写在前面
Facebook 开源的VideoPose3D模型致力于实现准确的人体骨骼3D重建。其效果令人惊叹,只需要使用手机相机就可以实现相似的效果。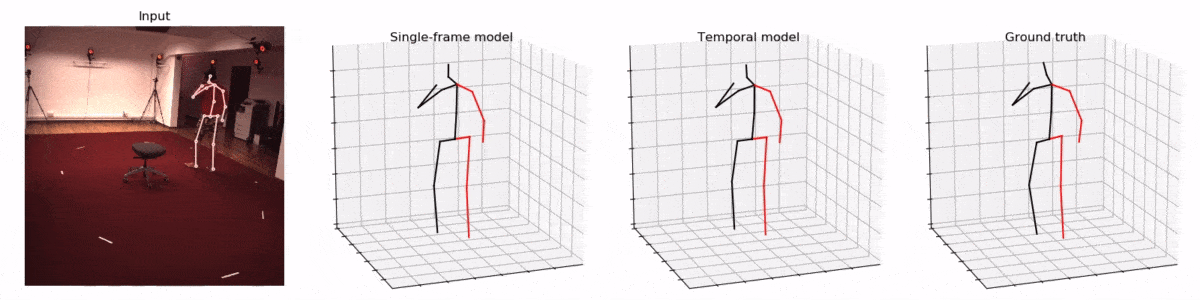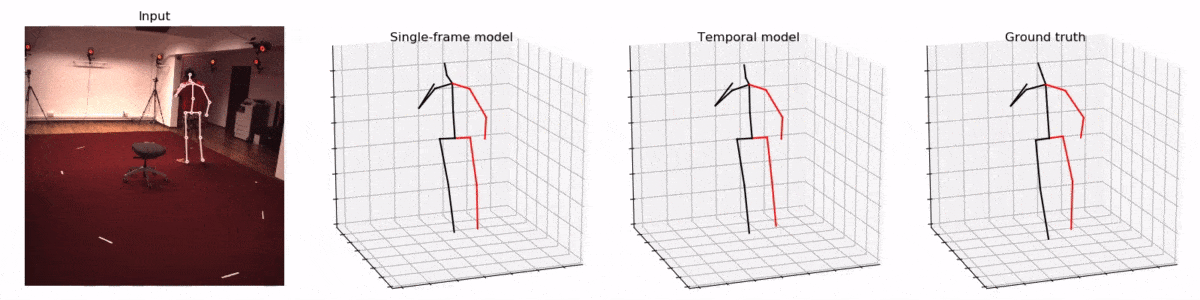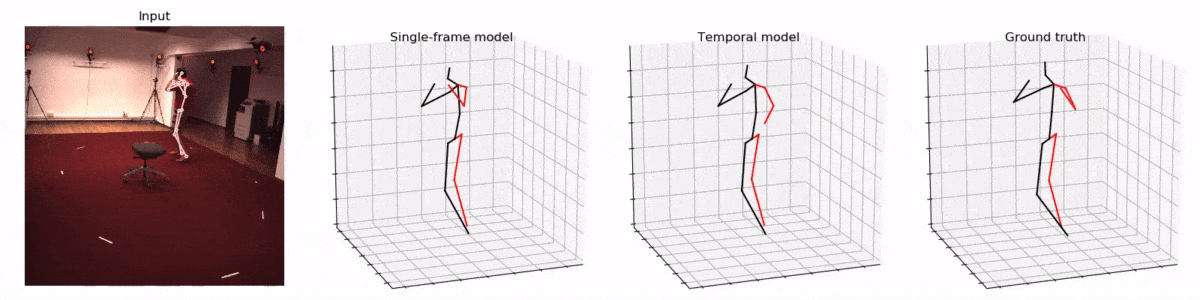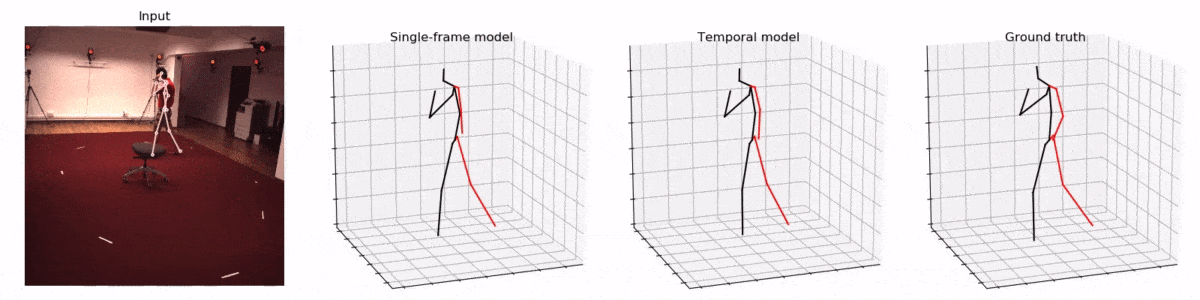

而一旦技术成熟,这种人体骨骼的三维重建在很多领域将会产生颠覆性的应用。
但是到目前为止,该技术还是有很多不足,其中制约该技术商业化运用的一个最大难点在于源码理解困难,模型是纯纯黑盒。因此本文将尝试理解该论文的实现方法。
介绍
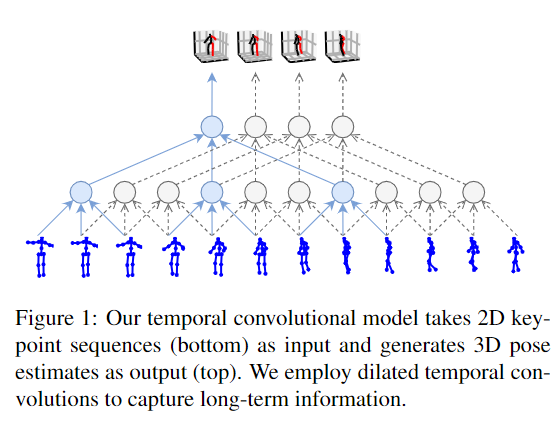
论文一开始就阐述了核心技术,即使用2D关键点预测3D姿势,最后再将3D姿势反向投影回原先的2D关键点(半监督方法)。
并且作者声称在2D关键点预测3D时使用了时间卷积架构(temporal convolutions),让模型可以一次看见多个帧,从而提升3D姿态估计的准确性。
并且作者还介绍了一个基于半监督学习的技术方法,以提高标记 3D 真实姿态数据的的准确性。
这里的几个关键词分别是:
2D关键点: 通过基于2D图像检测技术获取的人体2D关键点。相关的技术库主要有:Detectron,Openpose 等。
需要注意的是,这种技术仅检测在图片的2D坐标系内出现的人体骨骼关键点,并不包含深度信息(也就是第三轴),因此无法建立3D模型。
3D姿势: 相对于上文的2D关键点,3D姿势也可以说成是3D关键点,VideoPose3D模型通过获取的2D关键点为这些关键点添加了深度信息,从而建立了3D模型。这也是这个模型的魅力所在。
将3D姿势反向投影回原先的2D关键点,监督学习的技术方法:这两个关键词说的其实是一个技术。即在大量的未标记视频中(例如油管视频),通过2D关键点检测技术生成2D关键点之后,应用VideoPose3D生成3D关键点,,之后,再将生成的3D关键点投影回原来的2D空间中,这时就会发现,你有两套2D关键点了,一套是通过2D关键点检测技术生成的2D关键点,另一套是3D关键点投影回来的2D关键点。然后就可以通过计算这两套关键点之间的误差来评价生成的3D模型的效果了。因此被称为半监督学习的技术方法。而且作者借鉴了对抗神经网络(GAN)的理念,在两套关键点差异过大时对模型予以惩罚,从而可以大量生成标记数据集,,,这真是挺强的。这个技术的理解难点在于将3D姿势反向投影回2D,因为由VideoPose3D模型预测出来的3D关键点仅仅是各个关节的相对位置,而不包含当前世界场景下的绝对位置(也就是说,你不知道人物在视频中的移动轨迹),所以如果想要将3D关键点反向投影回2D的话,必须要获得人物的身体中心(或者原点)的移动轨迹,然后再将3D关键点投影上去。为此,作者还专门写了一个轨迹模型(Trajectory model)用于预测人体在3D空间内的轨迹。但是作者没有细说轨迹模型的实现方法。
时间卷积架构(temporal convolutions):
作者们利用了卷积神经网络的特性,让模型可以一次'看见'时间轴上的先后的多个动作(视频的帧),从而更好地估计3D姿态。这也是我认为本文的第二大创新点。
试想,让你只看一张图片就估计一个物体(人)的3D姿势,和让你包含了一个人连续动作的多个图片来估计3D姿势,可能后者会来得更准确一些。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:3D human pose estimation in video with temporal convolutions and semi-supervised training 论文理解 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 