钢铁知识库,一个学习python爬虫、数据分析的知识库。人生苦短,快用python。
使用pycharm创建python文件时候,有时候需要自动生成想要的文件头,如何生成呢?
只需要以下几步:
-
在file->settings中搜索temp,找到file and code templates->python script
即可自定pycharm创建文件自动生成的头文件注释信息。
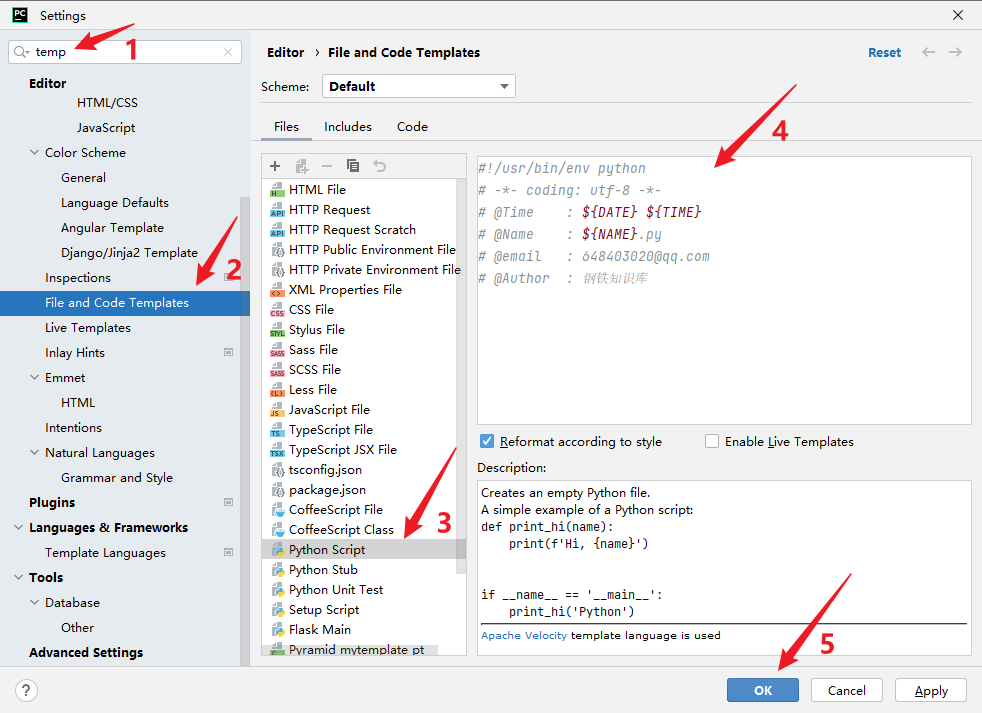

#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : ${DATE} ${TIME}
# @Name : ${NAME}.py
# @email : 648403020@qq.com
# @Author : 钢铁知识库
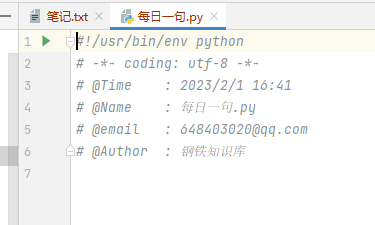
- 配置好后创建py文件效果如下:
- 当然也可以添加自己想要的预定义变量
---- 钢铁知识库 2023.02.03
#可用的预定义文件模板变量如下:
$ {PROJECT_NAME} - 当前项目的名称。
$ {NAME} - 在文件创建过程中在“新建文件”对话框中指定的新文件的名称。
$ {USER} - 当前用户的登录名。
$ {DATE} - 当前的系统日期。
$ {TIME} - 当前系统时间。
$ {YEAR} - 今年。
$ {MONTH} - 当月。
$ {DAY} - 当月的当天。
$ {HOUR} - 目前的小时。
$ {MINUTE} - 当前分钟。
$ {PRODUCT_NAME} - 将在其中创建文件的IDE的名称。
$ {MONTH_NAME_SHORT} - 月份名称的前3个字母。 示例:1月,2月等
$ {MONTH_NAME_FULL} - 一个月的全名。 示例:1月,2月等
以上就是python设置头文件的方式,其它文件也是类似,大家有需要自行配置即可。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:pycharm设置python头文件模版 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 