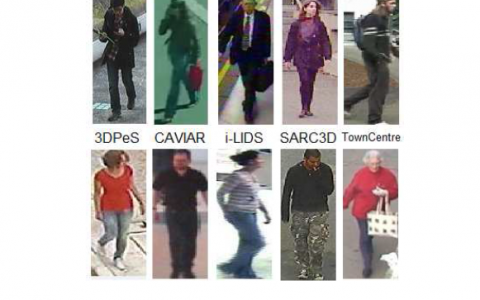
GAN在生成任务上与其他方法对比
Machine Learning (ML) 本质上是寻找一个函数f:X→Y,通过网络来近似这个函数。Structured Learning (SL) 输出相对于ML更加复杂,可能是图、树、序列……通常ML的问题,每个类别都会有一些样本,但是SL则不会——输出可能是输入从来没见过的东西。
在GAN 之前,auto-encoder (AE) 非常常用。AE结构:输入→ encoder → vector c → decoder →输出。训练的时候要使得输入输出尽可能相近。当做生成任务的时候,截取AE的decoder部分,随机给vector c,输出即生成的结果。所以可见AE可以用于做生成——即将decoder输出视为生成信息。但是这种训练方式面对一个问题,假设A、B都是训练集信息,针对A、B网络能够很好的进行生成,但是当面对0.5A+0.5B网络将会不知道输出应该是什么(最大的可能是两个图像的堆叠)。
对AE的改进叫做variational-AE (VAE) 在之前模型结构的基础上,对输入加上了噪声,其余不变。这种操作能够让模型能加稳定。
VAE同样有一个问题,下图是四种生成的情况。由于通常会以衡量输入输出的相似度作为评估标准,以L1或L2为例来讲,下图第一行的生成loss将会小于第二行。但从人的角度出发,第一行添加或者失去的一个像素点使得图像更加不真实,相反,第二行尽管图像与原图差别更大,但是更加真实。
的数学原理及基本算法")
VAE的另一个问题是,如果数据分布较为分散,从降低训练loss的情况出发,更倾向于产生数据分布介于分散分布之间。但往往,这样会使得生成结果非常不真实。
GAN能够弥补上述模型的缺陷。SL做生成任务,通常两种思考方式:bottom-up和top-down。前者是通过一个一个小组件完成生成任务,但往往会失去大局观。top-down是从大体上生成,但很难在细节上完成生成。GAN的通常构成包括generator(生成器)和discriminator(辨别器)。从SL的角度分析GAN,则可以将GAN看做同时具有bottom-up和top-down结构的生成模型。generator从细节上考虑如何生成,可视为bottom-up,discriminator从宏观考虑生成效果是否真实,可视为top-down。
GAN背后的数学原理
首先,GAN的结构通常包括generator和discriminator,前者用于生成,后者对生成结果进行评价。下面介绍GAN背后的数学原理。
假设随机变量X∼Pdata(x),通过GAN的generator生成的结果有:X∼PG(x)。那么如果生成器效果越好,那么两个分部将会越相近。通常使用最大似然进行优化。从 Pdata(x)中进行采样,获取样本{x1,x2,x3…xm},那么目标就是要去最大化这些样本产生的log likelihood:L=θargmaxlogi=1∏mPG(x;θ)这个公式的意思就是从Pdata采样出的样本用PG这个分布来产生,log likelihood越大越好。对上述公式进行进一步化简:
LLLL=θargmaxlogi=1∏mPG(xi;θ)=θargmaxi=1∑mlogPG(xi;θ)≈θargmaxEx∼Pdata[logPG(x;θ)]=θargmaxx∫Pdata(x)logPG(z;θ)dx上面公式的最后一个,可知,是关于θ进行求最大,所以,如果在该公式后面添加一项与θ无关的项将不会影响使该函数最大时θ的值,因此,上式改为:L=θargmaxx∫Pdata(x)logPG(x;θ)dx−x∫Pdata(x)logPdata(x)dx上面的公式实际上是Pdata和PG的KL散度的相反数,实际上上面的式子等同于:L=θargmin(Pdata∣∣PG)从GAN的角度理解上面的式子,generator定义了一个分布:PG而discriminator即作为评估者,计算L。
进行进一步的普适化——衡量两个分布之间的差异不仅仅KL散度可行,类似JS散度等也可以。因此,重新定义generator的作用,即定义一个分布PG,generator的作用就是:
G∗=θargminDiv(PG,Pdata)其中Div表示某一种散度(divergence)。此时如果是已知Pdata分布,则可以很好的解决上述问题(例如数据服从正态分布,那么设置正态分布参数未知,使用BP可以进行很好的拟合),但现在分布未知。
前文说过discriminator类似一个评估者,目的是分别真实样本还是生成样本——可以视为二分类任务。那么,可公式化其目标函数:
V(G,D)=Ex∼Pdata[logD(x)]+Ex∼PG[log(1−D(x))]那么discriminator训练的目标就是最大化这个式子,即D∗=DargmaxV(D,G)假设D(x)可能是任何函数——实际上无法做到,只有当参数无穷多的时候才能做到,将上式进行继续改写:
V(D,G)=x∫[Pdata(x)log(D(x))+PG(x)log(1−D(x))]dx当训练discriminator的时候通常会将generator进行固定,此时可将PG视为常数,Pdata显然是一个常数。那么上式可以写做V=x∫alog(D(x))+blog(1−D(x))dx要使得积分最大,如果每一个位置被积函数最大,那么积分最大。通过对被积函数f=alog(D)+blog(1−D),令导数等于零:
∂x∂fDa=0=1−Db可以得到D的表示并回带进V(后面省略分布里面的x),让被积函数分子分母同时乘以21:
DVVVV=Pdata+PGPdata=x∫Pdatalog21(Pdata+PG)21Pdatadx+x∫PGlog21(Pdata+PG)21PGdx=−2log2+x∫Pdatalog21(Pdata+PG)Pdatadx+x∫PGlog21(Pdata+PG)wPGdx=−2log2+KL(Pdata∣∣2Pdata+PG)+KL(PG∣∣2Pdata+PG)=−2log2+2JSD(Pdata∣∣PG)其中JSD表示JS散度。因此,discriminator的任务就是辨别生成数据和原始训练数据分布的不同,具体衡量指标是JS散度。
定义完discriminator借着从数学角度理解generator。generator的目标任务是:G∗=Gargmin(DargmaxV(G,D))在训练G的时候discriminator是固定的,所以训练目标可以修改为:Loss=Ex∼PG[log(1−D(x))]对于GAN的具体训练有两个需要注意的点
- generator和discriminator参数更新略有不同
- 刚开始D(x)非常小
针对第一个点,参考下图:的数学原理及基本算法")
两次更新之后的generator由于差异较大,将造成同一个discriminator不能同等地衡量这两个generator的效率——从数学角度来讲,训练generator的时候,依旧假设D的最大值点不变,但是因为实际上G的参数更新过多,D0∗已经不再是全局最大值点了,这样训练的G将会产生问题。所以实际操作,每次迭代,discriminator训练到底,generator训练更新次数较少。
针对第二点,刚开始的generator生成效果差,所以从函数图像看:
的数学原理及基本算法")
log(1−D(x))非常接近0,那么可知斜率很小,参数更新非常艰难。所以这里使用−log(D(x))替代原来的函数。从图像上可以看到两者的大小对应——同时最大、最小。
参考资料:李宏毅老师GAN讲解视频
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫