=10, ...
ValidationData=validationData, ...
OutputNetwork='best-validation-loss' ...
);
% options = trainingOptions("sgdm", ...
% ExecutionEnvironment=exe_env, ...
% InitialLearnRate=0.001, ...
% MiniBatchSize=16,...
% MaxEpochs=300, ...
% BatchNormalizationStatistics="moving",...
% ResetInputNormalization=false,...
% VerboseFrequency=30);
% 执行训练程序
if doTraining
% Train the YOLO v4 detector.
if flag_augment % 是否数据增强
[detector,info] = trainYOLOv4ObjectDetector(augmentedTrainingData,detector,options);
else
if if_checkPoint % 是否使用checkpoint
load(checkpoint_path);
[detector,info] = trainYOLOv4ObjectDetector(trainingData, net, options);
else
[detector,info] = trainYOLOv4ObjectDetector(trainingData,detector,options);
end
end
else
% 否则使用预训练模型
pretrained = load('yolov4_tiny.mat');
detector = pretrained.detector;
end
训练过程中的输出信息如下:
*************************************************************************
Training a YOLO v4 Object Detector for the following object classes:
* bird
* cat
* cow
* dog
* horse
* sheep
Epoch Iteration TimeElapsed LearnRate TrainingLoss ValidationLoss
_____ _________ ___________ _________ ____________ ______________
Starting parallel pool (parpool) using the 'local' profile ...
Connected to the parallel pool (number of workers: 6).
1 20 00:01:40 0.001 62.356
1 40 00:01:48 0.001 25.72
1 60 00:02:01 0.001 19.095
1 80 00:02:08 0.001 21.819
2 100 00:02:29 0.001 14.169 0.67991
2 120 00:02:43 0.001 19.108
...
在这个过程中,首先选择是否进行数据增强。然后,设置训练参数,例如执行环境(GPU)、学习率、批量大小、最大迭代次数等。接下来,根据选择进行训练或使用预训练模型。训练完成后,将模型保存为animal_tiny_yolov4.mat。最后,使用训练好的模型在测试集上进行检测,评估检测精度,保存测试结果和训练曲线。整个训练过程涉及预处理数据、数据增强、设置训练参数、进行训练、评估检测精度等步骤。以上代码示例展示了如何使用MATLAB实现这些步骤,以实现YOLOv4模型的训练和评估。
5. 系统实现
在本节中,将详细介绍如何将YOLOv4目标检测器与图形用户界面(GUI)相结合,以实现一个友好、易于使用的动物识别系统。结合GUI可以让用户更方便地上传图片、选择模型参数,以及查看识别结果。以下是设计框架和实现原理。系统实现主要包括以下几个部分:
- 图形用户界面(GUI):提供用户与系统交互的界面,包括图片上传、模型参数选择、结果展示等功能。
- 图像处理模块:对用户上传的图片进行预处理,以适应YOLOv4模型的输入要求。
- 检测器模块:使用训练好的YOLOv4动物目标检测器进行动物类别识别。
- 结果处理模块:对检测结果进行后处理,以便在GUI上展示。
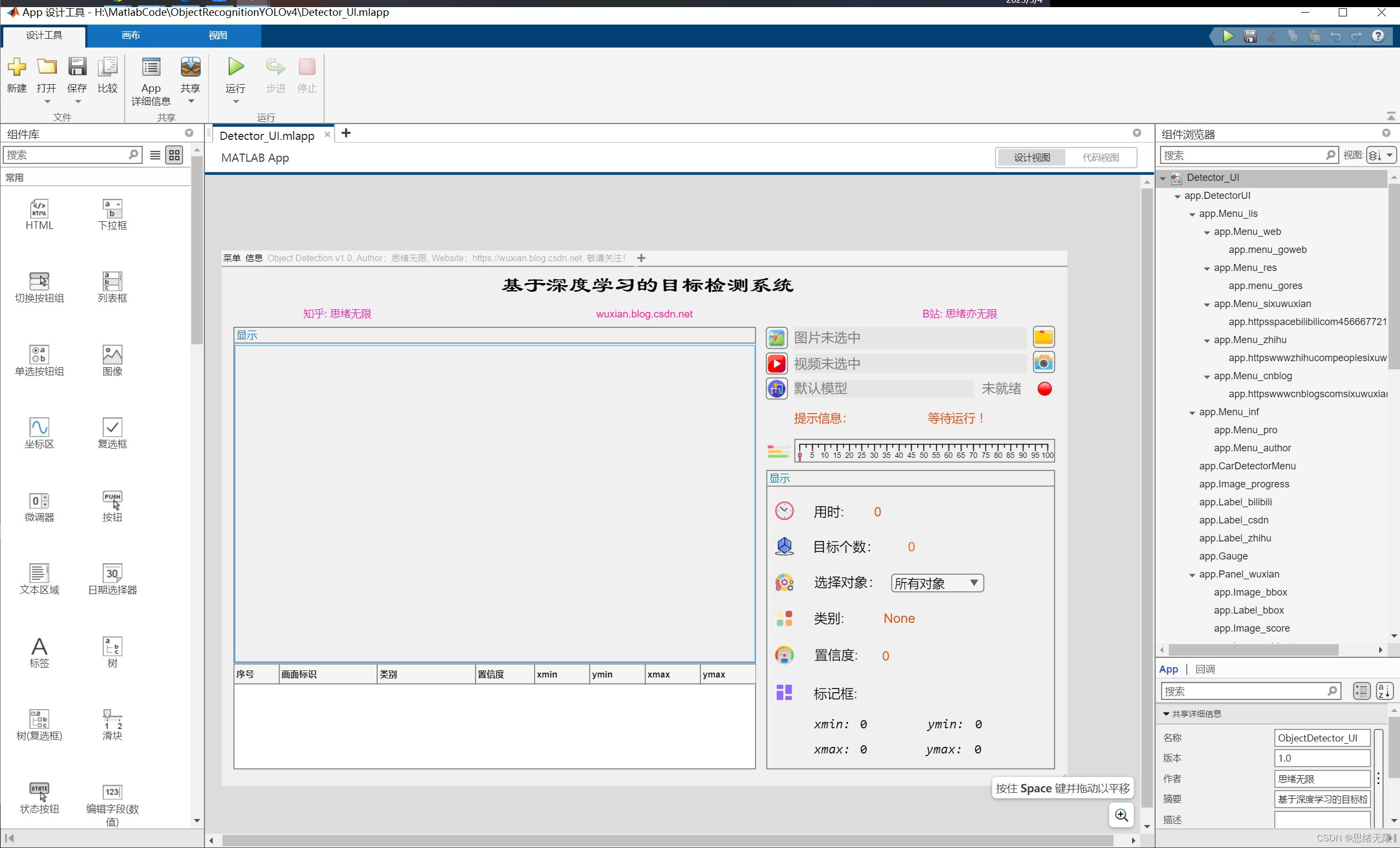
我们的GUI设计旨在为用户提供一个简洁、直观的操作界面。主要元素包括菜单栏、图片显示区域、参数设置区域和结果显示区域。将这些元素布局得紧凑而有序,以便用户能够方便地进行图片上传、参数设置和结果查看。以下是GUI中涉及的主要控件:
- 图片选择按钮:用户点击此按钮后,系统将打开文件选择器以便用户选择一张图片。选定图片后,图片将在图像显示坐标系中展示。
- 视频选择按钮:用户点击此按钮后,系统将打开文件选择器以便用户选择一个视频文件。选定视频后,视频将在图像显示坐标系中播放并实时显示识别结果。
- 摄像头开启按钮:用户点击此按钮后,系统将开启计算机摄像头并实时捕获视频流。捕获的视频将在图像显示坐标系中展示并实时显示识别结果。
- 更换模型按钮:用户点击此按钮后,系统将弹出一个对话框,让用户选择新的模型文件。选定新模型后,系统将使用新模型进行后续的识别任务。
- 图像显示坐标系:用于实时显示用户上传的图片、选定的视频或捕获的摄像头视频流,以及在图像上显示识别结果。
- 结果显示区域:用于展示检测到的动物类别、置信度等信息。用户可以在这个区域查看识别结果。
为了实现GUI的交互功能,需要编写一系列回调函数。以下是主要的回调函数及其功能:
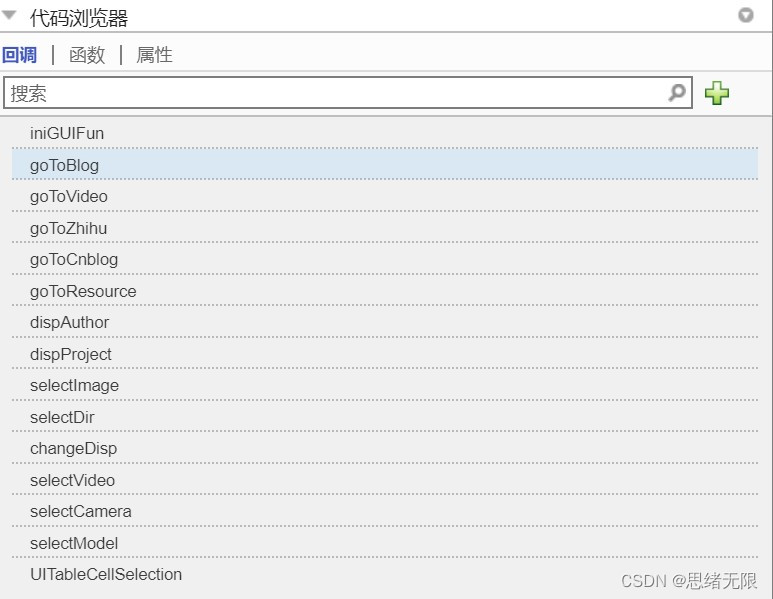
- 图片选择回调函数:当用户点击图片选择按钮时,此函数将被触发。它负责打开文件选择器,让用户选择一张图片,并将图片显示在图像显示坐标系中。
- 视频选择回调函数:当用户点击视频选择按钮时,此函数将被触发。它负责打开文件选择器,让用户选择一个视频文件,并在图像显示坐标系中播放视频,同时实时显示识别结果。
- 摄像头开启回调函数:当用户点击摄像头开启按钮时,此函数将被触发。它负责开启计算机摄像头,捕获视频流并在图像显示坐标系中实时显示识别结果。
- 更换模型回调函数:当用户点击更换模型按钮时,此函数将被触发。它负责弹出一个对话框,让用户选择新的模型文件,并将新模型应用于后续的识别任务。
通过以上设计,实现了一个易于使用、功能齐全的图形用户界面。用户可以通过这个界面方便地进行图片上传、视频选择、摄像头开启、模型更换和结果查看,从而实现动物识别任务。
6. 总结与展望
本文主要介绍了一种基于YOLOv4的目标检测系统。首先,详细阐述了数据集的标注格式及预处理过程,包括图像的标注、数据的划分等。接着,使用 YOLOv4 检测网络构建了动物识别模型,并详细描述了训练过程中的参数设置、锚框估计、数据增强等关键环节。随后,讨论了系统实现的关键技术,包括网络设计、GUI设计等,并展示了一个基于 MATLAB 的图形用户界面,方便用户进行动物识别任务。
尽管本文所提出的动物识别系统已经取得了较好的效果,但仍存在一些可以改进和优化的地方。在未来的研究中,我们将关注以下几个方面:
- 更丰富的数据集:为了提高模型的泛化能力,可以通过收集更多动物种类和场景的图像数据来扩展数据集。同时,可以尝试使用半监督或无监督学习方法,以充分利用未标注数据。
- 更先进的检测算法:随着深度学习技术的发展,可以尝试将更先进的检测算法应用于动物识别任务中,以提高模型的准确性和实时性。
- 多模态信息融合:考虑到动物识别过程中可能涉及多种模态信息,如声音、行为等,可以研究如何将这些信息融合到模型中,以提高识别性能。
- 实时识别与跟踪:针对实时视频流的动物识别和跟踪任务,可以研究更高效的算法和技术,以降低延迟并提高跟踪稳定性。
- 模型部署与优化:为了在不同平台上实现高效的动物识别,可以研究模型压缩、硬件加速等技术,以满足不同场景的需求。
下载链接
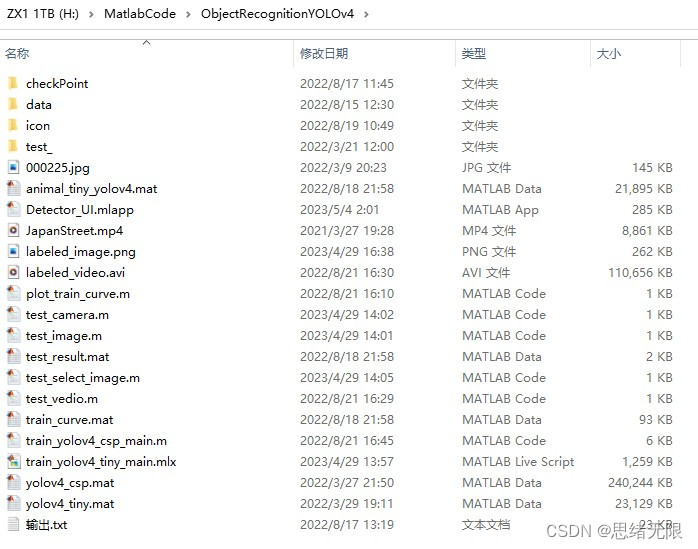
若您想获得博文中涉及的实现完整全部程序文件(包括测试图片、视频,mlx, mlapp文件等,如下图),这里已打包上传至博主的面包多平台,见可参考博客与视频,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:
在文件夹下的资源显示如下图所示:
注意:该代码采用MATLAB R2022a开发,经过测试能成功运行,运行界面的主程序为Detector_UI.mlapp,测试视频脚本可运行test_video.m,测试摄像头脚本可运行test_camera.m。为确保程序顺利运行,请使用MATLAB2022a运行并在“附加功能管理器”(MATLAB的上方菜单栏->主页->附加功能->管理附加功能)中添加有以下工具。
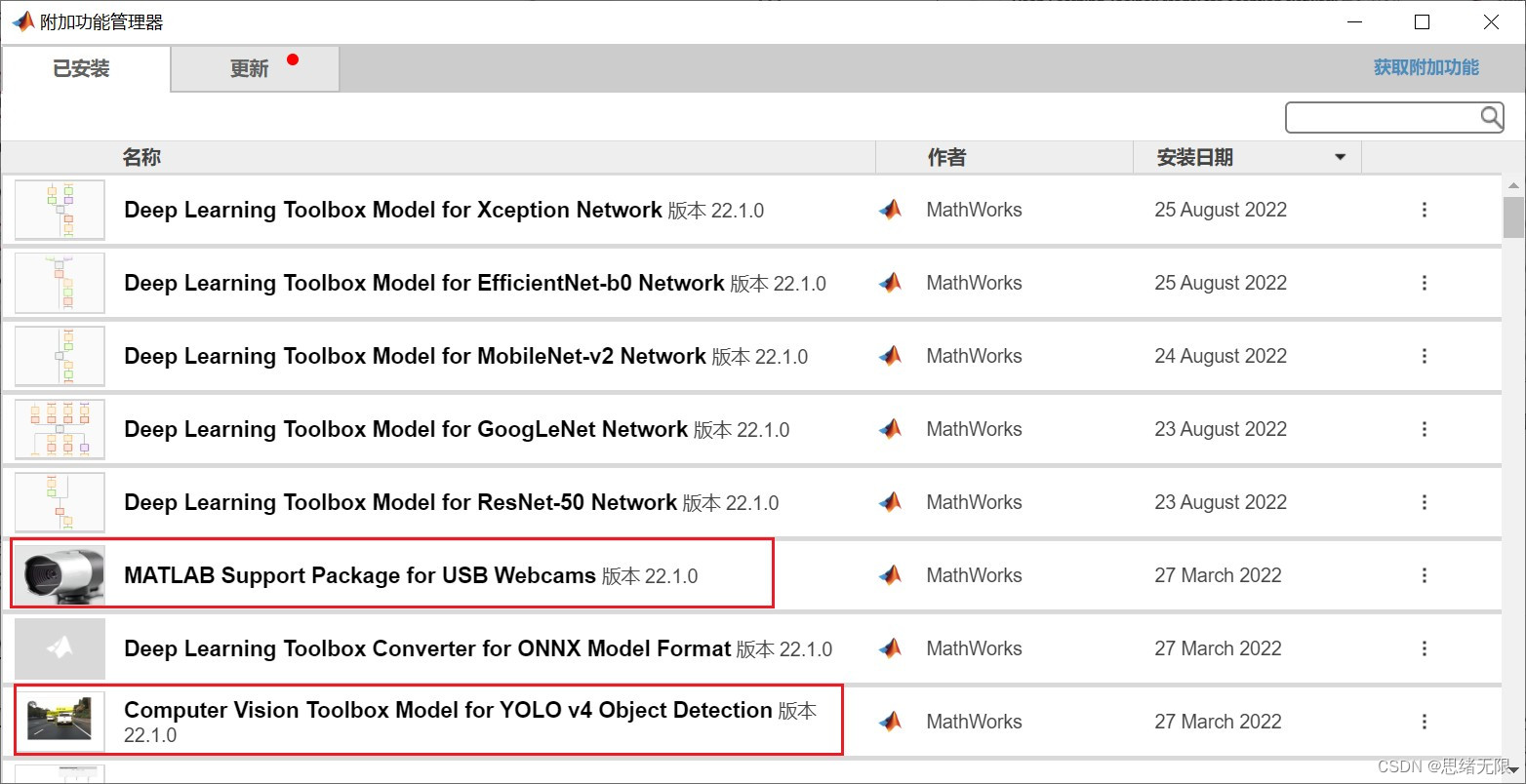
完整资源中包含数据集及训练代码,环境配置与界面中文字、图片、logo等的修改方法请见视频,项目完整文件下载请见参考博客文章里面,或参考视频的简介处给出:➷➷➷
参考博客文章:https://zhuanlan.zhihu.com/p/626659942/
参考视频演示:https://www.bilibili.com/video/BV1ts4y1X71R/
结束语
任何绝对的声明程序无Bug都是不可能的,尽管我们已经努力调试程序,确保在目前的运行环境下没有发现Bug,但计算机配置、操作系统、MATLAB版本等多种因素都可能影响程序的运行。如果在运行过程中遇到问题,希望读者冷静思考、认真检查操作流程、科学合理寻找解决方案,不要让浮躁和偏激影响了学习的热忱。
由于博主能力有限,博文中提及的方法即使经过试验,也难免会有疏漏之处。希望您能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。同时如果有更好的实现方法也请您不吝赐教。
参考文献
[1] Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 779-788).
[2] Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 580-587).
[3] Girshick, R. (2015). Fast R-CNN. In Proceedings of the IEEE international conference on computer vision (pp. 1440-1448).
[4] Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster R-CNN: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems (pp. 91-99).
[5] Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C. Y., & Berg, A. C. (2016). SSD: Single shot multibox detector. In European conference on computer vision (pp. 21-37). Springer, Cham.
[6] Lin, T. Y., Goyal, P., Girshick, R., He, K., & Dollár, P. (2017). Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision (pp. 2980-2988).
[7] Everingham, M., Van Gool, L., Williams, C. K., Winn, J., & Zisserman, A. (2010). The Pascal visual object classes (VOC) challenge. International journal of computer vision, 88(2), 303-338.
[8] Lin, T. Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., ... & Zitnick, C. L. (2014). Microsoft COCO: Common objects in context. In European conference on computer vision (pp. 740-755). Springer, Cham.
[9] Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., ... & Berg, A. C. (2015). Imagenet large scale visual recognition challenge. International journal of computer vision, 115(3), 211-252.
[10] Redmon, J., & Farhadi, A. (2017). YOLO9000: better, faster, stronger. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7263-7271).
[11] Redmon, J., & Farhadi, A. (2018). YOLOv3: An incremental improvement. arXiv preprint arXiv:1804.02767.
[12] Bochkovskiy, A., Wang, C. Y., & Liao, H. Y. M. (2020). YOLOv4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934.
[13] Geiger, A., Lenz, P., & Urtasun, R. (2012). Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3354-3361).
[14] Sindhu V S. Vehicle identification from traffic video surveillance using YOLOv4[C]//2021 5th International Conference on Intelligent Computing and Control Systems (ICICCS). IEEE, 2021: 1768-1775.
[15] Shewajo F A, Fante K A. Tile-based microscopic image processing for malaria screening using a deep learning approach[J]. BMC Medical Imaging, 2023, 23(1): 1-14.
[16] MathWorks. (2021). Object Detection Using YOLO v2 Deep Learning. Retrieved from https://www.mathworks.com/help/vision/ug/object-detection-using-yolo-v2-deep-learning.html.
原文链接:https://www.cnblogs.com/sixuwuxian/p/17372282.html
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:基于YOLOv4的目标检测系统(附MATLAB代码+GUI实现) - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 