为了更好的阅读体验,请点击这里
4.1 多层感知机
4.1.1 隐藏层
由于仿射变换中的线性是一个很强的假设,因此导致了线性模型可能会不适用。线性意味着单调假设:任何特征的增大都会导致模型输出的增大或者模型输出的减小。
但是违反单调性的例子比比皆是。除此之外,分类任务中,仅依托像素强度分类也很不合理。由于任何像素的重要性都以复杂的方式取决于该像素周围的值。对于深度神经网络,用观测数据来联合学习隐藏层表示和应用于该表示的线性预测器。
因此可以在网络中加入隐藏层。把前 \(L-1\) 层看作表示,把最后一层看作线性预测器。这种架构通常称为多层感知机。但是具有全连接层的多层感知机的参数开销可能太过巨大。
用矩阵 \(\boldsymbol{X} \in \mathbb{R}^{n\times d}\) 来表示有 \(n\) 个样本的小批量,其中每个样本具有 \(d\) 个输入特征。对于具有 \(h\) 个隐藏单元的单隐藏层多层感知机,用 \(\boldsymbol{H} \in \mathbb{R}^{n\times h}\) 表示隐藏层的输出,称为隐藏表示(hidden representation)。在数学或代码中,\(\boldsymbol{H}\) 也称为隐藏层变量(hidden layer variable)或隐藏变量(hidden variable)。不妨设当前有一个一层隐藏层以及一层输出层的网络,由于隐藏层和输出层都是全连接的,所以我们有隐藏层权重 \(\boldsymbol{W}^{(1)} \in \mathbb{R}^{d \times h}\) 和隐藏层偏置 \(\boldsymbol{b}^{(1)} \in \mathbb{R}^{1 \times h}\) 以及输出层权重 \(\boldsymbol{W}^{(2)} \in \mathbb{R}^{h \times q}\) 和输出层偏置 \(\boldsymbol{b}^{(2)} \in \mathbb{R}^{1 \times q}\)。形式上,我们按如下方式计算单隐藏层多层感知机的输出 \(\boldsymbol{O} \in \mathbb{R}^{n \times q}\):
\boldsymbol{H} &= \boldsymbol{XW}^{(1)} + \boldsymbol{b}^{(1)} \\
\boldsymbol{O} &= \boldsymbol{HW}^{(2)} + \boldsymbol{b}^{(2)}
\end{align}
\]
注意,上述模型本质上和单个线性层相同。原因在于:
\]
所以,如果要搞多层架构的话,必须在仿射变换之后对每个隐藏单元应用非线性的激活函数(activation function)\(\sigma\)。激活函数的输出(例如,\(\sigma(\cdot)\))称为激活值(activation)。这样就不会再退化到线性模型了,所以有:
\boldsymbol{H} &= \sigma(\boldsymbol{XW}^{(1)} + \boldsymbol{b}^{(1)}) \\
\boldsymbol{O} &= \boldsymbol{HW}^{(2)} + \boldsymbol{b}^{(2)}
\end{align}
\]
出于记号习惯的考量,我们定义非线性函数 \(\sigma\) 也以按行的方式作用于其输入,即一次计算一个样本。构建多层感知机,可以继续堆叠这样的隐藏层。
多层感知机可以通过隐藏神经元,捕捉到输入之间复杂的相互作用,这些神经元依赖于每个输入的值。我们可以很容易地设计隐藏节点来执行任意计算。而且,虽然一个单隐层网络能学习任何函数,但并不意味着我们应该尝试使用单隐藏层网络来解决所有问题。事实上,通过使用更深(而不是更广)的网络,可以更容易地逼近许多函数。
4.1.2 激活函数
1. ReLU
整流线性单元(rectified linear unit, ReLU)式子如下:
\]
ReLU 函数通过将相应的激活值设为 \(0\),仅保留正元素并丢弃所有负元素。
这里代码在画图的时候很有趣,如下:
x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True)
y = torch.relu(x)
d2l.plot(x.detach(), y.detach(), 'x', 'relu(x)', figsize=(5, 2.5))
在 y.detach() 那里修改为 y.data 也可以过编译,原因是 pyplot.plot(x,y) 函数中的 x,y 需要用两个 numpy 类型的变量,而 tensor 变量如果有梯度/梯度追踪,那么无法转换成 numpy 类型的变量。如果这里是两个没有梯度/梯度追踪的 tensor 变量,则会被类型转化成 numpy 类型。
ReLU 函数的导数如下:
0,& x<0 \\
0~或者~不可导,&x=0 \\
1,& x>0
\end{cases}
\]
当输入值精确等于 \(0\) 时,ReLU 函数不可导。此时,默认使用左边的导数,即当输入为 \(0\) 时,导数为 \(0\)。原书中说,可以忽略这种情况,因为输入可能永远都不会是 \(0\)。
使用 ReLU 的原因是其求导表现特别好:要么让参数消失,要么让参数通过。这使得优化表现得更好,并且ReLU减轻了困扰以往神经网络的梯度消失问题。
也有一些变体,比如参数化 ReLU(parameterized ReLU, pReLU)函数,该变体为 ReLU 添加了一个线性项,因此即使参数是负的,某些信息仍然可以通过:
\]
2. sigmoid 函数
对于一个定义域在 \(\mathbb{R}\) 中的输入,sigmoid 函数将输入变换为区间 \((0,1)\) 上的输出。因此,sigmoid 通常称为挤压函数(squashing function):它将范围 \((-\infin, \infin)\) 中的任意输入压缩到区间 \((0,1)\) 中的某个值:
\]
sigmoid 函数是一个平滑的、可微的阈值单元近似。
它的导数为:
\]
当输入为 \(0\) 时,sigmoid 函数的导数达到最大值 \(0.25\); 而输入在任一方向上越远离 \(0\) 点时,导数越接近 \(0\)。
3. tanh 函数
与 sigmoid 函数类似,tanh(双曲正切)函数也能将其输入压缩转换到区间 \((-1,1)\) 上。tanh函数的公式如下:
\]
当输入在 \(0\) 附近时,tanh 函数接近线性变换。函数的形状类似于 sigmoid 函数,不同的是 tanh 函数关于坐标系原点中心对称。
tanh 函数的导数是:
\]
当输入接近 \(0\) 时,tanh 函数的导数接近最大值 \(1\)。输入在任一方向上越远离 \(0\) 点,导数越接近 \(0\)。
课后题
第四道课后题有点意思,因为我没看懂题意。在英文原书的网址 MLP 中,我发现原问题是这么问的:
Assume that we have a nonlinearity that applies to one minibatch at a time, such as the batch normalization (Ioffe and Szegedy, 2015). What kinds of problems do you expect this to cause?
引用别人的答案:数据可能会被剧烈地拉伸或者压缩,可能会导致分布的偏移,并且与后面的神经元对接后可能会损失一定的特征。
4.2 多层感知机的从零开始实现
这里结合 PyTorch 的 optimizer 和自己的参数的方法很有趣。
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = nn.Parameter(torch.randn(num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
这里是把 nn.Parameter 类打包成一个 list 丢进 SGD 的参数中。
另外在 numpy 或者是 PyTorch 中,可以用 @ 来表示矩阵乘法。
练习(6):如果想要构建多个超参数的搜索方法,请设计一个聪明的策略:
- 手调(Babysitting)
- 网格搜索(Grid Search)
- 随机搜索(Random Search)
4.4 模型选择、欠拟合和过拟合
机器学习的目标是发现模式(pattern)。更正式地说,我们的目标是发现某些模式,这些模式捕捉到了我们训练集潜在总体的规律。如果成功做到了这点,即使是对以前从未遇到过的个体,模型也可以成功地评估风险。如何发现可以泛化的模式是机器学习的根本问题。
困难在于,当我们训练模型时,我们只能访问数据中的小部分样本。当我们使用有限的样本时,可能会遇到这样的问题: 当收集到更多的数据时,会发现之前找到的明显关系并不成立。
将模型在训练数据上拟合的比在潜在分布中更接近的现象称为过拟合(overfitting),用于对抗过拟合的技术称为正则化(regularization)。
4.4.1 训练误差和泛化误差
训练误差(training error)是指模型在训练数据集上计算得到的误差。泛化误差(generalization error)是指,模型应用在同样从原始样本的分布中抽取的无限多数据样本时,模型误差的期望。问题是,我们永远不能准确地计算出泛化误差。这是因为无限多的数据样本是一个虚构的对象。在实际中,我们只能通过将模型应用于一个独立的测试集来估计泛化误差,该测试集由随机选取的、未曾在训练集中出现的数据样本构成。
假设训练数据和测试数据都是从相同的分布中独立提取的。这通常被称为独立同分布假设(i.i.d. assumption),这意味着对数据进行采样的过程没有进行“记忆”。有时候我们即使轻微违背独立同分布假设,模型仍将继续运行得非常好。但同时有些违背独立同分布假设的行为肯定会带来麻烦。
一个模型是否能很好地泛化取决于很多因素。有以下几个倾向于影响模型泛化的因素:
- 可调整参数的数量。当可调整参数的数量(有时称为自由度)很大时,模型往往更容易过拟合。
- 参数采用的值。当权重的取值范围较大时,模型可能更容易过拟合。
- 训练样本的数量。即使模型很简单,也很容易过拟合只包含一两个样本的数据集。而过拟合一个有数百万个样本的数据集则需要一个极其灵活的模型。
4.4.2 模型选择
为了确定候选模型中的最佳模型,我们通常会使用验证集。不能依靠测试数据进行模型选择。然而,我们也不能仅仅依靠训练数据来选择模型,因为我们无法估计训练数据的泛化误差。
解决此问题的常见做法是将我们的数据分成三份,除了训练和测试数据集之外,还增加一个验证数据集(validation dataset),也叫验证集(validation set)。书中每次实验报告的准确度都是验证集准确度,而不是测试集准确度。
也可以用 K 折交叉验证。原始训练数据被分成 \(K\) 个不重叠的子集。然后执行 \(K\) 次模型训练和验证,每次在 \(K−1\) 个子集上进行训练,并在剩余的一个子集(在该轮中没有用于训练的子集)上进行验证。最后,通过对 \(K\) 次实验的结果取平均来估计训练和验证误差。
但是这会带来一个问题,不存在平均误差方差的无偏估计。于是通常会用近似来解决。
4.4.3 欠拟合还是过拟合
训练误差和验证误差都很严重,但它们之间仅有一点差距。如果模型不能降低训练误差,这可能意味着模型过于简单(即表达能力不足),无法捕获试图学习的模式。此外,由于我们的训练和验证误差之间的泛化误差很小,我们有理由相信可以用一个更复杂的模型降低训练误差。这种现象被称为欠拟合(underfitting)。
另一方面,当我们的训练误差明显低于验证误差时要小心,这表明严重的过拟合(overfitting)。
是否过拟合或欠拟合可能取决于模型复杂性和可用训练数据集的大小。
4.4.4 多项式拟合
作者用拟合一个多项式的方式来作为示范。当参数量等于原本的数据分布的参数量时拟合函数正常。但是如果模型参数量较少会发生欠拟合,而模型参数量过大会发生过拟合。
课后题(部分)
(1)多项式回归问题可以准确地解出吗?
直接高斯消元,或者参考前面解方程。
(2)绘制训练损失与模型复杂度(多项式的阶数)的关系图。观察到了什么?需要多少阶的多项式才能将训练损失减少到0?
animator = d2l.Animator(xlabel='degree', ylabel='loss', yscale='log', xlim=[1, max_degree], ylim=[1e-3, 1e2], legend=['train', 'test'])
for i in range(max_degree):
p = train_parameter(poly_features[:n_train, :i], poly_features[n_train:, :i], labels[:n_train], labels[n_train:])
animator.add(i + 1, p)
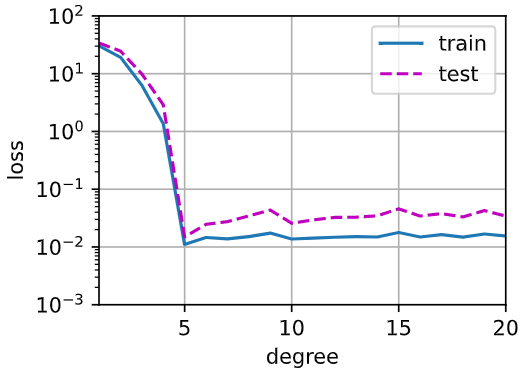
训练损失无法减少到 0.
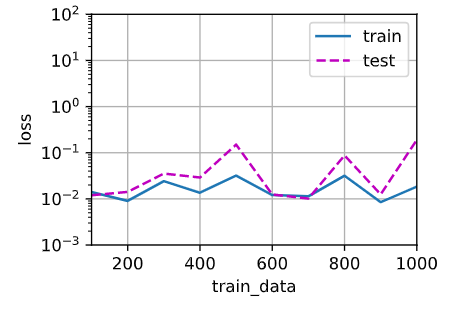
数据量那个图,取度数为 \(4\),在代码中体现为 \(5\)。只能说是毫无规律:
animator = d2l.Animator(xlabel='train_data', ylabel='loss', yscale='log', xlim=[100, 1000],
ylim=[1e-3, 1e2], legend=['train', 'test'])
for i in range(10):
poly_features, labels = getData((i+1) * 100)
p = train_parameter(poly_features[:n_train, :5], poly_features[n_train:, :5], labels[:n_train], labels[n_train:])
animator.add((i + 1)*100, p)
(3)如果不对多项式特征 \(x^i\) 进行标准化 \((1/i!)\) ,会出现什么问题?能用其他方法解决这个问题吗?
如果有一个 \(x\) 大于 \(1\),那么这个很大的 \(i\) 就会带来很大的值,优化的时候可能会带来很大的梯度值。
(4)泛化误差可能为零吗?
几乎不可能。
4.5 权重衰减(weight decay)
单项式(monomial)是多项式对多变量数据的自然扩展,也可以说是变量的幂的乘积。给定 \(k\) 个变量,阶数 \(d\)(即选 \(k\) 个自然数的加和为 \(d\)),则共有 \(\begin{pmatrix} k-1+d \\ d-1\end{pmatrix}\) 种单项式。因此对于多变量数据在多项式上的扩展,需要更细粒度的工具来调整函数复杂度。
4.5.1 范数与权重衰减
权重衰减是使用最广泛的正则化技术之一,它通常也称为 \(L_2\) 正则化。这个技术通过函数与零的距离来度量函数的复杂度。要保证权重向量比较小,最常用方法是将其范数作为惩罚项加到最小化损失的问题中,将原来的训练目标最小化训练标签上的预测损失,调整为最小化预测损失和惩罚项之和。
上一章种线性回归例子的损失为:
\]
那么,可以通过正则化常数 \(\lambda\) 来描述这种权衡,这是一个非负超参数,我们使用验证数据拟合:
\]
原书中关于这部分函数的设计原因写的很详细:
对于 \(\lambda=0\),我们恢复了原来的损失函数。对于 \(\lambda>0\),我们限制 \(\|\boldsymbol{w}\|\) 的大小。这里我们仍然除以 \(2\),当我们取一个二次函数的导数时,\(2\) 和 \(\frac{1}{2}\) 会抵消,以确保更新表达式看起来既漂亮又简单。为什么在这里我们使用平方范数而不是标准范数(即欧几里得距离)?这样做是为了便于计算。通过平方 \(L_2\) 范数,我们去掉平方根,留下权重向量每个分量的平方和,这使得惩罚的导数很容易计算:导数的和等于和的导数。
此外,为什么我们首先使用 \(L_2\) 范数,而不是 \(L_1\) 范数。事实上,这个选择在整个统计领域中都是有效的和受欢迎的。\(L_2\) 正则化线性模型构成经典的岭回归(ridge regression)算法,\(L_1\) 正则化线性回归是统计学中类似的基本模型,通常被称为套索回归(lasso regression)。使用 \(L_2\) 范数的一个原因是它对权重向量的大分量施加了巨大的惩罚。这使得我们的学习算法偏向于在大量特征上均匀分布权重的模型。在实践中,这可能使它们对单个变量中的观测误差更为稳定。相比之下,\(L_1\) 惩罚会导致模型将权重集中在一小部分特征上,而将其他权重清除为零。这称为特征选择(feature selection),这可能是其他场景下需要的。
那么 \(L_2\) 正则化回归的小批量随机梯度下降更新如下式:
\]
根据之前章节,我们根据估计值与观测值之间的差异来更新 \(\boldsymbol{w}\)。然而,我们同时也在试图将 \(\boldsymbol{w}\) 的大小缩小到零。这就是为什么这种方法有时被称为权重衰减。我们仅考虑惩罚项,优化算法在训练的每一步衰减权重。与特征选择相比,权重衰减为我们提供了一种连续的机制来调整函数的复杂度。较小的 \(\lambda\) 值对应较少约束的 \(\boldsymbol{w}\),而较大的 \(\lambda\) 值对 \(\boldsymbol{w}\) 的约束更大。
是否对相应的偏置 \(b^2\) 进行惩罚在不同的实践中会有所不同,在神经网络的不同层中也会有所不同。通常,网络输出层的偏置项不会被正则化。
4.5.3 从零开始实现(有趣的 optim)
这一节中出现了很有趣的 Optimizer 的写法,原文是给权重设置了权重衰减,而偏置没有设置权重衰减。具体代码如下:
trainer = torch.optim.SGD([{"params": net[0].weight, 'weight_decay': wd},
{"params": net[0].bias}], lr=lr)
下面简单写一下 PyTorch 原文档中的有趣用法。
逐个参数优化方法
Optimizer 也支持逐个参数优化的选项。这里传入的不再是 Variable(或者说是 Tensor)的一个可迭代对象,取而代之的是传入 dict 的可迭代对象(事实上,Optimizer 中也只能传入这两个的可迭代对象)。它们中的每一个会定义一个分离的参数组。组中应当有一个包含了参数列表的 param 键,其他键应当匹配能够被 Optimizer 接受的参数。
当然,与此同时也仍然可以在外面写其他默认参数,这不会覆盖掉参数组里面的参数。
官网中给出了这样一个例子:
optim.SGD([
{'params': model.base.parameters()},
{'params': model.classifier.parameters(), 'lr': 1e-3}
], lr=1e-2, momentum=0.9)
这意味着 model.base 的参数会使用默认学习率 1e-2。model.classifier 的参数会使用 1e-3。动量 0.9 将会应用于所有参数。
课后题
(1)绘制训练精度和测试精度关于 \(\lambda\) 的函数图,可以观察到什么?
def train_concise_many_times(max_wd):
animator = d2l.Animator(xlabel = 'wd', ylabel = 'loss', yscale='log', xlim=[1, max_wd], legend=['train', 'test'])
for wd in range(max_wd):
net = nn.Sequential(nn.Linear(num_inputs, 1))
for param in net.parameters():
param.data.normal_()
loss = nn.MSELoss(reduction='none')
num_epochs, lr = 100, 0.003
trainer = torch.optim.SGD([{"params": net[0].weight, 'weight_decay': wd},
{"params": net[0].bias}], lr=lr)
for epoch in range(num_epochs):
for X, y in train_iter:
trainer.zero_grad()
l = loss(net(X), y)
l.mean().backward()
trainer.step()
animator.add(wd + 1, (d2l.evaluate_loss(net, train_iter, loss), d2l.evaluate_loss(net, test_iter, loss)))
train_concise_many_times(10)
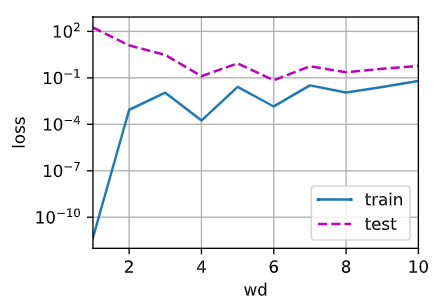
可以观察到随着 \(\lambda\) 增加,训练 loss 增大,测试 loss 在 \(\lambda=4\) 的时候达到最小,然后趋于平稳。
(2)使用验证集来找到最优值 \(\lambda\),它真的是最优值吗?
不一定,如果验证集与测试集满足独立同分布,那么最优。
(3)如果使用 \(\sum_i |w_i|\) 作为惩罚(\(L_1\) 正则化),那么更新的公式长什么样子?
不妨设新的损失函数为:
\]
则,更新公式为:
w_i + \eta \lambda - \frac{\eta}{|B|} \left(\sum_{j \in B} \boldsymbol{x}^{(j)}(\boldsymbol{w}^T \boldsymbol{x}^{(j)} + b - y^{(j)}) \right)_i, &w_j < 0 \\
w_i - \eta \lambda - \frac{\eta}{|B|} \left(\sum_{j \in B} \boldsymbol{x}^{(j)}(\boldsymbol{w}^T \boldsymbol{x}^{(j)} + b - y^{(j)}) \right)_i, &w_j \ge 0
\end{cases}
\]
(4)已知 \(\|\boldsymbol{w}\|^2 = \boldsymbol{w}^T \boldsymbol{w}\)。能找到类似的矩阵方程吗?(提示:弗罗贝尼乌斯范数)
矩阵 \(X \in \mathbb{R}^{m \times n}\) 的 Frobenius norm 为:
\]
(5)处理过拟合的方法除了权重衰减、增加训练数据、使用适当复杂度的模型,还有哪些?
还有 dropout,提前终止等。
(6)在贝叶斯统计中,使用先验和似然的乘积,通过公式 \(P(w|x) \propto P(x|w)P(w)\) 得到后验。如何得到正则化的 \(P(w)\)?
这里题目显然有些奇怪,英文原文为:
In Bayesian statistics we use the product of prior and likelihood to arrive at a posterior via \(P(w∣x) \propto P(x∣w)P(w)\). How can you identify P(w) with regularization?
最后一句可以翻译为如何用正则化得到 \(P(w)\),也可以翻译为如何得到带有正则化的 \(P(w)\)。
优化 \(w\) 的过程本质上也是最大化后验概率 \(P(w|x)\) 的过程,也是最小化其负对数似然的过程,即:
\]
可以发现上式中 \(-\ln P(w)\) 就是正则化项了。如果要让 \(P(w|x)\) 尽量大,那么就应当让正则化项 \(P(w)\) 尽量大。
这样的话问题最好应当翻译成:如何得到带有与 \(P(w)\) 相关的正则化项。
4.6 暂退法(Dropout)
由于上一章的做法是假设了一个先验,即权重的值取自均值为 0 的高斯分布。这可能不是特别优雅。因此希望模型深度挖掘特征,即将其权重分散到许多特征中,而不是过于依赖少数潜在的虚假关联。
4.6.1 重新审视过拟合
线性模型没有考虑到特征之间的交互作用,换言之,每一个仅为一次项,没有交叉相乘的项。对于每个特征,线性模型必须指定正的或负的权重,而忽略其他特征。
泛化性和灵活性之间的这种基本权衡被描述为偏差-方差权衡(bias-variance tradeoff)。线性模型有很高的偏差:它们只能表示一小类函数。然而,这些模型的方差很低:它们在不同的随机数据样本上可以得出相似的结果。
神经网络并不局限于单独查看每个特征,而是学习特征之间的交互。但即使我们有比特征多得多的样本,深度神经网络也有可能过拟合。
4.6.2 扰动的稳健性
经典泛化理论认为,为了缩小训练和测试性能之间的差距,应该以简单的模型为目标。简单性以较小维度的形式展现。此外,参数的范数也代表了一种有用的简单性度量。简单性的另一个角度是平滑性,即函数不应该对其输入的微小变化敏感。1995年,克里斯托弗·毕晓普证明了 具有输入噪声的训练等价于Tikhonov正则化。这项工作用数学证实了“要求函数光滑”和“要求函数对输入的随机噪声具有适应性”之间确实存在联系。
Srivastava提出了暂退法(Dropout)。在训练过程中,他们建议在计算后续层之前向网络的每一层注入噪声。因为当训练一个有多层的深层网络时,注入噪声只会在输入-输出映射上增强平滑性。这种方法之所以被称为暂退法,因为从表面上看是在训练过程中丢弃(drop out)一些神经元。在整个训练过程的每一次迭代中,标准暂退法包括在计算下一层之前将当前层中的一些节点置零。
关键的挑战就是如何注入这种噪声。一种想法是以一种无偏差(unbiased)的方式注入噪声。这样在固定住其他层时,每一层的期望值等于没有噪音时的值。
-
在毕晓普的工作中,他将高斯噪声添加到线性模型的输入中。在每次训练迭代中,他将从均值为零的分布 \(\epsilon \sim N(0, \sigma^2)\) 采样噪声添加到输入 \(\boldsymbol{x}\),从而产生扰动点 \(\boldsymbol{x}' = \boldsymbol{x} + \epsilon\),预期是 \(\mathbb{E}[\boldsymbol{x}']=\boldsymbol{x}\)。
-
在标准暂退法正则化中,通过按保留(未丢弃)的节点的分数进行规范化来消除每一层的偏差。换言之,每个中间活性值 \(h\) 以暂退概率 \(p\) 由随机变量 \(h'\) 替换,如下所示:
\[h' = \begin{cases}
0 &,\text{概率为 $p$} \\
\frac{h}{1-p} &,\text{其他情况}
\end{cases}
\]期望值保持不变,即 \(\mathbb{E}[h']=h\)。
4.6.3 实践中的暂退法
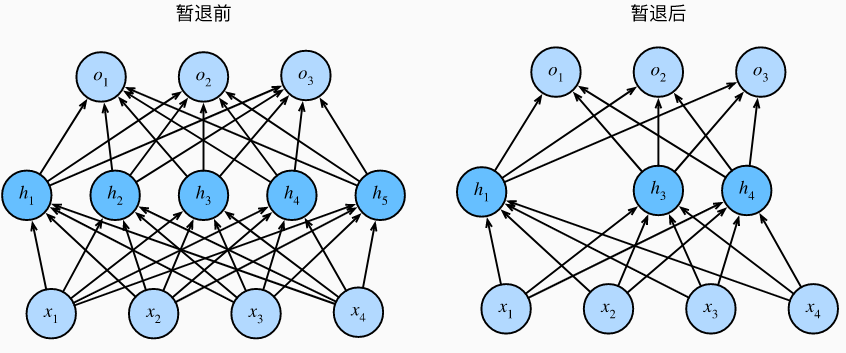
上图为 Dropout 前后的多层感知机。其中 Dropout 过程删除了 \(h_2\) 和 \(h_5\)。因此输出的计算不依赖 \(h_2\) 和 \(h_5\)。并且它们各自的梯度在执行反向传播时也会消失。这样,输出层的计算不能过度依赖于 \(h_1, h_2, \dots, h_5\) 的任何一个元素。
通常,我们在测试时不用暂退法。给定一个训练好的模型和一个新的样本,我们不会丢弃任何节点,因此不需要标准化。然而也有一些例外:一些研究人员在测试时使用暂退法,用于估计神经网络预测的“不确定性”:如果通过许多不同的暂退法遮盖后得到的预测结果都是一致的,那么我们可以说网络发挥更稳定。
代码中有个技巧是,在靠近输入层的地方设置较低的暂退概率。感性理解这个原因可能是,通过第一层后如果设置的暂退概率较高/跟之后的差不多的话,会导致通过线性层后丢掉靠近源数据的特征,进而导致数据中的部分内容被丢弃。
nn.Dropout(dropout_probability) 会在训练时,暂退层根据指定的暂退概率随机丢弃上一层的输出(相当于下一层的输入)。在测试时,暂退层仅传递数据。
此外,作者推荐的暂退概率为 \([0.2, 0.5]\) 之间。
课后题
(1)如果更改第一层和第二层的暂退概率,会出现什么问题?具体地说,如果交换这两个层,会出现什么问题?设计一个实验来回答这些问题,定量描述该结果,并总结定性的结论。
# 交换前
dropout1, dropout2 = 0.2, 0.5
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Dropout(dropout1),
nn.Linear(256, 256),
nn.ReLU(),
nn.Dropout(dropout2),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
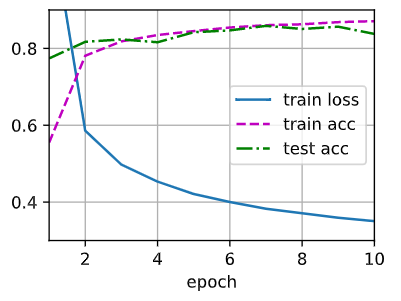
# 交换后
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Dropout(dropout2),
nn.Linear(256, 256),
nn.ReLU(),
nn.Dropout(dropout1),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
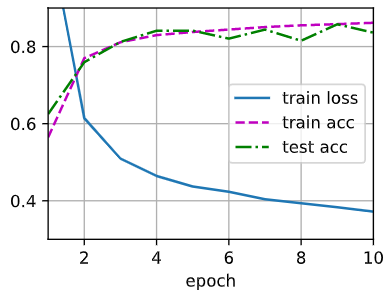
可以观察到仅仅有微小的差距。交换后的收敛速度变慢了一点点,而精度几乎没变化。译者在评论区说:
It may be hard to observe a huge loss/acc difference if the network is shallow and can converge quickly. As you can find in the original dropout paper (http://jmlr.org/papers/volume15/srivastava14a/srivastava14a.pdf) as well, the improvement with dropout on MNIST is less than 1%.
翻译过来大概意思是,当模型比较小很难观察到巨大的 loss/acc 的差别,并且它会快速收敛。原论文中也说,在 MNIST 上使用 dropout 的提升小于 1%。
(2)增加训练轮数,并将使用暂退法和不使用暂退法时获得的结果进行比较。
此处增大训练轮数到 20 轮。当每层中间有 Dropout 层时,代码如下:
num_epochs = 20
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Dropout(dropout1),
nn.Linear(256, 256),
nn.ReLU(),
nn.Dropout(dropout2),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
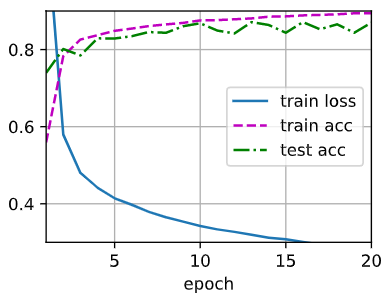
去掉中间的 Dropout 层时,代码如下:
num_epochs = 20
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
连续测了几次都发现,图像出现了突然的 loss/acc 爆炸。刚开始以为是 Kaggle 服务器的问题,再测了几把发现是真的会出这个问题。
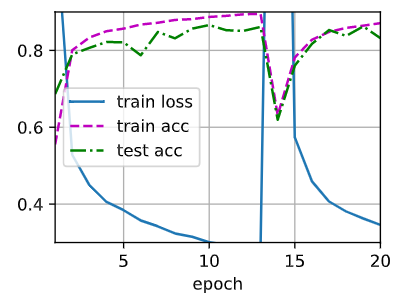
除去突然的 loss/acc 爆炸外,对比两张图,可以发现去掉 Dropout 层的时候拟合得更快。理论上讲,带有 dropout 的应当减少更多的泛化误差,但是这几张图片中可能确实有一点,但是实在看不太出来。
(3)当使用或不使用暂退法时,每个隐藏层中激活值的方差是多少?绘制一个曲线图,以展示这两个模型的每个隐藏层中激活值的方差是如何随时间变化的。
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
dropout1, dropout2 = 0.2, 0.5
class Net(nn.Module):
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2, is_training=True):
super(Net, self).__init__()
self.num_inputs = num_inputs
self.training = is_training
self.lin1 = nn.Linear(num_inputs, num_hiddens1)
self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)
self.lin3 = nn.Linear(num_hiddens2, num_outputs)
self.relu = nn.ReLU()
def forward(self, X):
H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))
if self.training == True:
H1 = dropout_layer(H1, dropout1)
d1 = torch.var(H1)
H2 = self.relu(self.lin2(H1))
if self.training == True:
H2 = dropout_layer(H2, dropout2)
d2 = torch.var(H2)
out = self.lin3(H2)
return out, d1, d2
def train_epoch_with_variance(net, train_iter, loss, updater):
"""The training loop defined in Chapter 3.
Defined in :numref:`sec_softmax_scratch`"""
# Set the model to training mode
if isinstance(net, torch.nn.Module):
net.train()
# Sum of training loss, sum of training accuracy, no. of examples
metric = d2l.Accumulator(3)
for X, y in train_iter:
# Compute gradients and update parameters
y_hat, v1, v2 = net(X)
l = loss(y_hat, y)
if isinstance(updater, torch.optim.Optimizer):
# Using PyTorch in-built optimizer & loss criterion
updater.zero_grad()
l.mean().backward()
updater.step()
else:
# Using custom built optimizer & loss criterion
l.sum().backward()
updater(X.shape[0])
metric.add(v1 * (y.numel() - 1), v2 * (y.numel() - 1), y.numel())
# Return training loss and training accuracy
return metric[0] / metric[2], metric[1] / metric[2]
def train_with_varience(net, train_iter, test_iter, loss, num_epochs, updater):
"""Train a model (defined in Chapter 3).
Defined in :numref:`sec_softmax_scratch`"""
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['variance 1', 'variance 2'])
for epoch in range(num_epochs):
train_metrics = train_epoch_with_variance(net, train_iter, loss, updater)
print(train_metrics)
animator.add(epoch + 1, train_metrics)
print(train_metrics)
num_epochs, lr, batch_size = 20, 0.5, 256
loss = nn.CrossEntropyLoss(reduction = 'none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
net_with_dropout = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2, True)
net_with_dropout.apply(init_weights)
train_with_varience(net_with_dropout, train_iter, test_iter, loss, num_epochs, trainer)
net_without_dropout = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2, False)
net_without_dropout.apply(init_weights)
train_with_varience(net_without_dropout, train_iter, test_iter, loss, num_epochs, trainer)
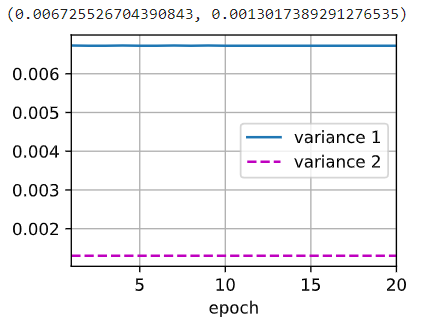
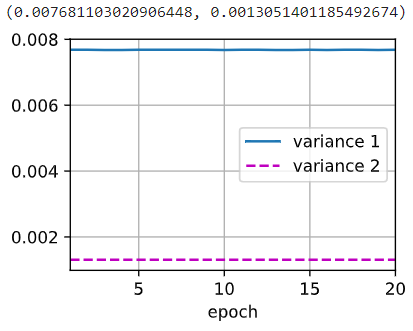
上图(左图)为使用暂退法的第一层方差与第二层方差,下图(右图)为不使用暂退法的第一层与第二层方差。可以发现加入 Dropout 层后,方差明显变小。
(4)为什么在测试时通常不使用暂退法?
尽量将全部函数都应用上来,暂退法本质上是给模型加噪声,测试的时候反而会影响效果。
(5)以本节中的模型为例,比较使用暂退法和权重衰减的效果。如果同时使用暂退法和权重衰减,会发生什么情况?结果是累加的吗?收益是否减少(或者说更糟)?它们互相抵消了吗?
wd = 0
trainer = torch.optim.SGD([
{"params": net[1].weight, "weight_decay": wd},
{"params": net[4].weight, "weight_decay": wd},
{"params": net[7].weight, "weight_decay": wd},
{"params": net[1].bias},
{"params": net[4].bias},
{"params": net[7].bias},
], lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
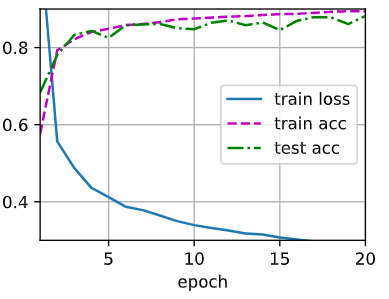
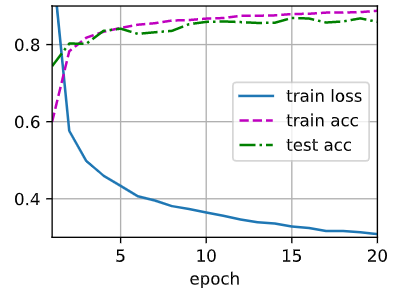
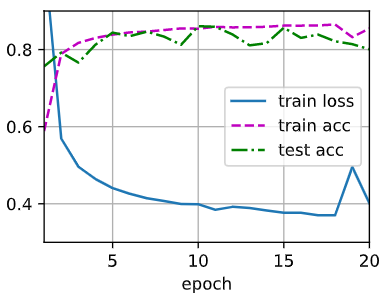
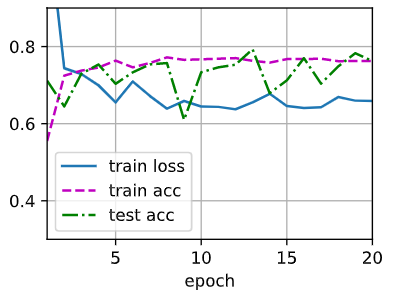
图 1 是 wd=0 的情况下,即不采用权重衰减仅采用暂退法的曲线。图 2 是 \(10^{-4}\) 的情况下的曲线,图 3 为 \(10^{-3}\) 的情况下的曲线,可以发现准确率有所降低,训练损失函数也没有降下去,最后还有奇怪的凸起。图 4 为 \(10^{-2}\) 情况下的曲线,可以发现完全没拟合。再大的情况甚至曲线都不会出现在这张图上了。
由上面几张图可以简单得出结论,超过 \(10^{-3}\) 的情况几乎无法选择,\(10^{-4}\) 目前来看情况最好,但是和 \(0\) 的情况比起来,收敛速度更慢,除此之外难以说明哪个更优。
(6)如果我们将暂退法应用到权重矩阵的各个权重,而不是激活值,会发生什么?
只使用暂退法修改前两个线性层的权重。
dropout1, dropout2 = 0.2, 0.5
class Net(nn.Module):
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2, is_training=True):
super(Net, self).__init__()
self.num_inputs = num_inputs
self.training = is_training
self.lin1 = nn.Linear(num_inputs, num_hiddens1)
self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)
self.lin3 = nn.Linear(num_hiddens2, num_outputs)
self.relu = nn.ReLU()
def forward(self, X):
W1 = dropout_layer(self.lin1.weight, dropout1)
W2 = dropout_layer(self.lin2.weight, dropout2)
H1 = self.relu(torch.matmul(X.reshape((-1, self.num_inputs)), W1.t()) + self.lin1.bias)
H2 = self.relu(torch.matmul(H1, W2.t()) + self.lin2.bias)
out = self.lin3(H2)
return out
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
num_epochs, lr, batch_size = 20, 0.5, 256
loss = nn.CrossEntropyLoss(reduction = 'none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
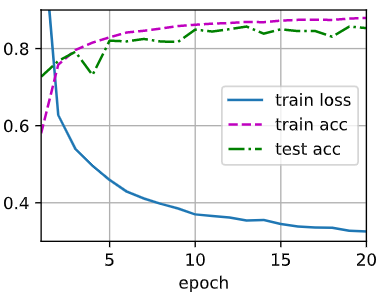
训练速度更慢了,且几乎显然不如对激活值应用暂退法。
(7)请提出另一个在每一层注入随机噪声的技术,该技术优于标准暂退法。
评论区有老哥说对每一层输出的激活值加了个高斯噪声(这不就是书中提的 Bishop 的做法吗),但是由于原本的损失以及精度太好了,所以啥都看不出来。我懒得做,估计我也做不出来。
4.7 前向传播、反向传播和计算图
中间作为示例的式子就跳过吧,就附个图好了,剩下的部分太长了=。=
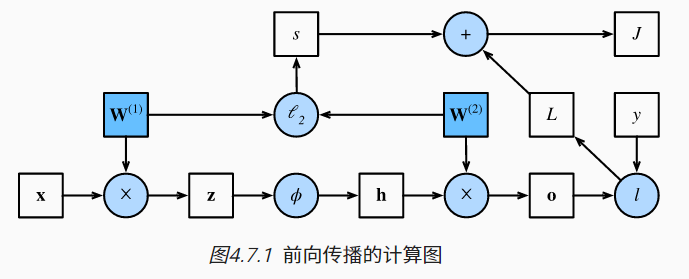
前向传播(forward propagation或forward pass)指的是:按顺序(从输入层到输出层)计算和存储神经网络中每层的结果。
反向传播(backward propagation或backpropagation)指的是计算神经网络参数梯度的方法。简言之,该方法根据微积分中的链式规则,按相反的顺序从输出层到输入层遍历网络。该算法存储了计算某些参数梯度时所需的任何中间变量(偏导数)。
对于前向传播,我们沿着依赖的方向遍历计算图并计算其路径上的所有变量。然后将这些用于反向传播,其中计算顺序与计算图的相反。
因此,在训练神经网络时,在初始化模型参数后,我们交替使用前向传播和反向传播,利用反向传播给出的梯度来更新模型参数。注意,反向传播重复利用前向传播中存储的中间值,以避免重复计算。带来的影响之一是我们需要保留中间值,直到反向传播完成。这也是训练比单纯的预测需要更多的内存(显存)的原因之一。此外,这些中间值的大小与网络层的数量和批量的大小大致成正比。因此,使用更大的批量来训练更深层次的网络更容易导致内存不足(out of memory)错误。
课后题
(1)假设一些标量函数 \(\boldsymbol{X}\) 的输入 \(\boldsymbol{X}\) 是 \(n \times m\) 矩阵。\(f\) 相对于 \(\boldsymbol{X}\) 的梯度的维数是多少?
显然是 \(n \times m\) 的。可以理解为 \(f = x_{11} \oplus x_{12} \oplus \cdots \oplus x_{nm}\),那么 \(f\) 对 \(\boldsymbol{X}\) 中的每一个元素都有偏导数。
(2)向本节中描述的模型的隐藏层添加偏置项(不需要在正则化项中包含偏置项)
画计算图——不画(懒得拍照了)
推导反向传播方程:
\frac{\partial J}{\partial \boldsymbol{b}^{(2)}} = \frac{\partial J}{\partial L} \frac{\partial L}{\partial \boldsymbol{b}^{(2)}} = \frac{\partial L}{\partial\boldsymbol{b}^{(2)}}
\]
上面的推导可能有一些问题,希望您们如果和我推的不一样可以在评论区讨论一下。
(3)计算本节所描述的模型用于训练和预测的内存空间。
首先假定所有的变量统一使用 float32,即一个浮点数 \(4\) 个字节。其次,训练时由于需要中间变量,因此所需空间是全部中间变量所占空间之和,除此之外还有梯度的存在。而预测时除了输入 \(\boldsymbol{x}\)、输出 \(y\)、目标函数 \(J\) 这三者(除参数以外)必须要存储外,剩下的仅需要统计占最大空间的变量即可。
如下表所示(这里有些定义的空间大小您需要回去翻一下原书):
| 变量/参数 | 特征个数 |
|---|---|
| \(\boldsymbol{x}\) | \(d\) |
| \(\boldsymbol{z}\) | \(h\) |
| \(\boldsymbol{h}\) | \(h\) |
| \(\boldsymbol{o}\) | \(q\) |
| \(y\) | 1 |
| \(L\) | 1 |
| \(s\) | 1 |
| \(J\) | 1 |
| \(\boldsymbol{W}^{(1)}\) | \(h \times d\) |
| \(\boldsymbol{W}^{(2)}\) | \(q \times h\) |
| \(\frac{\partial \boldsymbol{z}}{\partial \boldsymbol{x}}\) | \(h \times d\) |
| \(\frac{\partial \boldsymbol{z}}{\partial \boldsymbol{W}^{(1)}}\) | \(h \times d\) |
| \(\frac{\partial \boldsymbol{h}}{\partial \boldsymbol{z}}\) | \(h\) |
| \(\frac{\partial \boldsymbol{o}}{\partial \boldsymbol{h}}\) | \(q \times h\) |
| \(\frac{\partial \boldsymbol{o}}{\partial \boldsymbol{W}^{(2)}}\) | \(q \times h\) |
| \(\frac{\partial L}{\partial \boldsymbol{o}}\) | \(q\) |
| \(\frac{\partial L}{\partial y}\) | 1 |
| \(\frac{\partial s}{\partial \boldsymbol{W}^{(1)}}\) | \(h \times d\) |
| \(\frac{\partial s}{\partial \boldsymbol{W}^{(2)}}\) | \(q \times h\) |
| \(\frac{\partial J}{\partial s}\) | 1 |
| \(\frac{\partial J}{\partial y}\) | 1 |
因此,训练时,除梯度外,所占空间为 \(4 \times (d + 2h + q + 4 + h \times d + q \times h)\) 字节。
而梯度如果不优化的话,足足占了 \(4 \times 3 \times (1 + h \times d + q \times h)\) 字节。
因此共占了 \(4 \times (d + 2h + q + 7 + 4 \times h \times d + 4 \times q \times h)\) 字节。
预测时所占空间为 \(4 \times \left(d + 2 + h \times d + q \times h + \max (1, h, q) \right)\) 字节。
(4)假设想计算二阶导数。计算图会发生什么变化?预计计算需要多长时间?
在使用 autograd 计算一阶导数时,让 create_graph=True 这样就可以对一阶导再求导了。
显而易得的,计算图中的节点数量会增加,因为梯度也变成节点进入计算图中,假设上一次节点数为 \(n\),那么二阶导的计算图中的节点个数变为 \(2n+1\),预计计算时间会变二倍。
(5)假设计算图对当前 GPU 来说太大了。(5.a)请尝试把它划分到多个 GPU 上。(5.b)这与小批量训练相比,有哪些优点和缺点?
可以参考知乎PyTorch 81. 模型并行 Model Parallel 将模型并行到多个 GPU 的做法。
比如现在有一个包含2个 Linear layers 的模型,我们想在2块 GPU 上 run 它,办法可以是在每块 GPU 上放置1个 Linear layer,并且把得到的中间结果在 GPU 之间移动。代码可以是这样子:
import torch import torch.nn as nn import torch.optim as optim class ToyModel(nn.Module): def __init__(self): super(ToyModel, self).__init__() self.net1 = torch.nn.Linear(10, 10).to('cuda:0') self.relu = torch.nn.ReLU() self.net2 = torch.nn.Linear(10, 5).to('cuda:1') def forward(self, x): x = self.relu(self.net1(x.to('cuda:0'))) return self.net2(x.to('cuda:1'))注意,上述 ToyModel 看起来与在单个 GPU 上的实现方式非常相似,除了四个 to(device) 的调用,将 Linear layer 和张量放在适当的设备上。这是该模型中唯一需要改变的地方。backward() 和 torch.optim 将自动处理梯度问题,就像模型是在一个 GPU 上一样。
你只需要确保在调用损失函数时,标签和输出是在同一个设备上。像下面这样:
model = ToyModel() loss_fn = nn.MSELoss() optimizer = optim.SGD(model.parameters(), lr=0.001) optimizer.zero_grad() outputs = model(torch.randn(20, 10)) labels = torch.randn(20, 5).to('cuda:1') loss_fn(outputs, labels).backward() optimizer.step()这里应该把标签 labels 放在 \(1\) 号 GPU 上面,因为模型的输出就在 \(1\) 号 GPU 上。
这样做可以增大数据的规模,本质上和小批量训练一样,但是这样可以增大批量的大小。而训练速度略有降低,这是由于数据在不同的 GPU 上复制而导致的。
4.8 数值稳定性和模型初始化
初始化方案的选择在神经网络学习中起着举足轻重的作用,它对保持数值稳定性至关重要。此外,这些初始化方案的选择可以与非线性激活函数的选择有趣的结合在一起。我们选择哪个函数以及如何初始化参数可以决定优化算法收敛的速度有多快。糟糕选择可能会导致我们在训练时遇到梯度爆炸或梯度消失。
4.8.1 梯度消失和梯度爆炸
在链式法则中,梯度容易受到数值下溢问题的影响。当将太多的概率乘在一起时,这些问题经常会出现。在处理概率时,一个常见的技巧是切换到对数空间,即将数值表示的压力从尾数转移到指数。不幸的是,上面的问题更为严重:参数矩阵可能具有各种各样的特征值。他们可能很小,也可能很大;他们的乘积可能非常大,也可能非常小。
不稳定梯度带来的风险不止在于数值表示,也威胁到我们优化算法的稳定性。我们可能面临一些问题。要么是梯度爆炸(gradient exploding)问题:参数更新过大,破坏了模型的稳定收敛;要么是梯度消失(gradient vanishing)问题:参数更新过小,在每次更新时几乎不会移动,导致模型无法学习。
1. 梯度消失
sigmoid 函数以前很流行。由于早期的人工神经网络受到生物神经网络的启发,神经元要么完全激活要么完全不激活(就像生物神经元)的想法很有吸引力。
当sigmoid函数的输入很大或是很小时,它的梯度都会消失。此外,当反向传播通过许多层时,除非我们在刚刚好的地方,这些地方sigmoid函数的输入接近于零,否则整个乘积的梯度可能会消失。当我们的网络有很多层时,除非我们很小心,否则在某一层可能会切断梯度。事实上,这个问题曾经困扰着深度网络的训练。因此,更稳定的ReLU系列函数已经成为从业者的默认选择。
2. 梯度爆炸
多层神经网络通常存在像悬崖一样斜率较大的区域。这是由于几个较大的权重相乘导致的。书上举的例子是一百个服从 \(N(0,1)\) 的 \(4\times 4\) 矩阵相乘,当遇到斜率较大的悬崖结构时,梯度更新会很大程度地改变参数值,通常会完全跳过这类悬崖结构,使得参数弹射得非常远,可能导致之前做了无用功。
3. 打破对称性
神经网络设计中的另一个问题是其参数化所固有的对称性。书中举了一个一层两个隐藏单元的多层感知机,其中两个隐藏单元在前向传播过程中采用相同的输入和参数。这会导致回传时有相同的梯度,进而导致无论怎么迭代参数都对称。虽然小批量随机梯度下降不会打破这种对称性,但暂退法正则化可以。
4.8.2 参数初始化
解决(或至少减轻)上述问题的一种方法是进行参数初始化, 优化期间的注意和适当的正则化也可以进一步提高稳定性。
1. 默认初始化
如果我们不指定初始化方法, 框架将使用默认的随机初始化方法。例如在 PyTorch 中,线性层的权重和偏置被初始化为 \(U(-\sqrt{k}, \sqrt{k})\),其中 \(k=\frac{1}{\text{in_features}}\)。
2. Xavier 初始化
原书假设没有非线性的全连接层输出 \(o_i\) 的分布。对于该层 \(n_{\text{in}}\) 输入 \(x_j\) 以及相关权重 \(w_{ij}\),输出由下式给出:
\]
不妨假设 \(\mathbb{E}[w_{ij}] = 0, \text{Var}[w_{ij}] = \sigma^2\),而 \(\mathbb{E}[x_j] = 0, \text{Var}[x_j] = \gamma^2\),且这些都互相独立。
则可以计算出 \(o_i\) 的期望和方差:
\mathbb{E}[o_i] &= \sum_{j=1}^{n_{\text{in}}} \mathbb{E}[w_{ij} x_j] \\
&= \sum_{j=1}^{n_{\text{in}}} \mathbb{E}[w_{ij}] \mathbb{E}[x_j] \\
&= 0 \\
\text{Var}[o_i] &= \mathbb{E}[o_i^2] - (\mathbb{E}[o_i])^2 \\
&= \mathbb{E}[w_{ij}^2 x_j^2] - 0 \\
&= \mathbb{E}[w_{ij}^2] \mathbb{E}[x_j^2] \\
&= n_{\text{in}} \sigma^2 \gamma^2
\end{align}
\]
如果要使方差不变的方法是设置 \(n_{\text{in}} \sigma^2=1\)。然而,反向传播的过程中,也有类似的问题。如果要使反向传播梯度的方差不变,需要设置 \(n_{\text{out}} \sigma^2=1\),但是由于一般来说全连接层维度都会有所变化,即 \(n_{\text{in}} \not = n_{\text{out}}\),因此几乎无法同时满足上述两个条件。
于是 Xavier 初始化提出,要满足这个条件:
\]
通常,Xavier 初始化从均值为 \(0\),方差 \(\sigma^2 = \frac{2}{n_{\text{in}} + n_{\text{out}}}\) 的高斯分布中抽样权重。也可以改成从均匀分布中抽取权重,那么 Xavier 初始化的均匀分布为:
\]
尽管“不存在非线性”的假设在神经网络中很难实现,但是 Xavier 初始化方法在实践中比较有效。
练习题
(1)除了多层感知机的排列对称性之外,还能设计出其他神经网络可能会表现出对称性且需要被打破的情况吗?
显然存在,如 CNN 等。
(2)我们是否可以将线性回归或 softmax 回归中的所有权重参数初始化为相同的值?
可以,但是并不推荐。原因在于最开始这一步会显著体现出对称性,如果输入数据也具有对称性,那么反向传播后参数对称性几乎无法改变。
(3)在相关资料中查找两个矩阵乘积特征值的解析解。这对确保梯度条件合适有什么启示?
最大特征值与最小特征值可以决定矩阵的条件数,如果相差太大,那么条件数就也会太大,稍有扰动就会出现巨大差别。
(4)如果我们知道某些项是发散的,我们能在事后修正吗?
参考 LARS 的原论文,可以对每一层使用不同的学习率来修正这一问题。
4.9 环境和分布偏移
机器学习的许多应用中都存在类似的问题: 通过将基于模型的决策引入环境,可能会导致破坏模型的后果。
4.9.1 分布偏移的类型
在一个经典的情景中,假设训练数据是从某个分布 \(p_S(\boldsymbol{x}, y)\) 中采样的, 但是测试数据将包含从不同分布 \(p_T(\boldsymbol{x}, y)\) 中抽取的未标记样本。 一个清醒的现实是:如果没有任何关于 \(p_S(\boldsymbol{x})\) 和 $$p_T(\boldsymbol{x}, y)$$ 之间相互关系的假设, 学习到一个分类器是不可能的。
幸运的是,在对未来我们的数据可能发生变化的一些限制性假设下,有些算法可以检测这种偏移,甚至可以动态调整,以提高原始分类器的精度。
1. 协变量偏移
协变量偏移是指输入的分布改变了,但是标签函数(即条件分布 \(P(y|\boldsymbol{x})\))没有改变。之所以命名为协变量偏移是因为协变量(特征)分布的变化。比如原书中给的例子:
训练时使用下列写实猫狗图像:

测试时使用下列卡通猫狗图像:

训练集由真实照片组成,而测试集只包含卡通图片。假设在一个与测试集的特征有着本质不同的数据集上进行训练,如果没有方法来适应新的领域,可能会有麻烦。
2. 标签偏移
标签偏移(label shift)描述了与协变量偏移相反的问题。这里我们假设标签边缘概率 \(P(y)\) 可以改变, 但是类别条件分布 \(P(\boldsymbol{x} | y)\) 在不同的领域之间保持不变。当我们认为 \(y\) 导致 \(\boldsymbol{x}\) 时,标签偏移是一个合理的假设。在另一些情况下,标签偏移和协变量偏移假设可以同时成立。例如,当标签是确定的,即使 \(y\) 导致 \(\boldsymbol{x}\),协变量偏移假设也会得到满足。有趣的是,在这些情况下,使用基于标签偏移假设的方法通常是有利的。这是因为这些方法倾向于包含看起来像标签(通常是低维)的对象,而不是像输入(通常是高维的)对象。
3. 概念偏移
概念偏移(concept shift): 当标签的定义发生变化时,就会出现这种问题。类别会随着不同时间、不同地理位置的用法而发生变化。例如地瓜这个概念南北方有巨大差异,这是地理位置的差异。再比如中国从文言文到白话文的过程中所有的词伴随着时间流逝意思已经有巨大变化。因此,最好可以利用在时间或空间上逐渐发生偏移的知识。
4.9.3 经验风险与实际风险
1. 经验风险与实际风险
训练数据 \(\{(\boldsymbol{x}_1, y_1), \dots, (\boldsymbol{x}_n, y_n)\}\) 的特征和相关的标签经过迭代,在每一个小批量之后更新模型 \(f\) 的参数。为了简单起见,我们不考虑正则化,因此极大地降低了训练损失:
\]
其中 \(l\) 是损失函数,用来度量:给定标签 \(y_i\),预测 \(f(\boldsymbol{x}_i)\) 的“糟糕程度”。统计学家将上面式子为经验风险。经验风险(empirical risk)是为了近似真实风险(true risk),整个训练数据上的平均损失,即从其真实分布 \(P(\boldsymbol{x}, y)\) 中抽取的所有数据的总体损失的期望值:
\]
然而在实践中,我们通常无法获得总体数据。因此可以最小化经验风险来近似最小化真实风险。
2. 协变量偏移纠正
假设对于带标签的数据 \((\boldsymbol{x}_i, y_i)\),我们要评估 \(P(y|\boldsymbol{x})\)。然而观测值 \(\boldsymbol{x}_i\) 是从某些源分布 \(q(\boldsymbol{x})\) 中得出的,而不是从目标分布 \(p(\boldsymbol{x})\) 中得出的。幸运的是,依赖性假设意味着条件分布保持不变,即:\(p(y|\boldsymbol{x}) = q(y|\boldsymbol{x})\)。如果源分布 \(q(\boldsymbol{x})\) 是“错误的”,我们可以通过在真实风险的计算中,使用以下简单的恒等式来进行纠正:
\]
换句话说,我们需要根据数据来自正确分布与来自错误分布的概率之比,来重新衡量每个数据样本的权重:
\]
将权重 \(\beta_i\) 代入到每个数据样本 \((\boldsymbol{x}_i, y_i)\) 中,我们可以使用”加权经验风险最小化“来训练模型:
\]
由于不知道这个比率 \(\beta_i\),我们需要估计它。有许多方法都可以用,包括一些花哨的算子理论方法,试图直接使用最小范数或最大熵原理重新校准期望算子。对于任意一种这样的方法,我们都需要从两个分布中抽取样本:“真实”的分布 \(p\),通过访问测试数据获取;训练集 \(q\),通过人工合成的很容易获得。请注意,我们只需要特征 \(\boldsymbol{x} \sim p(\boldsymbol{x})\),不需要访问标签 \(y \sim p(y)\)。
在这种情况下,有一种非常有效的方法可以得到几乎与原始方法一样好的结果:逻辑斯蒂回归(logistic regression)。这是用于二元分类的 softmax 回归的一个特例。综上所述,我们学习了一个分类器来区分从 \(p(\boldsymbol{x})\) 抽取的数据和从 \(q(\boldsymbol{x})\) 抽取的数据。如果无法区分这两个分布,则意味着相关的样本可能来自这两个分布中的任何一个。此外,任何可以很好区分的样本都应该相应地显著增加或减少权重。
为了简单起见,假设我们分别从 \(p(\boldsymbol{x})\) 和 \(q(\boldsymbol{x})\) 两个分布中抽取相同数量的样本。现在用 \(z\) 标签表示:从 \(p\) 抽取的数据为 \(1\),从 \(q\) 抽取的数据为 \(−1\)。然后,混合数据集中的概率由下式给出:
\]
因此,如果使用 logistic 回归方法,其中 \(P(z=1|\boldsymbol{x}) = \frac{1}{1 + \exp(-h(\boldsymbol{x}))}\)(ℎ是一个参数化函数),则很自然有:
\]
在得到这个式子之后,接下来就只剩下两个问题了。第一个问题是关于区分来自两个分布的数据;第二个问题是关于加权经验风险的最小化问题。问题二里,要对其中的项加权 \(\beta_i\)。
现在,我们来看一下完整的协变量偏移纠正算法。假设我们有一个训练集 \(\{(\boldsymbol{x}_1, y_1), \dots, (\boldsymbol{x}_n, y_n)\}\) 和一个未标记的测试集 \(\{\boldsymbol{u}_1, \dots, \boldsymbol{u}_m \}\)。对于协变量偏移,我们假设 \(\boldsymbol{x}_i (1 \le i \le n)\) 来自某个源分布,\(\boldsymbol{u}_i\) 来自目标分布。以下是纠正协变量偏移的典型算法:
- 生成一个二元分类训练集:\(\{(\boldsymbol{x}_1, -1), \dots, (\boldsymbol{x}_n, -1), (\boldsymbol{u}_1, 1), \dots, (\boldsymbol{u}_m, 1)\}\)。
- 用逻辑斯蒂回归训练二元分类器得到函数 \(h\)。
- 使用 \(\beta_i = \exp(h(\boldsymbol{x}_i))\) 或更好的 \(\beta_i = \min (\exp(h(\boldsymbol{x}_i)), c)\)(\(c\) 为常量)对训练数据进行加权。
- 使用权重 \(\beta_i\) 进行经验风险最小化中 \(\{(\boldsymbol{x}_1, y_1), \dots, (\boldsymbol{x}_n, y_n)\}\) 的训练。
请注意,上述算法依赖于一个重要的假设:需要目标分布(例如,测试分布)中的每个数据样本在训练时出现的概率非零。如果我们找到 \(p(\boldsymbol{x}) > 0\) 但 \(q(\boldsymbol{x})=0\) 的点,那么相应的重要性权重会是无穷大。
3. 标签偏移纠正
原书这段写的非常奇怪,很难看懂。写一点一家之言。
假设我们处理的是 \(k\) 个类别的分类任务。使用与上文中相同符号,\(q\) 和 \(p\) 中分别是源分布(例如训练时的分布)和目标分布(例如测试时的分布)。假设标签的分布随时间变化:\(q(y) \not = p(y)\),但类别条件分布保持不变:\(q(\boldsymbol{x}|y)=p(\boldsymbol{x}|y)\)。如果源分布 \(q(y)\) 是“错误的”,我们可以根据之前定义的真实风险中的恒等式进行更正:
\]
这里,重要性权重将对应于标签似然比率:
\]
标签偏移的一个好处是,如果我们在源分布上有一个相当好的模型,那么我们可以得到对这些权重的一致估计,而不需要处理周边的其他维度。在深度学习中,输入往往是高维对象(如图像),而标签通常是低维(如类别)。因此处理标签偏移会容易一些。
为了估计目标标签分布 \(p(y)\),我们首先采用性能相当好的现成的分类器(通常基于训练数据,即 \(q\) 对应的数据进行训练),并使用验证集(也来自训练分布)计算其混淆矩阵。混淆矩阵 \(\boldsymbol{C}\) 是一个 \(k \times k\) 矩阵,其中每列对应于标签类别,每行对应于模型的预测类别。每个单元格的值 \(c_{ij}\) 是验证集中真实标签为 \(j\),而模型预测为 \(i\) 的样本数量所占的比例。这个矩阵可以理解为在源分布上当真实标签为 \(j\) 发生时,模型预测为 \(i\) 的条件概率 \(P_q(i|j)\)。由于标签偏移仅仅是标签的边缘概率 \(P(y)\) 改变,因此这个式子在目标分布上的条件概率 \(P_p(i | j)\) 与在源分布上的条件概率 \(P_q(i|j)\) 相等。
现在,我们不能直接计算目标数据上的混淆矩阵,因为我们无法看到真实环境下的样本的标签,除非我们再搭建一个复杂的实时标注流程。然而,我们所能做的是将所有模型在测试时的预测取平均数,得到平均模型输出 \(\mu(\hat{\boldsymbol{y}}) \in \mathbb{R}^k\),其中第 \(i\) 个元素 \(\mu (\hat{y}_i)\) 是我们模型预测测试集中 \(i\) 的总预测分数,也可以理解为在目标分布下模型预测为 \(i\) 类别的概率之和。
结果表明,如果我们的分类器一开始就相当准确,并且目标数据只包含我们以前见过的类别,以及如果标签偏移假设成立(这里最强的假设),我们就可以通过求解一个简单的线性系统来估计测试集的标签分布:
\]
因为作为一个估计,\(\sum_{j=1}^k c_{ij} p(y_j) = \mu (\hat{y}_i)\) 对所有 \(1 \le i \le k\) 成立,其中 \(p(y_j)\) 是 \(k\) 维标签分布向量 \(p(\boldsymbol{y})\) 的第 \(j\) 个元素。如果我们的分类器一开始就足够精确,那么混淆矩阵 \(\boldsymbol{C}\) 的对角线元素将会比较大,因此是可逆的, 进而我们可以得到一个解 \(p(\boldsymbol{y}) = \boldsymbol{C}^{-1} \mu(\hat{\boldsymbol{y}})\)。
这个式子原书的跳步非常严重,所以展开了写一下。
\sum_{j=1}^k c_{ij} p(y_j) &= \sum_{j=1}^k P_q(\text{model predict}=i|\text{true label}=j) P_p(\text{true label}=j) \\
&= \sum_{j=1}^k P_p(\text{model predict}=i|\text{true label}=j) P_p(\text{true label}=j) \\
&= \sum_{j=1}^k P_p(\text{model predict}=i,\text{true label}=j) \\
&= P_p(\text{model predict}=i) = \mu (\hat{y}_i)
\end{align}
\]
因此,上式成立。
因为我们观测源数据上的标签,所以很容易估计分布 \(q(y)\)。那么对于标签为 \(y_i\) 的任何训练样本 \(i\),我们可以使用我们估计的 \(p(y_i) / q(y_i)\) 比率来计算权重 \(\beta_i\),并将其代入加权经验风险最小化的式子中。
4. 概念偏移纠正
概念偏移很难用原则性的方式解决。除了从零开始收集新标签和训练,别无妙方。幸运的是,在实践中极端的偏移是罕见的,通常情况下,概念的变化总是缓慢的。在这种情况下,我们可以使用与训练网络相同的方法,使其适应数据的变化。换言之,我们使用新数据更新现有的网络权重,而不是从头开始训练。
4.9.4 学习问题的分类法
1. 批量学习
在批量学习(batch learning)中,我们可以访问一组训练特征和标签 \(\{ (\boldsymbol{x}_1, y_1), \dots, (\boldsymbol{x}_n, y_n) \}\),我们使用这些特性和标签训练 \(f(\boldsymbol{x})\)。然后,我们部署此模型来对来自同一分布的新数据 \((\boldsymbol{x},y)\) 进行评分。
2. 在线学习
除了“批量”地学习,我们还可以单个“在线”学习数据 \((\boldsymbol{x}_i, y_i)\)。更具体地说,我们首先观测到 \(\boldsymbol{x}_i\),然后我们得出一个估计值 \(f(\boldsymbol{x}_i)\),只有当我们做到这一点后,我们才观测到 \(y_i\)。然后根据我们的决定,我们会得到奖励或损失。
在在线学习(online learning)中,我们有以下的循环。在这个循环中,给定新的观测结果,我们会不断地改进我们的模型。
\]
3. 老虎只因
老虎只因(bandits)是上述问题的一个特例。虽然在大多数学习问题中,我们有一个连续参数化的函数 \(f\)(例如,一个深度网络)。但在一个老虎只因问题中,我们只有有限数量的手臂可以拉动。也就是说,我们可以采取的行动是有限的。对于这个更简单的问题,可以获得更强的最优性理论保证。
4. 控制
在很多情况下,环境会记住我们所做的事。不一定是以一种对抗的方式,但它会记住,而且它的反应将取决于之前发生的事情。许多这样的算法形成了一个环境模型,在这个模型中,他们的行为使得他们的决策看起来不那么随机。近年来,控制理论也被用于自动调整超参数,以获得更好的解构和重建质量,提高生成文本的多样性和生成图像的重建质量。
5. 强化学习
强化学习(reinforcement learning)强调如何基于环境而行动,以取得最大化的预期利益。
6. 考虑到环境
上述不同情况之间的一个关键区别是:在静止环境中可能一直有效的相同策略,在环境能够改变的情况下可能不会始终有效。环境变化的速度和方式在很大程度上决定了我们可以采用的算法类型。
4.10 Kaggle:预测房价
使用 Kaggle 跑代码的时候发现,to_csv() 函数会出问题,我也改不动,因此本章派生实验跳过。
原文链接:https://www.cnblogs.com/bringlu/p/17353646.html
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:【动手学深度学习】第四章笔记:多层感知机、权重衰减、暂退法、数值稳定性和模型初始化、环境和分布偏移 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
