摘要:先介绍条形图直方图,然后用随机数生成一系列数据,保存到列表中,最后统计出相关随机数据的概率并展示
前述介绍了由点进行划线形成的拆线图和散点形成的曲线图,连点成线,主要用到了matplotlib中的plot()和scatter()这个函数,但在实际生活工作中,不仅有折线图,还经常会出现月份经济数据对比图,身高统计图等,制成图表就很容易对比看出差异。
下面用matplotlib中bar()函数和hist()来实现条形图和直方图。
一、bar()函数
bar()函数的最主要的几个参数如下:
bar(x, height, width=0.8, bottom=None, *, align='center', data=None, **kwargs)
参数1:x : 标量型,x轴上的坐标。浮点数或类数组结构。注意x可以为字符串数组
参数2:height:y轴上的坐标。浮点数或类数组结构
参数3:width:指定柱形图的宽度。浮点数或类数组结构。默认值为0.8
参数4:bottom:标量或标量类数组型,y坐标的起始高度
参数5:align:柱状图在x轴上的对齐方式,可选{‘center’, ‘edge’} center:中心对称 edge:边缘对称
参数6:**kwargs:接收的关键字参数传递给关联的Rectangle。 返回值:BarContainer实例,其patches属性是柱体的列表
条形图(柱状图)一个简单的示例,随便设置12个月份,并给定某些数据,代码如下:
plt.bar([1,2,3,4,5,6,7,8,9,10,11,12,13],[5,2,7,8,2,1,8,6,2,5,6,7,10], label="Test one", color='red') #x位置上数列[1,2,3,4,5,6,7,8,9,10,11,12,13],表示为相对y轴,柱状图在X轴的位置,后面一列为对应y轴的高度。
plt.legend() #运行结果里图例名称显示出来
plt.xlabel('bar number')
plt.ylabel('bar height')
plt.title('TEST')
plt.show()
第一行中的color=‘red’表示柱状图全部显示为红,为显示区别,做以下修改:
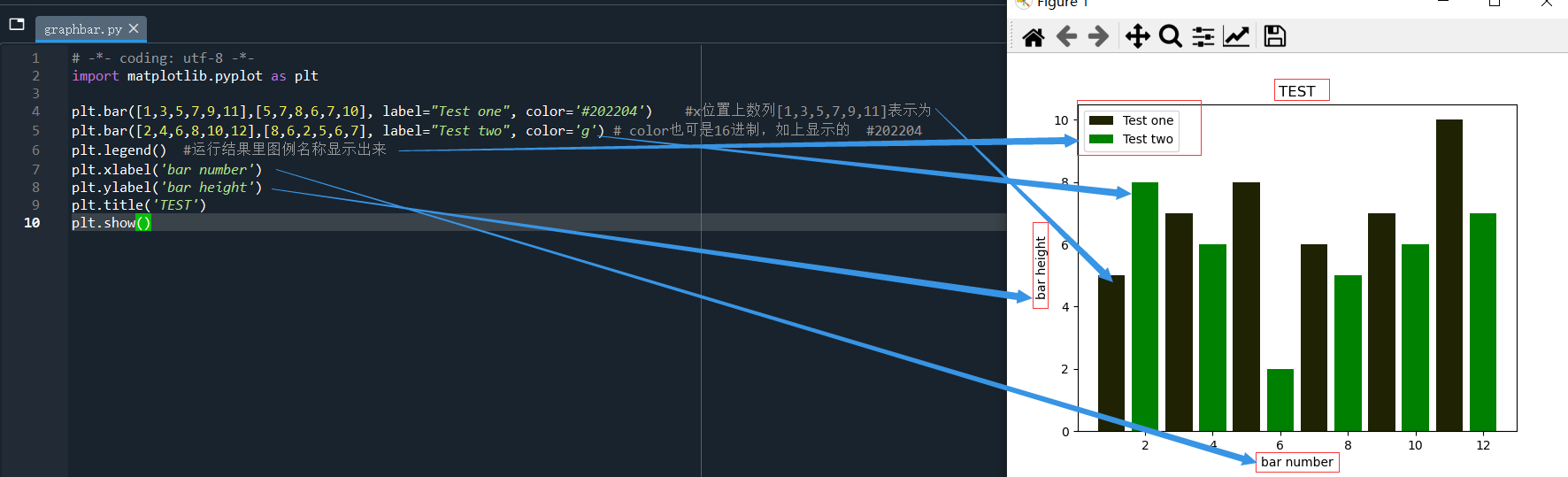
import matplotlib.pyplot as plt plt.bar([1,3,5,7,9,11],[5,7,8,6,7,10], label="Test one", color='#202204') plt.bar([2,4,6,8,10,12],[8,6,2,5,6,7], label="Test two", color='g') # color也可是16进制,如上显示的 #202204 plt.legend() #运行结果里图例名称显示出来 plt.xlabel('bar number') plt.ylabel('bar height') plt.title('TEST') plt.show()
具体显示结果如下:

二,hist()函数
hist(x,bins=None,range=None,density=None,weights=None,cumulative=False,bottom=None,histtype=“bar”, align=“mid”,orientation=“vertical”,rwidth=None,log=False,color=None,label=None,stacked=False,normed=None, hold=None,data=None,**kwargs)
hist()函数的基础参数如下:
x :表示输入值,可以是单个数组,或者不需要相同长度的数组序列。
bins:表示绘制条柱的个数。若给定一个整数,则返回 “bins+1” 个条柱,默认为10。
range:bins的上下范围(最大和最小值)。
color:表示条柱的颜色,默认为None。
facecolor #直方图颜色
edgecolor #直方图边框颜色
alpha # 透明度
histtype #直方图类型,‘bar’, ‘barstacked’, ‘step’, ‘stepfilled’
orientation # 水平或垂直方向
rwidth #柱子与柱子之间的距离,默认是0
下面通过一个例子来说明hist()函数的作用:
import matplotlib.pyplot as plt population_ages = [18,34,23,56,32,45,78,23,45,12,31,25,61,27,34,57,54,26,45,37,36,8,14,17,13,88,99,49,63,105,121,116] #设定一组年龄 bins = [0,10,20,30,40,50,60,80,90,100,130] #年龄分段 plt.hist(population_ages, bins, histtype='bar', rwidth=0.8,color='#199209') plt.xlabel('The Age Group') plt.ylabel('The number') plt.title('The Age Range') plt.legend() plt.show()
注意:bins[]中60,80和100,130中间缺少是故意为之,见下实际运行图中的差别
运行结果如下:

很明显,hist()函数会自动根据参数bins中的区分将参数x中的数据自动进行统计。
搞事情,既然参数x(如例子中的population_ages)可能是数列,那能否用随机函数自动生成数组,然后在进行统计呢?当然可以。
三、数据统计
色子经常用来娱乐(用作他途造成后果与我无关),它有6个面,分别点数为1,2,3,4,5,6,可利用随机函数(上篇中的choice函数)来随机产生,比如choice([1,2,3,4,5,6]),产生N次(比如20万次)并将每次结果保存到列表中,最后统计出各点的总数或所点比例。
分析:
1)先建一个类,其功能就是运行一次,就随机选择6个面(点数)
2)将色子实例化,并给定一个参数(运行的次数),图形化显示出来。
class Sezi(): def __init__(self,sides):#给自身定义一个面数,方便后面修改参数进行其他操作 self.sides = sides #色子可以是6面,也可以是8面,10面,12面,需要给定 def roll(self): return choice([1,2,3,4,5,6])#每投一次,随机选择一个点数 testsezi = Sezi(6) #实例化,6个面 results = [] # 定义一个空的数列,用来保存每次投掷的点数 for roll_num in range(100): #循环,投100次 result = testsezi.roll() #将每次投掷结果保存到变量result中 results.append(result) #存入到数列results print(results) #直接打印出来
运行结果:

与此同时,为了后面方便,引入另一个随机函数randint(x, y),这个函数的作用是产生x-y之间的数字,比如randint(1,10),就产生1到10之间的数字。
choice([1,2,3,4,5,6])可以修改为randint(1,self.sides),这样实例化后,需要输入随意一个面数,就会随机产生对应的数字。
上述还只是打印在交互栏,且类、实例还是在一个文件中,分成不同的文件,并数据统计用图的形式显示。
1,重新修改色子类
文件名sezi.py,里面代码如下:
from random import * class Sezi(): def __init__(self,sides):#给自身定义一个面数,面数对应点数 self.sides = sides #色子可以是6面,也可以是8面,10面,12面,需要给定 self.side=0 self.bins=[] while self.side < self.sides: #获取面数,并得到一个面数的bins,可直接调用。 self.side += 1 self.bins.append(self.side) def roll(self): return randint(1,self.sides)#每投一次,随机选择一个点数
2、新建一个名称sezigame.py的文件,代码如下
import matplotlib.pyplot as plt from sezi import * testsezi = Sezi(8) #实例化,8个点 results = [] # 定义一个空的数列,用来保存每次投掷的点数 for roll_num in range(50000): #循环,投50000次 result = testsezi.roll() #将每次投掷结果保存到变量result中 results.append(result) #存入到数列results plt.hist(results, testsezi.bins, histtype='bar', rwidth=0.8,color='#199209') #直接调用testsezi.bins
运行结果:

如果有2个相同的色子呢?
同时掷两个骰子,最小为2,最大为12,结果分布情况自然也就不同。
将名称sezigame.py的文件修改,改动后的代码如下:
import matplotlib.pyplot as plt from sezi import * sezi_1 = Sezi(6) #实例化,6个面 sezi_2 = Sezi(6) results = [] # 定义一个空的数列,用来保存每次投掷的点数 for roll_num in range(50000): #循环,投50000次 result = sezi_1.roll()+sezi_2.roll() #将两次投掷结果保存到变量result中 results.append(result) #存入到数列results max_result = sezi_1.sides+sezi_2.sides #2个最大值为12,最小为2 side = 0 new_bins = [] while side <= max_result: side += 1 new_bins.append(side) plt.xlabel('The sides') plt.ylabel('The numbers') plt.title('The frequency') plt.hist(results,new_bins, histtype='bar',color='#199209',rwidth=0.618)
运行结果如下:

是不是有点正态分布的感觉了?
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:python数据可视化-matplotlib入门(4)-条形图和直方图 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 