以下内容是个人参考网上的学习资料以及自己的理解进行总结的
1、循环神经网络的介绍具体看
https://www.cnblogs.com/pinard/p/6509630.html
深度神经网络无法利用数据中时间序列信息,循环神经网络应势而生。循环神经网络的主要用途是处理和预测序列数据,它最擅长解决的问题是与时间序列相关的。它与CNN一样参数是共享的。
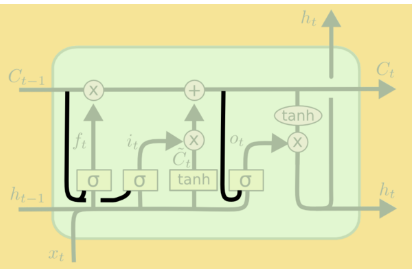
循环神经网络工作的关键点就是利用历史的信息来帮助当前的决策,因此而带来了更大的技术挑战--长期依赖(此外RNN的序列过长时会出现梯度消失现象)LSTM(长短时记忆)的出现正是为了解决这一问题。LSTM是对RNN细胞进行了改造,加入了“遗忘门”它的作用是让循环神经网络“忘记”没有用的信息,它会根据当前的输入Xt和上一时刻的输出Ht-1以及上一时刻的细胞状态共同决定应该从上一时刻的细胞状态记忆中遗忘什么。在循环神经网络‘忘记’了部分之前的状态后,它还需要从当前的输入补充最新的记忆,这个过程是由输入门完成的。“输入门”会根据当前的输入Xt和上一时刻的输出Ht-1以及当前产生的新的细胞状态决定哪些部分进入当前时刻的状态Ct。“输出门”它会根据更新后的状态Ct,上一时刻的输出Ht-1和当前的输入Xt来决定该时刻的输出Ht。
注意:LSTM相比于RNN具备长期的记忆功能是因为除了隐状态Ht,增加了一个新的细胞状态,通过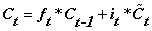
 对赋予LSTM长期记忆功能的细胞状态不断进行更新,一方面及时的遗忘无用的信息,另一方面及时的补充新的信息。
对赋予LSTM长期记忆功能的细胞状态不断进行更新,一方面及时的遗忘无用的信息,另一方面及时的补充新的信息。
当前时刻的隐藏状态输出由当前输入数据,之前的隐藏状态和更新后的细胞状态一起共同决定。
RNN以及其变种的一系列网络最大的问题是,由于其循环的结构导致其无法并行计算,所以训练RNN需要花费大量的时间。同时LSTM的记忆能力也是有限的,有论文证明当序列长度大于200时仍然会出现遗忘现象。
2、LSTM以及其变种(GRU等)图解析
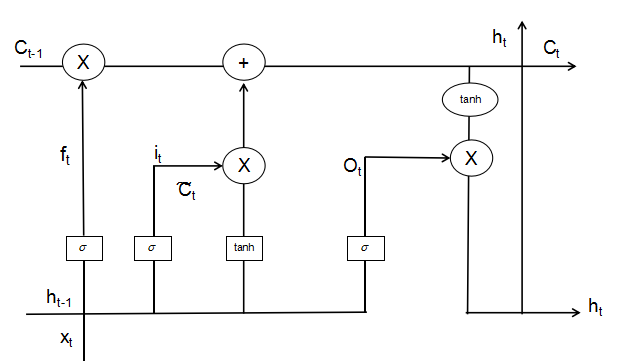
其中牵扯到的计算如下:
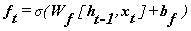 (忘记门部分)
(忘记门部分)
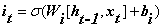 (输入门部分)
(输入门部分)
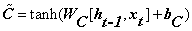 (当前时刻新细胞状态的产生)
(当前时刻新细胞状态的产生)
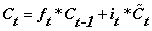 (细胞状态的更新,忘记门结合上一时刻的细胞状态决定需要遗忘的信息,输入门结合当前时刻产生的新的细胞状态决定应该添加什么信息,最终共同对包含长期记忆的细胞状态进行更新)
(细胞状态的更新,忘记门结合上一时刻的细胞状态决定需要遗忘的信息,输入门结合当前时刻产生的新的细胞状态决定应该添加什么信息,最终共同对包含长期记忆的细胞状态进行更新)
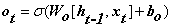 (输出门部分)
(输出门部分)
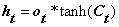 (输出门结合包含长期记忆的细胞状态共同决定当前时刻的输出)
(输出门结合包含长期记忆的细胞状态共同决定当前时刻的输出)
注意以上的*是元素级相乘,不是矩阵相乘。
根据以上的公式能够发现,细胞的状态无法对门控结构造成影响,可以加入窥视孔连接,使得细胞状态得以对门控结构造成影响。细胞单元结构图的改变:
相应计算公式的改变:
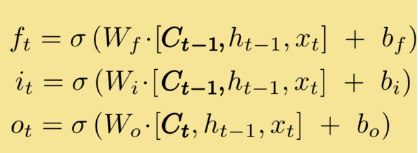
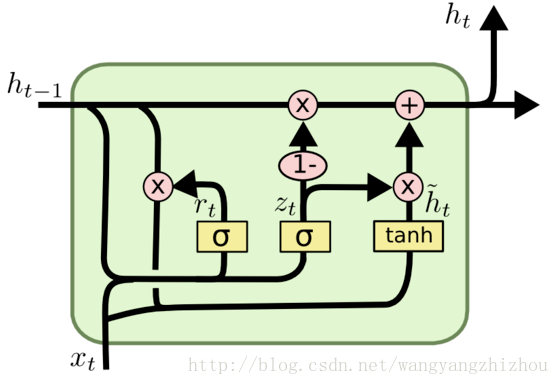
另一个变型GRU,它把LSTM中的遗忘门和输入门合并为了一个单一的更新门,同时还混合了细胞状态及隐藏状态以及其它一些改动。GRU的门控结构减少到了两个,分别为更新门和重置门,更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多。重置门用于控制忽略前一时刻的状态信息的程度,重置门的值越小说明忽略得越多。
细胞结构图以及计算公式如下:
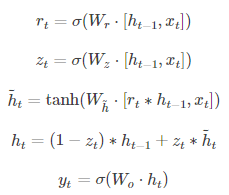
3.LSTM为什么选用sigmoid和tanh两个激活函数是否可以改变
从LSTM的前向传播计算公式中能够得出,三个sigmoid激活函数用于门处,通过sigmoid转换为0-1之间的值能够得到对遗忘输入输出的更直观的表示(因为后来又和细胞状态相乘是否起到一个概率的作用),为什么不用其他sig函数因为sigmoid函数更容易达到饱和,其他的难以饱和,LSTM应该需要饱和的门来记住或忘记信息,不饱和的门会使得过去和现在的记忆一直在叠加,造成记忆错乱。sigmoid激活函数最好不要改变。
两个tanh用于细胞状态处,有论文指出这个可以替换。
4、对于cell和num_units(hidden_size隐藏层神经元的个数)的说明(最开始学习时在这里比较迷惑)
就拿最基础的RNN来说吧,cell其实就是一个RNN的网络,
cell表示多个时刻(序列)组成的RNN网络,从一个序列时刻到另一个序列时刻,cell的内部状态(神经元)就会更新。也就是说,从空间上讲,cell是同一个,但是时间上,cell_1表示输入x(1),隐状态h_1,cell_2表示输入x(2),隐状态h_2。
num_units(hidden_size)是RNN及其变种隐藏层节点的个数,也是神经网络用于特征提取的核心部分,其它的一些网络变换是为了使得隐藏层能够更好的提取特征。
num_units越大则每个LSTM的Cell能记忆的东西就越多。
5、LSTM的隐藏层到底在哪,以及其内部参数个数的计算
以下内容参考:
https://blog.csdn.net/notheadache/article/details/81164264
https://www.zhihu.com/question/64470274
LSTM 的 cell 里面的 num_units 该怎么理解,其实也是很简单,看看下图:
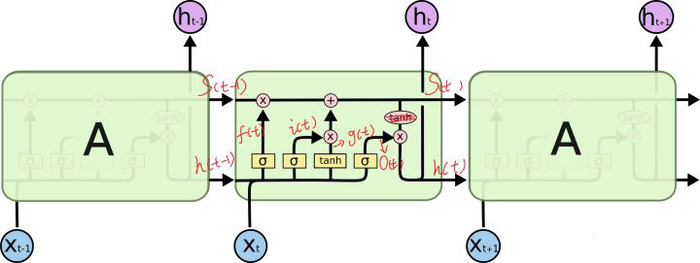
可以看到cell在t时刻 里面有四个黄色小框,你如果理解了那个代表的含义一切就明白了,每一个小黄框代表一个前馈网络层,对,就是经典的神经网络的结构,num_units就是这个层的隐藏神经元个数,就这么简单。其中1、2、4的激活函数是 sigmoid,第三个的激活函数是 tanh。
1)cell 的权重是共享的,这是什么意思呢?这是指这张图片上有三个绿色的大框,代表三个 cell 对吧,但是实际上,它只是代表了一个 cell 在不同时序时候的状态,所有的数据只会通过一个 cell,然后不断更新它的权重。
2)那么一层的 LSTM 的参数有多少个?我们知道参数的数量是由 cell 的数量决定的,这里只有一个 cell,所以参数的数量就是这个 cell 里面用到的参数个数。假设 num_units 是128,输入是28位的,那么结合2中提及的计算公式,可以得到,四个小黄框的参数一共有 128*(128+28)*4,可以看看 TensorFlow 的最简单的 LSTM 的案例,中间层的参数就是这样,不过还要加上输出的时候的激活函数的参数,假设是10个类的话,就是128*10的 W 参数和10个bias 参数
3)cell 最上面的一条线的状态即 s(t) 代表了长时记忆,而下面的 h(t)则代表了工作记忆或短时记忆。
6、LSTM相比于RNN能够缓解梯度消失的原因
具体解析可参考:https://www.zhihu.com/question/34878706/answer/665429718
https://www.zhihu.com/question/44895610/answer/616818627
https://zhuanlan.zhihu.com/p/85776566
正向RNN中对于每一时刻的隐状态由当前时刻的输入和上一时刻的隐状态共同决定:
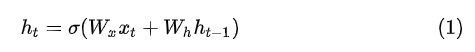
在对式中的权值W进行更新时需要对W求导,而由于RNN网络其特有的结构特性,使得在求导时会出现连乘操作:
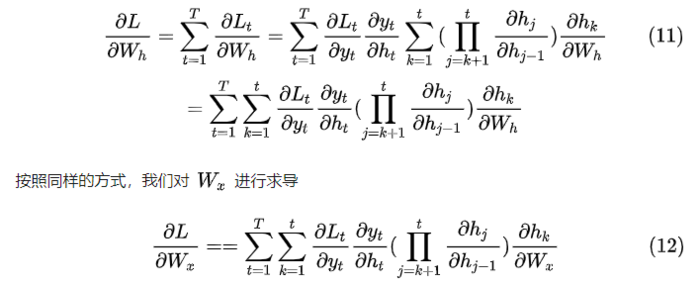


而对于LSTM,相比于RNN加入了特有的门控结构,同时相比于RNN出了隐藏状态h还多了一个细胞状态C,没时刻都会对细胞状态进行更新,同时细胞状态的引入也是LSTM具备长期记忆能力的关键。

7、BasicLSTMCell与LSTMCell的区别
BasicLSTMCell是LSTM实现的一个基础版本,LSTMCell是LSTM实现的一个高级版本。主要说LSTMCell中的use_peepholes参数,默认的为False表示不使用窥视孔连接。即为LSTMCell能够添加上面在第2条中所描述的窥视孔规则。
8、static_rnn和dynamic_rnn的区别:
静态RNN不能处理变长数据,动态RNN能够处理变长数据,这里的变长是说每个batch的最大长度能够不同,可以根据不同batch其batch中最大长度的文本进行填充,静态RNN是事先规定所有batch的句子最大长度都相同。注意:不管静态还是动态的RNN,其每个batch的文本长度都要是相同的。
单向的RNN:
注意:输出方面静态和动态的都是两个
输入数据方面:static_rnn接收的是一个个List,对于三维的输入x经过inputs=tf.unstack(x,axis=1)转换即可。而dynamic_rnn是Array
输出方面:Static_rnn输出的是一个大的list,顺序即为时间序列顺序,里面是一个个array,一维是批次大小,二维是RNN隐藏层节点的个数。dynamic_rnn的输出是一个三维的array,注意需要维度转换,转换为时间批次优先的,outputs=tf.transpose(outputs,[1,0,2])
作为下一全连接层输入,只需取最后一个序列的结果,因为前面的信息都被学习到了,最后一个序列的输出就是语义的表征,即为outputs[-1]即可。
双向的RNN:
注意:输出方面静态的是三个,动态的是两个
静态的也是输出一个list,顺序即为时间序列顺序,里面是一个个array,一维是批次大小,二维是RNN隐藏层节点的个数*2(这里是单向的二倍)。
具体代码实现为:
inputs=tf.unstack(x,axis=1)
outputs,_,_=tf.nn.static_bidirectional_rnn(lstm_fw_cell,lstm_bw_cell,inputs,dtype=tf.float32)
动态的也是一个Tensor,需要先对输出进行合并然后再转换为时间批次优先。
具体代码实现为:
outputs,output_states=tf.nn.bidirectional_dynamic_rnn(lstm_fw_cell,lstm_bw_cell,x,dtype=tf.float32)
outputs=tf.concat(outputs,2)#这里2可换为-1
outputs=tf.transpose(outputs,[1,0,2])
dynamic_rnn中重要参数与返回值说明
它比静态RNN更加好用,注意的它的参数initial_state用于初始化cell的状态,这个参数不用设置,但是必须设置另外一个参数dtype它用于设置期望的输出和初始化state的类型,不设置initial_state必须要设置dtype,系统会自动按规定类型进行初始化。还有一个就是sequence_length用于指定输入数据的有效长度,因为dynamic_rnn可以处理变长数据。对于其返回值,在说返回值之前还要说到一个参数time_major:若其值设置为False则表示非时间批次优先,input的shape为[batch_size,max_time,...],如果是True则shape为[max_time,batch_size,...]
一般选用默认的false因为符合输入数据规范,同时dynamic_rnn的返回值有两个outputs和state,那么注意这里一定要对outputs输出进行维度转换,转换为时间批次优先,同时对于下面的全连接层只取最后一维。
outputs=tf.transpose(outputs,[1,0,2])
pred=tf.contrib.layers.fully_connected(outputs[-1],n_classes,activation_fn=None)
9、动态RNN的第二个输出state的分析
具体参考:
https://blog.csdn.net/xiaokang06/article/details/80235950
对于dynamic_rnn的输出state是一个元组,元组的长度是LSTM网络的层数,state中的每一个元素为一个LSTMStateTuple,它的长度为2,第一个元素存的为每层LSTM最后一个时刻的c(细胞状态),第二个元素存的为每层LSTM最后一个时刻的h(即为隐层的输出),其中c和h的维度都是(batch_size,hidden_size)。其中LSTM最后一层的最后一个时间批次的输出为output[:-1:],同时为state[-1].h。
注意:LSTM网络结构从第一个输出output中能够得到最后一层各个时刻的输出。从第二个输出state中能够得到各层最后一个时刻的细胞状态c以及各层最后一个时刻隐层的输出h。
10.如何用LSTM处理过长的数据
尽管LSTM相比于RNN能够一定程度上缓解梯度消失问题,从而具备更好的记忆功能,但是当序列长度过长时仍然会出现梯度消失问题,有论文指出序列长度大于200LSTM也会容易出现梯度消失。
那么该如何用LSTM处理过长的数据,参考:https://blog.csdn.net/together_cz/article/details/73824127
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:神经网络之循环神经网络及细节分析 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 