水电站入库流量预测--基于自定义损失函数的循环神经网络建模方法
从志在必得到铩羽而归——记一次大数据竞赛经历
最近参加了一个比赛,在工业大数据产业创新平台上,是一个水电站入库流量预测问题。简单看了一下题目,嚯,这个方向以前有做过啊,不说了~开整。
赛题背景:对进入水电站水库的入库流量进行精准预测,能够帮助水电站对防洪、发电计划调度工作进行合理安排。入库流量受到降水、蒸发、土壤(直接影响地表径流、地下径流)、上游来水等诸多因素的综合影响(如下图所示)。通过数据分析方法,基于大量的历史数据和可获取的监测数据,实现水电站入库流量的精准预测,将对水电站生产带来显著的安全和经济价值。
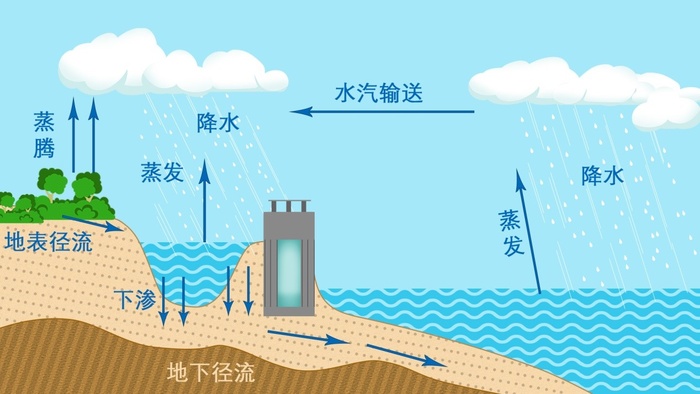

赛题描述:基于历史数据和当前观测信息,对电站未来7日入库流量进行预测。预测时间间隔为3个小时,即对未来56个时间节点的入库流量数据进行预测。其中,历史数据包括:入库流量数据、环境观测数据,遥测站降雨数据,降雨预报数据。
一.问题分析及思路简述
这是一个典型的时序数据预测问题。首先对数据进行分析。本次题目的原始数据时间段为2013/1/1——2018/1/7,共计5年的历史数据,目标对2018年3段数据(初赛),2019年5段数据(复赛)进行预测,各类数据情况如下。
1.入库流量数据:这是本题的预测目标,每个数据点之间时间间隔为3小时。通过观察可以看出,主办方已经将这些数据进行了归一化,流量数据都分布于0~1之间。通过对数据文件的时间节点进行扫描,发现缺失2014-11-20 11:00:00到2014-12-31 23:00:00之间的数据。
2.环境表数据:环境表的数据间隔为天,即每隔24小时一个数据点。数据文件中共有三类数据,包括温度,风速,风向。其中温度和风速已经进行了归一化操作,数据依然分布在0~1之间,而风向则是原始值,数值较大且没有明显区分度(数值处于999001~999016之间)。
3.遥测站降雨数据:这个数据文件较大,其时间粒度最细,每隔1个小时即有一个数据点。另外每个数据点包含39个测站,每一个数据即代表某个测站在某一小时内的降雨量。可以看出,数据也已经进行过归一化,但其数值一般都比较小,普遍小于0.1。
4.降雨预报数据:降雨预报的数据以天为单位,即时间间隔为24小时。每一个时间节点上,包含5个数据点,代表未来5天的降雨情况。数据也都已经被归一化到0~1范围之内。经过扫描发现有部分日期的降雨数据缺失。如下表:
表1 降雨数据缺失情况
|
2013-03-11 |
2013-07-19 |
2014-01-25 |
|
2014-04-09 |
2014-04-16 |
2014-06-03 |
|
2015-02-07 |
2016-05-21 |
2017-09-30 到 2017-10-27 |
经过对数据的简单分析,发现数据存在下述问题:①数据缺失,建立模型之前,需要对缺失数据进行处理,一般使用填充法或者是在拼接训练样本时跳过缺失的数据段。②时间尺度不统一,预测目标入库流量数据的时间间隔为3小时,遥测站降雨数据时间间隔为1小时,而环境表和降雨预报数据的时间间隔都是24小时。在建模之前需要对各类数据的时间尺度进行统一。③特征较为繁杂,这里主要指的是降雨量预报数据和遥测站降雨数据;其中每个时间点的数据都包含较多特征,在建立模型时是否将其纳入,都是我们后续要完成的工作。
由于数据时序性突出且在每个时间点包含多种特征(即数据有包含多个时间节点,每个时间节点又包含多个特征数据),因此计划使用RNN模型,将多个时间节点的多条特征数据丢入模型一把梭。其建模过程大概分为以下几步:①数据预处理及特征选择,②模型建立及训练,③结果预测。其中需要额外注意的是:本次比赛的评分规则为纳什效率系数(NSE),因此在建立模型的过程中,需要对损失函数(误差判别函数)进行特殊的设计。评分规则截图如下:

二.数据预处理及特征选择
数据预处理一般包含野值剔除、空缺值填充、数据归一化等操作。由于此次赛会提供的数据基本上都经过了归一化,就不必再进行额外的归一化操作。又由于降雨量数值的跃动性较强,极其不稳定(如图1),因此常规的空缺值填充方法(如均值填充、相似特征回归等)所得到的结果可信度较差,在数据预处理阶段,便不对空缺值进行填充,仅在拼接模型时将其跳过。同样的,由于降雨量数据强烈的不稳定性(如图1),这里不对其进行野值剔除操作,常规的3σ准则等野值判别方式也无法有效工作。
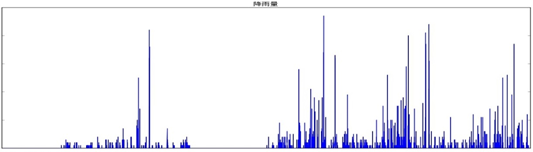
图1 部分降雨量统计示意图
在特征选择方面,第一步工作是对遥测站降雨数据进行降维,即对39个测站的数据进行加和,形成一个单一的降雨量特征。并将其时标和入库流量数据进行统一,变为每3小时1个数据点。第二步的工作是验证降雨量预报工作的可信度,具体方法是使用协方差函数,计算降雨量序列和降雨量预报序列的相关系数,其结果如下:
第一天预报: 0.6411514582529538
第二天预报: 0.556989653623267
第三天预报: 0.5372333462465179
第四天预报: 0.4850024133929662
第五天预报: 0.4228036934449081
可以看出,相关系数都大于0,即表明未来5天的降雨预报与真实的降雨量之间都是正相关的,可以说预测结果都较为准确,因此将这5个特征全部纳入循环神经网络模型。另外基于对数据的直观理解,在环境表中,风速和温度可以直接影响水域的蒸发速率,而风向关系不是很大,因此将风向这个特征进行移除。
三.模型建立及训练
1.训练模型拼接经过上一步的特征选择工作,现在一共剩下9种特征数据,也就是说在一个时间节点,共有[温度、风速、D1降雨、D2降雨、D3降雨、D4降雨、D5降雨、实际降雨量(近3小时)、入库流量]9条数据。由于题目最终要基于前一个月的数据对下个月前7天的入库流量进行预测,这里直接将时间窗口拉满,使用前30天的数据作为模型输入,后7天的数据作为模型输出。数据的时间间隔为3小时,30天的数据共有240个时间节点,7天的数据共有56个时间节点。最终的一个训练样本由2部分组成,第一部分是维度为(240*9)的输入,第二部分使维度为(56*1)的输出,输出中仅包含接下来7天内的入库流量特征数据。如图2所示,单个样本的输入为绿色框中的部分,包括240个时间节点的全部特征数据;样本的输出为红色框内的部分,即后续56个时间节点的入库流量值。
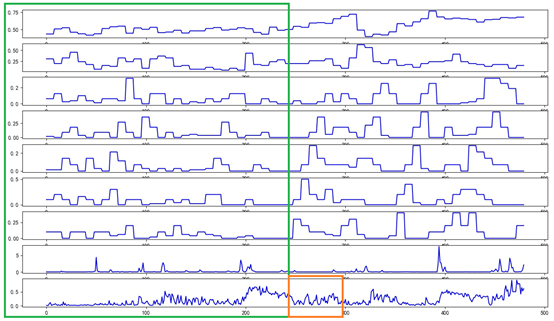
图2 单个样本输入及输出示意
在进行拼接的过程中,采用窗口滑动的方法逐点获取样本,同时注意要将所有特征的时间节点对齐,所有特征数据都是时间连续且一致的情况下,再将其存入训练样本集合。最终得到11189条训练样本。
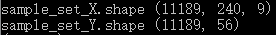
图3 训练样本及其维度
2.LSTM循环神经网络构建
①前向传播计算结构
这里采用LSTM循环神经网络模型对数据进行建模,可以同时将数据的时序性和多特征性纳入考量。在每一个时间节点,LSTM单元的输入由2部分组成——当前时间节点的输入,以及上一个时间节点的输出。
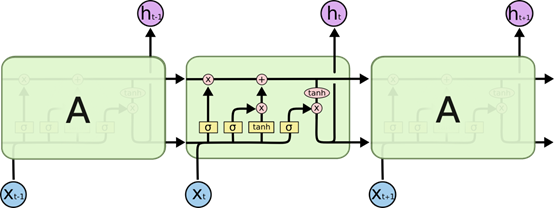
图4 LSTM循环神经网络模型
上图是LSTM单元的示意图,其公式不再具体描述。训练样本中每一个时间节点的数据,都作为输入的一部分进入LSTM单元,经计算后得到输出并再次循环进入该LSTM单元;直到最后一个时间节点,获得一个特征向量,维度为(1*神经元数),将它乘以一个维度为(神经元数*56)的矩阵,得到一个长度为56的向量,使用Sigmoid激活函数计算后,向量中的所有值都位于(0,1)之间。该向量即为模型的最终输出结果,代表未来56个时间节点的入库流量预测。
1 self.w = tf.Variable(tf.truncated_normal([self.num_nodes, self.output_dim], -0.1, 0.1),name=\'w\') # output_dim 是指输出维度,即一个样本的Y包含几个值 2 self.b = tf.Variable(tf.zeros([self.output_dim]),name=\'b\') 3 self.batch_in = tf.placeholder(tf.float32, [None, self.train_data.shape[1], self.input_dim],name=\'batch_in\') 4 self.batch_out = tf.placeholder(tf.float32, [None, self.output_dim],name=\'batch_out\') 5 lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(self.num_nodes,forget_bias=1.0,state_is_tuple=True) 6 output, final_state = tf.nn.dynamic_rnn(lstm_cell, self.batch_in, time_major=False, dtype=tf.float32) 7 self.y_pre = tf.nn.sigmoid(tf.matmul(final_state[1], self.w) + self.b,name="y_pre")
上述代码中,w,b为最后输出结果的权重参数和偏置,用来将RNN最后一个时间节点输出的特征向量转换为一个长度为56的最终输出向量。batch_in,batch_out则是输入的占位符,代表训练样本的输入(X)和输出(Y),其第一维设置为None,使其可以匹配任意数量的样本,方便成批开展训练。在第5行中的num_nodes代表神经元数目,同时也是特征向量的长度。y_pre则代表前向传播的最终结果,也是最终得到的预测值。
②定义损失函数及反向传播计算
之后需要定义损失函数及反向传播计算。这里重点对损失函数的设计进行详细说明,本次题目的评分规则比较特殊,不同于一般的交叉熵函数、均方根误差等评价方式,这里使用纳什效率系数(NSE)作为评价指标。
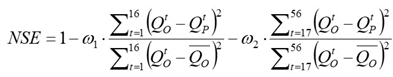
在进行NSE计算的过程中,将数据分成两段,前2天的误差结果给予0.65的权重,后5天的结果给予0.35的权重。根据题目要求,NSE越大,评分越高。也就是说需要公式右侧的两个减数:
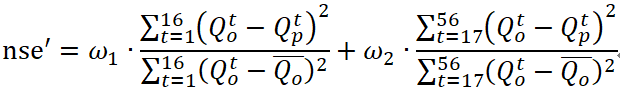
尽可能小。因此,在设计损失函数时,将nse\'设置为损失函数,并在训练模型的过程中使其朝着损失变小的方向进行训练。
1 self.batch_out_mean = tf.reshape(tf.reduce_mean(self.batch_out,axis=1),[-1,1]) 2 self.nse_left = 0.65*tf.reduce_sum(tf.square(self.batch_out[:,:16]-self.y_pre[:,:16]),axis=1)/tf.reduce_sum(tf.square(self.batch_out[:,:16]-self.batch_out_mean),axis=1) 3 self.nse_right = 0.35*tf.reduce_sum(tf.square(self.batch_out[:,16:]-self.y_pre[:,16:]),axis=1)/tf.reduce_sum(tf.square(self.batch_out[:,16:]-self.batch_out_mean),axis=1) 4 self.nse = tf.reduce_mean(self.nse_left+self.nse_right,name="nse") 5 self.train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.nse) 6 self.saver = tf.train.Saver()
上述代码中,self.nse代指的是上方公式中的nse\'变量。首先计算这一批真实值中每一个样本向量的均值,再分别计算nse\'的两个部分,赋予其0.65及0.35的权重,之后再加和。之后在第5行,设置优化器,使模型在反向传播计算的过程中,沿着nse\'减小的方向优化。反向传播的过程构造完毕。
3.模型训练及参数调优
①梯度爆炸问题的解决
在对部分训练样本进行训练的过程中,发现某些样本在经历几轮训练后损失值急剧攀升,成为某个较大的固定值后便不再有任何变动。初步分析是损失函数nse\'中,有部分Qot值与观测序列均值接近,导致分母部分接近于0,以致损失函数值激增,导致梯度爆炸。为解决这个问题,分阶段对训练样本进行测试,筛除会导致梯度爆炸的样本,最终筛除的样本为:6200~6460,7650~8100共计710个样本,约占样本总数的6%。
②训练样本切分
经过样本筛除之后,剩余样本共10479个,将这些训练样本划分为3个集合,即训练集、验证集、测试集。其中训练集占比90%,共9431条样本;验证集和测试集占比都为5%,分别含有524条训练样本。
③学习率调节及训练终止条件设置
在每一轮次的训练中,仅使用训练集中的数据对模型参数进行优化调节,并在完成一轮训练之后,使用当前的模型参数,对验证集中的训练样本进行预测,并计算其nse\'。如果该模型对训练集的预测效果优于上一轮,则继续训练;如果模型连续3轮在验证集中没有取得更好的预测效果,则将学习率降低50%,以防止模型在最优解附近震荡;如果模型连续4轮没有在验证集中取得更好的预测效果,则结束训练,保存模型参数。训练结束以后,使用得到的模型对测试集数据进行预测,计算其nse\'结果,与验证集差距不大的话,则说明模型的预测结果可信。
1 last_loss = 9999.9 2 last_4_converge = [1,1,1,1] 3 last_3_converge = [1,1,1] 4 for i in range(epochs): 5 for j in range(int(len(self.train_data)/self.batch_size)): 6 batch_i = self.train_data[j*self.batch_size:(j+1)*self.batch_size] 7 batch_o = self.train_label[j*self.batch_size:(j+1)*self.batch_size] 8 self.sess.run(self.train_op, feed_dict={self.batch_in:batch_i, self.batch_out:batch_o.reshape(self.batch_size,self.output_dim)}) 9 if (i+1)%1==0: 10 this_loss = self.sess.run(self.nse,feed_dict={self.batch_in:self.validate_X, self.batch_out:self.validate_Y.reshape(len(self.validate_Y),self.output_dim)}) 11 if(this_loss>=last_loss): 12 last_3_converge.append(0) 13 last_3_converge.pop(0) 14 last_4_converge.append(0) 15 last_4_converge.pop(0) 16 else: 17 last_3_converge.append(1) 18 last_3_converge.pop(0) 19 last_4_converge.append(1) 20 last_4_converge.pop(0) 21 last_loss = this_loss 22 train_loss = self.sess.run(self.nse,feed_dict={self.batch_in:batch_i,self.batch_out:batch_o.reshape(self.batch_size,self.output_dim)}) 23 print(\'epoch:%d train:\'%(i+1),train_loss,\' validate:\',this_loss,\' \',last_4_converge) 24 if((1 not in last_4_converge) or (self.lr<0.000002)): #连续4轮未收敛或学习率过小时,结束训练 25 break 26 elif(1 not in last_3_converge): #连续3轮未收敛,降低学习率 27 self.lr = self.lr*0.5
④模型训练
根据上述的方法描述,构建LSTM深度学习模型,开展训练,经过多轮调整测试,发现超参数在设置为下表中的结果时,预测效果较好。
表2 模型超参数设置建议
|
隐藏层神经元数目 |
批处理大小 |
初始学习率 |
优化器 |
|
256 |
32 |
0.002 / 0.003 |
RMSProp |
通过共计1000轮次的训练(两轮500次的训练),最终得到预测模型。其对训练集上最后一个批次的数据预测偏差(nse\')为0.151,对验证集中所有数据的预测偏差(nse\')为0.19552,对测试集中所有样本的预测偏差(nse\')为0.19509。
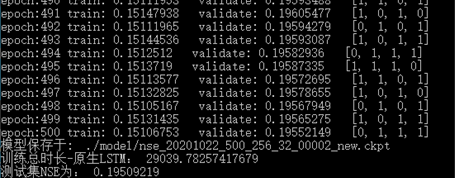
图5 训练结果
结果出来一看,哎,这模型厉害了!对于没有训练过的的测试集来说,其预测结果的平均nse\'是0.19509,按照赛会给出的计分公式: score=(1-nse\')*100,理论上讲,对于新的输入样本,预测结果的nse平均应该是0.805左右,咋地也能得到80来分的成绩。后面又把测试集的预测结果图像画出来一看,嘿,还真不错。


上面是测试集中找了几个比较有代表性的数据样本预测结果,不论是哪种形状的数据,递增的、大段固定值的、以天为单位强周期的,都能取得不错的效果,尤其是对入库流量的峰谷趋势把握的相当到位。预测最差的也就是最后一张图片,nse\'的值约为1.064。看到这些,瞬间觉得信心爆棚,胜利似乎近在眼前。
但现实总是无情打脸,在使用这个模型对目标数据进行预测时,效果很不理想。上传预测结果后,基本上是负分,对于复赛中2019年的5段数据更是超出了下界,即意味着nse\'的值超过了2.0。最后终究没有冲进决赛圈(前30),折戟赛场,铩羽而归。
四.原因分析及个人感悟
技术层面:
对于已有的2013年初至2017年底的数据,本文所构建的LSTM循环神经网络表现良好,能够对未来7天的入库流量数据进行精准的预测。但对主办方给出的3段2018年数据及5段2019年数据,则效果欠佳,损失函数nse\'值扩大了5~20倍不等。由于主办方并未公开2018年及2019年数据,无法做到按例分析。猜测出现该问题的原因可能是以下几个方面:
①模型对已有数据(2013.1——2017.12)产生了过拟合。理论上来讲,这种现象是不会发生的,因为在进行模型训练的过程中,模型参数调整仅依赖于训练集,而模型训练程度则由验证集进行判断,测试集始终没有参与其中。以前在别的时序数据预测项目中出现过模型在测试集上表现糟糕,而在训练集和验证集上表现良好的现象,可以推测出模型对训练集合验证集拟合过度。本次比赛中这种对训练集、验证集、测试集都表现良好而在新的样本上表现差劲的现象还是第一次遇到。经过思考,为避免模型对已有数据产生过拟合,可以在设置终止条件时,控制学习率的大小,为其规定一个最小值,当学习率调整小于该值时,停止训练。
②在解决梯度爆炸问题的过程中,剔除了710个样本,这710个样本中可能存在某种规律没有被模型所掌握。关于这个问题有两种解决方案:一是在损失函数中,在计算分母时判断其值的大小,为其规定一个最小值,如0.01,避免梯度的爆炸;二是使用常规损失函数如rmse(均方根误差)来训练出第二个模型,预测结果由两个模型进行均值融合后获得。
③时间窗口设置过长。这次为了节约建模时间,把时间窗口设置到最大的30天,这样便增加了模型的复杂度,在进行训练时,更多的时间窗口便意味着特征向量在LSTM结构里循环了更多的次数,也就更容易产生梯度爆炸/消失问题。另外,直观上来讲,30天前的降雨对当前的河流水量产生不了太大影响,因此设定一个较短的、符合实际情况的时间窗口更加合适。
心理层面:
通过这次比赛有以下收获:一是不能钻牛角尖,骄兵必败。在初赛阶段,我已经发现上传的预测结果无法达到模型的理论得分,当时经过了500轮的训练,模型的理论得分在70分左右,但上传的2018年3条数据预测结果只得到了-20分的成绩。由于对于自己的模型信仰坚定,我判断是训练还不够不充分所导致。便又深入训练了500轮,达到了理论得分80分的水平,在复赛中对2019年5条数据的预测结果直接崩盘,达到-100分开外......二是将所有特征放进模型里面一把梭,会使其参数量增大,模型复杂度也会跟着暴涨,根据奥卡姆剃刀法则,越复杂的模型也就越难以信任。未来的建模过程中还应投入更多的人工分析工作,不能一味信任复杂模型。
欢迎各位大佬进行指导,提出改进意见。

本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:水电站入库流量预测–基于自定义损失函数的循环神经网络建模方法 – 牛云杰 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 