一、爬取目标
大家好,我是 @马哥python说,一枚10年程序猿。
今天分享一期python爬虫案例,爬取目标是新浪微博的微博签到数据,字段包含:
页码,微博id,微博bid,微博作者,发布时间,微博内容,签到地点,转发数,评论数,点赞数
经过分析调研,发现微博有3种访问方式,分别是:
- PC端网页:https://weibo.com/
- 移动端:https://weibo.cn/
- 手机端:https://m.weibo.cn/
最终决定,通过手机端爬取。
这里,给大家分享一个爬虫小技巧。
当目标网站既存在PC网页端,又有手机移动端,建议爬取移动端,原因是:移动端一般网页结构简单,并且反爬能力较弱,更方便爬虫爬取。
二、展示爬取结果
通过爬虫代码,爬取了“环球影城”这个关键字下的前100页微博,部分数据如下: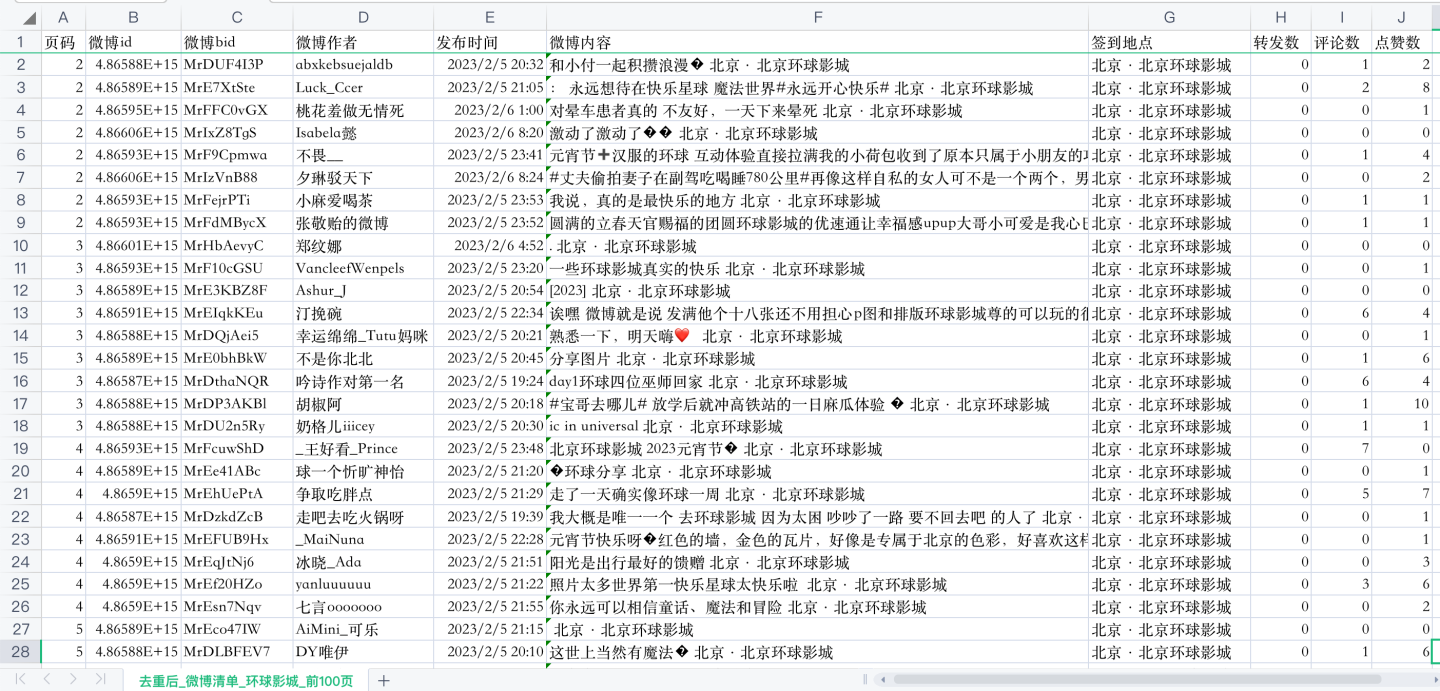

一共翻页了100页,大概1000条左右微博。
三、讲解代码
首先,导入需要用到的库:
import os # 判断文件存在
import re # 正则表达式提取文本
import requests # 发送请求
import pandas as pd # 存取csv文件
import datetime # 转换时间用
然后,定义一个转换时间字符串的函数,因为爬取到的时间戳是GMT格式(类似这种:Fri Jun 17 22:21:48 +0800 2022)的,需要转换成标准格式:
def trans_time(v_str):
"""转换GMT时间为标准格式"""
GMT_FORMAT = '%a %b %d %H:%M:%S +0800 %Y'
timeArray = datetime.datetime.strptime(v_str, GMT_FORMAT)
ret_time = timeArray.strftime("%Y-%m-%d %H:%M:%S")
return ret_time
定义一个请求头,后面发送请求的时候带上它,防止反爬:
# 请求头
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Mobile Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-encoding": "gzip, deflate, br",
}
打开chrome浏览器,在m端网址搜索"环球影城",选择地点,选择第一条搜索结果"北京环球影城",如下: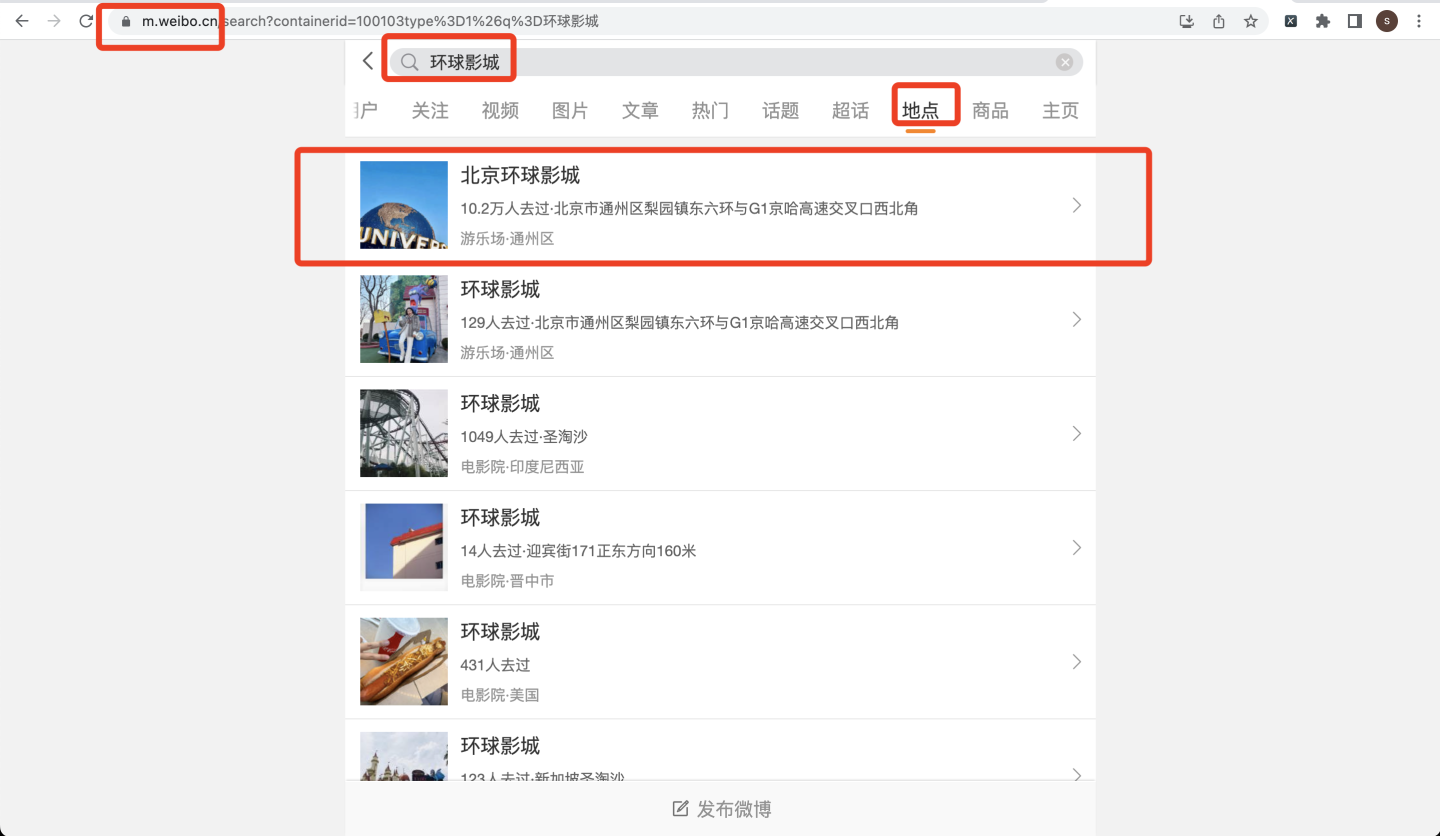
获取地点对应的containerid,后面会用到,爬虫代码如下:
def get_containerid(v_loc):
"""
获取地点对应的containerid
:param v_loc: 地点
:return: containerid
"""
url = 'https://m.weibo.cn/api/container/getIndex'
# 请求参数
params = {
"containerid": "100103type=92&q={}&t=".format(v_loc),
"page_type": "searchall",
}
r = requests.get(url, headers=headers, params=params)
cards = r.json()["data"]["cards"]
scheme = cards[0]['card_group'][0]['scheme'] # 取第一个
containerid = re.findall(r'containerid=(.*?)&', scheme)[0]
print('[{}]对应的containerid是:{}'.format(v_loc, containerid))
return containerid
点击第一个地点"北京环球影城",跳转到它对应的微博签到页面: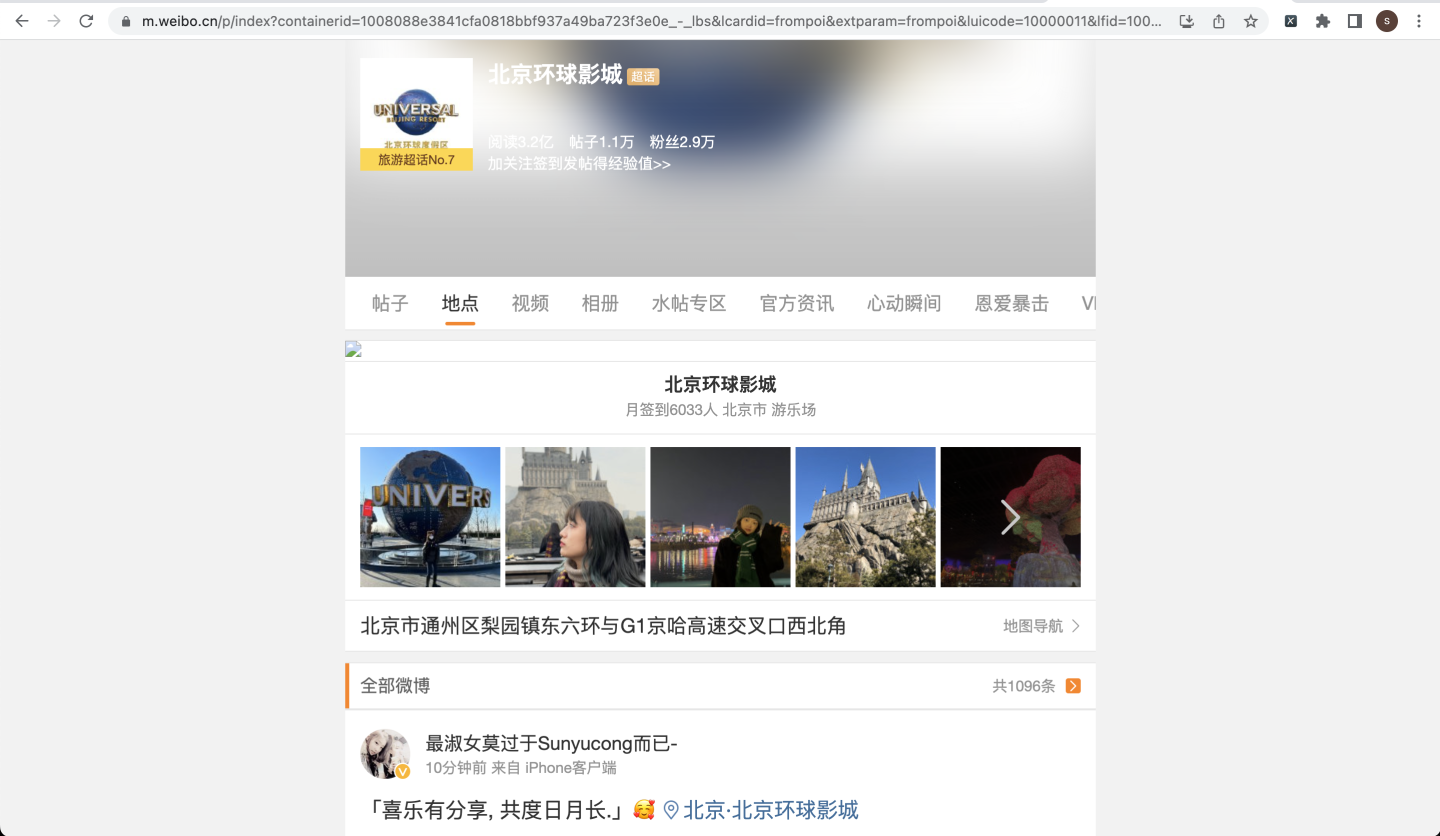
首先打开开发者模式,然后往下翻页,多翻几次,观察XHR页面的网络请求: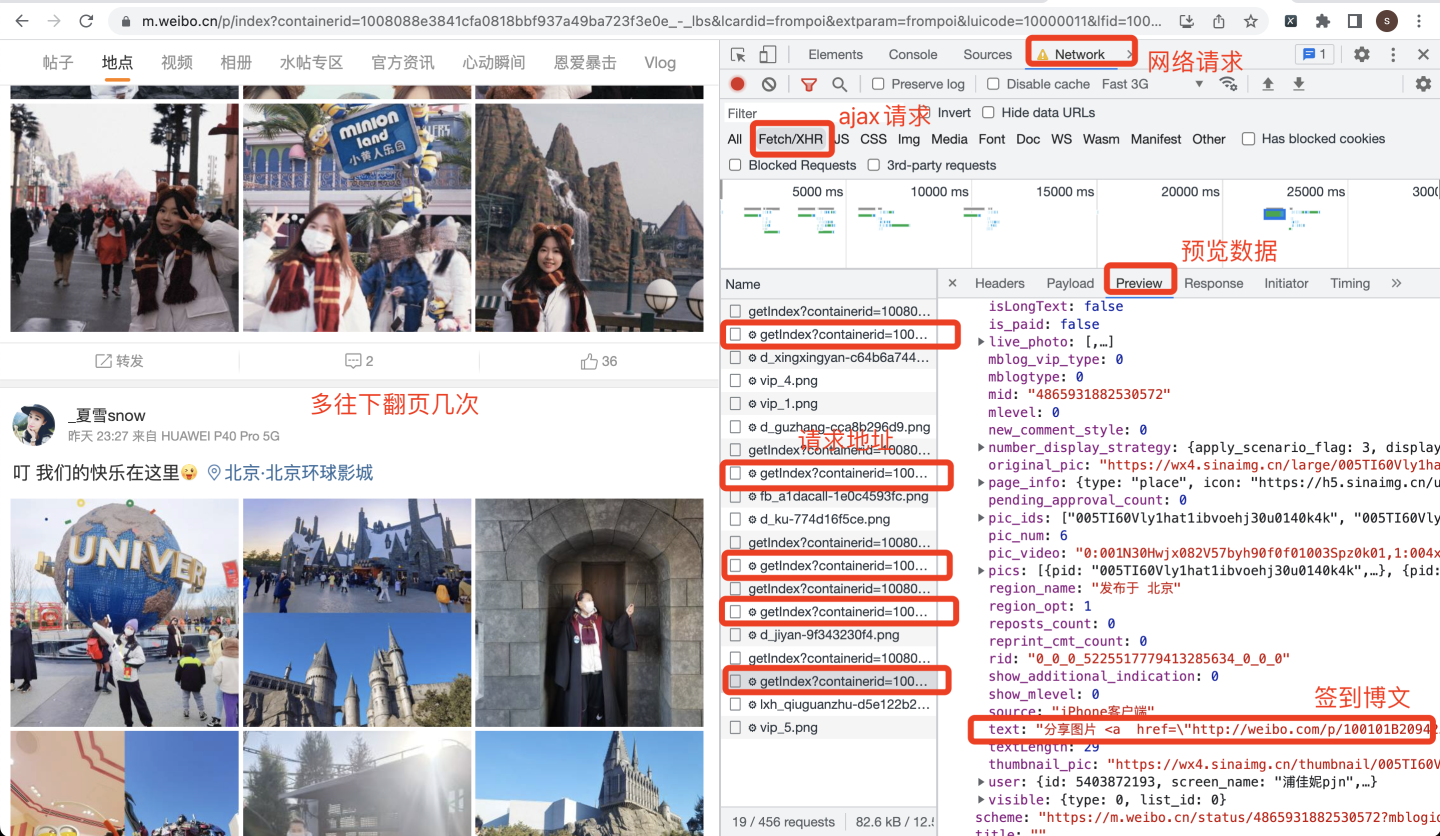
根据分析结果,编写请求代码:
# 请求地址
url = 'https://m.weibo.cn/api/container/getIndex'
# 请求参数
params = {
"containerid": containerid,
"luicode": "10000011",
"lcardid": "frompoi",
"extparam": "frompoi",
"lfid": "100103type=92&q={}".format(v_keyword),
"since_id": page,
}
其中,since_id每次翻页+1,相当于页码数值。
请求参数,可以在Payload页面获取: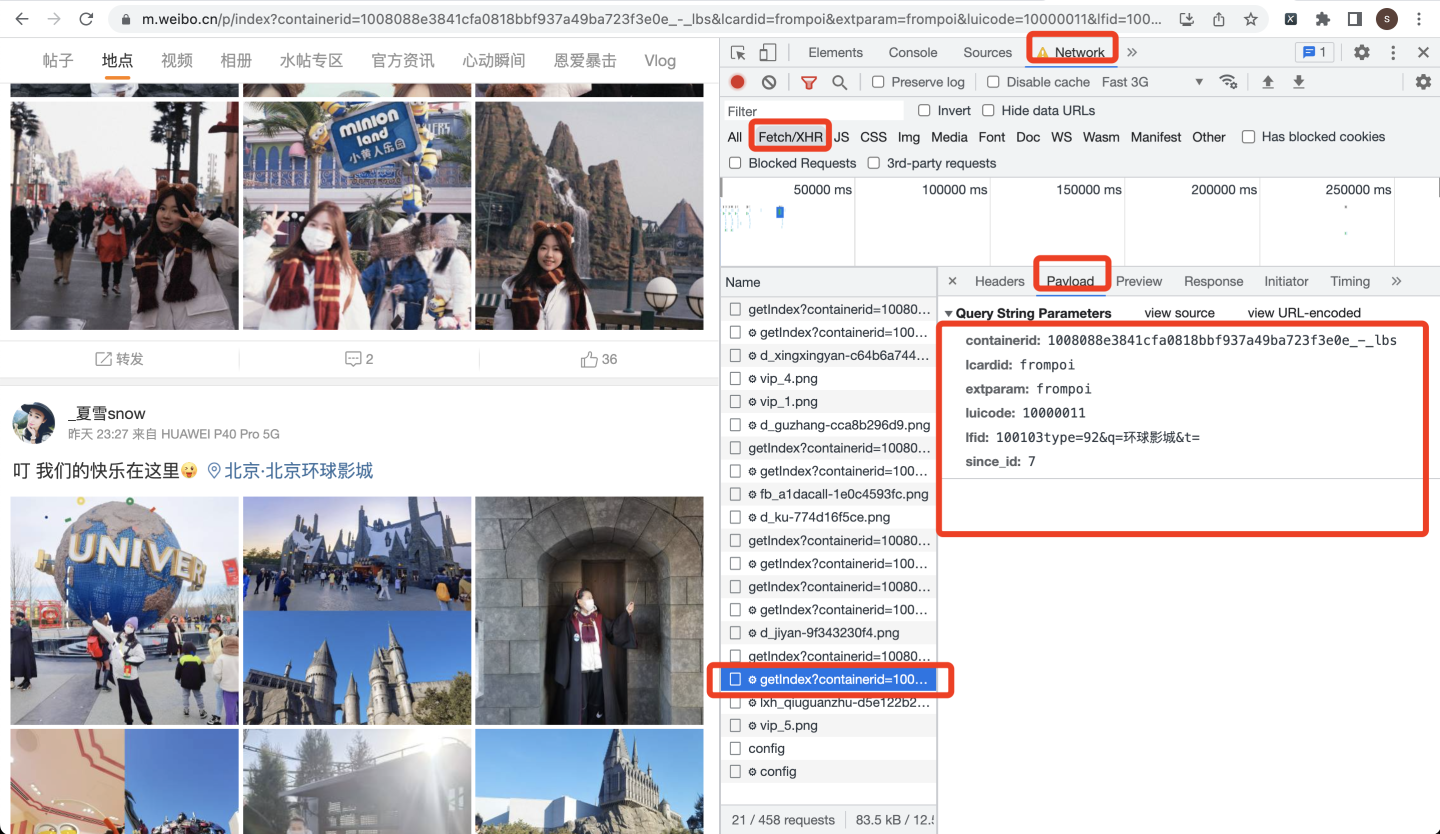
下面开始发送请求并解析数据:
# 发送请求
r = requests.get(url, headers=headers, params=params)
print(r.status_code) # 查看响应码
# 解析json数据
try:
card_group = r.json()["data"]["cards"][0]['card_group']
except:
card_group = []
定义一些空列表,用于后续保存数据:
time_list = [] # 创建时间
author_list = [] # 微博作者
id_list = [] # 微博id
bid_list = [] # 微博bid
text_list = [] # 博文
text2_list = [] # 博文2
loc_list = [] # 签到地点
reposts_count_list = [] # 转发数
comments_count_list = [] # 评论数
attitudes_count_list = [] # 点赞数
以"微博博文"为例,展示代码,其他字段同理,不再赘述。
# 微博博文
text = card['mblog']['text']
text_list.append(text)
把所有数据保存到Dataframe里面:
# 把列表数据保存成DataFrame数据
df = pd.DataFrame(
{
'页码': page,
'微博id': id_list,
'微博bid': bid_list,
'微博作者': author_list,
'发布时间': time_list,
'微博内容': text2_list,
'签到地点': loc_list,
'转发数': reposts_count_list,
'评论数': comments_count_list,
'点赞数': attitudes_count_list,
}
)
最终,把所有数据保存到csv文件:
# 表头
if os.path.exists(v_weibo_file):
header = False
else:
header = True
# 保存到csv文件
df.to_csv(v_weibo_file, mode='a+', index=False, header=header, encoding='utf_8_sig')
print('csv保存成功:{}'.format(v_weibo_file)))
说明一下,由于每次保存csv都是追加模式(mode='a+'),所以加上if判断逻辑:
- 如果csv存在,说明不是第一次保存csv,不加表头;
- 如果csv不存在,说明是第一次保存csv,加上表头。
如此,可避免写入多次表头的尴尬局面。
整个代码中,还含有:正则表达式提取博文、爬取展开全文、从博文中提取签到地点、数据清洗(删除空数据、去重复)等功能,详细请见原始代码。
四、同步视频
代码演示视频:https://www.zhihu.com/zvideo/1605933587244658688
五、附完整源码
完整源码:【python爬虫案例】爬了上千条m端微博签到数据
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:【2023微博签到爬虫】用python爬上千条m端微博签到数据 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 